
🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
一、DataSophon是什么
1.1 DataSophon概述
1.2 架构概览
1.3 设计思想
二 、使用
2.1 HDFS的使用
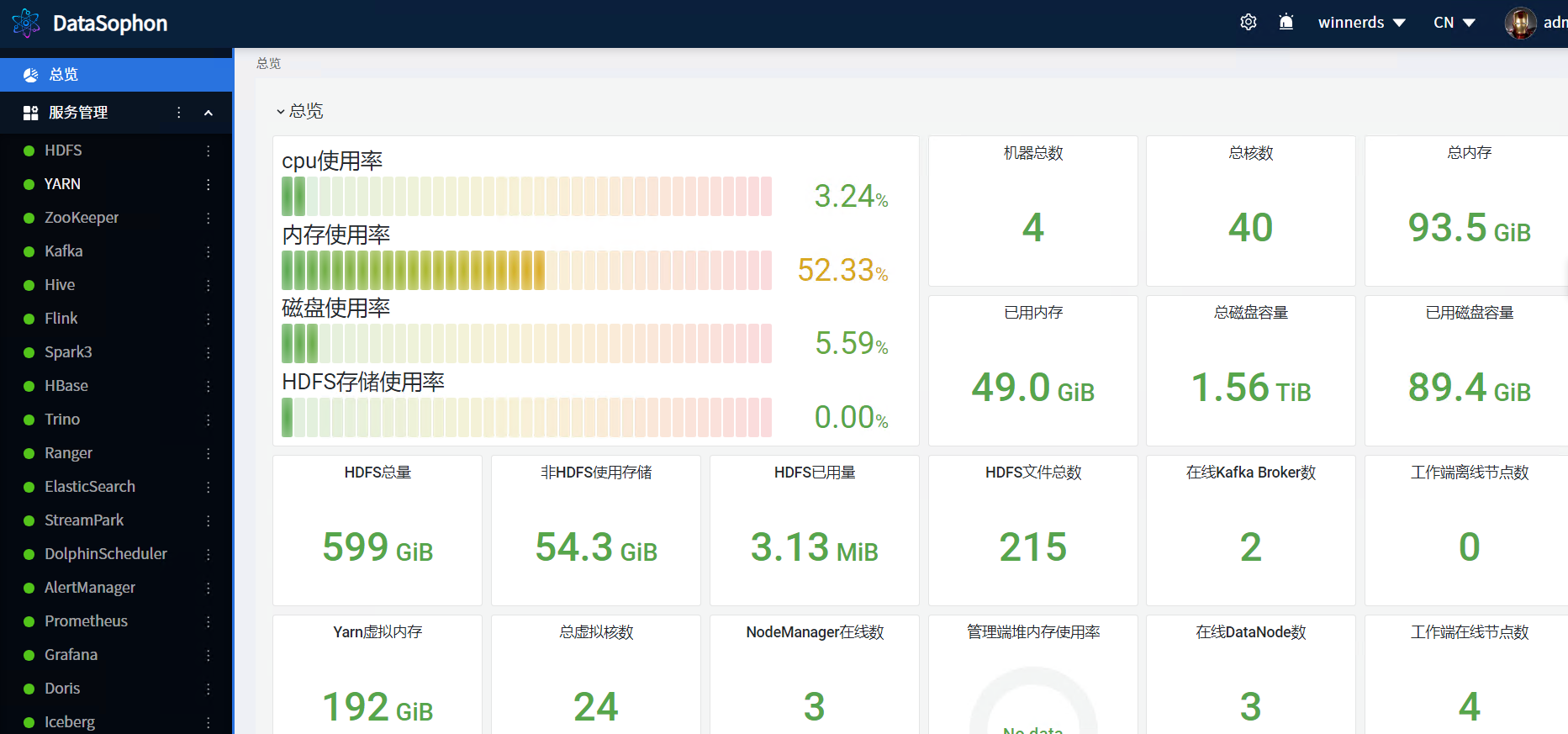
2.1.1 总览监控页面
2.1.2 HDFS web 页面
2.1.3 客户端命令
2.2 Hive的使用
2.2.1 总览监控页面
2.2.2 建表
2.3 HBase
2.3.1 总览监控页面
2.3.2 创建表
2.4 Spark
2.5 DataSophon 添加租户
一、DataSophon是什么
1.1 DataSophon概述
DataSophon也是个类似的管理平台,只不过与智子不同的是,智子的目的是锁死人类的基础科学阻碍人类技术爆炸,而DataSophon是致力于自动化监控、运维、管理大数据基础组件和节点的,帮助您快速构建起稳定,高效的大数据集群服务。
主要特性有:
- 快速部署,可快速完成300个节点的大数据集群部署
- 兼容复杂环境,极少的依赖使其很容易适配各种复杂环境
- 监控指标全面丰富,基于生产实践展示用户最关心的监控指标
- 灵活便捷的告警服务,可实现用户自定义告警组和告警指标
- 可扩展性强,用户可通过配置的方式集成或升级大数据组件
官方地址:DataSophon | DataSophon
GITHUB地址:datasophon/README_CN.md at dev · datavane/datasophon
1.2 架构概览

1.3 设计思想
为设计出轻量级,高性能,高可扩的,可满足国产化环境要求的大数据集群管理平台。需满足以下设计要求:
(1)一次编译,处处运行,项目部署仅依赖java环境,无其他系统环境依赖。
(2)DataSophon工作端占用资源少,不占用大数据计算节点资源。
(3)可扩展性高,可通过配置的方式集成托管第三方组件。、
二 、使用
2.1 HDFS的使用
2.1.1 总览监控页面
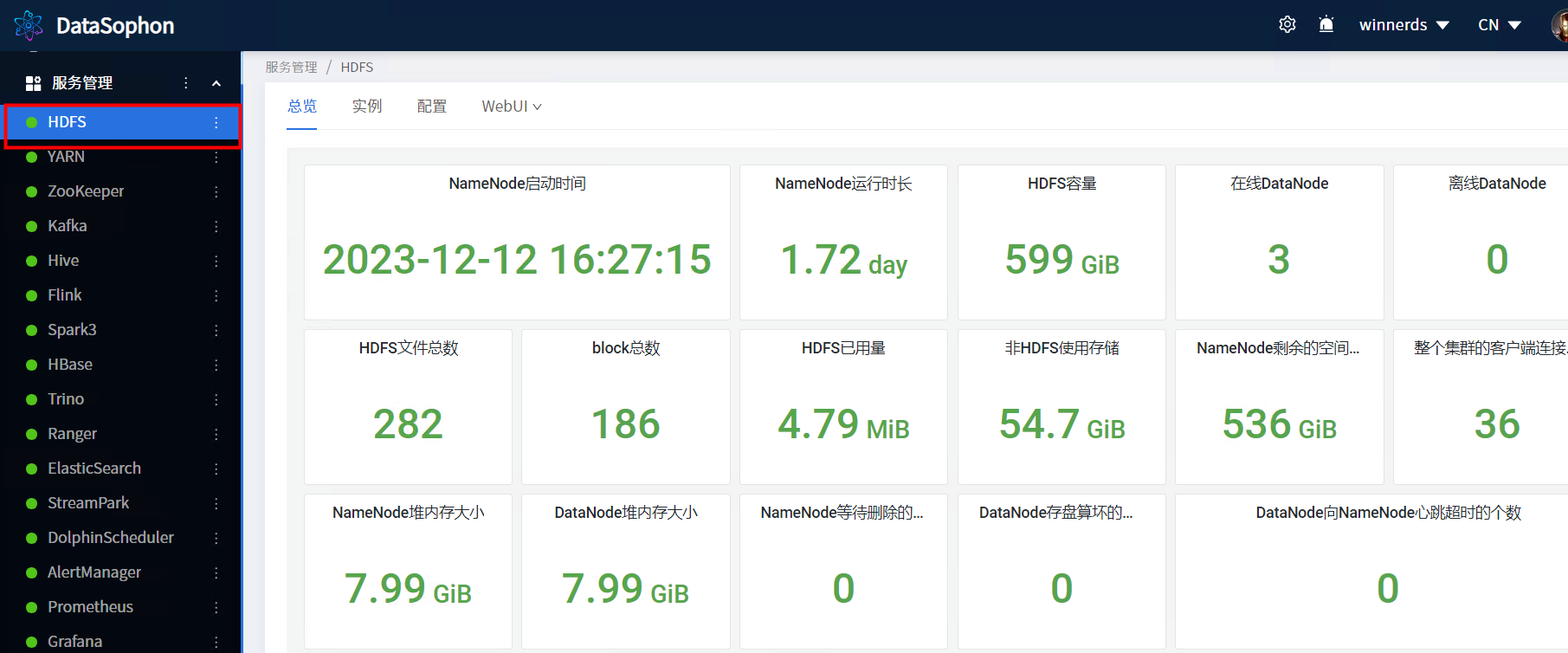
2.1.2 HDFS web 页面

DataNode节点
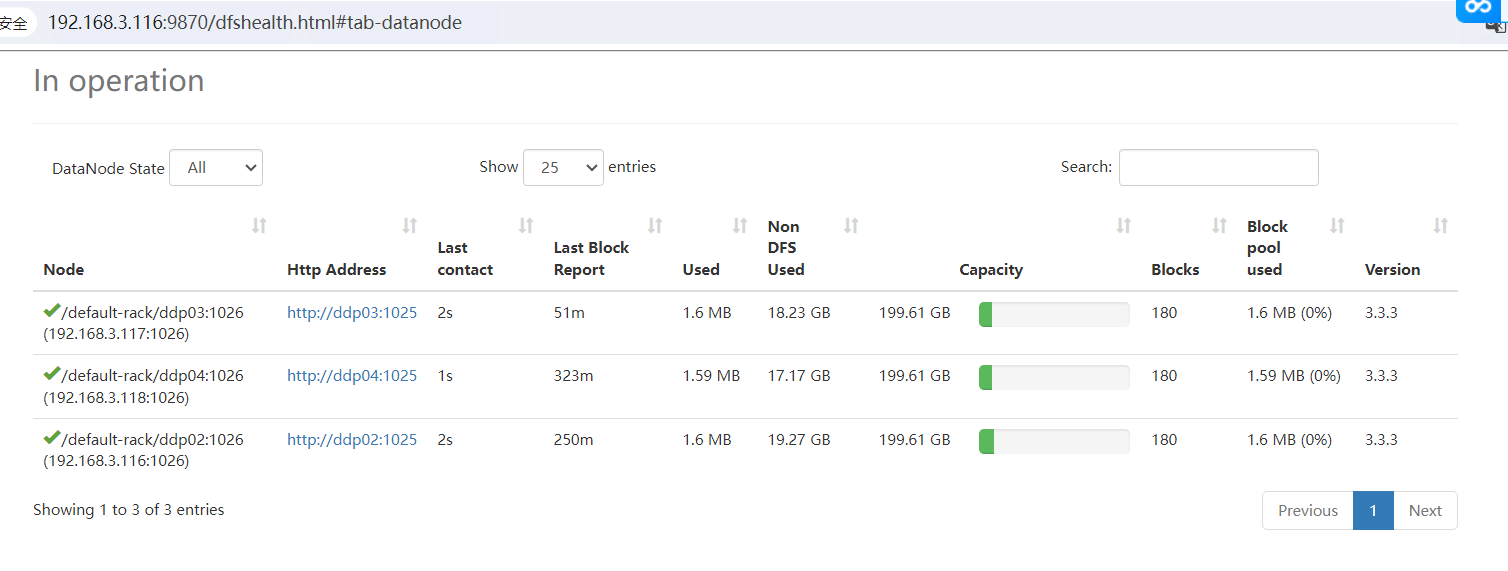
2.1.3 客户端命令
客户端命令先配置下环境变量
[hdfs@ddp01 ~]$ cat ~/.bashrc
export HADOOP_HOME=/opt/datasophon/hdfs/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
创建文件夹/kangll 并上传文件

增加配置
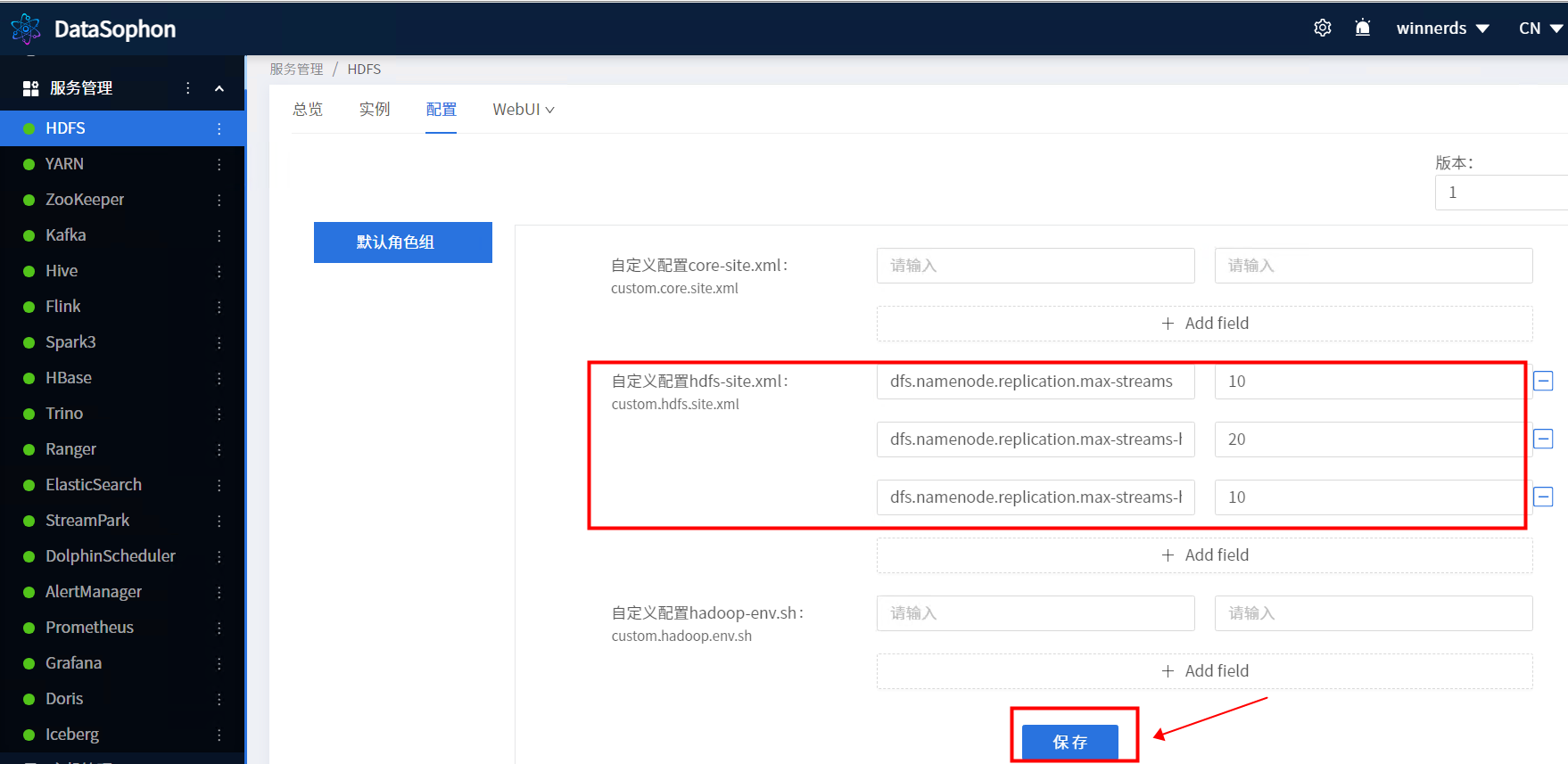
点击小圆圈
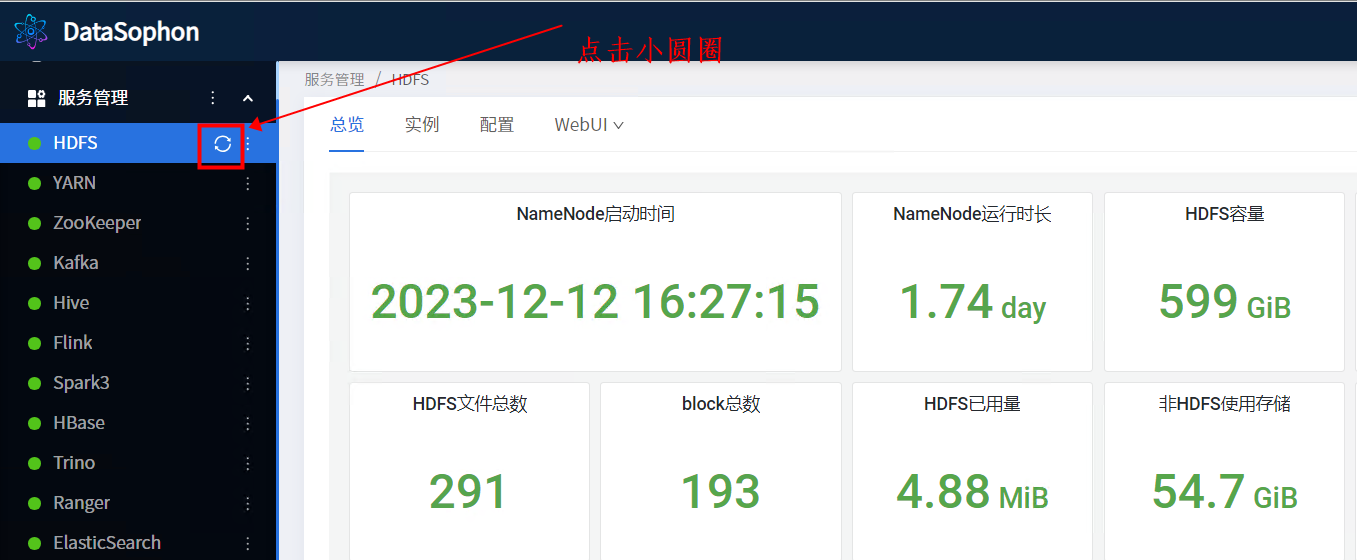
重启需要刷新配置对的服务

等待重启完成

2.2 Hive的使用
2.2.1 总览监控页面

2.2.2 建表
# 进入命令行
hivecreate database kangll;
use kangll;
create table stu(name string);
insert into stu values("kangll");
select * from stu;查询OK

2.3 HBase
2.3.1 总览监控页面
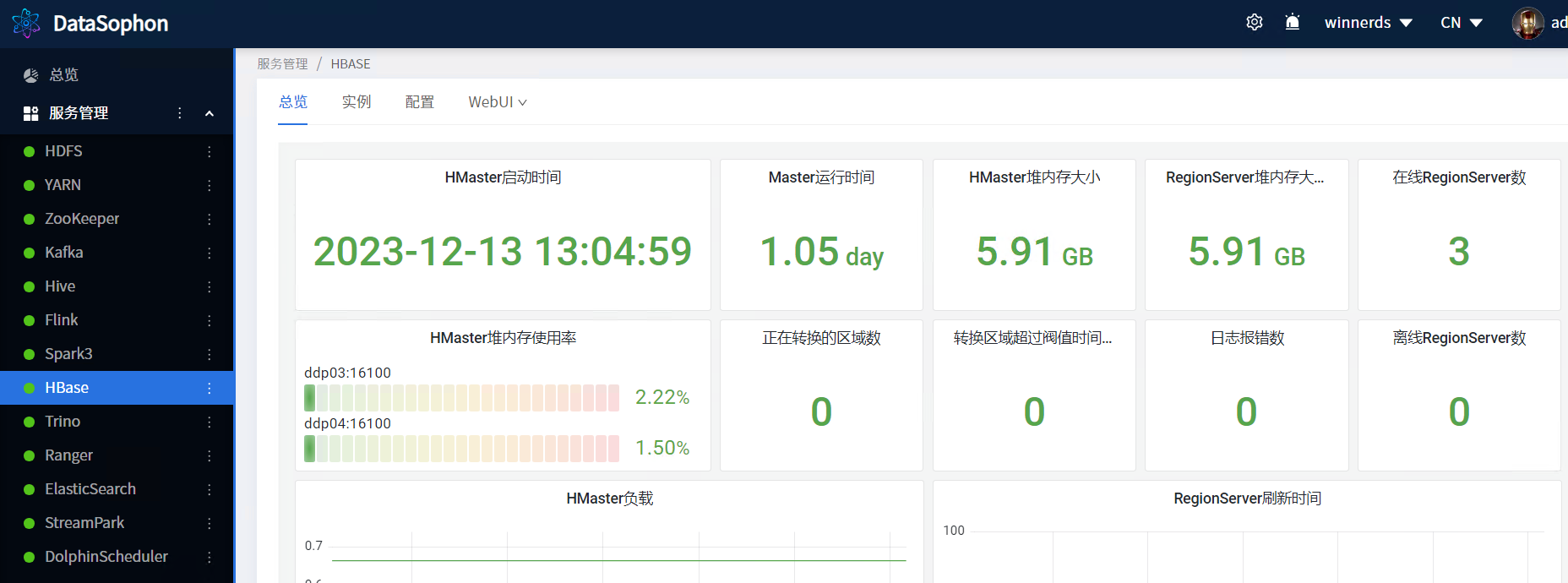
2.3.2 创建表
create 'counter_inout',
{NAME => 'd',VERSIONS => 1,DATA_BLOCK_ENCODING => 'FAST_DIFF',COMPRESSION => 'SNAPPY'},
{NAME => 't',VERSIONS => 1,DATA_BLOCK_ENCODING => 'FAST_DIFF',COMPRESSION => 'SNAPPY'},
{SPLITS=> ['1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}报错如下:
ERROR: org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'snappy' previously failed test. Set hbase.table.sanity.checks to false at conf or table descriptor if you want to bypass sanity checksat org.apache.hadoop.hbase.util.TableDescriptorChecker.warnOrThrowExceptionForFailure(TableDescriptorChecker.java:337)at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:304)at org.apache.hadoop.hbase.util.TableDescriptorChecker.sanityCheck(TableDescriptorChecker.java:114)at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:2094)at org.apache.hadoop.hbase.master.MasterRpcServices.createTable(MasterRpcServices.java:696)at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:387)at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:132)at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:369)at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:349)
Caused by: org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'snappy' previously failed test.at org.apache.hadoop.hbase.util.CompressionTest.testCompression(CompressionTest.java:90)at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:300)... 8 moreFor usage try 'help "create"'Took 1.0929 seconds添加如下配置解决
hbase.io.compress.snappy.codec org.apache.hadoop.hbase.io.compress.xerial.SnappyCodec
hbase.table.sanity.checks false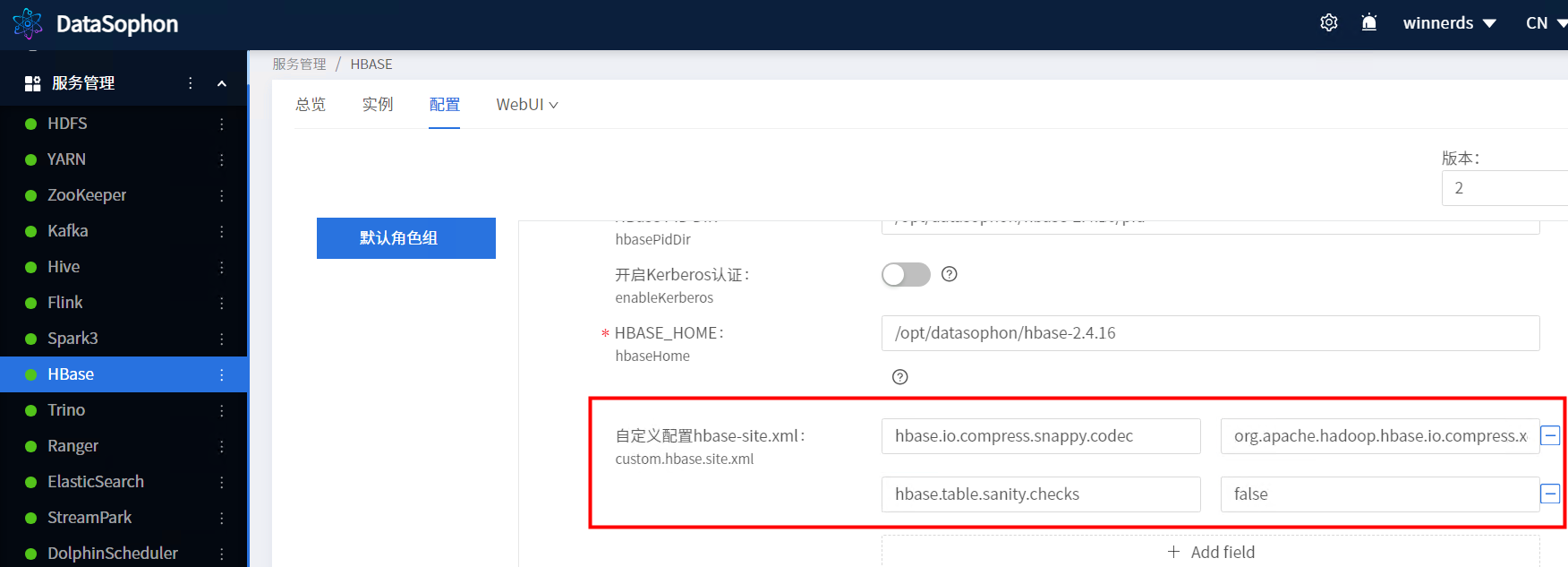
表创建完成后插入数据再进行查询

2.4 Spark
SparkPi 任务运行测试
spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
--executor-memory 1G \
--num-executors 2 \/opt/datasophon/spark3/examples/jars/spark-examples_2.12-3.1.3.jar \
100YARN任务

测试程序执行完成

2.5 DataSophon 添加租户
DataSophon 添加租户

添加成功

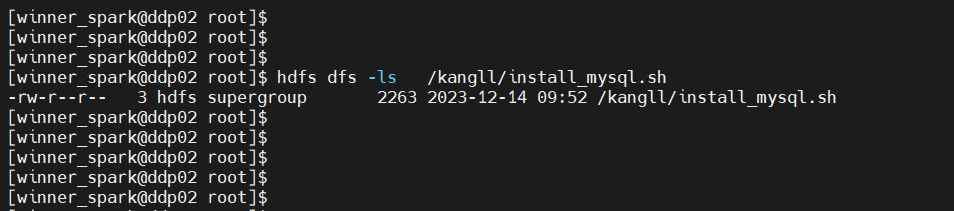
使用winner_spark 查看 HDFS文件

















)

