文章目录
- 背景
- 具体步骤
- 1.环境搭建
- 2.写个demo
- 1.数据处理
- 2.分割数据集
- 3.用模型训练数据,并得到预测结果
- 4.绘制结果
- 5.评估
背景
最近学习了一些关于机器学习的内容,做个笔记。
具体步骤
1.环境搭建
需要用到的工具:pycharm,anaconda
anaconda可以帮助我们创造虚拟的python环境,并在环境当中安装各种所需要的包,而且每个虚拟环境都是互相独立的,非常方便。
我们可以单独创建一个sklearn的环境,用于学习。
在命令行里面打开这个环境,并安装所需要的工具
pip install -U scikit-learn
pip install numpy scipy matplotlib
其中,sklearn集成了常见的一些机器学习的算法,可以让我们直接调用,https://www.scikitlearn.com.cn/。
NumPy可以做一些科学计算,https://www.numpy.org.cn/。
matplotlib是一个绘图工具,可以将我们的计算结果绘制成图形,https://matplotlib.org/。
anaconda环境搭建好了之后,可以在pycharm里面选择使用我们搭建好的python环境,
这样就可以开始愉快的玩耍了。
2.写个demo
这个demo是用线性回归模型预测波士顿的房价,数据库是来源于sklearn框架。机器学习编程都有一定的套路,具体分为以下几步:
1.数据处理
原始的load_boston()获取数据库方法从1.2版本已经被移除,需要使用链接获取。
其中data就是影响房价的因素,如当地的犯罪率,房屋年龄,房屋间数,和就业中心的距离等等,target就是房价。
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
2.分割数据集
我们需要将原始的数据集拆分成训练集和测试集,这里是三七分,当然拆分的比例我们可以自定义。
X = data
y = target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)3.用模型训练数据,并得到预测结果
注意这里,用训练集得到训练模型之后,用测试集的输入得到测试集的预测输出。
LR = LinearRegression()
LR.fit(X_train, y_train)
y_pred = LR.predict(X_test) # 得到预测结果
4.绘制结果
这里我们就可以将原始数据测试集的输出和预测输出做个对比,并绘制成图形。
# x轴为真实的价格,y轴为预测价格
plt.scatter(y_test, y_pred)
plt.xlabel("Real Price")
plt.ylabel("Predicted Price")
plt.title("Real Prices vs Predicted prices")
plt.grid()
# 对比线,越接近y=x这条线,效果越好
x = np.arange(0, 50)
y = x
plt.plot(x, y, color='red', lw=4)
plt.text(30, 40, "predict line")
plt.show()
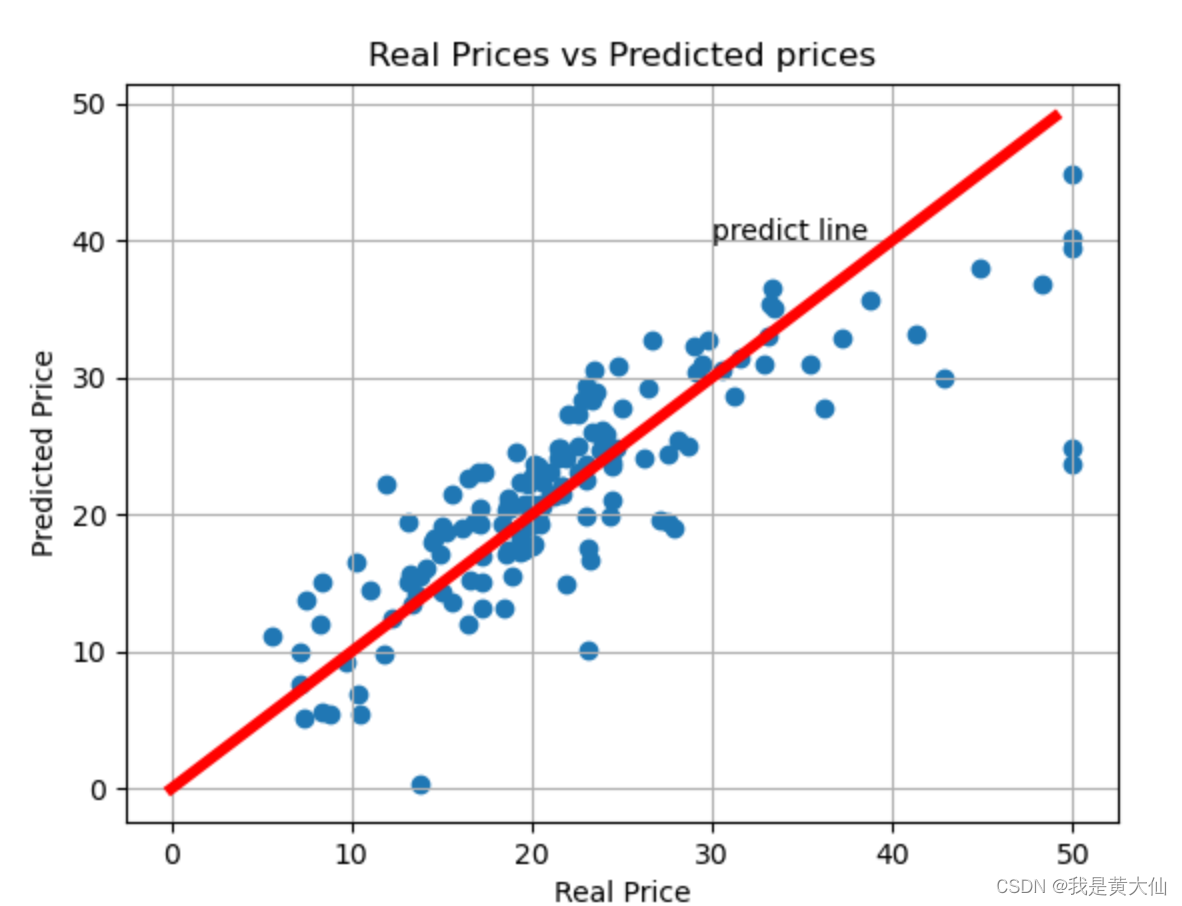
图形如下,其中红色表示y=x的图形,方便我们参考对比。
x轴是真实价格,y轴是预测价格,两个价格越接近,表示我们模型训练得越好。
5.评估
我们还可以用方差来进行评估,方差值越小,表明效果越好
mse = metrics.mean_squared_error(y_test, y_pred)
print(mse)
我们得到方差值为27,看来这个效果比较一般,我们需要考虑使用其他的模型来预测房价。



问题)


)
)











 - 数据绑定高级用法)
