1 包装类
1.1 包装类概述
1.1.1 什么是包装类
在进行类型转换时,有一种特殊的转换:将 int 这样的基本数据类型转换为对象,如下图所示:

所有基本类型都有一个与之对应的类,即包装类(wrapper)。因此,包装类即基本数据类型对应的类。
基本数据类型不能直接参与引用类型的使用或计算,使用包装类将基本数据类型转换为引用数据类型,可以参与到其他引用类型的使用。包装类如下表所示:

包装类中也提供了一些与类型相关的常用方法,可以简化开发者对基本数据类型的操作。
1.1.2 【案例】包装类的赋值示例
编写代码,测试基本数据类型与包装类的相互转换。代码示意如下:
public class WrapperDemo1 {public static void main(String[] args) {int num = 128;//基本类型转换为包装类Integer i1 = Integer.valueOf(num);Integer i2 = Integer.valueOf(num);System.out.println(i1 == i2);//falseSystem.out.println(i1.equals(i2));//trueDouble d1 = Double.valueOf(123.0);Double d2 = Double.valueOf(123.0);System.out.println(d1 == d2);//falseSystem.out.println(d1.equals(d2));//true//包装类转换为基本类型int i = i1.intValue();System.out.println(i);double d = i1.doubleValue();System.out.println(d);byte b = i1.byteValue();System.out.println(b);}
}1.1.3 Number及其主要方法
抽象类 Number 是 Byte、Double、Float、Integer、Long 和 Short 类的父类,它定义了一些公共方法,用于将表示的数值转换为不同的数据类型。下面是 Number 类的主要方法:
- doubleValue():以 double 类型返回表示的数值。
- intValue():以 int 类型返回表示的数值。
- floatValue():以 float 类型返回表示的数值。
这些方法允许将 Number 类的子类对象转换为不同的数据类型,以便在程序中进行数值的操作和处理。
请注意,Number 类本身是一个抽象类,不能直接实例化,而是用作其他数值类的基类。其子类如 Byte、Double、Float、Integer、Long 和 Short 提供了这些方法的具体实现,并为特定类型的数值提供了更多的功能和操作。
使用 Number 类及其子类,您可以执行各种数值计算和转换操作,根据具体的需求将数值对象转换为不同的数据类型。
1.1.4 Integer 常用功能
Integer类提供了多个方法,用于在int类型和String类型之间进行转换,并且还定义了一些常量。下面是一些常用的Integer方法和常量:
- static int MAX_VALUE:该常量的值为231 - 1,表示int类型可以表示的最大值。
- static int MIN_VALUE:该常量的值为-231,表示int类型可以表示的最小值。
- parseInt(String s):这是一个静态方法,用于将字符串转换为int类型的值(前提是字符串必须表示一个整数)。如果字符串不是合法的整数表示形式,会抛出NumberFormatException异常。
下面是一个示例代码,演示了使用parseInt方法将字符串转换为整数的过程:
public void testParseInt() {String str = "123";int value = Integer.parseInt(str);System.out.println(value); // 123str = "壹佰贰拾叁";// 会抛出NumberFormatException// value = Integer.parseInt(str);
}在上述示例中,我们首先将字符串"123"通过parseInt方法转换为整数值123,并成功输出。然后,我们尝试将字符串"壹佰贰拾叁"转换为整数,由于该字符串不是一个合法的整数表示形式,会抛出NumberFormatException异常。
通过使用Integer类的这些方法,我们可以方便地在整数值和字符串之间进行转换,并进行相应的数据处理和操作。
1.1.5 Double常用功能
Double类用于包装基本类型double的值,可以通过构造方法将double类型的值包装成Double对象,构造方法如下:
Double(double value):使用指定的double值创建一个Double对象。
Double(String s):使用指定的字符串表示形式创建一个Double对象。Double类还提供了一些常用的方法,其中包括:
double doubleValue():返回此Double对象的double值。
static double parseDouble(String s):将指定的字符串解析为double值,并返回一个新的double值。这是一个使用Double类的示例代码:
Double num1 = new Double(3.14);
System.out.println(num1.doubleValue()); // 输出:3.14
String str = "2.718";
Double num2 = Double.parseDouble(str);
System.out.println(num2); // 输出:2.718在上述示例中,我们使用构造方法将double类型的值和字符串转换为Double对象。然后,我们通过doubleValue方法获取Double对象的double值,并将其打印出来。另外,我们使用parseDouble方法将字符串"2.718"解析为double值,并将其存储在Double对象num2中。
通过Double类的这些方法,我们可以方便地进行double类型和Double对象之间的转换,以及对double值进行操作和处理。
1.1.6 【案例】包装类的功能示例
以下是一个使用包装类的功能示例代码,测试Integer的最大最小值,并将字符串解析为int和double类型:
package api_02;
public class WrapperDemo2 {public static void main(String[] args) {//获取int最大值?int imax = Integer.MAX_VALUE;System.out.println(imax);int imin = Integer.MIN_VALUE;System.out.println(imin);long lmax = Long.MAX_VALUE;System.out.println(lmax);/** 包装类可以将字符串解析为对应的基本类型* 前提是该字符串正确描述了基本类型可以保存* 的值,否则解析时会抛出解析异常:* NumberFormatException*/String str = "123";int d = Integer.parseInt(str);System.out.println(d);double dou = Double.parseDouble(str);System.out.println(dou);}
}在上述示例中,我们使用Integer.MAX_VALUE和Integer.MIN_VALUE分别获取了int类型的最大值和最小值,并将其打印出来。同样地,我们使用Long.MAX_VALUE获取了long类型的最大值,并将其打印出来。
接下来,我们使用Integer.parseInt()方法将字符串"123"解析为int类型,并将其打印出来。同时,我们使用Double.parseDouble()方法将字符串"123"解析为double类型,并将其打印出来。
通过这个示例,我们可以看到包装类的一些常用功能,包括获取最大最小值和将字符串解析为基本类型的值。这些功能方便了我们在处理数据时进行类型转换和数值获取。
1.1.7 自动拆装箱
自动拆箱和装箱是Java中的特性,用于在基本数据类型和对应的包装类之间进行转换,而无需手动编写转换代码。自动拆箱指的是从包装类对象中获取封装的基本数据类型值的操作,而自动装箱指的是将基本数据类型值封装到对应的包装类对象中的操作。
在 JDK 1.5 及以后的版本中,Java引入了自动拆箱和装箱的机制,使得操作更加方便。通过自动拆箱和装箱,我们可以直接在基本类型和包装类型之间进行赋值和运算,编译器会自动进行类型转换。
下面是自动拆箱和装箱的示例代码:
public class BoxingUnboxingDemo {public static void main(String[] args) {// 自动装箱Integer num1 = 10;Double num2 = 3.14;// 自动拆箱int value1 = num1;double value2 = num2;System.out.println("自动装箱后的值:" + num1 + ", " + num2);System.out.println("自动拆箱后的值:" + value1 + ", " + value2);}
}在上述示例中,我们使用自动装箱将基本类型的值赋给对应的包装类对象,如Integer num1 = 10和Double num2 = 3.14。然后,使用自动拆箱将包装类对象中的值赋给基本类型变量,如int value1 = num1和double value2 = num2。
通过自动拆箱和装箱,我们可以直接在基本类型和包装类型之间进行赋值和运算,而不需要手动进行类型转换。这样的机制使得代码更加简洁、易读,并提高了开发效率。
1.2 大数字类
1.2.1 什么是大数字类
在Java中,基本数据类型中整型最大范围是64位long型整数。但在实际应用中,可能需要存储超过该范围的整型数字,或者对超过该范围的多个整型数字进行计算。例如,在密码学中需要使用512位的整型数字作为密钥。Java中提供了BigInteger类来表示任意大小的整数,提供了BigDecimal类来表示任意大小且精度完全准确的浮点数。
BigInteger和BigDecimal被称为Java中的大数字类,位于java.math包下,两个类均为Number类的子类。大数字类除了可以表示大数字以外,还提供了大数字的各类运算方法,如四则运算、幂运算等。
1.2.2 【案例】BigInteger示例
编写代码,测试BigInteger类的用法。代码示意如下:
package api_02;
import java.math.BigInteger;
public class BigIntegerDemo {public static void main(String[] args) {// 创建BigInteger对象,封装大整数BigInteger i1 = new BigInteger("1234567890");BigInteger i2 = new BigInteger("12345678901234567890");BigInteger result1 = i1.add(i2); // 12345678902469135780System.out.println("result1= " + result1);BigInteger result2 = i1.multiply(i2); // 15241578751714678875019052100System.out.println("result2= " + result2);long l1 = result2.longValue(); // 转换为long类型,超范围会导致精度缺失System.out.println("l1="+l1); // -4871824193159134140// 转换为long类型,超范围会抛出异常long l2 =result2.longValueExact(); // BigInteger out of long range}
}1.2.3 【案例】BigDecimal示例
编写代码,测试BigDecimal类的用法。代码示意如下:
package api_02;
import java.math.BigDecimal;
import java.math.RoundingMode;
public class BigDecimalDemo {public static void main(String[] args) {BigDecimal d1 = new BigDecimal("123.4567");BigDecimal d2 = d1.multiply(d1);System.out.println(d2); // 15241.55677489// BigDecimal用scale()表示小数位数BigDecimal d3 = new BigDecimal("12.34");BigDecimal d4 = new BigDecimal("12.3400");BigDecimal d5 = new BigDecimal("123400");System.out.println(d3.scale()); // 2System.out.println(d4.scale()); // 4System.out.println(d5.scale()); // 0// 可以对一个BigDecimal设置它的scale// 如果精度比原始值低,那么按照指定的方法进行四舍五入或者直接截断BigDecimal d6 = d1.setScale(2, RoundingMode.HALF_UP);BigDecimal d7 = d1.setScale(2, RoundingMode.DOWN);System.out.println(d6); // 123.46System.out.println(d7); // 123.45// 在比较两个BigDecimal的值是否相等时,// 使用equals()方法不但要求的值相等,还要求scale()相等BigDecimal d8 = new BigDecimal("123.456");BigDecimal d9 = new BigDecimal("123.45600");System.out.println(d8.equals(d9));// 应该使用compareTo()比较两个BigDecimal的值System.out.println(d8.compareTo(d9)); // 0 表示相等}
}1.2.4 如何精确处理小数
BigDecimal是Java中的一个类,用于进行高精度的数值计算。它提供了一种精确表示和操作任意精度的十进制数的方式,避免了使用浮点数在精度和舍入误差上可能存在的问题。
下面是一个示例,说明BigDecimal如何比double更准确:
public class BigDecimalExample {public static void main(String[] args) {double num1 = 0.1;double num2 = 0.2;double sum1 = num1 + num2;System.out.println("Sum using double: " + sum1); // 输出结果: 0.30000000000000004BigDecimal decimal1 = new BigDecimal("0.1");BigDecimal decimal2 = new BigDecimal("0.2");BigDecimal sum2 = decimal1.add(decimal2);System.out.println("Sum using BigDecimal: " + sum2); // 输出结果: 0.3}
}在上述示例中,使用double类型进行0.1和0.2的相加,由于浮点数的精度限制,计算结果会产生舍入误差,得到一个略微不准确的结果。而使用BigDecimal进行相加时,精确地表示了0.1和0.2,并得到了准确的计算结果。
这个例子说明了在需要精确计算时,特别是涉及到货币、财务或其他需要准确小数表示的场景时,使用BigDecimal更可靠,避免了浮点数带来的舍入误差。
2 异常
2.1 异常概述
2.1.1 什么是异常
当我们编写程序时,有时会遇到一些意外情况或错误,这些情况超出了我们预期的正常情况。比如,我们可能会在程序中除以零,试图打开一个不存在的文件,或者因为网络问题无法连接到服务器。
int n = 10;int m = 0;int r = n / m; // ArithmeticException: / by zero这些意外情况就被称为异常。当程序遇到异常时,如果异常没有被捕获和处理,程序可能会崩溃或者出现错误的结果。
可以把异常比作现实生活中的意外情况。当你驾驶汽车时,你预期能够平稳地行驶,但如果突然出现了一个障碍物,你就需要采取一些措施来应对这个意外情况,比如刹车或者绕道而行。同样地,程序在执行过程中也会遇到意外情况,需要通过异常处理来应对。
因此,异常可以被认为是程序执行过程中的意外情况或错误,需要通过适当的处理措施来应对,以确保程序能够继续执行或提供适当的响应。
2.1.2 异常类型继承关系
Java中一切都是对象,异常消息也不例外,也是对象。异常对象的类型之间存在继承关系。所有的异常类都是从Throwable类派生而来的。Throwable是Java异常类层次结构的根类,它分为两个主要的子类:Error和Exception。
1. Error类:Error类表示严重的错误,通常是无法恢复的错误,例如内存溢出、系统崩溃等。程序一般无法处理这类错误,因为它们通常表示了底层系统的问题,所以我们不需要在代码中捕获或处理Error。
2. Exception类:Exception类表示一般的异常情况,它又分为两种类型:
- 检查异常(Checked Exception):这些异常在编译时就需要进行处理,否则编译器会报错。受检异常通常表示外部条件的变化或输入错误,例如文件未找到、网络连接中断等。开发者必须在代码中显式地捕获和处理受检异常,或者在方法签名中声明抛出该异常,以便调用方处理。
- 非检查异常(Unchecked Exception):这些异常在编译时不需要进行处理,因为它们通常表示程序内部错误、逻辑错误或者编程错误。非受检异常也称为运行时异常(RuntimeException)。它们可以在代码中捕获和处理,但也可以选择不处理。常见的非检查异常包括空指针异常、数组越界异常等。
异常类之间的继承关系形成了异常类的层次结构。派生自Exception类的异常又可以进一步派生出其他异常类,形成更具体的异常类型。这样的层次结构允许我们在捕获异常时进行精确的处理,以便适应不同的异常情况。
总结起来,Java的异常类型继承关系如下所示:
Throwable
├── Error
└── Exception├── Checked Exception└── Unchecked Exception (RuntimeException)这种继承关系帮助我们理解异常类的分类和处理方式,以便在编写代码时更好地处理异常情况。
2.1.3 Throwable类的API
Throwable类是Java中所有错误和异常的根类,它是Exception和Error类的父类。Throwable类提供了一些常用的API方法,用于处理和获取有关错误和异常的信息。下面是Throwable类的一些常用API方法:
- getMessage():获取异常的详细描述信息。返回一个字符串,描述异常的原因或相关信息。
- getCause():获取导致当前异常的原因。返回一个Throwable对象,表示导致当前异常的异常或错误。
- printStackTrace():打印异常的堆栈跟踪信息。将异常的堆栈跟踪信息输出到标准错误流,用于调试和错误诊断。
- getStackTrace():获取异常的堆栈跟踪信息。返回一个StackTraceElement数组,包含异常发生时方法的调用链信息。
- toString():返回异常对象的字符串表示。通常返回异常类的名称,以及异常的详细描述信息。
总的来说,Throwable类提供了处理和获取异常信息的基本方法,可以帮助开发人员更好地理解和处理错误和异常情况。
2.2 处理异常
2.2.1 try-catch语句块
使用try-catch语句块可以让我们捕获和处理异常,避免程序崩溃或出现不受控制的错误。它使我们能够在程序执行过程中遇到异常时,采取适当的措施,保证程序的正常运行,并提供错误信息或容错机制。这样可以提高程序的健壮性和可靠性,增加用户体验。
try-catch语句块是一种用于处理异常的结构,在Java中被广泛使用。它由两个主要部分组成:try块和catch块。
try块用于包含可能会抛出异常的代码。在try块中,我们可以放置可能会发生异常的语句或代码块。当程序执行到try块时,它会尝试执行其中的代码。
catch块用于捕获并处理try块中可能抛出的异常。如果try块中的代码执行过程中发生了异常,那么异常将被catch块捕获,并根据catch块中的逻辑进行相应的处理。catch块提供了异常处理的代码逻辑。
try-catch语句块的基本语法如下:
try {// 可能会抛出异常的代码
} catch (异常类型1 变量名1) {// 异常处理逻辑1
} catch (异常类型2 变量名2) {// 异常处理逻辑2
} catch (异常类型3 变量名3) {// 异常处理逻辑3
}当程序执行try块中的代码时,如果发生了与catch块中定义的异常类型匹配的异常,那么程序将跳转到匹配的catch块,并执行相应的异常处理逻辑。catch块可以有多个,每个catch块可以捕获不同类型的异常,并提供相应的处理逻辑。
2.2.2【案例】try-catch示例
下面是使用try-catch语句块的示例代码:
public class ExceptionDemo2 {public static void main(String[] args) {System.out.println("程序开始了");Scanner console = new Scanner(System.in);System.out.print("请输入一个字符串:");String str = console.nextLine();str = "null".equals(str) ? null : str;try {// 当字符串为null时,会出现空指针异常System.out.println(str.length());// 当字符串为""时,会出现下标越界异常System.out.println(str.charAt(0));// 当字符串不是数字时,会出现数字格式化异常System.out.println(Integer.parseInt(str));// 当出现异常时,后面的代码不会再执行System.out.println("!!!!!!!");} catch (NullPointerException e) {System.out.println("出现了空指针!");} catch (StringIndexOutOfBoundsException e) {System.out.println("出现了下标越界!");} catch (Exception e) {// Exception是所有异常的父类,所以它能捕获所有异常System.out.println("反正就是出了个错!");}// 异常处理后,程序会继续执行System.out.println("程序结束了");}
}在上述示例中,我们使用了try-catch语句块来捕获可能发生的异常。
在try块中,我们执行了三个可能抛出异常的操作:获取字符串长度、获取字符串的第一个字符、将字符串转换为整数。针对每个可能的异常,我们使用了对应的catch块来捕获并处理异常。在catch块中,我们打印出相应的错误信息。
如果没有发生异常,则try块中的所有代码都会被顺序执行。如果发生了异常,程序会跳转到匹配的catch块,并执行相应的异常处理逻辑。在示例中,我们使用了不同的catch块来处理不同类型的异常,最后一个catch块使用了Exception来捕获所有异常。如果异常没有被任何catch块捕获到,那么程序将终止,并打印出异常的调用栈信息。
无论是否发生了异常,程序都会继续执行try-catch语句块之后的代码,因此在最后打印出"程序结束了"。通过使用try-catch语句块,我们能够在程序执行过程中捕获和处理异常,以确保程序的正常执行,并提供适当的错误信息。
2.2.3 finally语句块
finally语句块在try或catch语句块之后,不论try语句块中是否出现异常,finally语句块中的代码均会被执行。主要用于执行释放资源的逻辑。
根据Java的异常机制,如果某行代码出现异常,Java会自动触发异常机制,跳转到异常处理逻辑中。此时,出现异常的那行代码后面的代码将不会被执行。也就是说,try语句块并不能保证其中的所有代码都被执行。

在一些场景中,一段程序的最后需要执行一些“收尾”操作,例如重置计数器、删除不再使用的数组或集合、关闭流等。如果将这些“收尾”代码写在try语句块的末尾,当出现异常时,这些代码将不会被执行,从而影响程序的正常逻辑或导致资源得不到释放等问题。
为了解决这个问题,Java引入了finally语句块。无论是否发生异常,finally语句块中的代码都会被执行。这样,我们可以将“收尾”代码放在finally语句块中,确保在任何情况下都能执行这些代码,以实现资源的释放和清理操作。
使用finally语句块可以保证在异常处理后进行必要的清理工作或执行其他必要的操作,从而确保程序的一致性和可靠性。
2.2.4【案例】finally示例
下面是使用finally语句块的示例代码:
public class ExceptionDemo3 {public static void main(String[] args) {System.out.println("程序开始了");try {String str = null;System.out.println(str.length());} catch (Exception e) {System.out.println("出错了!");} finally {System.out.println("finally中的代码执行了!");}System.out.println("程序结束了");}
}在上述示例中,我们使用了try-catch-finally结构来处理可能发生的异常。
在try块中,我们执行了一个可能引发空指针异常的操作:获取一个null引用的长度。由于str为null,所以会触发空指针异常。
在catch块中,我们捕获并处理了异常,打印出"出错了!"。
无论异常是否被捕获,finally块中的代码都会被执行。在示例中,我们使用了finally块来打印出"finally中的代码执行了!"。无论try块中的代码是否抛出了异常,这段代码都会被执行,确保了在异常处理后的一致性操作。
最后,在try-catch-finally结构之后,我们打印出"程序结束了"。通过使用finally语句块,我们可以确保在程序执行过程中进行清理工作或执行必要的操作,无论是否发生了异常。
2.2.5 finally的执行时机
finally语句块中的代码一定会被执行,那么它是在什么时间点执行的呢?这个细节常作为面试中的考题出现。例如下列代码中,get()的返回结果应该是多少?
public static int get1(){int a =1;try{return a+1;}finally {a = 3;}
}以上代码中,get1方法的返回结果为2。可以看到,finally代码虽然会被执行,但是在try中的return后面的表达式运算后执行,所以方法返回值是在finally执行前就确定好了。
如果在finally中也增加一个return:
public static int get2(){int a =1;try{return a+1;}finally {a = 3;return a;}
}以上代码中,get2方法的返回结果为3,这里的finally中多了一个return语句,影响了整个方法的返回结果。换句话说,如果finally中也有return语句,那么整个方法的返回结果就是finally中的return的值。
如果在try/catch中JVM突然中断了(如使用了System.exit(0)),那么finally中的代码还会执行吗?
public static void print(){try{System.out.println("try");System.exit(0);}finally {System.out.println("finally");}
}输出结果为:"try"。finally的执行需要两个前提条件:对应的try语句块被执行,程序正常运行。当使用System.exit(0)中断执行时,finally就不会再执行了。
除了我们提到的这种System.exit(0)中断执行的情况,还有几种情况也会导致finally不会执行:
- System.exit()方法被执行
- try或catch语句块中有死循环
- 操作系统强制“杀掉了”JVM进程,如执行了kill -9命令
需要注意的是,这些情况都属于极端情况,通常在正常的程序执行中,finally语句块都会被执行。
2.3 抛出异常
2.3.1 关于抛出异常
抛出异常是指在程序执行过程中遇到错误或异常情况时,由当前代码主动创建并抛出一个异常对象。抛出异常的目的是通知上层调用者或异常处理机制,表明当前代码无法正常处理某个特定情况,需要由上层调用者或异常处理机制来处理。
举例说明一下:
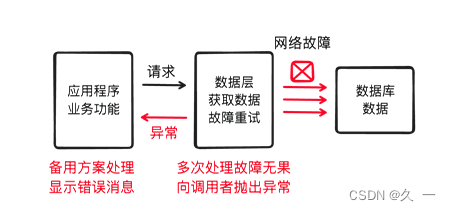
在程序开发中,有时我们需要通过网络或数据库等底层服务获取数据。然而,这些底层服务可能会出现故障,如网络连接断开或数据库不可用等情况。在这种情况下,我们可以使用try-catch块来尝试处理异常,以便在出现故障时采取适当的措施。
通过使用try-catch块,我们可以捕获并处理底层服务可能引发的异常。我们可以在catch块中执行一些恢复操作、记录日志或通知用户等操作,以确保程序的稳定性和可靠性。
然而,有时候尽管我们尝试了多次,底层服务仍然处于故障状态,无法恢复正常。在这种情况下,为了让程序的调用者知道出现了故障,并且进一步处理该情况,我们需要抛出异常。
通过抛出异常,我们将故障信息传递给调用者或上层代码。调用者可以根据异常类型和信息,采取适当的措施,例如提供备用方案、显示错误信息给用户或记录故障报告。抛出异常能够提供更灵活的异常处理方式,并将异常处理的责任交给上层代码。
综上所述,抛出异常的目的是让程序的调用者知晓底层服务的故障情况,并且能够进一步处理该异常。这种异常处理方式可以提高程序的可靠性和容错性,使程序在出现异常时具备更好的应对能力。
2.3.2 throw
当编写 Java 程序时,throw和throws关键字用于处理异常情况,让代码能够更好地应对错误和异常。
throw 关键字的用途:
- throw 关键字用于在代码中显式地抛出一个异常对象。
- 使用 throw 可以在程序中触发异常,表示出现了某种错误或异常情况,需要中断当前的执行流程并传递异常给上层代码。
- throw 关键字通常在方法体内部使用,用于抛出自定义的异常或已有的异常对象。
示例:
public void divide(int dividend, int divisor) {if (divisor == 0) {throw new ArithmeticException("Division by zero");}int result = dividend / divisor;System.out.println("Result: " + result);
}在上述示例中,如果除数为零,则会使用 throw 关键字抛出一个 ArithmeticException 异常对象,表示除以零的错误情况。
2.3.3 throws
throws 关键字的用途:
- throws 关键字用于在方法声明中指定可能会抛出的异常类型。
- 当一个方法可能抛出异常时,可以使用 throws 关键字在方法签名中声明这些异常,以告知方法的调用者可能需要处理这些异常。
- throws 关键字后面跟着的是一个或多个异常类型,用逗号分隔,表示该方法可能会抛出这些异常。
示例:
public void readFile() throws FileNotFoundException {File file = new File("path/to/file.txt");FileInputStream fis = new FileInputStream(file);// 读取文件的代码
}在上述示例中,readFile 方法可能会抛出 FileNotFoundException 异常,所以使用 throws 关键字在方法签名中声明了该异常。这样,调用者在调用该方法时就知道可能需要处理该异常。
需要注意的是,当使用 throws 声明异常时,调用该方法的代码必须对这些异常进行处理,或者继续将异常往上层抛出。处理异常的方式可以是使用 try-catch 块捕获并处理异常,或者在调用者方法中再次使用 throws 声明该异常。
通过使用 throw 和 throws 关键字,我们能够更好地处理异常情况,提高代码的可读性和可维护性,同时为程序提供更好的异常处理机制。
2.3.4【案例】throw和throws示例
下面是一个使用 throw 和 throws 的示例:
public class ExceptionDemo4 {public static void main(String[] args) {try {divide(10, 0);} catch (ArithmeticException e) {System.out.println("捕获到异常:" + e.getMessage());}}public static void divide(int dividend, int divisor) throws ArithmeticException {if (divisor == 0) {throw new ArithmeticException("除数不能为零");}int result = dividend / divisor;System.out.println("结果:" + result);}
}在上述代码中,我们定义了一个 divide 方法,用于进行两数相除的操作。在方法中,我们首先检查除数是否为零,如果是,则使用 throw 关键字抛出一个 ArithmeticException 异常,并提供异常信息。如果除数不为零,那么我们进行除法计算,并打印结果。
在 main 方法中,我们调用了 divide 方法,并使用 try-catch 块捕获可能抛出的 ArithmeticException 异常。如果异常被捕获到,我们输出异常信息。
通过使用 throws 关键字在方法签名中声明 throws ArithmeticException,我们告知调用者,该方法有可能抛出 ArithmeticException 异常,需要进行相应的异常处理。
这个示例展示了如何使用 throw 关键字抛出异常,并使用 throws 关键字声明可能抛出的异常类型。通过这种方式,我们可以在方法内部检测到错误情况,并将异常传递给调用者进行处理
2.3.5 重写方法时的throws规则
在重写方法时,对于方法签名中声明的异常类型,有以下规则:
- 子类重写的方法可以不抛出任何异常,即子类方法可以不使用 throws 关键字声明任何异常。这是因为子类方法可以选择不抛出任何异常,即使父类方法声明了异常。
- 子类重写的方法可以抛出父类方法声明的异常,或者该异常的子类。这被称为异常的协变性。在重写方法时,可以使用与父类方法相同的异常声明,或者使用父类异常的子类声明。
- 子类重写的方法抛出的异常类型不能比父类方法声明的异常类型更广泛(即不能抛出父类方法未声明的异常)。这是因为子类对象可以作为父类对象使用,如果子类方法抛出了更广泛的异常,那么在父类对象引用的场景下,异常处理可能会出现问题。
下面是一个示例,展示了重写方法时 throws 的规则:

总结来说,子类重写方法时的 throws 规则是允许不抛出异常、抛出相同异常或其子类异常,但不能抛出其他异常。这样可以保持异常处理的一致性和可靠性。
2.3.6【案例】重写方法时的throws示例
编写代码,重写方法,并测试其 throws。代码示意如下:
class Parent {public void method() throws IOException {// 父类方法声明了IOException异常}
}
class Child extends Parent {// 子类重写父类方法,可以不抛出异常@Overridepublic void method() {// 不抛出异常}
}
class Child2 extends Parent {// 子类重写父类方法,可以抛出IOException或其子类异常@Overridepublic void method() throws FileNotFoundException {// 抛出FileNotFoundException异常}
}
class Child3 extends Parent {// 子类重写父类方法,不可抛出其他异常,只能抛出父类方法声明的IOException异常@Overridepublic void method() throws IOException {// 抛出IOException异常}
}在上述示例中,Parent 类中的 method() 方法声明了抛出 IOException 异常。子类 Child 可以选择不抛出任何异常,而子类 Child2 可以抛出 FileNotFoundException 异常,因为它是 IOException 的子类。子类 Child3 只能抛出 IOException 异常,不能抛出其他异常。
这个示例展示了在重写方法时的 throws 规则,子类可以选择不抛出异常、抛出相同异常或其子类异常,但不能抛出其他异常。这样可以保持异常处理的一致性和可靠性,同时给程序提供更准确的异常信息。
2.3.7 thorw 和 throws的区别
throw和throws的区别:
- throw关键字用于在代码中显式地抛出异常对象,将异常的处理责任交给调用者,使程序在抛出异常后立即停止执行。
- throws关键字用于方法的声明中,表示该方法可能会抛出指定类型的异常,告知调用者可能需要处理这些异常。
简洁回答:
- throw用于抛出异常对象,使程序立即停止执行。
- throws用于方法声明,表示可能会抛出异常。
总结:
throw关键字用于抛出异常,throws关键字用于方法声明。throw用于具体的异常抛出,而throws用于方法级别的异常声明,告知调用者可能需要处理这些异常。
2.4 自定义异常
2.4.1 什么是自定义异常
自定义异常是指开发者创建的异常类,用于表示特定类型的异常情况。尽管Java提供了许多异常类,但在实际应用中可能需要更多自定义的异常来适应特定的业务需求。例如,在进行数据操作时,可能会遇到错误的数据,这些错误的数据出现时应该抛出异常,比如AddException。然而,Java并没有提供这样的异常类,所以需要开发者自己创建一个自定义的异常类来满足需求。通过自定义异常,开发者可以更精确地描述和处理特定的异常情况,提高代码的可读性和可维护性。

2.4.2 创建自定义异常
创建自定义异常通常涉及以下步骤:
1. 创建一个继承自Exception或RuntimeException的子类。根据异常的性质和场景选择合适的父类。如果希望自定义异常是受检异常,应继承Exception类;如果希望自定义异常是非受检异常,应继承RuntimeException类。
2. 在自定义异常类中,给类起一个明确的名称,反映该异常所代表的特定异常情况。命名应具有描述性,能够清晰地表达异常的含义,方便其他开发者理解和使用。
3. 在自定义异常类中,通常需要显式声明构造函数。构造函数可根据需要接受参数,并使用super关键字调用父类对应参数的构造函数。这样可以确保在创建自定义异常对象时,父类的属性得到正确的初始化。
通过以上步骤,开发者可以创建自定义异常类,用于表示特定的异常情况。自定义异常类可以提供更具体和明确的异常信息,使异常处理更加精确和灵活。同时,自定义异常类也可以帮助其他开发者更好地理解和处理代码中的异常情况。

2.4.3 【案例】自定义异常示例
下面是一个创建自定义异常的示例代码:
// 自定义异常类
class MyCustomException extends Exception {public MyCustomException(String message) {super(message);}
}
// 使用自定义异常类的示例
class MyClass {public void performOperation(int value) throws MyCustomException {if (value < 0) {throw new MyCustomException("值不能为负数");}// 执行其他操作}
}
// 在主程序中捕获和处理自定义异常
public class CustomExceptionExample {public static void main(String[] args) {MyClass myObject = new MyClass();try {myObject.performOperation(-5);} catch (MyCustomException e) {System.out.println("捕获到自定义异常:" + e.getMessage());}}
}在上述示例中,我们创建了一个名为UsernameCannotBeNullException的自定义异常类,它继承自Exception类。在UserRegistration类的registerUser方法中,如果传入的用户名为null或为空字符串,就会抛出UsernameCannotBeNullException异常。在主程序中,我们通过try-catch语句块捕获并处理自定义异常,打印出异常的消息。
这个示例展示了如何根据特定的业务需求创建自定义异常,并在代码中抛出和处理这个异常。这样可以提高代码的可读性,让异常信息更加明确,帮助开发人员快速定位问题。

)

)










)


)

