1.transformer的encoder运作
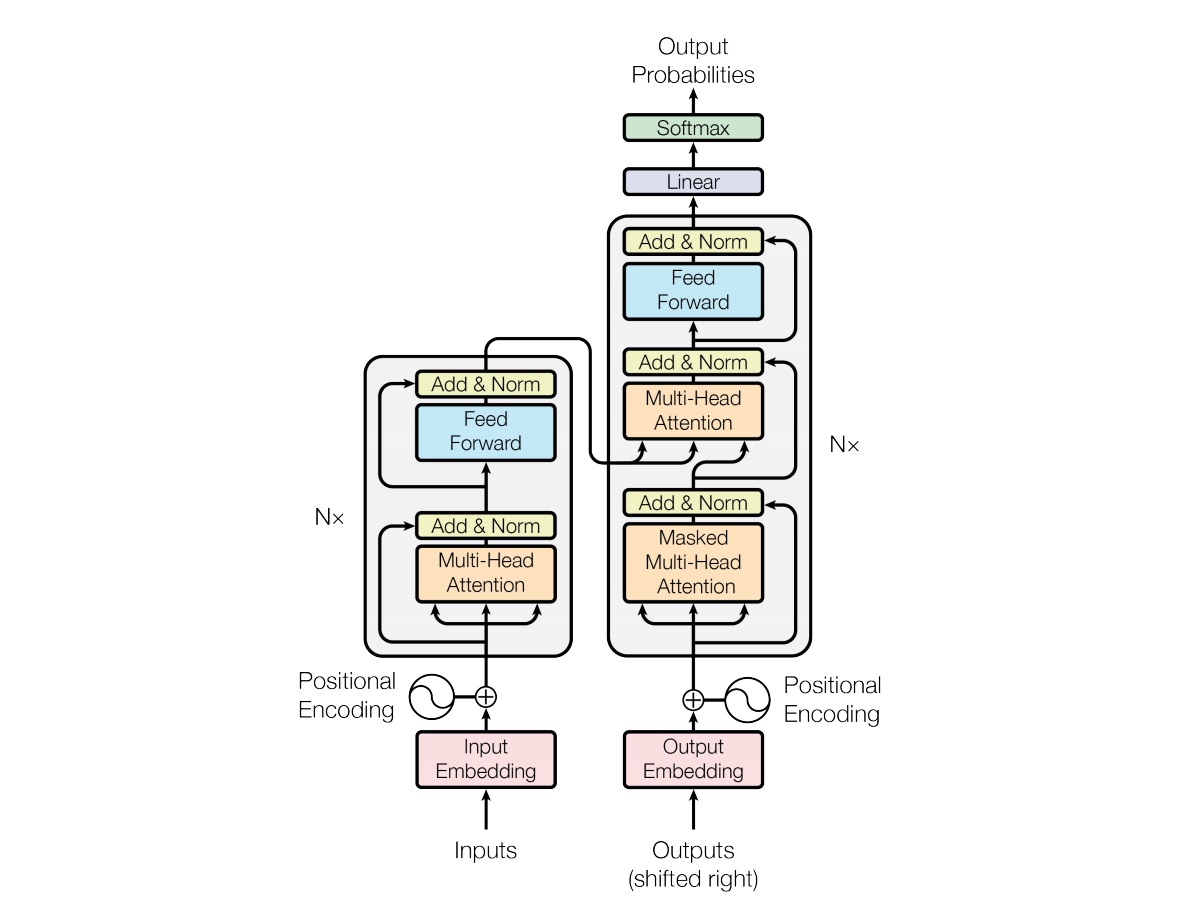
transformer的encoder部分包括了输入和处理2大部分。首先是输入部分inputs,这里初始的inputs是采用独热向量进行表示的,随后经过word2vec等操作把独热向量(采用独热向量的好处就是可向量是正交的,可以采用矩阵乘法来快速的计算向量之间的相似度)转变成了稠密向量(解决了高纬矩阵稀疏的问题,同时还可以用向量之间的距离来表示词与词之间关系的远近)。当然转换过程就是由独热向量乘上一个W矩阵,这个W矩阵就是由w2v训练得到的。W的行数等于独热向量的维度,W的列数则是期望的稠密向量每个字的维度。
不采用直接输入独热向量的原因是,独热向量的效果和稠密向量的是一样的,但是会增加网络的参数。

随后是给输入添加位置信息,之所以要添加位置信息是因为transformer中采用的自注意力机制是没有考虑到每个词之间的位置信息,而位置信息往往又是非常重要的,就比如:我欠他100W 和 他欠我100W。这两句话的意思一个地狱一个天堂。那么具体具体做法就是让变成稠密向量的输入input embedding直接加上一个相同维度大小的(一般都是512维)位置向量ei。并且ei的值也是提前确定的,并不需要通过数据学习得到。
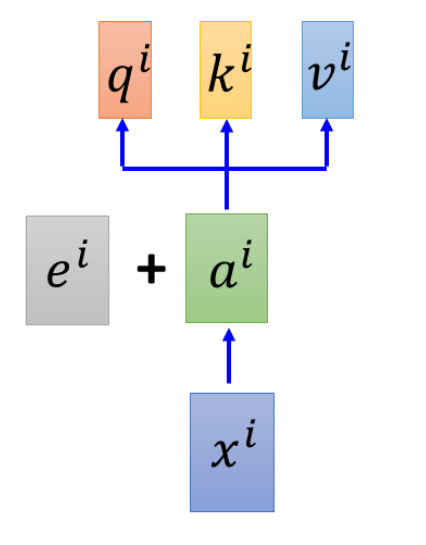
之后便是让添加了位置信息的输入向量(多个向量)经过一个多头注意力机制得到新的一排向量,然后采用残差机制,把新的一排向量加上原来的输入向量(这里可以设置权重调整添加的程度)。这里之所以采用残差机制,就是为了防止在训练过程中发生退化的问题,也就是残差机制存在的意义。可以自行查询残差机制的作用~随后把输入向量进行层归一化。层归一化的操作就是计算一个样本中所有维度的平均值和标准差,然后每个维度的值减去平均值除以标准差。层归一化的意义在于加快训练速度和提高训练的稳定性。注意Add&Norm是先残差机制再层归一化。
最后把新的一排向量输入到全连接神经网络中,并经过Add&Norm操作得到encoder的输出。其中全连接神经网络先是一个线性变换抬高向量的维度,然后一个激活函数进行非线性变换,最后再是线性变换降低维度。
2.transformer的decoder运作
decoder的输入有2种,根据输入的不同可以分为自回归模式和非自回归模式。
(1)自回归模式
自回归模式的decoder在训练的时候采用教师强制模式。它会首先输入一个BOS符号(同样先用独热编码然后转成稠密向量表示,并添加位置信息),然后经过一个掩码注意力机制后,经过Add&Norm操作。所谓的教师强制模式就是无论BOS对应的输出是什么,decoder的下一个输入都是正确的数据集,而不采用decoder的输出,这是为了防止错误传播。而采用掩码注意力机制,则是防止训练的时候受到真实数据的影响,即参数更新时不受影响。
掩码多头注意力机制:
对于一排向量的qkv,第一个向量的q只能与自己的k相乘得到a,然后a乘v得到新的向量;第二个向量的q只能与第一个和自身相乘。即掩码注意力机制就是在训练时只能依赖当前时刻以及之前的信息,而不能看到未来的信息,所以需要把当前时刻后面的信息掩盖掉。

(2)非自回归模式
这种就是一次性输入固定长度个BOS,然后一次性得到对应的输出。

在经过掩码注意力机制以及第一个Add&Norm操作后,来到了cross attention部分,在图中写的是多头注意力机制,但是也被称为cross attention。
(3)cross attention
这里的cross attention之所以是交叉,就是因为q向量来自于decoder的第一个Add&Norm操作后的一排向量,乘一个新的Wq矩阵得到的,而k,v向量则来自于encoder的输出向量乘上新的Wk和Wv矩阵得到的,然后q向量对k相乘加上v向量得到新的输出向量。最后得到同样长度的新的向量
之后同样经过一个全连接网络,以及第二个Add&Norm操作。到这里的话整个decoder部分就运作完了。总结一下就是根据不同的输入,给出不同的输出向量。如果是自回归模式,那么输出会是w1,w1+w2,w1+w2+w3······。如果是非自回归模式,那么输出会是一排向量。
3.transforme的完整运作机制-以文字生成为例
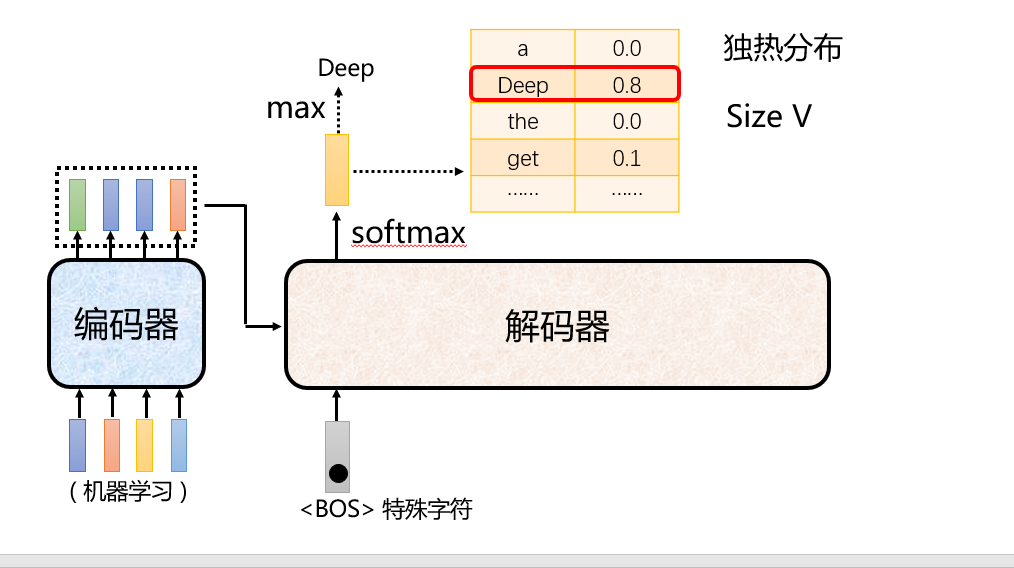
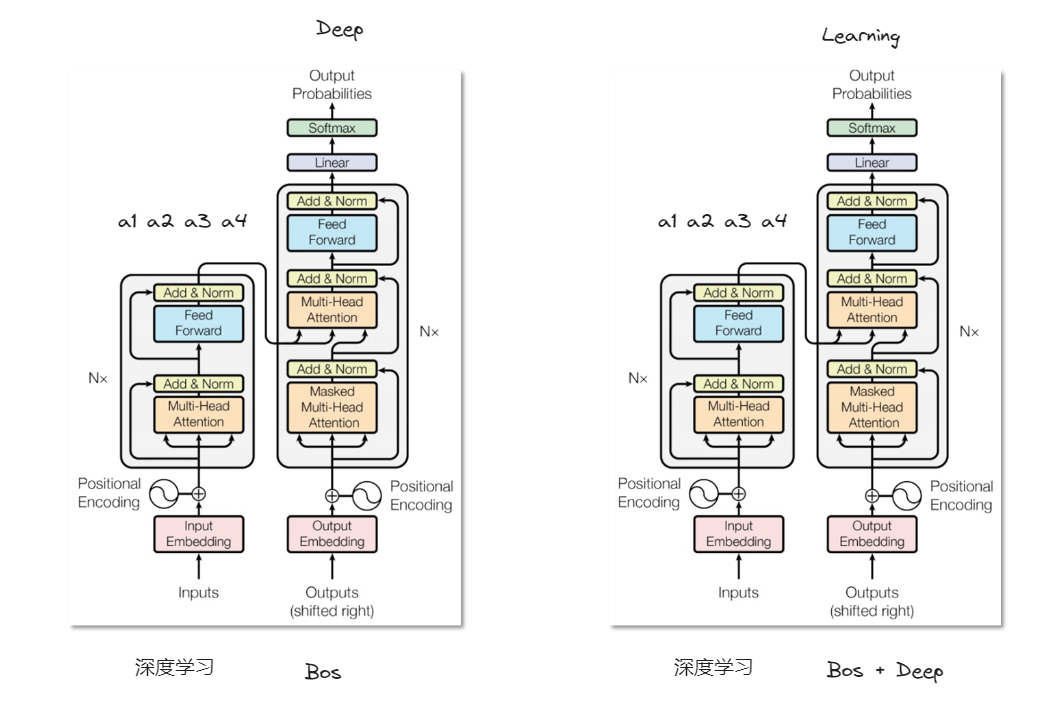
以翻译为例,自回归模式。训练数据集是“深度学习-Deep learning”。encoder的输入是深度学习的独热编码,经过encoder block后得到4个词向量。同时decoder的输入是bos的独热向量,在cross attention部分bos的词向量会得到q,结合深度学习的词向量的kv,重新得到一个新的bos的词向量。然后经过一个全连接网络和一个Add&Norm操作后,decoder block就结束了。最后是整个transformer的输出部分。

输出的bos的词向量先经过一个线性层,然后经过softmax归一化得到概率分布,再结合词典找出概率最大的位置对应词典中的词。得到Deep一词。
第二次的输入是Bos + Deep,同样经过decoder后得到2个词向量,经过线性层后变为1维,最后经过softmax得到概率最大的词是learning。最后下一个输出是End则结束文字生成。













)
 2024中文绿色无需激活版下载)
)

)

