用户向程序输入数据,程序分析数据,但是当用户的输入大于缓冲区长度时,数据会溢出,覆盖掉内存中其他内容,比如函数返回地址,从而可能导致程序返回到错误的地址执行了不安全的程序(远程代码执行)——蠕虫病毒
类型错误:有符号变成无符号而没有标识
动态分析:只有在发生了才能检测到错误
Valgrind检测内存错误:依赖输入,通过检测只代表当前输入下没问题
模糊检测:Valgrind和其他程序结合,产生大量输入测试
静态分析:不运行代码,判断是否会停机、退出或出错

Rust的最终目的是进行一些静态分析,从而检测安全问题
Program Analysis
Valgrind的作用是实时修补程序编译产生的汇编代码,在Valgrind下运行这些汇编代码时,调用malloc之类内存分配函数时会被替换成Valgrind内部的内存分配函数,以做到观察内存情况。可以在没有源代码的情况下分析程序
sanitizer:在源码中插入代码进行检测,可以获得更多的信息
模糊检测:分为盲目模糊检测和基于覆盖率的模糊检测
基于覆盖率的模糊检测:通过不断地执行代码画控制流图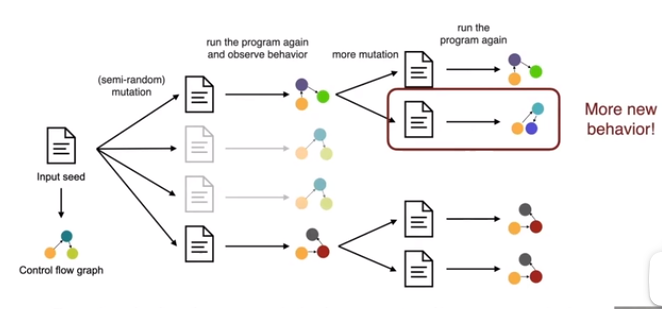
linting:通过找到可能导致重大后果的明显错误来检测代码,如用户输入时调用的gets函数,代码检测器的持续反馈
数据流分析:识别数据在可能的执行路径中的情况,常用于检测变量是否初始化和是否释放内存
活性分析:检测程序某一点的变量是否拥有内存,并持续阅读源代码,超过作用域前是否还没释放内存

Memory Safety
所有权:哪一部分代码负责分配内存,哪一部分代码负责释放该内存,这样就能将统一类内存统一管理,而不会造成内存泄漏
前置条件和后置条件:如内存由谁来分配(前置条件),分配后使用,使用后由谁来释放(后置条件)
使用更好的类型系统来实际制定我们在代码中的意图(前置条件和后置条件),以便编译器能理解,从而在编译过程中检查是否满足——Rust
# rust命令行编译
rustc xxx.rs
# cargo创建项目
cargo new xxx
# cargo构建项目
cargo build
# cargo编译执行
cargo run
fn main(){let julio = "hello".to_string();//julio有字符串的所有权let ryan = julio;//所有权转移到ryan上,julio失去所有权println!("{}", ryan);//正常println!("{}", julio);//错误:error[E0382]: borrow of moved value: `julio`
}
Rust中的值只有一个所有者,每个值当到达作用域边界时就根据所有者释放它,
借用:类似于引用、起别名,但不会改变所有权归属
fn main(){let julio = "hello".to_string();//julio有字符串的所有权let ryan = &julio;//所有权还在julio上,ryan借用println!("{}", ryan);//正常println!("{}", julio);//正常
}
Error Handling
Rust在编译期使用特有的所有权模型,自动调用free,而到了执行期,与c相同,所以没有性能下降
fn main(){let s = String::from("hello");//不可变,常量s.push_str(" world");//错误:error[E0596]: cannot borrow `s` as mutable, as it is not declared as mutable
}fn main(){let mut s = String::from("hello");//mut关键字,可变s.push_str(" world");//正常
}
fn func(s: String){println!("{}", s);
}fn main(){let s = String::from("hello");func(s);//将字符串的所有权交给func函数,s不再有所有权func(s);//此时s没有所有权,错误,通过传递引用解决
}
Rust强制你清晰地表达你的意思,从而使编译器捕获之前无法捕获的错误
可变引用和不可变引用:
Rust的引用规则为:
- 在作用域中的数据有且只能有一个可变引用;
- 可以有多个不可变引用;
- 不能同时拥有不可变引用和可变引用。
//println!不是简单的读数据,更类似使用数据
fn main(){let s = String::from("hello");let s1 = &mut s;//可变引用,相当于一个写线程,错误,因为不能从一个不可变常量中获取可变引用let s2 = &s;//不可变引用,相当于一个读线程println!("{} {} {}", s, s1, s2);
}fn main(){let mut s = String::from("hello");let s1 = &mut s;//可变引用,相当于一个写线程println!("{} {}", s, s1);//错误,因为不能同时通过同一个值的两个可以修改值的量来使用值
}fn main(){let mut s = String::from("hello");let s1 = &mut s;println!("{}", s);//错误,使用值,之后s1会使用,但是可能导致s使用失效(身为所有者)println!("{}", s1);
}fn main(){let mut s = String::from("hello");let s1 = &mut s;println!("{}", s1);//正确,因为在定义s1和使用s1间,s没有使用值,所以s1直接使用值是安全的println!("{}", s);//正确,s1使用完了s才使用(线程安全)
}拒绝服务攻击:如内存不够或分配失败,memcpy拷贝到内存非法的地方
空值给程序员带来了巨大的负担,需要不断跟踪,如果有空值可能是因为资源分配问题,或是仅仅表示一种状态
Rust通过引入Option类型来解决空值的含义模糊问题
fn option() -> Option<String>{if random_num() > 10{Some(String::from("bigger than 10"))}else{None}
}fn main(){if option().is_none(){println!("less than 10");}
}fn main(){let message = option().unwrap_or(String::from("less than 10"));//message为some或为给出的默认值
}fn main(){match option(){Some(message) => {println!("get message:{}", message);},None => {println!("don't get message");}}
}
Object Oriented Rust
Rust中的几乎所有内容都是一个表达式。 表达式是返回值的东西。 如果输入分号,则会抑制该表达式的结果,在大多数情况下,这就是您想要的结果。 另一方面,这意味着如果您使用不带分号的表达式结束函数,则将返回最后一个表达式的结果。 match 语句中的块也可以使用相同的内容。 您可以在其他任何需要值的地方使用不带分号的表达式。
自动解引用:
fn main(){let x: Box<u32> = Box::new(10);println!("{}", *x);//输出10
}
链表结构体:
struct Node{value: u32,next: Option<Box<Node>>,//Box是指向堆上对象的指针,使下一个Node在堆上分配,从而保证指向的Node能在需要的时候存在,而Option的None表示结束链表
}struct LinkList{head: Option<Box<Node>>,size: usize,
}//实现Node
impl Node{//公共函数pub fn new(value: u32, next: Option<Box<Node>>) -> Node{//构建NodeNode{value: value, next: next}//不加分号,返回构建的Node}
}//实现链表
impl LinkList{pub fn new() -> LinkList{LinkList{head: None, size: 0}}pub fn get_size(&self) -> usize{//(*self).size//显式解引用指针self.size}pub fn is_empty(&self) -> bool{self.get_size() == 0}pub fn push(&mut self, value: u32){let node: Box<Node> = Box::new(Node::new(value, self.head.take())); //take()从中取出值,在其位置留下None self.head = Some(node);//头插法self.size += 1;}pub fn pop(&mut self) -> Option<u32>{let node :Box<Node> = self.head.take()?;//函数返回Option,如果右式为None就直接返回Noneself.head = node.next;self.size -= 1;Some(node.value)}
}
fn main(){let mut list: LinkList = LinkList::new();assert!(list.is_empty());assert_eq!(list.get_size(), 0);for i in 1...10{//[1, 10)list.push(i);}println!("{}", list.pop().unwrap());
}
Traits and Generics
Traits:用于显示、拷贝、迭代器、比较等
//覆盖默认Drop,
impl Drop for LinkList{//链表的Drop特征,当链表超过作用域时调用删除fn drop(&mut self){let mut current = self.head.take();while let Some(mut node) = current{//覆盖了原来的前结点,此时前结点无所有者,释放current = node.next.take();//拿走下一个}}
}
print!("{:?}", x);//输出x的调试版本
#[derive()]是 Rust 编程语言中的一个属性(attribute),用于自动为结构体(struct)或枚举(enum)实现特定的 traits(特性)。Traits 定义了类型可以实现的行为,使用#[derive()]属性可以让编译器为我们生成实现这些 traits 所需的代码。
#[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord)]
struct Point {x: f64,y: f64
}impl Point{pub fn new(x: f64, y: f64){Point{x: x, y: y}}
}fn main() {let origin = Point::new(0.0, 0.0);let mut p = origin;// copy语义,产生一个新的Pointprint!("{:?}", p);//Debug}
PartialEq 和 Eq这两个 Traits 的名称实际上来自于抽象代数中的等价关系和局部等价关系,实际上两者的区别仅有一点,即是否在相等比较中是否满足反身性(Reflexivity)。
实现 Eq 的前提是已经实现了 PartialEq,因为实现 Eq 不需要额外的代码,只需要在实现了PartialEq 的基础上告诉编译器它的比较满足自反性就可以了。
自定义train:
#[derive(Debug, Clone, PartialEq)]
struct Point {x: f64,y: f64
}impl Point{//new需要指定-> Self,它只表示当前类型(Point)pub fn new(x: f64, y: f64) -> Self{Point{x: x, y: y}}
}pub trait ComputeNorm{//默认实现fn compute_norm(&self) -> f64 {0.0//默认返回0.0}
}//Point实现的ComputeNorm
impl ComputeNorm for Point {fn compute_norm(&self) -> f64 {(self.x * self.x + self.y * self.y).sqrt()}
}impl ComputeNorm for Option<f64> {}//使用默认实现fn main() {let some_point = Point::new(3.0, 4.0);print!("{}", some_point.compute_norm());//输出5
}
impl Add for Point {type Output = Self;//关联类型,这里说明输出的类型和自身类型相同fn add(&self, other: Self) -> Self {Point::new(self.x + other.x, self.y + other.y)}
}
泛型:
pub enum MyOption<T> {SUNTHIN(T),MUTHIN
}
pub struct MatchingPair<T> {first: T,second: T
}impl<T> MatchingPair<T> {pub fn new(first: T, second: T) -> Self {MatchingPair {first: first, second: second}}
}//实现MatchingPair的Display,当泛型T实现了fmt的Display方法(约束)
impl fmt::Display for MatchingPair<T> where T: fmt::Display{fn fmt(&self, f: &mut fmt::Formatter<`_>) -> fmt::Result {write!(f, "({}, {})" self.first, self.second)//可以自由地写泛型类型的数据而不用单独实现}
}
Smart Pointers
impl<T: Clone> Clone for MatchingPair<T> {fn clone(&self) -> Self {MatchingPair::new(self.first.clone(), self.second.clone())}
}
trait组合:
//保证既能比较又能打印
fn print_min<T: fmt::Display + ParialOrd>(x: T, y: T) {if x < y {println!("{}", x);} else {println!("{}", y);}
}
Rc< T >:引用计数指针,只能处理不可改变的堆内存块。允许多个不可变引用,可能导致循环引用问题
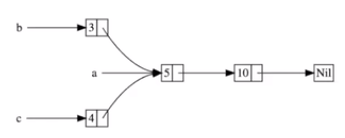
use std::rc::Rc;struct LinkedList {head: Option<Rc<Node>>,size: usize
}impl LinkedList {pub fn push_front(&self, value: u32) -> Self {let new_node = Rc::new(Node::new(value, self.head.clone());LinkedList {head: Some(new_node), size: self.size + 1}}
}
fn main() {let list: LinkedList = LinkedList::new();let version1 = list.push_front(10);let version2 = version1.push_front(5);let version3 = version2.push_front(3);println!("{}", version1);//10println!("{}", version2);//10 5println!("{}", version2);//10 5 3
}
RefCell< T >:内部可变性,可变地借用一个不可变的值,允许我们在只持有不可变引用的前提下对数据进行修改。
借用检查的工作仅仅是被延后到了运行阶段,如果违反了借用规则,还是会触发panic!(更高的运行成本)
常用形式 Rc< RefCell< T > > 用于指向同一数据块的多个指针,如双向链表
Pitfalls in Multiprocessing
多线程:僵尸线程,即未被回收的线程
int func_that_might_fail(){pid_t pid1 = fork();if (pid1 == 0) {printf("1");return 0;}
}int main(){func_that_might_fail();pid_t pid2 = fork();if (pid2 == 0) {printf("2");return 0;}
}
命令:可以理解成就是一个子进程,该子进程执行一个命令
let output = Command::new("ps").args(&["--pid", &pid.to_string(), "-o", "pid= ppid= command="]).output()//输出到缓冲区,父进程阻塞,等待子进程完成并返回内容,用于调用外部二进制文件并等待执行完成.expect("Failed to execute subprocess")//执行子进程let status = Command::new("ps").args(&["--pid", &pid.to_string(), "-o", "pid= ppid= command="]).status()//状态,同output,不过不改变子进程标准输出位置(父进程是啥它就是啥),返回退出状态码.expect("Failed to execute subprocess")//执行子进程let child = Command::new("ps").args(&["--pid", &pid.to_string(), "-o", "pid= ppid= command="]).spawn()//产生,分支子进程,返回子进程的句柄,可用来让子进程等待let status = child.wait().expect("Failed to execute subprocess")//执行子进程
预执行函数:在子进程创建后和执行前由父进程执行的函数
use std::os::unix::process::CommandExt;let cmd = Command::new("ls");//创建
unsafe {cmd.pre_exec(function_to_run);//执行预执行函数
}
let child = cmd.spawn();//子函数执行
应安排一个新管道来连接父子进程
let mut child = Command::new("cat").stdin(Stdio::piped()).stdout(Stdio::piped()).spawn()?;
child.stdin.as_mut().unwrap().write_all(b"Hello, world!")?;
let output = child.wait_with_output()?;
Pitfalls in Signal Handling

使用sigaction.sa_mask可以保证处理信号时又来的信号阻塞,父进程执行waitpid等待所有子进程执行完才使用sigchld_count打印,安全
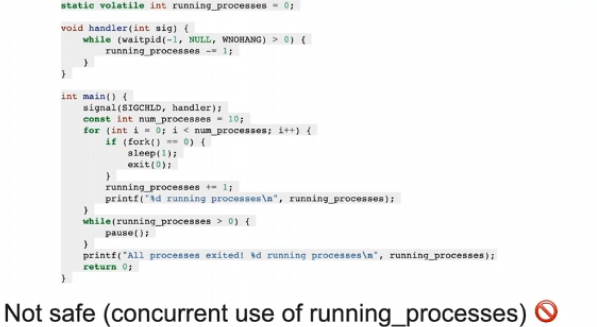
子进程进行waitpid等待会导致死锁

printf会使用锁flock()将标准输出锁住,当你调用printf且已经获得了锁的时候,来了个信号,你转去处理信号,handler调用printf,此时再flock()会发现输出已经被锁住了,等待,死锁
不在处理程序中完成工作,而是在拦截信号中完成,通过设置全局变量来指定handler是否完成工作,从而来让main完成
自管道:和自己通信的管道,main只需要不停读管道,而handler负责将信号写入管道,但是无法同时读/写管道。使用线程或非阻塞IO
Rest没有内置信号处理,需要依赖外部库ctrlc crate,它使用了自管道和多线程
多线程进行信号处理打印是安全的:因为在handler中打印被阻塞时main不会停住,而是继续打印,然后释放锁,handler打印
线程和信号处理程序具有相同的并发性问题但是代码的调度是完全不同的
- 线程:多个(通常)等优先级的执行线程在处理器上不断交换可以使用锁来保护数据
- 信号处理程序:处理程序将完全抢占所有其他代码并占用CPU,直到它完成不能使用锁或任何其他同步原语实际上,信号处理程序应该避免各种阻塞!(为什么?)
因此,信号处理程序对库代码(比如printf)的处理非常糟糕。库不知道您安装了什么信号处理程序,也不知道这些信号处理程序做什么,因此它们不能禁用信号处理来保护自己免受并发问题的影响
多进程vs多线程:

- 速度:多线程免于切换上下文,速度更快
- 内存使用:多线程共享内存,使用率更高
- CPU使用:多线程更好,同理
- 易用性:多线程不需要考虑通信等问题,更好
- 安全性:多进程更好,一个Bug破坏了内存,共享内存会最终导致多线程崩溃,而多进程只会让单个进程崩溃
这也就是为什么Google Chrome选择多进程架构,因为Google认为无法解决所有问题,因此用进程隔离开防止全部崩溃
Mozilla认为是可以解决大部分问题的,所以为Firefox创建了Rust,尝试解决问题
Intro to Multithreading
一个标签页就是一个进程
竟态条件:软件的条件和行为取决于无法控制的事件的顺序或时间,你能从不同的事件的事件安排中得到不同的结果
fn main() {let mut threads = Vec::new();for _ in 0..NUM_THREADS {threads.push(thread::spawn(|| {//闭包函数/lambda函数 有参时:|x: u32, f: f64|let mut rng = rand::thread_rnp();thread::sleep(time::Duration::from_millis(rng.gen_range(0, 5000)));println!("thread finished running!");}));}for handle in threads {handle.join().expect("panic happend inside of a thread!");}println!("all threads finished!");
}
Shared Memory
当线程之间所有权需要共享时,可以使用
Arc(共享引用计数,Atomic Reference Counted 缩写)。这个结构通过Arc::clone(&x)实现可以为内存堆中的值的位置创建一个引用指针,同时增加引用计数器。由于它在线程之间共享所有权,因此当指向某个值的最后一个引用指针退出作用域时,该变量将被删除。Arc是Rc的多线程版本
move:
const NAMES: [&self; 6] = ["frank", "jon", "lauren", "marco", "julie", "patty"]
fn main() {let mut threads = Vec::new();for i in 0..6 {threads.push(thread::spawn(move || {//move将所引用的所有变量(i)的所有权转移至闭包内,通常用于使闭包的生命周期大于所捕获的变量的原生命周期,拷贝println!("{}", NAMES[i]);}));}for handle in threads {handle.join().expect("panic occurred in thread");}
}
使用Rc< RefCell >,作为共享内存,可以让各个线程都操作一个变量
fn main() {let remainingTickets: Rc<RefCell<usize>> = Rc::new(RefCell::new(250));let mut threads = Vec::new();for i in 0..10 {let remainingTicketRef = remainingTickets.clone();threads.push(thread::spawn(|| {ticketAgent(i, &mut remainingTicketRef.borrow_mut())}));}for handle in threads {handle.join().expect("panic occurred in thread");}
}
此时Rc是不安全的,因为可能有多个线程同时修改同一变量,使用Arc保证操作的原子性,并且要加锁
Mutex:本质上时一个存储一段内存的容器,确保你可以拥有独占的访问权限,但是不能拷贝,所以外包一层Arc实现拷贝

fn ticketAgent(id: usize, remainingTickets: Arc<Mutex<usize>>) {loop {let mut remainingTicketsRef = remainingTickets.lock().unwrap();...}
}fn main() {let remainingTickets: Arc<Mutex<usize>> = Arc::new(Mutex::new(250));let mut threads = Vec::new();for i in 0..10 {let remainingTicketRef = remainingTickets.clone();threads.push(thread::spawn(move || {ticketAgent(i, remainingTicketRef)//即使克隆remainingTicketRef也是指向同一内存的}));}for handle in threads {handle.join().expect("panic occurred in thread");}
}
互斥锁持续在ticketAgent的循环作用域中存在,直到离开循环,此时互斥锁释放并释放它锁住的东西
Synchronization
条件变量Condvar和互斥锁相关,互斥锁和数据片段相关
解决资源访问顺序的问题。而 Rust 考虑到了这一点,为我们提供了条件变量(Condition Variables),它经常和
Mutex一起使用,可以让线程挂起,直到某个条件发生后再继续执行
将条件变量与互斥量关联起来的习惯做法是将它们成对放在一起,并将这对变量包装在Arc中。
实现多线程通过队列和主线程通信,队列只有一个,主线程不断等待子线程传入队列的信息
# Cargo.toml
[dependencies]
rand = "0.7.3" # 使用的rand库版本
extern crate rand;
use std::sync::{Arc, Mutex, Condvar};
use std::{thread, time};
use std::collections::VecDeque;
use rand::Rng;fn rand_sleep() {let mut rng = rand::thread_rng();thread::sleep(time::Duration::from_millis(rng.gen_range(0, 30)));
}#[derive(Clone)]//Arc实现了Clone,所以不需要单独实现它的Clone
pub struct SemaPlusPlus<T> {//Pair,使用.0和.1访问元素queue_and_cv: Arc<(Mutex<VecDeque<T>>, Condvar)>,
}impl<T> SemaPlusPlus<T> {pub fn new() -> Self {SemaPlusPlus {queue_and_cv: Arc::new((Mutex::new(VecDeque::new()), Condvar::new()))}}//发送pub fn send(&self, message: T) {// 获得锁let mut queue = self.queue_and_cv.0.lock().unwrap();queue.push_back(message);// 只在队列变成非空时才通知全体线程if queue.len() == 1 {self.queue_and_cv.1.notify_all();}}//接收pub fn recv(&self) -> T {let mut queue = self.queue_and_cv.0.lock().unwrap()queue = self.queue_and_cv.1.wait_while(queue, |queue| {queue.is_empty()//队列为空就一直等待}).unwrap();// 将锁移动到等待状态,等待结束后返回锁queue.pop_front().unwrap()}
}fn main() {let sem: SemaPlusPlus<String> = SemaPlusPlus::new();let mut handles = Vec::new();for i in 0..12 {// 每个线程克隆一个,但都指向同一SemaPlusPluslet sem_clone = sem.clone();let handle = thread::spawn(move || {rand_sleep();sem_clone.send(format!("thread {} finished", i))});handles.push(handle);}for _ in 0..12 {println!("{}", sem.recv());}for handle in handles {handle.join().unwrap();}
}
C/C++没有将锁和数据联系起来,而Rust要求必须获得锁才能使用数据
Channels
Golang:通过通信共享内存,而不是共享内存来通信(多线程,不共享内存)
如果不共享内存,则需要将数据复制到消息中,开销会很大。我们共享一些内存(在堆中),并且只在通道中进行浅拷贝。
通道减少了数据竞争的可能性,但如果使用不当(因为会有多个指针指向同一内存),也不能排除竞争
MPMC通道:多生产者多消费者,理想通道
Rust使用MPSC通道:多生产者单消费者
use std::thread;
use crossbeam_channel::unbounded;let (sender, receiver) = unbounded();// Computes the n-th Fibonacci number.
fn fib(n: i32) -> i32 {if n <= 1 {n} else {fib(n - 1) + fib(n - 2)}
}// Spawn an asynchronous computation.
thread::spawn(move || sender.send(fib(20)).unwrap());// Print the result of the computation.
println!("{}", receiver.recv().unwrap());
使用通道比使用锁和CV更加安全,但是在极端情况下还是会导致问题
通道并不总是最好的选择:不太适合全局值(例如缓存或全局计数器)
Scalability and Availability
可扩展性和可用性两者此消彼长
Netflix通过在一个可控的环境中故意诱导失败来检查复杂系统中可能出现的故障:混沌工程——“对系统进行实验的学科,以建立对系统在生产中承受动荡条件的能力的信心。”Simian Army——Chaos Monkey
Information Security
安全的两个原则:
- 身份验证Authentication:你是谁
- 授权Authorization:你正在做的是否是你被允许做的
作业笔记
/proc/{pid}/fd中存放进程所用的文件描述符的符号链接,指向文件描述符在vnode表中指向的任何文件,可以从/proc/{pid}/fdinfo/{fd}获取关于每个文件描述符的额外信息
获取文件
let dir = fs::read_dir(format!("/proc/{}/fd", self.pid)).ok()?;
for entry in dir{let name = entry.expect("process error").file_name();let parsed: usize = name.into_string().expect("osstring to string error").parse().unwrap();result.push(parsed);
}
创建泛型结构体
struct Node<T> {value: T,next: Option<Box<Node<T>>>,
}impl<T> Node<T> {pub fn new(value: T, next: Option<Box<Node<T>>>) -> Node<T> {Node::<T> {value: value, next: next}}
}
nix::sys::ptrace::cont:重新启动已停止的跟踪进程,ptrace(PTRACE_CONT, ...)
使用 PID 继续执行进程,(可选) 传递由sig指定的信号
pub fn cont<T: Into<Option<Signal>>>(pid: Pid, sig: T) -> Result<()>
Child::kill():强制子进程退出。如果子项已退出,则返回Ok(())
pub fn kill(&mut self) ->Result<()>
nix::sys::ptrace::getregs():获取用户程序的寄存器
pub fn getregs(pid: Pid) -> Result<user_regs_struct>
为了有用,backtrace应该显示函数名和行号,以便程序员可以看到程序的哪些部分正在运行。然而,正在运行的可执行文件仅由汇编指令组成,不知道函数名或行号。为了打印这些信息,我们需要读取存储在为调试而编译的可执行文件中的额外调试符号。这个调试信息存储地址和行号、函数、变量等之间的映射。有了这些信息,我们就可以找到变量在内存中的存储位置,或者根据处理器指令指针的值找出正在执行的是哪一行。
void
bar(int a, int b)
{int x, y;x = 555;y = a+b;
}void
foo(void) {bar(111,222);
}
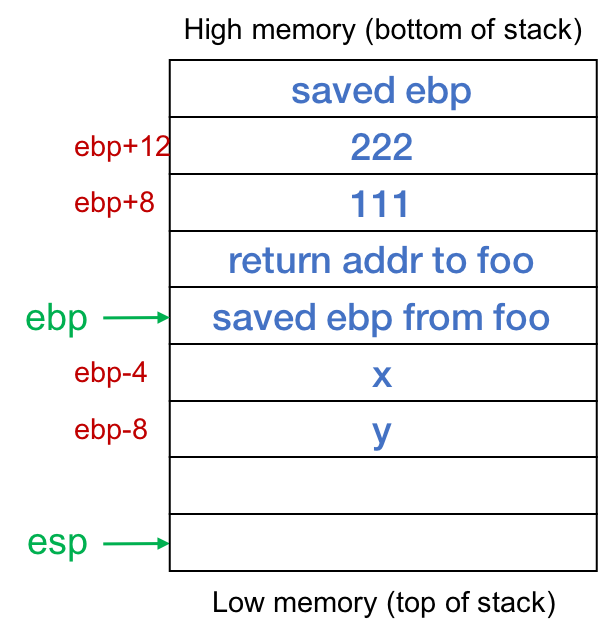
堆栈帧由两个寄存器限定:%rbp中的值是当前堆栈帧顶部的地址,%rsp中的值是当前堆栈帧底部的地址(%ebp和%esp指的是寄存器的较低32位,但您将分别处理%rbp和%rsp)。
读进程内存
rbp = ptrace::read(self.pid(), (地址) as ptrace::AddressType)? as usize;
如何在进程上设置断点?答案可能比您想象的要复杂,但这正是GDB的工作原理。要在0x123456的指令上设置断点,只需使用ptrace写入子进程的内存,将0x123456的字节替换为值0xcc。这对应于INT(“中断”)指令;任何运行此指令的进程都将暂时停止。
当我们“遇到断点”时,下级程序执行了0xcc INT指令,导致下级程序暂停(由于SIGTRAP)。然而,0xcc指令覆盖了程序中有效指令的第一个字节。如果我们从0xcc之后继续执行,我们将跳过一条合法的指令。更糟糕的是,许多指令有多个字节长。如果我们在多字节指令上设置断点并继续执行,CPU将尝试将指令的第二个字节解释为一个新的独立指令。程序很可能会由于段错误或非法指令错误而崩溃。
为了从断点继续,我们需要用原始指令的值替换0xcc。然后,我们需要倒带指令指针(%rip),使其指向原始指令的开头(而不是指向其中的一个字节)。
这样做之后,我们可以继续执行。但是,我们的断点不再在代码中,因为我们已经将0xcc换成了真正的指令。如果我们在循环或多次调用的函数中设置了断点,这是不理想的!








)
)

)




![华为 Auth-HTTP Server 1.0 任意文件读取漏洞复现 [附POC]](http://pic.xiahunao.cn/华为 Auth-HTTP Server 1.0 任意文件读取漏洞复现 [附POC])

-使用kube-bench检测Kubernetes集群安全)
