近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著的进展,如GPT-series(GPT-3, GPT-4)、Google-series(Gemini, PaLM), Meta-series(LLAMA1&2), BLOOM, GLM等模型在各种任务中展现出惊人的能力。然而,随着模型规模的不断增大和参数数量的剧增,这些模型的成功往往伴随着巨大的计算和存储资源消耗,给其训练和推理带来了巨大挑战,也在很大程度上限制了它们的广泛应用。因此,研究如何提高LLMs的效率和资源利用,使其在保持高性能的同时降低资源需求,成为了当前领域的热点问题。
今天这篇工作是一篇survey,旨在全面调查和总结提高LLMs效率的最新研究进展。工作首先概述了LLMs面临的挑战,随着模型规模的增大,传统的训练方法难以适应庞大的模型参数和计算资源需求。接下来,详细介绍了从模型为中心、数据为中心和框架为中心三个角度出发的一系列高效技术。这些技术涵盖了量化、参数修剪、低秩逼近、知识蒸馏等模型压缩方法,推理加速、混合专家训练等高效结构以及数据选择、提示工程等数据为中心策略。最后,讨论了支持高效训练和推理的LLM框架,为实际应用提供了有力支持。
该工作的目的是为研究人员和从业者提供一个关于高效LLMs技术的全面了解,以期激发更多关于这一重要领域的研究和创新。在这个信息爆炸的时代,提高LLMs的效率对于推动自然语言处理技术的发展具有重大意义,同时也将为人工智能的广泛应用奠定坚实基础。接下来就让我们一起探索高效的大型语言模型!
论文: Efficient Large Language Models: A Survey
地址: https://arxiv.org/abs/2312.03863
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
建了技术答疑、交流群!想要进交流群、需要资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流
资料1

资料2

下面将从以模型为中心,包括模型压缩,高效预训练,高效微调,高效推理,高效结构设计五个部分;以数据为中心,包括数据选择,提示工程两个部分;以框架为中心介绍该篇工作。
模型为中心
模型压缩
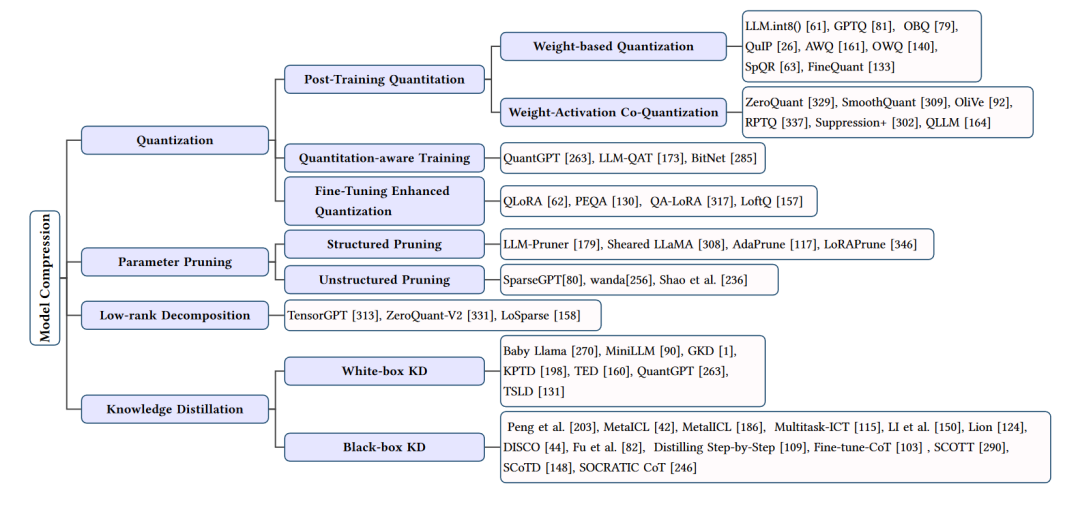
模型压缩方法的总结
模型压缩部分主要关注于减少大型语言模型(LLMs)的计算和存储需求,同时尽量保持其性能。这部分的技术主要包括量化、参数修剪、低秩逼近和知识蒸馏等方法。下面我们将详细介绍这些技术。
- 量化
量化是一种通过减少模型权重和激活的位宽来压缩模型的技术。常见的量化方法包括权重量化、激活量化和权重-激活共量化。量化可以降低计算和存储需求,但可能会带来一定的性能损失。为了解决这个问题,研究者们提出了多种量化技术,如动态范围量化(DRQ)、**知识蒸馏量化(KDQ)**等,它们在保持模型性能的同时实现了高效的压缩。
- 参数修剪
参数修剪是一种通过移除模型中不重要的参数来减小模型大小的方法。参数修剪可以分为结构化修剪和非结构化修剪。结构化修剪关注于移除模型中的整个子结构,如行、列或子块;非结构化修剪则关注于移除单个参数。参数修剪可以在一定程度上降低模型复杂度,但过度修剪可能导致性能下降。为了解决这个问题,研究者们提出了一些策略,如基于敏感度的修剪、低秩分解修剪等,以实现性能和压缩之间的平衡。
- 低秩逼近
低秩逼近通过将模型权重矩阵近似表示为低秩矩阵来减小模型大小。这种方法可以显著降低模型的计算和存储需求。常见的低秩逼近技术包括矩阵分解、核方法和秩限制等。为了保持模型性能,研究者们还提出了一些优化策略,如迭代训练、低秩补偿等。
- 知识蒸馏
知识蒸馏是一种通过训练一个较小的学生模型来模仿大型教师模型的行为,从而实现模型压缩的方法。知识蒸馏可以分为白盒知识蒸馏和黑盒知识蒸馏。白盒知识蒸馏利用教师模型的内部信息进行训练,而黑盒知识蒸馏仅依赖于教师模型的输入输出。为了提高蒸馏效果,研究者们提出了一些改进策略,如多任务学习、多阶段训练等。
模型压缩技术通过各种方法降低大型语言模型的计算和存储需求,使其在实际应用中更具可行性。然而,这些技术在压缩模型的同时也需要权衡性能损失。未来的研究将继续探索更高效、更精确的模型压缩方法,以实现性能与压缩之间的最佳平衡。
高效预训练
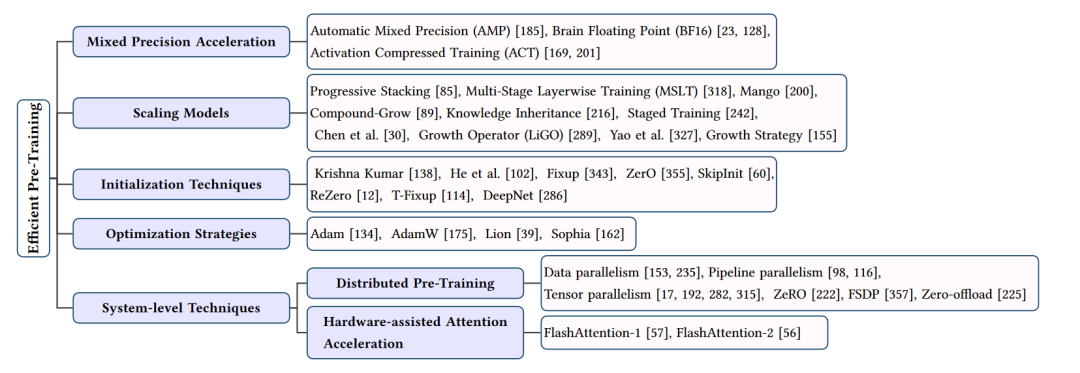
高效预训练技术的总结
在大型语言模型(LLMs)的研究中,预训练是一个至关重要的步骤,它为模型提供了丰富的知识和表示能力。然而,预训练过程通常需要大量的计算资源和时间,这对于许多研究者和从业者来说是一个巨大的挑战。因此,研究者们提出了许多高效预训练技术,以降低预训练的成本和复杂性。下面将从四个方面介绍这些技术:混合精度加速、模型缩放、初始化技术和优化策略。
- 混合精度加速
混合精度加速是一种利用低精度数据类型(如16位或32位浮点数)进行计算,同时保持模型的高性能的方法。这种技术通过减少数据类型的位宽来降低计算和存储需求,从而提高预训练效率。常见的混合精度加速方法包括自动混合精度(AMP)、BF16等。这些方法在保持模型性能的同时,显著降低了预训练过程中的计算和内存开销。
- 模型缩放
模型缩放技术通过利用较小模型的信息来指导较大模型的预训练,从而提高预训练效率。这些方法包括渐进式堆叠、多阶段层训练(MSLT)、复合增长等。它们通过在预训练过程中逐步增加模型的规模、深度和宽度,实现了更快的收敛速度和更高的性能。此外,一些研究还利用知识继承等技术,通过教师模型的知识来加速学生模型的预训练。
- 初始化技术
合适的初始化方法对于预训练过程的收敛速度和模型性能至关重要。一些研究者提出了特定的初始化技术,如函数保留初始化(FPI)和高级知识初始化(AKI),以提高大型模型预训练的效率。这些方法通过在预训练初期为大型模型提供良好的初始状态,有助于加快收敛速度并提高最终性能。
- 优化策略
优化策略在预训练过程中起到了关键作用。一些研究者提出了新的优化器,如Lion和Sophia,以提高预训练效率。这些优化器通过调整学习率、动量等超参数,以及引入第二阶信息,实现了更快的收敛速度和更高的内存利用率。此外,一些研究还探讨了分布式预训练技术,如数据并行、流水线并行和张量并行等,以利用多设备并行计算来加速预训练过程。
高效预训练技术通过混合精度加速、模型缩放、初始化技术和优化策略等方法,显著降低了大型语言模型预训练过程中的计算和时间成本。这些技术为LLMs的研究和应用提供了有力支持,有助于推动自然语言处理领域的发展。然而,这些技术仍然存在一定的局限性,未来的研究应该继续探索更高效、更实用的预训练方法。
高效微调
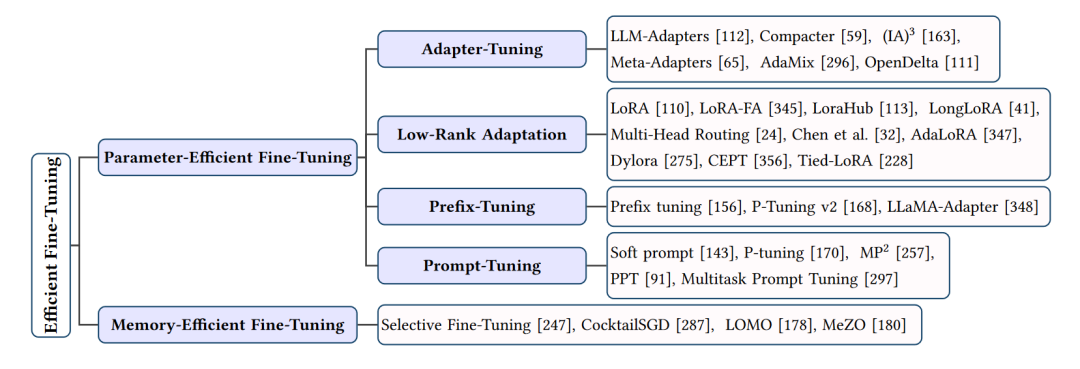
高效微调方法的总结
在大型语言模型(LLMs)的应用中,微调是一个关键步骤,它使模型能够适应特定的任务和领域。然而,微调过程可能会消耗大量计算资源和时间。为了提高微调效率,研究者们提出了许多高效微调方法。接下来将从两个方面介绍这些技术:参数高效微调和内存高效微调。
- 参数高效微调
参数高效微调方法旨在通过减少模型参数的更新来提高微调效率。这些方法主要包括适配器调优、低秩适应和前缀调优等。
1.1 适配器调优(Adapter-Tuning)
适配器调优是一种将适配器模块集成到LLMs中的方法,这些适配器模块可以在微调过程中更新,而模型的其他部分保持不变。适配器可以是串联适配器,每个LLM层都添加一个适配器模块;也可以是并联适配器,每个适配器模块与LLM层并行。适配器调优的典型技术包括LLM-Adapters、Compacter、(IA)3、Meta-Adapters等。
1.2 低秩适应(Low-Rank Adaptation)
低秩适应(LoRA)是一种通过引入两个低秩矩阵来更新模型参数的方法。在微调过程中,原始模型参数保持不变,而是更新这两个低秩矩阵。LoRA及其变体(如LoRA-FA、LongLoRA等)在保持较高性能的同时,显著降低了微调过程中的计算和内存需求。
1.3 前缀调优(Prefix-Tuning)
前缀调优在LLMs的每一层添加一系列可训练的前缀令牌,这些令牌针对特定任务进行定制。前缀调优的典型技术包括Prefix Tuning、P-Tuning v2和LLaMA-Adapter。通过使用前缀令牌,这些方法可以在微调过程中实现参数效率和性能提升。
- 内存高效微调
内存高效微调方法关注于降低微调过程中的内存消耗。这些方法主要包括选择性微调和分阶段微调等。
2.1 选择性微调
选择性微调通过仅更新模型的部分中间激活来降低内存需求。典型的选择性微调技术包括Selective Fine-Tuning、CocktailSGD和LOMO。这些方法在保持较高性能的同时,显著降低了微调过程中的内存消耗。
2.2 分阶段微调
分阶段微调将微调过程分为多个阶段,每个阶段仅更新部分模型参数。这种方法可以降低内存需求,同时保持模型性能。典型的分阶段微调技术包括Staged Training和MeZO。
高效微调方法通过参数高效微调和内存高效微调等技术,显著降低了大型语言模型在微调过程中的计算、时间和内存成本。
高效推理
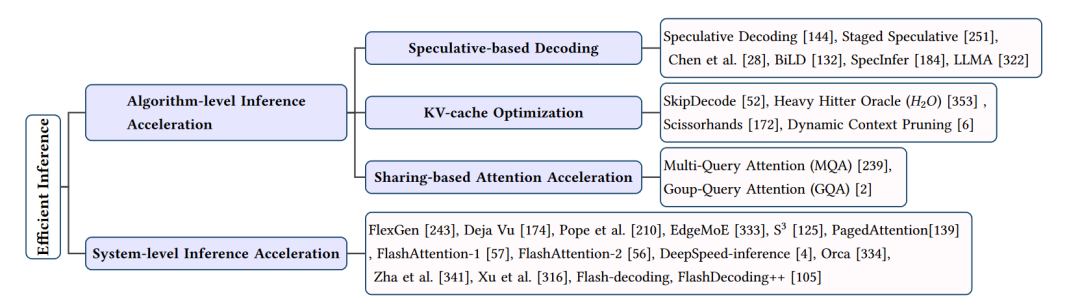
高效推理技巧的总结
在大型语言模型(LLMs)的应用中,高效的推理技巧对于实现实时响应和降低计算成本至关重要。接下来将从算法层面和系统层面两个方面介绍高效推理技巧。
一、算法层面的高效推理技巧
- 投机解码
投机解码(Speculative Decoding)是一种在解码过程中采用多个候选模型并行计算的技术。通过使用较小的草稿模型创建投机前缀,然后评估这些前缀与大型目标模型的初步输出,可以加速解码过程。典型的投机解码方法包括Chen等人提出的快速自回归模型(Faster Autoregressive Model) 和BiLD,它们分别采用不同的策略来提高投机解码的性能。
- KV-Cache优化
KV-Cache优化旨在减少LLMs推理过程中Key-Value(KV)缓存的计算和存储开销。一些方法如SkipDecode和Heavy Hitter Oracle(A^2A)通过跳过较低层和中间层的计算来加速推理过程。而Dynamic Context Pruning和Scissorhands则利用可学习机制来识别和移除非信息性的KV-Cache tokens,从而提高计算效率和模型可解释性。
- 分享式注意力加速
分享式注意力加速通过不同KV头共享方案来加速注意力计算。例如,多查询注意力(MQA)和分组查询注意力(GQA) 分别共享一组KV或多个KV头的线性变换,从而减少计算复杂度。这些方法在保持较高性能的同时,显著降低了计算和内存需求。
二、系统层面的高效推理技巧
- FlexGen
FlexGen是一个针对内存受限GPU的高吞吐量推理引擎。通过集成CPU、GPU和磁盘的计算资源,以及采用线性编程搜索策略来管理硬件组件,FlexGen能够在有限的硬件资源下实现高效的LLM推理。
- Deja Vu
Deja Vu定义了一种上下文稀疏性概念,并利用预测器预测这种稀疏性。通过使用内核融合、内存合并等技术,Deja Vu能够在推理过程中实现高效的计算和内存优化。
- EdgeMoE
EdgeMoE是一种针对LLMs的设备端处理系统,基于Mixture-of-Experts(MoE)结构进行内存和计算管理。通过将模型划分为不同部分并分配到不同存储级别,EdgeMoE能够在推理过程中实现高效的资源利用。
- S3
S3系统通过预测输出序列的长度并根据预测结果规划生成请求,以优化设备资源的使用。同时,S3能够处理任何不正确的预测,实现高效的推理过程。
- PagedAttention
PagedAttention受到传统虚拟内存和分页方法的启发,为LLMs设计了一个允许在请求之间高效共享KV-Cache的系统。这种方法有助于降低内存消耗并加速高吞吐量推理。
- FlashAttention
FlashAttention通过融合矩阵乘法和softmax操作,以及采用张量核心自动调整和调度策略,实现高效的注意力计算。FlashAttention-1和FlashAttention-2分别针对不同硬件平台进行了优化,以实现更快速的推理过程。
高效结构
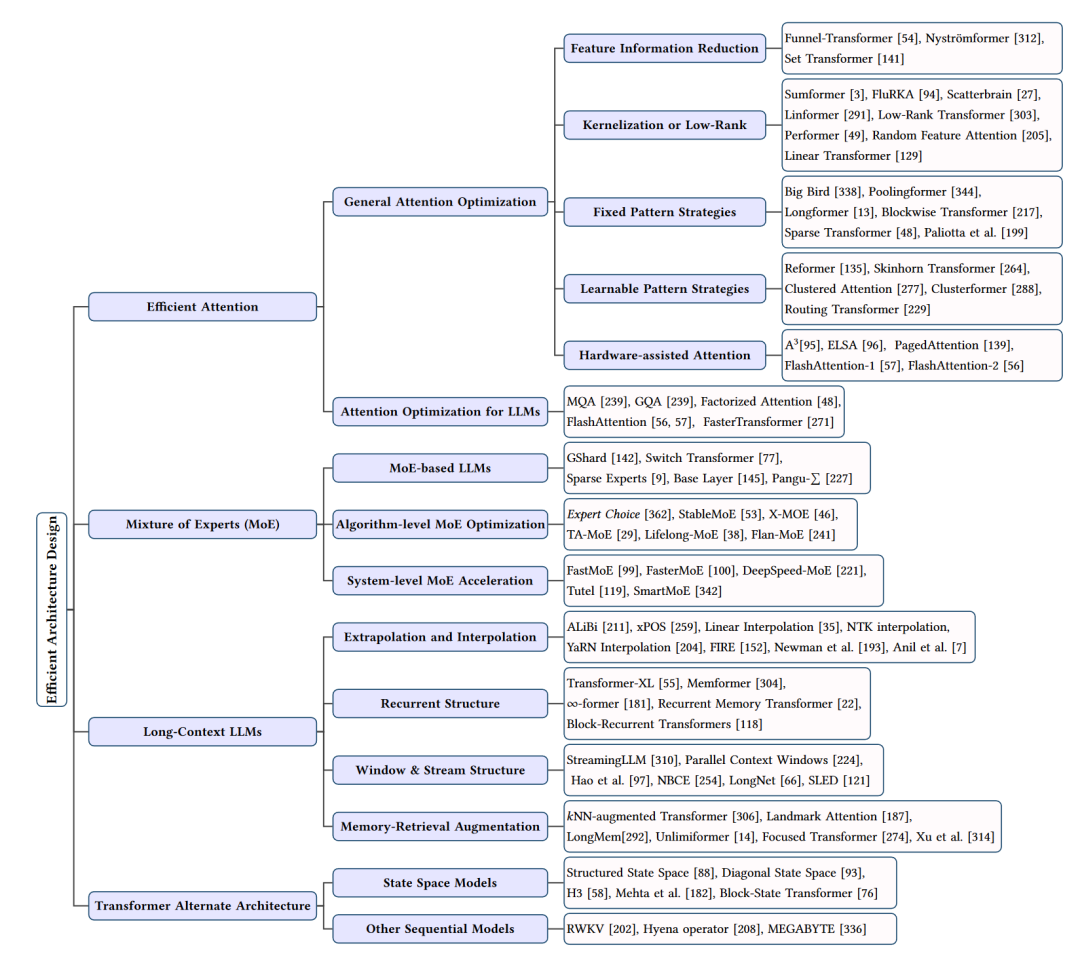
高效架构设计总结
在大型语言模型(LLMs)的研究中,高效的结构设计对于提高模型性能和降低计算成本具有重要意义。接下来将从四个方面介绍高效结构设计:注意力优化、混合专家(Mixture of Experts, MoE)模型、长上下文LLMs和Transformer替代结构。
- 注意力优化
注意力优化主要关注于降低自注意力机制的计算复杂度。这些方法包括:
-
特征信息缩减:通过减少序列中的特征信息,如Funnel-Transformer、Nyströmformer和Set Transformer等,降低计算需求。
-
核化或低秩:利用低秩表示或注意力核化技术,如Sumformer、FluRKA、Scatterbrain等,提高计算效率。
-
固定模式策略:通过局部窗口或固定步长块模式,如Paliotta等人的方法、Big Bird、Poolingformer等,实现注意力矩阵的稀疏化。
-
可学习模式策略:通过学习序列的组织方式,如Reformer、Skinhorn Transformer、Clustered Attention等,实现更高效的注意力计算。
-
硬件辅助注意力:通过定制硬件实现,如A3、ELSA、PagedAttention等,进一步提高注意力计算的效率。
- 混合专家(Mixture of Experts, MoE)模型
MoE模型将任务划分为多个子任务,并为每个子任务训练一个专家模型。这些专家模型共同为输入生成输出。MoE模型可以有效地管理大量参数,降低计算和内存需求。典型的MoE模型包括GShard、Switch Transformer、Sparse Experts等。此外,还有一系列算法层面和系统层面的MoE优化技术,如Expert Choice、StableMoE、FastMoE等。
- 长上下文LLMs
长上下文LLMs关注于处理长序列输入。为解决这个问题,研究者们提出了一系列方法,如:
-
外推和插值:通过优化位置嵌入,实现对更长序列的泛化,如ALiBi、xPOS等。
-
循环结构:通过引入记忆单元和循环机制,实现长序列建模,如∞-former、Recurrent Memory Transformer等。
-
窗口和流结构:通过设计新的窗口机制和流式处理,降低固定窗口的限制,如StreamingLLM、Parallel Context Windows等。
-
记忆检索增强:利用最近邻查找和内存增强技术,实现长序列的高效处理,如NN-Augmented Transformer、Landmark Attention等。
- Transformer替代结构
除了优化现有的Transformer结构,研究者们还提出了一些替代结构,如:
-
状态空间模型:通过将注意力机制替换为状态空间模型,实现近线性的计算复杂度,如Structured State Space(S4)、Diagonal State Space(DSS)等。
-
其他序列模型:结合循环神经网络和Transformer的优点,如RWKV、Hyena Operator等,实现高效的长序列处理。
以数据为中心
数据选择

数据选择技巧的总结
在大型语言模型(LLMs)的研究和应用中,数据选择对于提高模型性能和效率具有重要意义。合适的数据选择可以降低训练成本、提高泛化能力,并使模型更适应特定任务。加下来将从两个方面介绍数据选择技巧:高效预训练数据选择和高效微调数据选择。
- 高效预训练数据选择
预训练数据的选择对LLMs的性能至关重要。高质量的预训练数据可以帮助模型学习通用的知识表示,从而提高在各种任务上的表现。高效预训练数据选择技巧包括:
-
数据清洗:通过去除无关、重复或低质量的数据,降低噪声对模型学习的影响。
-
数据平衡:确保数据集中各类样本的比例均衡,避免模型在某些类别上过拟合。
-
数据增强:通过对原始数据进行扩充,如同义词替换、句子重组等,增加模型的泛化能力。
-
领域自适应:选择与目标任务相关的数据,使预训练模型更适应特定领域的任务。
- 高效微调数据选择
微调数据选择关注于为特定任务选取合适的训练数据。高效的微调数据选择可以降低微调成本,提高模型在目标任务上的性能。高效微调数据选择技巧包括:
-
任务相关性:选择与目标任务紧密相关的数据,以便模型能快速学习任务特定的知识。
-
数据筛选:通过评估数据与目标任务的相似性,筛选出最具代表性和价值的样本。
-
在线学习:利用在线学习策略,根据模型在验证集上的表现动态调整微调数据。
-
少样本学习:通过元学习、迁移学习等技术,利用少量标注数据实现高效的微调。
- 其他数据选择技巧
除了预训练和微调阶段的数据选择,还有一些其他技巧可以提高LLMs的效率:
-
示范选择:通过选择与目标任务相似的示范数据,引导模型更快地学习任务。
-
示范组织:合理组织示范数据,使其更符合模型的学习规律,提高学习效果。
-
模板格式化:设计合适的输入模板,以便模型能更好地理解任务需求。
提示工程
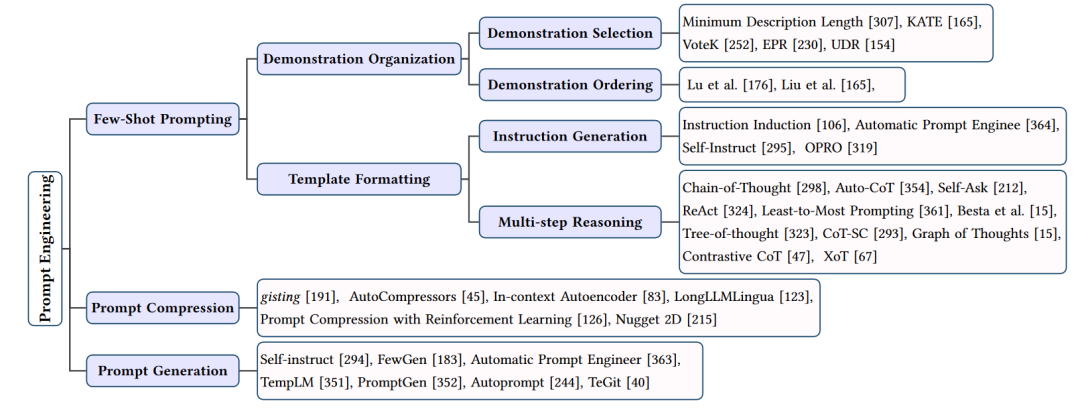
提示工程的总结
在大型语言模型(LLMs)的应用中,提示工程(Prompt Engineering)是一种关键技术,用于引导模型生成特定输出或执行特定任务。通过精心设计的提示,可以显著提高LLMs的性能和适用性。本文将介绍提示工程的主要方法和技巧,包括少样本提示、提示压缩和提示生成。
- 少样本提示
少样本提示是一种使用有限的示例来引导LLMs执行特定任务的方法。这些示例被称为“示范”(Demonstrations)。少样本提示技术主要包括:
-
示范选择:从训练数据中挑选与目标任务最相关的示例。这些示例应该具有代表性,以便模型能够从中学习到任务的关键特征。
-
示范组织:合理地组织示范,以便模型能够更好地理解任务。这可能包括调整示范的顺序、分组或格式化。
-
模板格式化:设计一个合适的输入模板,以便模型能够清楚地理解任务需求。模板应该简洁明了,同时包含足够的信息来引导模型生成正确输出。
- 提示压缩
提示压缩旨在通过压缩提示输入来降低LLMs的计算和存储需求。主要方法包括:
-
概要:将长文本概要为较短的表示,如提取关键信息或使用句子级别的概要。
-
压缩向量:将提示转换为紧凑的向量表示,如使用BERT等模型生成的句子嵌入。
-
结构化提示:设计结构化的提示格式,以便模型能够更高效地处理输入。这可能包括使用特定的语法规则或标记。
- 提示生成
提示生成旨在自动创建有效提示,以引导LLMs执行特定任务,而无需人工标注数据。主要方法包括:
-
自我指导:让LLMs根据自己的输出生成提示,从而实现自我学习和优化。
-
强化学习:使用强化学习技术训练LLMs生成高质量的提示。这通常涉及与环境(如用户或其他LLMs)的交互,以便根据反馈优化提示。
-
生成模型:利用生成模型(如GPT系列)为特定任务创建提示。这些模型可以根据输入的上下文生成合适的提示。
提示工程通过少样本提示、提示压缩和提示生成等技术,提高了LLMs的性能和适用性。这些方法使LLMs能够在各种任务中更好地理解和执行用户需求,同时降低了计算和存储成本。然而,提示工程仍然面临一些挑战,如如何平衡提示的简洁性和有效性,以及如何处理多样化和复杂的任务需求。未来的研究将继续探索更高效、更实用的提示工程技术。
以框架为中心

在大型语言模型(LLMs)的研究和应用中,以框架为中心的方法关注于构建和优化支持LLMs的软件框架。这些框架旨在简化LLMs的开发、训练和部署过程,提高计算资源的利用率,并支持各种高效算法和技术。接下来将介绍几个主要的以框架为中心的LLM框架,以及它们的特点和优势。
- DeepSpeed
DeepSpeed是由微软开发的一个集成框架,用于训练和部署LLMs。它提供了诸如数据并行、模型并行、流水线并行、提示批处理、量化和内核优化等功能。DeepSpeed Inference模块是其关键组件之一,其中的ZeRO-Inference技术可以解决GPU内存约束问题。DeepSpeed还支持混合精度训练、梯度累积、动态并行和分布式训练等技术,以提高训练效率。
- Megatron
Megatron是一个面向训练和部署LLMs的框架,由NVIDIA和微软共同开发。它支持数据并行、模型并行、流水线并行等技术,并提供了自动混合精度、选择性激活重计算等优化方法。Megatron的核心技术是战略性地分解模型张量操作,将它们分布式到多个GPU上,以提高处理速度和内存利用率。Megatron还支持BERT、GPT和T5等模型。
- Alpa
Alpa是一个用于训练和部署大型神经网络的库,它通过自动并行化技术来解决LLMs的计算和内存挑战。Alpa支持数据并行、模型并行、流水线并行等技术,并提供了自动调谐框架,以找到最佳的并行策略。Alpa还可以与流行的深度学习框架(如PyTorch和TensorFlow)无缝集成,简化LLMs的开发和训练过程。
- ColossalAI
ColossalAI是一个面向大规模并行训练的集成深度学习系统,支持LLMs的训练和部署。它提供了数据并行、模型并行、流水线并行等技术,并采用了一种模块化设计,以实现高效的算法和资源管理。ColossalAI还支持混合精度训练、梯度累积、动态并行等优化方法,以提高训练效率。此外,它还具有设备原生AI和用户友好的工具,以降低AI模型开发的门槛。
- Hugging Face Transformers
Hugging Face Transformers是一个流行的开源库,提供了大量预训练的LLMs,如GPT、BERT和T5等。它支持各种高效的推理技术,如令牌级并行、流水线并行和模型并行。Hugging Face Transformers库简化了LLMs的部署过程,使开发者能够轻松地将这些模型集成到各种应用中。
以框架为中心的方法通过构建和优化支持LLMs的软件框架,提高了LLMs的开发、训练和部署效率。这些框架通常提供了一系列并行化技术、优化方法和易用的工具,以满足不同场景和任务的需求。随着LLMs领域的不断发展,我们可以期待更多创新的框架和技术来支持这些模型的广泛应用。
结语
本文综述了大型语言模型(LLMs)的高效学习方法,主要包括模型压缩、高效微调和推理、数据选择、提示工程和框架优化等方面。这些技术旨在降低LLMs的计算和存储需求,提高训练和推理效率,同时保持或甚至提高模型性能。
模型压缩部分涵盖了量化、参数修剪、低秩逼近和知识蒸馏等方法,可以有效减小模型大小和计算复杂度。数据中心方法则关注数据选择和提示工程,通过精选训练数据和设计有效的输入提示,降低训练成本并提高模型泛化能力。提示工程通过设计合适的输入提示,引导LLMs更专注于任务关键信息,从而提高推理效果。最后,框架优化部分介绍了支持LLMs的软件框架,如DeepSpeed、Megatron和Alpa等,它们提供了并行计算、内存管理和优化技术,简化了LLMs的开发和部署过程。
这些高效学习方法为LLMs的研究和应用提供了有力支持,使这些模型能够在各种场景中发挥更大价值。然而,这些技术仍然面临一些挑战,如如何在压缩和加速过程中保持模型性能,以及如何适应多样化和复杂的任务需求。未来的研究将继续探索更高效、更实用的技术,以推动LLMs领域的发展。

)

)







)





代码解析+调试分析)
)
