JAVA8新特性之函数式编程详解
- 前言
- 一、初步了解函数式接口
- 二、 Lambda表达式
- 2.1 概述
- 2.2 lambda省略规则
- 2.3 lambda省略常见实例
- 2.4 lambda表达式与函数式接口
- 三、 Stream流
- 3.1 stream流的定义
- 3.2 Stream流的特点
- 3.3 Stream流的三个步骤
- 3.4 Stream 和 Collection 集合的区别:
- 3.5 使用stream流的好处
- 3.6 stream流的创建方式
- 1.通过集合对象创建串行或者并行流
- 2.通过数组创建
- 3.通过Stream的of()
- 4.双列集合构建Stream流
- 3.7 Stream中间操作
- 1.筛选与切片(filter && distinct && limit && skip)
- 2.映射(map && flatMap && mapToInt)
- 3.排序(sort)
- 3.8 Sream结束操作
- 1. 遍历(forEach)
- 2. 匹配(Match)
- 3. 查找( Find)
- 4.归并(reduce)
- 5. 最值(max && min)
- 6. 收集collect
- 7. 汇总数量(count)
- 四、Optional
- 4.1 概述
- 4.2 创建
- 4.3 安全的获取值
- 4.4 过滤
- 4.5 数据转换
- 五、并行流
- 5.1 并行流的创建
- 5.2 流的监视
前言
博主本人是一个编程小白,写此博客一来是作为自己的学习笔记,二来也是希望能够帮助到需要帮助的人。本篇博客是博主一边看视频和博客文章一边总结的。
本篇文章主要概述函数式编程相关知识,包括函数式接口详解、Steam流的详解、lambds表达式详解、Optional类的详解。基本覆盖日常开发所需接触到函数式编程的相关知识。
如果觉得博主写的还不错,就点点赞吧!此外如果大家发现有错误的地方也欢迎大家在评论区指正!
本博客主要参考来源:
视频:https://www.bilibili.com/video/BV1Gh41187uR/?spm_id_from=333.337.search-card.all.click
文章:https://blog.csdn.net/weixin_46075832/article/details/123630861?spm=1001.2014.3001.5506
有需要的同学可以结合上述视频和文章一起学习
一、初步了解函数式接口
首先我们了解一下函数式接口,这对我们理解Lambda有帮助
-
如果一个接口中,只声明了一个抽象方法,则此接口就称为函数式接口
-
我们可以在一个接口上使用 @FunctionalInterface 注解,这样做可以检查它是否是一个函数式接口。
-
这个注解既可以帮助我们检查这个接口是不是函数式接口,也可以让我们自定义函数式接口
-
大部分的函数式接口都定义在java.util.function包下。
二、 Lambda表达式
2.1 概述
首先我们直入主题,我们先来看一个函数式的编程
我们熟知的创建线程的方式
Runnable runnable = new Runnable() {@Overridepublic void run() {System.out.println("创建一个线程!");}};Thread thread = new Thread(runnable);thread.start();
我们可以实现了一个Runable接口,重写里面的run方法,然后将runable传入Thread里面就可以构建一个线程了。
但是我们知道,上述过程是可以简化的,我们可以采用匿名内部类的方式
Thread thread1 = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("创建一个线程!");}});
看,这样在代码的简洁程度上就会好很多。但是实际上还能简化,我们可以采用lambda表达式的方式。
我们按住ALT+ENTER键
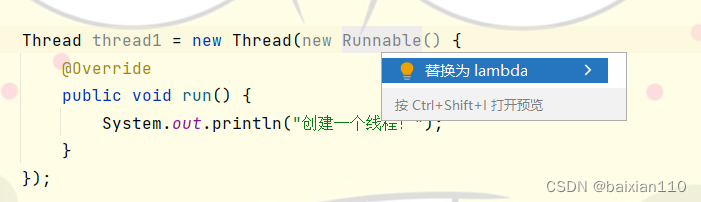
会有一个替换为lambda,我们点击之后,这个匿名内部类就会自动转化为lambda表达式的形式。就像下面这样
Thread thread1 = new Thread(() -> System.out.println("创建一个线程!"));
看,一行代码就搞定了。
所以可以发现函数式编程的好处之一就是代码简洁。
所以Lambda就是JDK8的一个语法糖,它可以对某些匿名内部类的写法进行简化。这就是函数式编程的一个重要体现。让我们不用在使用是什么对象,而是关注对数据进行什么样的操作。
我们可以再举几个例子
public static void main(String[] args) {int i = add1(new IntBinaryOperator() {@Overridepublic int applyAsInt(int left, int right) {return left + right;}});System.out.println(i);
}
public static int add1(IntBinaryOperator operator){int a = 10;int b = 10;return operator.applyAsInt(a,b);}
上述代码我在学习的时候还没看懂,这里解释一下,我们定义了一个静态方法add1
然后在main方法里调用了这个add1的方法,但是这个add1方法的参数是一个接口类型
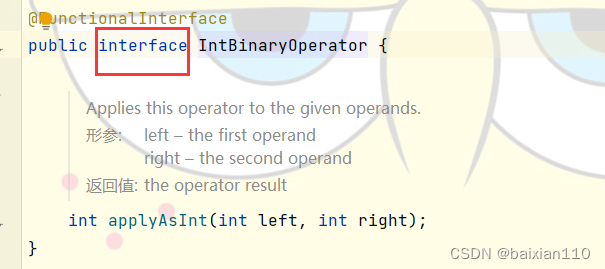 里面也只有一个appltAsInt的方法,我们当这个方法被调用的时候,需要IntBinaryOperator的形参传入,此时我们就需要实例化(或者说实现)这个接口然后传入。此时我们这里就使用了匿名内部类的方式,重写了applyAsInt方法。我们同样鼠标放在new IntBinaryOperator()上按住ALT加ENTER键,就可以将其转化为Lambda的形式
里面也只有一个appltAsInt的方法,我们当这个方法被调用的时候,需要IntBinaryOperator的形参传入,此时我们就需要实例化(或者说实现)这个接口然后传入。此时我们这里就使用了匿名内部类的方式,重写了applyAsInt方法。我们同样鼠标放在new IntBinaryOperator()上按住ALT加ENTER键,就可以将其转化为Lambda的形式
public static void main(String[] args) {int i = add1((left, right) -> left + right);System.out.println(i);
}
public static int add1(IntBinaryOperator operator){int a = 10;int b = 10;return operator.applyAsInt(a,b);}
就变成了上述形式,会发现非常简洁,但是一目了然这个函数做了什么。对于一个方法而言,我们实际上根本不需要关系这个函数叫什么,参数类型是什么之类的。从业务上,我们只需要知道这个函数有什么参数,拿着这些参数做什么就可以了。剩下的都可以省略。
2.2 lambda省略规则
所以这里就先说一嘴Lambda表达式的省略规则
1.参数类型可以省略
2.方法体中只有一句代码时大括号、return和唯一一句代码的分号可省略
3.方法只有一个参数时,小括号可以省略。
lambda省略规则的核心就是:可以推导出来就可以被省略。
以上面
public static void main(String[] args) {int i = add1((left, right) -> left + right);System.out.println(i);
}
public static int add1(IntBinaryOperator operator){int a = 10;int b = 10;return operator.applyAsInt(a,b);}
这个例子来说,之所以
add1(new IntBinaryOperator() {@Overridepublic int applyAsInt(int left, int right) {return left + right;}});
被省略成了
add1((left, right) -> left + right);System.out.println(i);
首先IntBinaryOperator这个是可以类型是可以被推导出来的,因为add1在定义的时候就这一个参数类型,所以肯定是这个参数类型;int被省略是因为这个IntBinaryOperator里面是只有一个抽象方法applyAsInt,而接口中的方法的返回值类型即使重写也只能是原本定义的返回值的类型的相同类型或者子类型。所以也是可以被推测的。而入参的参数类型int也可以被推导出来,因为applyAsInt参数类型就是int这是定义死的。
上述例子简述了一下Lambad表达式为什么可以省略。
2.3 lambda省略常见实例
正常开发中,我们能遇到的简化主要有以下几种
//语法格式一:无参,无返回值
@Test
public void test1(){Runnable r1 = new Runnable() {@Overridepublic void run() {System.out.println("我爱北京天安门");}};r1.run();System.out.println("*******************");Runnable r2 = ()-> {System.out.println("我爱北京天安门");};r2.run();
}//语法格式二:Lambda 需要一个参数,但是没有返回值。
@Test
public void test2(){Consumer<String> con1 = new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s + 1);}};con1.accept("谎言和誓言的区别是什么?");System.out.println("*******************");Consumer<String> con2 = (String s)-> System.out.println(s + 2);con2.accept("谎言和誓言的区别是什么?");
}
//语法格式三:数据类型可以省略,因为可由编译器推断得出,称为“类型推断”
@Test
public void test3(){Consumer<String> con1 = (String s) -> {System.out.println(s + 1);};con1.accept("一个是听得人当真了,一个是说的人当真了");System.out.println("*******************");Consumer<String> con2 = (s) -> {System.out.println(s + 2);};con2.accept("一个是听得人当真了,一个是说的人当真了");
}//语法格式四:Lambda 若只需要一个参数时,参数的小括号可以省略
@Test
public void test4(){Consumer<String> con1 = (s) -> {System.out.println(s);};con1.accept("一个是听得人当真了,一个是说的人当真了");System.out.println("*******************");Consumer<String> con2 = s -> {System.out.println(s);};con2.accept("一个是听得人当真了,一个是说的人当真了");
}//语法格式五:Lambda 需要两个或以上的参数,多条执行语句,并且可以有返回值
@Test
public void test5(){Comparator<Integer> com1 = new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {System.out.println(o1 + o2);System.out.println(o1);}};System.out.println(com1.compare(12,21));System.out.println("*****************************");Comparator<Integer> com2 = (o1,o2) -> {System.out.println(o1 + o2);return o1.compareTo(o2);};System.out.println(com1.compare(111,222));
}//语法格式六:当 Lambda 体只有一条语句时,return 与大括号若有,都可以省略
@Test
public void test6(){Comparator<Integer> com1 = (o1,o2) -> {return o1.compareTo(o2);};System.out.println(com1.compare(12,6));System.out.println("*****************************");Comparator<Integer> com2 = (o1,o2) -> o1.compareTo(o2);System.out.println(com1.compare(111,222));
}左边:lambda形参列表的参数类型可以省略(类型推断);如果lambda形参列表只有一个参数,其一对()也可以省略。
右边:lambda体应该使用一对{}包裹;如果lambda体只有一条执行语句(可能是return语句),省略这一对{}和return关键字。
2.4 lambda表达式与函数式接口
在了解了Lambda表达式之后,我们回顾一下上文中的函数式编程(函数式接口)我们不难理解,其实lambda表达式就是函数式接口的一个实例,只要一个对象是函数式接口的实例,那么该对象就可以用Lambda表达式来表示。
三、 Stream流
首先一点请大家记住:Stream流是java8的新特性,之前博主在面数字马力的时候就遇到有面试官问我使用JDK1.8的一些心得体会,当时问得我一脸懵逼,我以为他是在问我Spring框架带来的好处,结果可想而知啦!所以这里也跟大家说一下Stream流以及上面的Lambda表达式java8带来的新特性之一,在之前的JDK版本里面是没有的
3.1 stream流的定义
那么什么是stream流呢?
stream流简单理解就是用于操作数据源(集合、数组等)所生成的元素序列的流水线。
集合讲的是数据,Stream讲的是计算!
3.2 Stream流的特点
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行
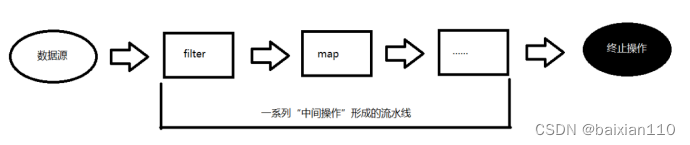
3.3 Stream流的三个步骤
- 创建 Stream
一个数据源(如:集合、数组),获取一个流
- 中间操作
一个中间操作链,对数据源的数据进行处理
- 终止操作(终端操作)
一旦执行终止操作,就执行中间操作链,并产生结果。之后,不会再被使用。
3.4 Stream 和 Collection 集合的区别:
Collection 是一种静态的内存数据结构,而 Stream 是有关计算的。前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
3.5 使用stream流的好处
Stream API ( java.util.stream) 把真正的函数式编程风格引入到Java中。这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 **使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。**简言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
3.6 stream流的创建方式
要知道Stream流是用来处理集合类的数据的。
1.通过集合对象创建串行或者并行流
default Stream stream() : 返回一个顺序流
default Stream parallelStream() : 返回一个并行流
例如:
List<Integer> list1 = new ArrayList<>();list1.add(1);list1.add(2);list1.add(3);Stream<Integer> stream = list1.stream();
2.通过数组创建
java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
static Stream stream(T[] array): 返回一个流
例如
int[] arr = {1,2,3,4,5};
IntStream stream2 = Arrays.stream(arr);
3.通过Stream的of()
例如:
String[] strs = {"a", "b", "c", "d", "e"};Stream<String> stream3 = Stream.of(strs);
4.双列集合构建Stream流
需要将双列集合转化为单列集合之后再创建
例如
Map<String,Integer> map2 = new HashMap<>();map2.put("a",1);map2.put("b",2);map2.put("c",3);Stream<Map.Entry<String, String>> stream4 = map.entrySet().stream();
3.7 Stream中间操作
首先Stream操作需要注意的是他是惰性求值的方式。
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
int[] arr = {1,2,2,4,5};IntStream stream2 = Arrays.stream(arr);stream2.distinct().filter(new IntPredicate() {@Overridepublic boolean test(int value) {return value>3;}});
我们开始书写stream要注意方法,因为一开始我们不知道该怎么写。
我们可以这样:
首先明确,一个Sream流必然要包含创建、中间操作、结束操作(很多同学在一开始学的时候总是忘记结束操作)。
比如说1,2,3,4,5这样五个数,构成一个数组,我们需要筛选出大于3的数并打印出来。
这里就要用到filter
我们可以先这样写:
int[] arr = {1,2,2,4,5};IntStream stream2 = Arrays.stream(arr);stream2.filter()
然后鼠标放在filter的入参上,按住ctrl+p,我们就知道入参是啥了。
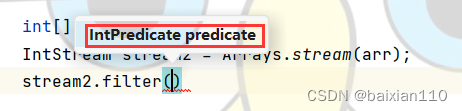
因为这是函数式接口,所以只会有一个入参,并且当我们创建这个接口的实例的时候,一定会重写里面的方法。就会像下面这样。
 这里面的value就是对应arr里面的每一个值,此时整个代码的风格是匿名内部类的方式,我们要过滤大于2的元素
这里面的value就是对应arr里面的每一个值,此时整个代码的风格是匿名内部类的方式,我们要过滤大于2的元素
所以应该像下面这样
int[] arr = {1,2,2,4,5};IntStream stream2 = Arrays.stream(arr);stream2.filter(new IntPredicate() {@Overridepublic boolean test(int value) {return value>2;}})
但是不要忘记,这样没有结束操作,stream的中间操作是不会执行的,所以需要加上一个结束操作,这里我们使用foreach操作作为结束操作,遍历一下数组,打印每一个元素。
int[] arr = {1,2,2,4,5};IntStream stream2 = Arrays.stream(arr);stream2.filter(new IntPredicate() {@Overridepublic boolean test(int value) {return value>2;}}).forEach(new IntConsumer() {@Overridepublic void accept(int value) {System.out.println(value);}});
但是不要忘记此时的风格是用匿名内部类的形式,我们需要将其更改为lambda表达式
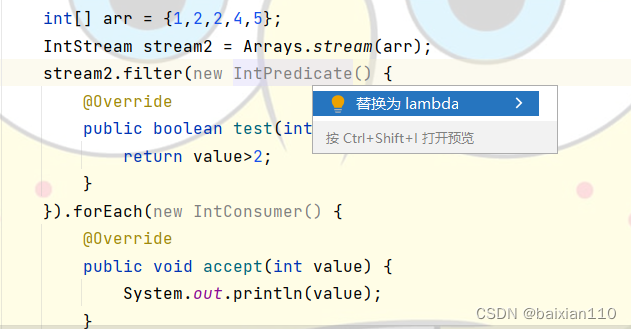
鼠标放在IntPredicate按住arlt+enter,就可以转化为lambda式了。
int[] arr = {1,2,2,4,5};IntStream stream2 = Arrays.stream(arr);stream2.filter(value -> value>2).forEach(value -> System.out.println(value));
Stream流的调试
在stream表达式那一行打断点就会出现如图所示的断点设置。
 我们点击下图框中的按钮
我们点击下图框中的按钮
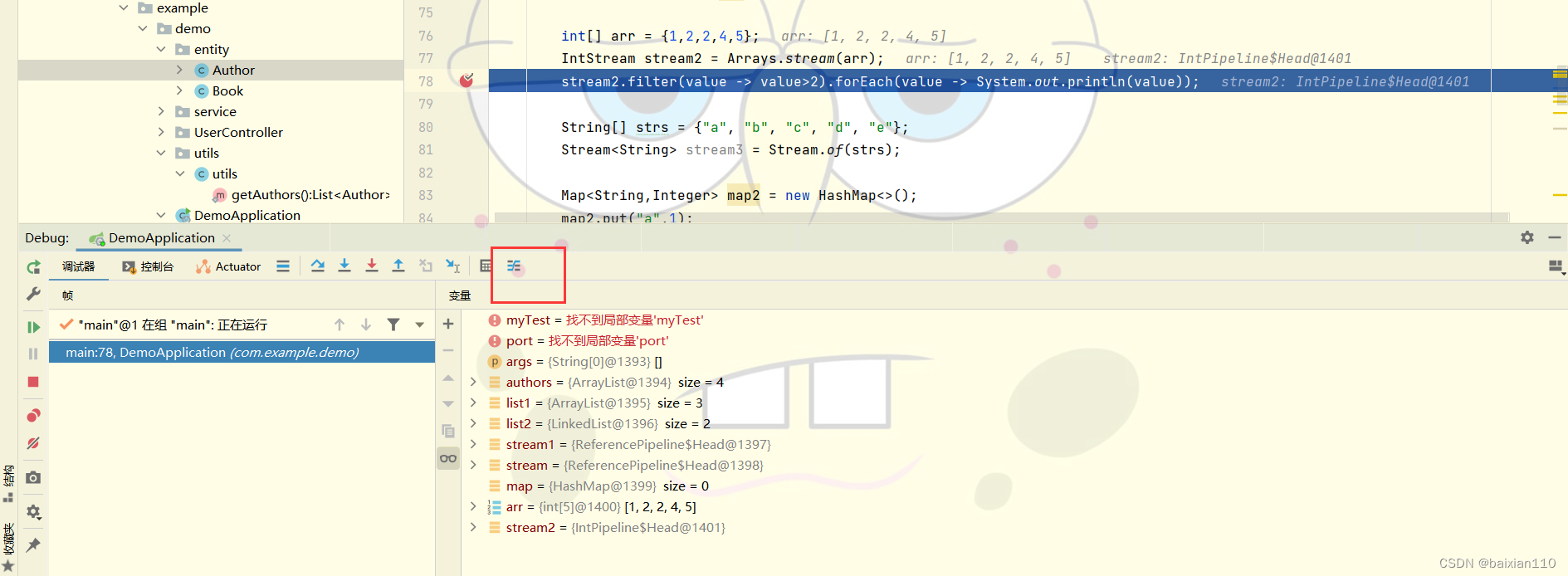 就可以看到可视化的stream处理过程。
就可以看到可视化的stream处理过程。
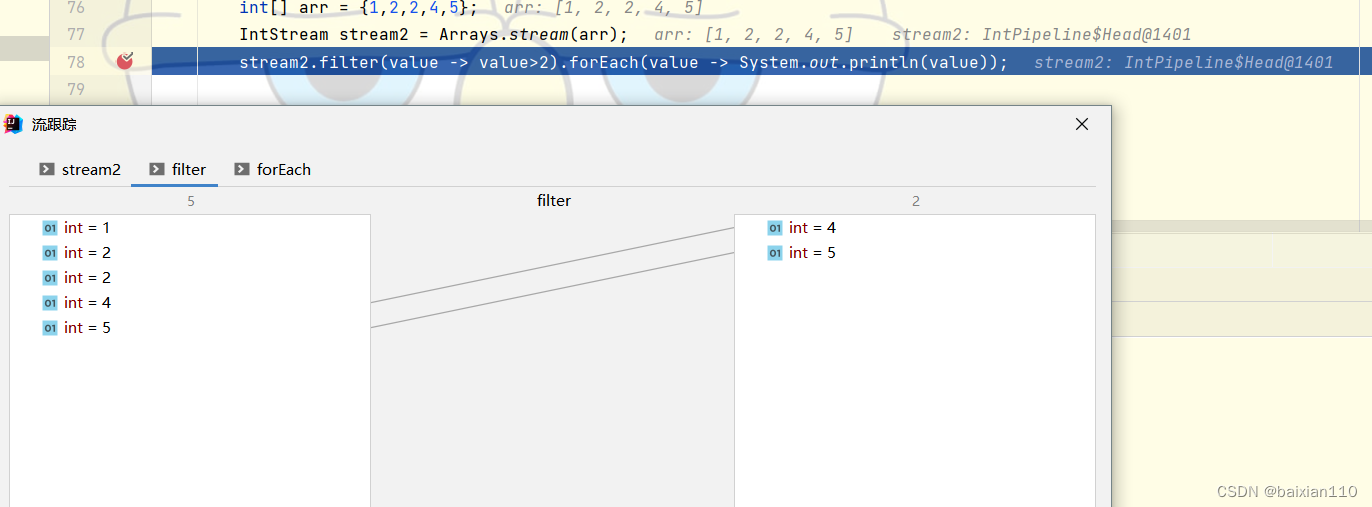
下面我们重点说一说这个中间操作
1.筛选与切片(filter && distinct && limit && skip)

filter
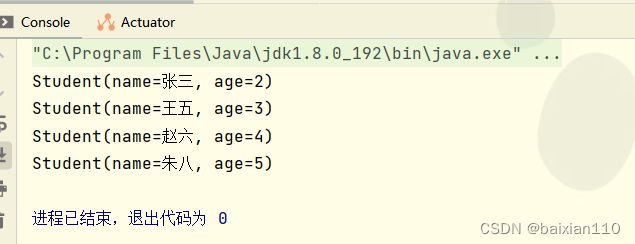
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list = new ArrayList<>();list.add(student1);list.add(student2);list.add(student3);list.add(student4);list.add(student5);list.stream().filter(student -> student.getAge()>3).forEach(System.out::println);

distinct
Student student1 = new Student("张三",1);Student student2 = new Student("张三", 1);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list = new ArrayList<>();list.add(student1);list.add(student2);list.add(student3);list.add(student4);list.add(student5);list.stream().distinct().forEach(System.out::println);

注意:distinct()是没有入参的,本质上就是删除重复数据,我们可以重写hashcode 和equals,来定义何为重复数据
@Data//用Data修饰的类就自动重写了get,set 构造方法,tostring方法
@AllArgsConstructor
public class Student {private String name;private int age;@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name);}
}
比如说我们这样定义的Student,那么我们实际上所谓的元素重复就是指名字相同就元素重复,所以此时我们执行
tudent student1 = new Student("张三",1);Student student2 = new Student("张三", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list = new ArrayList<>();list.add(student1);list.add(student2);list.add(student3);list.add(student4);list.add(student5);list.stream().distinct().forEach(System.out::println);
就会得到
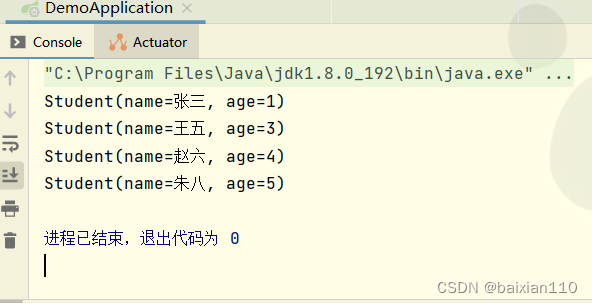
limit
Student student1 = new Student("张三",1);Student student2 = new Student("张三", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list = new ArrayList<>();list.add(student1);list.add(student2);list.add(student3);list.add(student4);list.add(student5);list.stream().limit(3).forEach(System.out::println);

skip
Student student1 = new Student("张三",1);Student student2 = new Student("张三", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list = new ArrayList<>();list.add(student1);list.add(student2);list.add(student3);list.add(student4);list.add(student5);list.stream().skip(1).forEach(System.out::println);
2.映射(map && flatMap && mapToInt)
map
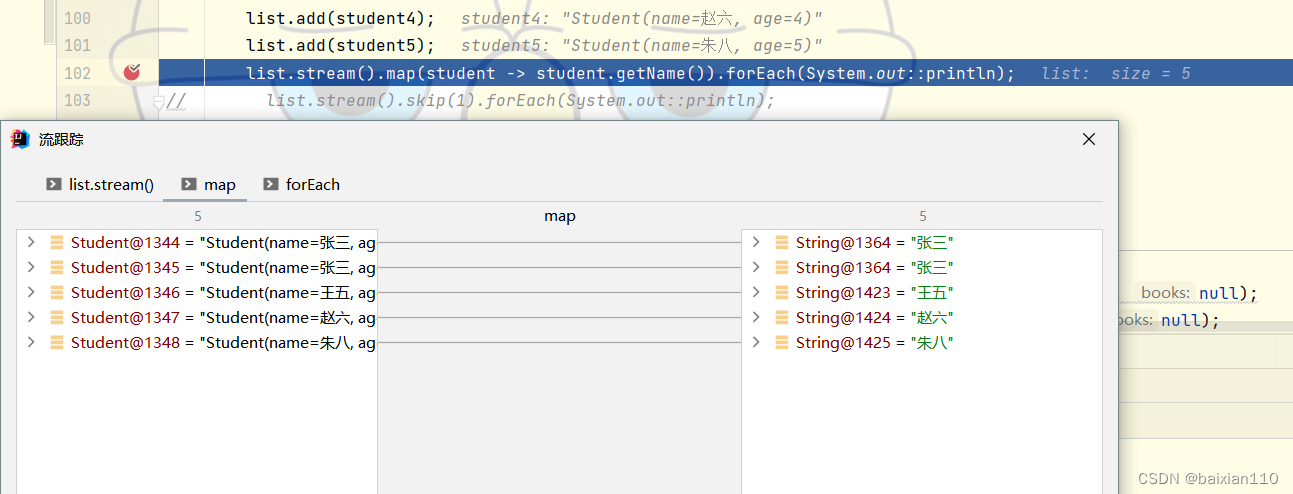
map的主要作用是对对象进行映射,就是可以将一个集合抽离出来,聚和为另外一个集合。比如说我要打印student的name,我可以将每一个student的name抽离出来,单独遍历打印。
Student student1 = new Student("张三",1);Student student2 = new Student("张三", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list = new ArrayList<>();list.add(student1);list.add(student2);list.add(student3);list.add(student4);list.add(student5);list.stream().map(new Function<Student, String>() {/*** Applies this function to the given argument.** @param student the function argument* @return the function result*/@Overridepublic String apply(Student student) {return student.getName();}}).forEach(System.out::println);

替换为lambda表达式
list.stream().map(student -> student.getName()).forEach(System.out::println);
使用调试模式去看整个过程:
再来一个需求,将student里面的age输出,并且统统加10之后返回
list.stream().map(new Function<Student, Integer>() {@Overridepublic Integer apply(Student student) {return student.getAge()+10;}}).forEach(System.out::println);
转化为lambda之后就是这样:
list.stream().map(student -> student.getAge()+10).forEach(System.out::println);
或者也可以两次map去实现
list.stream().map(student->student.getAge()).map(age->age+10).forEach(System.out::println);
其他几个map也差不多
flatmap
但是这里重点去说一下这个flatMap
我们去构建一个Class班级类
@Data
@AllArgsConstructor
public class Class {Integer id;List<Student> studentList ;String className;}
我们想按班级去打印每一个班级的学生
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);List<Student> list2 = new ArrayList<>();list2.add(student3);list2.add(student4);list2.add(student5);Class class1 = new Class(1, list1,"高一1班");Class class2 = new Class(2,list2,"高一2班");List<Class> classList = new LinkedList<>();classList.add(class1);classList.add(class2);classList.stream().flatMap(new Function<Class, Stream<Student>>() {@Overridepublic Stream<Student> apply(Class aClass) {System.out.println(aClass.getClassName());return aClass.getStudentList().stream();}}).forEach(new Consumer<Student>() {@Overridepublic void accept(Student student) {System.out.println(student.getName());}});
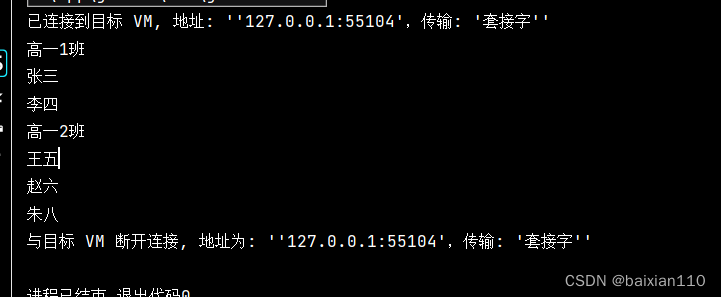
classList.stream().flatMap((Function<Class, Stream<Student>>) aClass -> {System.out.println(aClass.getClassName());return aClass.getStudentList().stream();}).forEach(student -> System.out.println(student.getName()));注意map与flatmap的区别:
欢迎大家去看这篇博客,这篇博客详细说明了map 和 flatmap的区别。
https://blog.csdn.net/weixin_52772307/article/details/128944511
简单来说
对{[1,2,3],[4,5,6,7],[9,10]}来说
map的处理是变成[1,2,3] [4,5,6,7][9,10]
而flatmap处理成[1,2,3,4,5,6,7,8,9,10]
基本数据类型的优化
现在是这样一个需求,将每个学生年龄加10,筛选出大于28岁的学生的年龄,在筛选完之后每个年龄再加2,最后打印
这个需求很简单,用stream流轻松搞定
list1.stream().map(new Function<Student,Integer>() {@Overridepublic Integer apply(Student student) {return student.getAge();}}).map(new Function<Integer, Integer>() {@Overridepublic Integer apply(Integer integer) {return integer+10;}}).filter(new Predicate<Integer>() {@Overridepublic boolean test(Integer integer) {return integer>28;}}).map(new Function<Integer, Integer>() {@Overridepublic Integer apply(Integer integer) {return integer+2;}}).forEach(new Consumer<Integer>() {@Overridepublic void accept(Integer integer) {System.out.println(integer);}});
list1.stream().map(student -> student.getAge()).map(integer -> integer+2).filter(integer -> integer>18).map(integer -> integer+2).forEach(integer -> System.out.println(integer));
但是我们要注意到一个问题
每一次map,比如说integer+10,都会有一次拆箱(将integer变成int),一次装箱(将结果再转为integer)。是想,如果元素非常多,那么光装箱和拆箱操作就会损耗很多性能。
所以SreamAPI提供了mapToInt等API,让其直接转化为int类型进行后续计算。
list1.stream().mapToInt(new ToIntFunction<Student>() {@Overridepublic int applyAsInt(Student value) {return value.getAge();}}).map(new IntUnaryOperator() {@Overridepublic int applyAsInt(int operand) {return operand+10;}}).filter(new IntPredicate() {@Overridepublic boolean test(int value) {return value>28;}}).map(new IntUnaryOperator() {@Overridepublic int applyAsInt(int operand) {return operand+2;}}).forEach(new IntConsumer() {@Overridepublic void accept(int value) {System.out.println(value);}});
list1.stream().mapToInt(value -> value.getAge()).map(operand -> operand+10).filter(value -> value>28).map(operand -> operand+2).forEach(value -> System.out.println(value));
3.排序(sort)
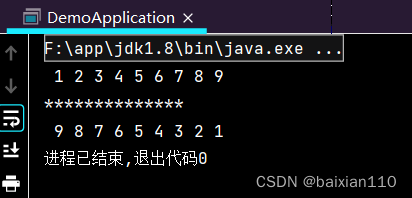
List<Integer> list = Arrays.asList(1,3,2,4,5,7,6,8,9);list.stream().sorted().forEach(o-> System.out.print(" "+o));System.out.println("\n**************");list.stream().sorted(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2-o1;}}).forEach(o-> System.out.print(" "+o));
3.8 Sream结束操作
1. 遍历(forEach)
foreach方法我们之前已经用过很多了,这里不再赘述其具体含义
List<Integer> list = Arrays.asList(1,3,2,4,5,7,6,8,9);list.forEach(o -> System.out.println(o));list.stream().forEach(o-> System.out.println(o));
但是,实际上,在java8之前就有对集合的foreach操作
list.stream().foreach 与 list.foreach()在使用上几乎没有什么差别。
只不过一个是先转换为流操作,一个是直接在集合上操作。
所以单纯的遍历集合的话是没有必要使用list.stream()转化的。
2. 匹配(Match)
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);//所有的元素全部满足匹配条件才会返回true,否则返回falseboolean flag1 = list1.stream().allMatch(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() > 4;}});System.out.println(flag1);//只要有一个元素满足匹配条件就会返回true,否则返回falseboolean flag2 = list1.stream().anyMatch(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() > 4;}});System.out.println(flag2);//所有元素都不满足匹配条件就会返回true,否则返回falseboolean flag3 = list1.stream().noneMatch(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() > 5;}});System.out.println(flag3);
3. 查找( Find)
首先FindAny是寻找到任意一个符合条件的元素(注意并不是顺序查询的,所以并不一定是第一个符合条件的元素)FindFirst才是寻找到第一个符合条件的元素。
我们先来说一下finfAny,注意的是这个接口是没有入参的。
他的返回类型是Optional类型的值

Optional也是java8提供的新类型,他是特意为避免很多空指针异常而设计的,这个我们后面也会去说。
要知道这个Option<Student>类型是不一定会有,所以我们需要一个ifPresent方法来作为下一步动作的判断条件。
假如说需求是输出任意一个年龄大于3的学生的名字
那么我们可以这样写
List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);Optional<Student> student = list1.stream().filter(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge()>2;}}).findAny();student.ifPresent(new Consumer<Student>() {@Overridepublic void accept(Student student) {System.out.println(student);}});
注意:
不难发现,finidAny并不支持条件筛选,只是能做到”查找任意一个“,而条件筛选是交给中间操作filter去做的。
此外笔者还额外注意到
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("王五", 2);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);list1.stream().filter(student -> student.getAge()>2).findAny().ifPresent(student -> System.out.println(student));
下面这个代码调试会发现
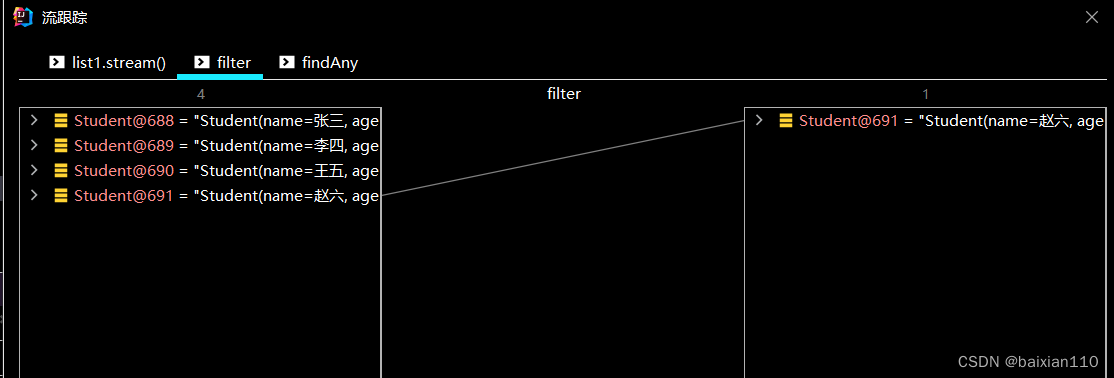
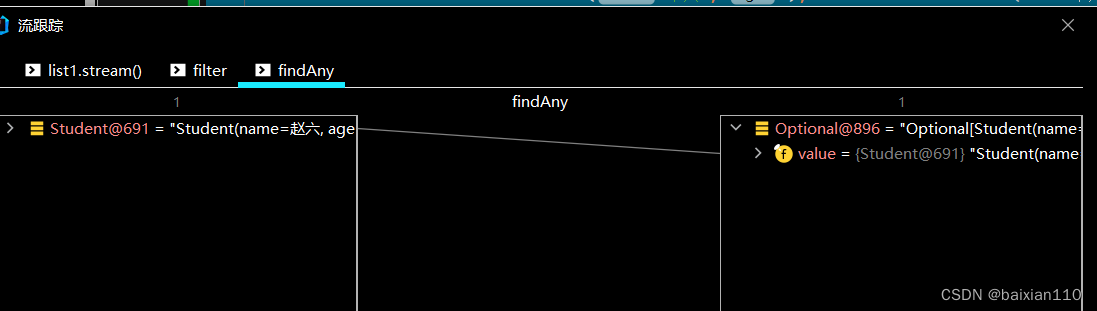
从list.stream()开始就不是将所有元素全部转化为流对象了,而是只会转化为第一个符合条件的元素就会结束。
那么FindFirst就没什么好说的了,此处就不展示了。
4.归并(reduce)
reduce操作相比前面几个操作会复杂一些,首先我们先来看reduce的第一个方法
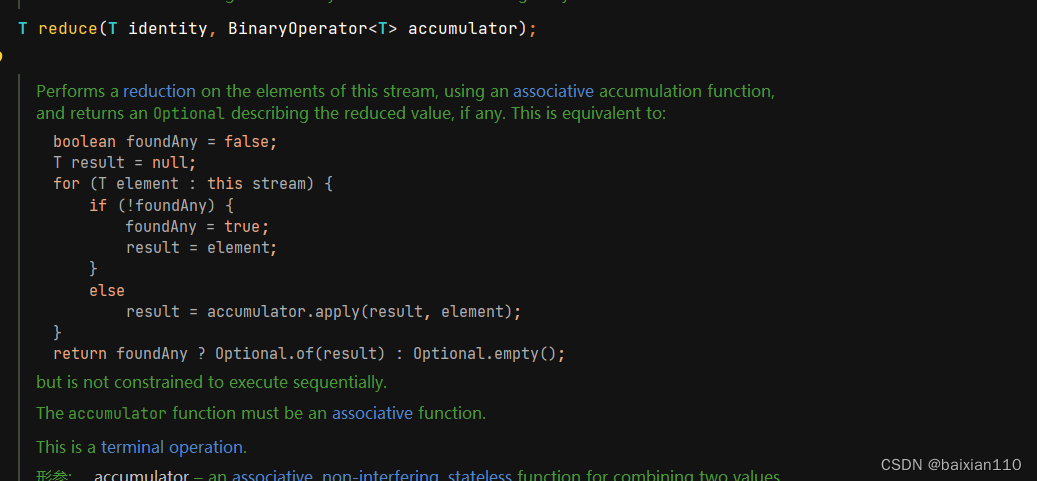
可以看到传入两个参数,一个是泛型类型的identity,一个是BinaryOpetional类型的accumulator
result = accumulator.apply(result, element);这一句实际就是将这两个参数传入去做一个计算,而计算方法我们是可以重写的。
下面需求是计算所有学生的年龄总和。
要计算年龄总和首先肯定需要将数组进行映射成只有年龄。
reduce常和map去联合使用,通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名。
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);Integer sumAge = list1.stream().map(new Function<Student, Integer>() {@Overridepublic Integer apply(Student student) {return student.getAge();}}).reduce(0, new BinaryOperator<Integer>() {@Overridepublic Integer apply(Integer identity, Integer integer2) {return identity + integer2;}});System.out.println(sumAge);
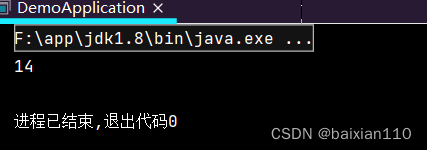
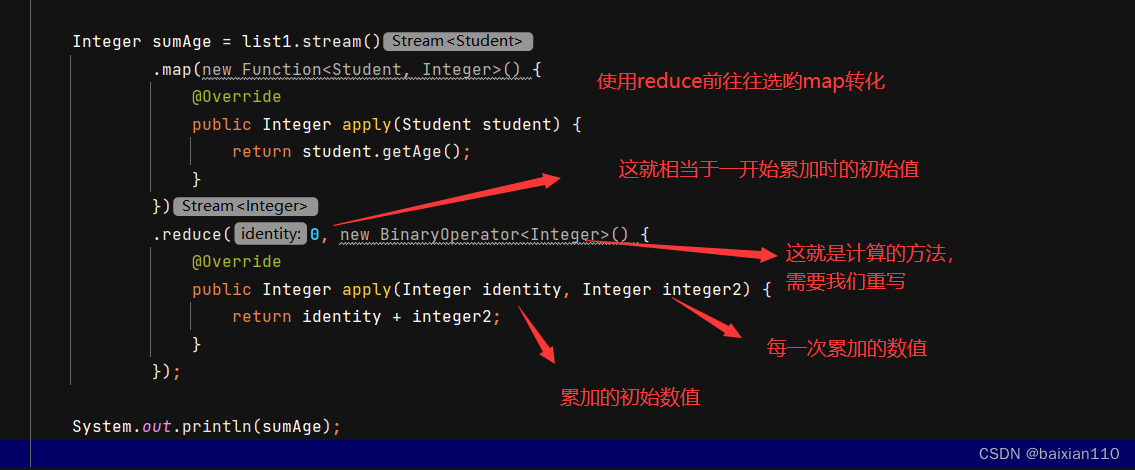
Integer sumAge = list1.stream().map(student -> student.getAge()).reduce(0, (identity, integer2) -> identity + integer2);System.out.println(sumAge);
下面需求是计算所有学生的年龄最大值
Integer maxAge = list1.stream().map(new Function<Student, Integer>() {@Overridepublic Integer apply(Student student) {return student.getAge();}}).reduce(Integer.MIN_VALUE, new BinaryOperator<Integer>() {@Overridepublic Integer apply(Integer integer, Integer integer2) {return integer < integer2 ? integer2 : integer;}});System.out.println(maxAge);
Integer maxAge = list1.stream().map(student -> student.getAge()).reduce(Integer.MIN_VALUE, (integer, integer2) -> integer < integer2 ? integer2 : integer);System.out.println(maxAge);5. 最值(max && min)
获取最大值或者最小值
需求:求所有班级中学生的年龄的最大值
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);List<Student> list2 = new ArrayList<>();list2.add(student3);list2.add(student4);list2.add(student5);Class class1 = new Class(1, list1,"高一1班");Class class2 = new Class(2,list2,"高一2班");List<Class> classList = new LinkedList<>();classList.add(class1);classList.add(class2);Optional<Integer> max = classList.stream().flatMap(new Function<Class, Stream<Student>>() {@Overridepublic Stream<Student> apply(Class aClass) {return aClass.getStudentList().stream();}}).map(new Function<Student, Integer>() {@Overridepublic Integer apply(Student student) {return student.getAge();}}).max(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o1 - o2;}});//注意:max或者min返回的是optional类,要获取到值,需要使用get方法System.out.println(max.get());
Optional<Integer> max = classList.stream().flatMap((Function<Class, Stream<Student>>) aClass -> aClass.getStudentList().stream()).map(student -> student.getAge()).max((o1, o2) -> o1 - o2);//注意:max或者min返回的是optional类,要获取到值,需要使用get方法System.out.println(max.get());
最小值也是一样的,这里就不举例了。
6. 收集collect
collect的使用频率也是非常高的。
Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。
此外,
Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表

我们可以看下面几个需求:
形成所有班级的学生姓名列表(不重复)
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("张三", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);List<Student> list2 = new ArrayList<>();list2.add(student3);list2.add(student4);list2.add(student5);Class class1 = new Class(1, list1,"高一1班");Class class2 = new Class(2,list2,"高一2班");List<Class> classList = new LinkedList<>();classList.add(class1);classList.add(class2);List<String> nameList = classList.stream().flatMap(new Function<Class, Stream<Student>>() {@Overridepublic Stream<Student> apply(Class aClass) {return aClass.getStudentList().stream();}})//去重.distinct().map(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}}).collect(Collectors.toList());System.out.println(nameList);
List<String> nameList = classList.stream().flatMap((Function<Class, Stream<Student>>) aClass -> aClass.getStudentList().stream()).distinct().map(student -> student.getName()).collect(Collectors.toList());System.out.println(nameList);
注意:这里distinction去重是重写了hashCode和equals方法的
@Data//用Data修饰的类就自动重写了get,set 构造方法,tostring方法
@AllArgsConstructor
@EqualsAndHashCode
public class Student {@EqualsAndHashCode.Includeprivate String name;@EqualsAndHashCode.Excludeprivate int age;}
需求:
形成所有班级的学生map(map的key是学生姓名,value是学生对象)(不重复)
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("张三", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);List<Student> list2 = new ArrayList<>();list2.add(student3);list2.add(student4);list2.add(student5);Class class1 = new Class(1, list1,"高一1班");Class class2 = new Class(2,list2,"高一2班");List<Class> classList = new LinkedList<>();classList.add(class1);classList.add(class2);List<String> nameList = classList.stream().flatMap((Function<Class, Stream<Student>>) aClass -> aClass.getStudentList().stream()).distinct().map(student -> student.getName()).collect(Collectors.toList());System.out.println(nameList);Map<String, Student> collect1 = collect.stream().collect(Collectors.toMap(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}}, new Function<Student, Student>() {@Overridepublic Student apply(Student student) {return student;}}));System.out.println(collect1);Map<String, Student> collect1 = collect.stream().collect(Collectors.toMap(student -> student.getName(), student -> student));System.out.println(collect1);
注意,如果这里不去重(注释掉distinct),会报错,这是因为map默认key必须是唯一的,但是这里有两个重名张三。
7. 汇总数量(count)
这个没啥好说的,就是计算元素个数的。
Student student1 = new Student("张三",1);Student student2 = new Student("李四", 2);Student student3 = new Student("王五", 3);Student student4 = new Student("赵六", 4);Student student5 = new Student("朱八", 5);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);long count = list1.stream().count();System.out.println(count);
四、Optional
4.1 概述
在日常开发中,当我们获取一个对象或者一个对象的属性(该属性也是也是一个对象)的时候,难免会遇到空指针异常的问题;这个异常可以说是java里最常见的一个异常了。那么对于空指针异常来说,我们最常见的避免方式就是使用if进行判断从而避免空指针的问题,但是在实际开发中有非常多的对象,以及对象属性,我们不可能考虑的那么全面,此时就需要Optinal这个对象了。optional也是java8新增的特性之一。此外,经过上述的Steam流的学习不难发现,StreamAPI中就有很多Optional的对象返回。
4.2 创建
Optional实际是一个包装类,他将我们原本的对象再进行了一次包装。
我们可以使用Optianal自带的方法去更加优雅的避免空指针异常(虽然并没有感觉有啥优雅的)
Student student1 = null;System.out.println(student1.getName());

我们可以使用Optinal的静态方法ofNullable来把数据封装成一个Optional对象。这样传入的参数无论是不是null都不会有影响。
就如下图这样:
Student student1 = null;Optional<Student> student11 = Optional.ofNullable(student1);System.out.println(student11.get().getName());
注意
封装成Optional之后,需要先调用get()方法,获取实际对象。
此外,一开始笔者在编写用例的时候出现了一个错误,笔者以为
Student student = new Student;
这个使用student.getName会有空指针异常的问题,但是并没有,这个对象是存在的,只是属性都为null才对。
但是实际上上述代码依旧会报错,但并不是空指针异常的错误

,我们之所以会用Optional一个最简单的原因就是尽量避免空指针异常导致程序直接停止运行,但是在业务上,我们还是要避免去执行空指针异常之后的代码。
所以对于Optional有一个ifPresent方法,就类似判断该Optional中的对象是不是null值,如果不是才会消费(consumer)
Student student1 = null;
// System.out.println(student1.getName());Optional<Student> student11 = Optional.ofNullable(student1);//尽量避免打印null值的情况
// System.out.println(student11.get().getName());//student11.ifPresent(new Consumer<Student>() {@Overridepublic void accept(Student student) {System.out.println(student.getName());}});
Student student1 = null;
// System.out.println(student1.getName());Optional<Student> student11 = Optional.ofNullable(student1);//尽量避免打印null值的情况
// System.out.println(student11.get().getName());//student11.ifPresent(student -> System.out.println(student.getName()));
这样就遇到null就不会再执行打印操作了
那么笔者在学到这里的时候就有疑问了?这和if判断为空不一样吗,还是很复杂啊,没有起到简化代码的效果啊!
那是因为我们上述的例子并没有体现实际开发中Optional真正的使用场景。
要知道用if和用optional两者最大的区别是Optional是Java8本身就定义好的一个对象,他是一个模板。所以我们大可以在定义对象的时候就将该对象定义为Optinal类型,这样不就省去了所谓的创建了吗。
就像这样:
Optional<Student> optionalStudent = null;optionalStudent.ifPresent(student -> System.out.println(student.getName()));
实际上在开发中我们获取对象一般都是数据库中查出来,如果我们使用的是MyBatis3.5及以上框架的话,实际上是支持Optinal的,我们可以直接将dao层的对象直接就定义为Option类型。MyBatis会自己将返回的数据封装成Optional对象。
此外,Optional还有几个不常见的方法
如果你能确定返回值不为null的话,可以使用Optional.of()方法创建Optional类。(所以这个方法就很鸡肋);
empty()是创建一个空的Optional类
4.3 安全的获取值
Optional最大的好处就是能够让我们安全的获取相应的值,那么Optional有一下几种方式可以相对安全的获取值
一种是ifpresent()方法
Student student = null;Optional<Student> optionalStudent = Optional.ofNullable(student);optionalStudent.ifPresent(new Consumer<Student>() {@Overridepublic void accept(Student student) {System.out.println(student.getName());}});
此外,Optional还提供了如果输入值为null,就改为返回默认值的情况,这种可以使用函数orElseGet返回默认值
Student student = null;Optional<Student> optionalStudent = Optional.ofNullable(student);optionalStudent.ifPresent(new Consumer<Student>() {@Overridepublic void accept(Student student) {System.out.println(student.getName());}});System.out.println(optionalStudent.orElseGet(new Supplier<Student>() {@Overridepublic Student get() {return new Student("默认值",0);}}));
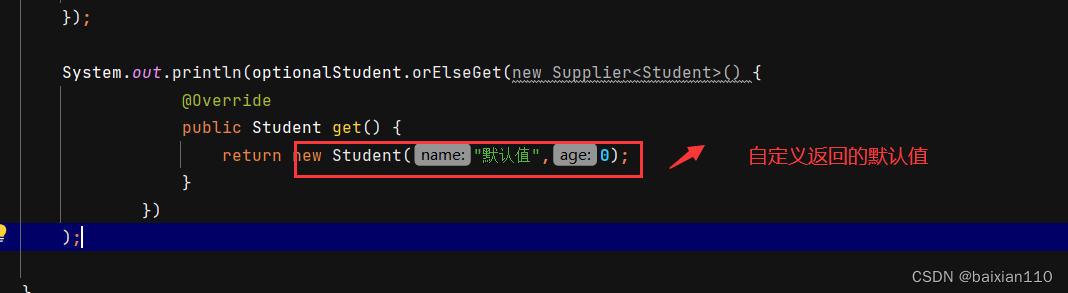
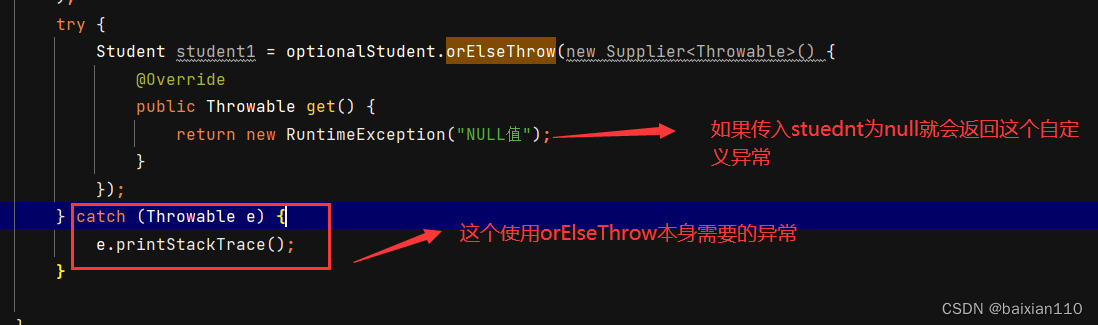
最后一种就是如果出现null值我们能不能抛出自定义异常呢?当然可以,可以使用orElsethrow方法
Student student = null;Optional<Student> optionalStudent = Optional.ofNullable(student);try {Student student1 = optionalStudent.orElseThrow(new Supplier<Throwable>() {@Overridepublic Throwable get() {return new RuntimeException("NULL值");}});} catch (Throwable e) {e.printStackTrace();}
实际上Optional不仅有ifpresent方法,还有ispresent方法
与ifPresent需要重写Consumer消费不同的,isPresnet朴实无华,是通过搭配if去判断的,因为他的返回值是个boolean的值
Student student = null;Optional<Student> studentOptional = Optional.ofNullable(student);boolean ispresent = studentOptional.isPresent();if(ispresent){System.out.println(studentOptional.get().getName());}else{System.out.println("默认值");}
4.4 过滤
Optional还提供了一个过滤方法,当满足过滤条件时,正常返回数据,当不满足过滤条件的时候,直接返回Optinal的空值(return Optional.empty())
看如下代码
Student student = null;Optional<Student> optionalStudent = Optional.ofNullable(student);Optional<Student> optionalStudent1 = optionalStudent.filter(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() > 18;}});System.out.println(optionalStudent1.orElseGet(new Supplier<Student>() {@Overridepublic Student get() {return new Student("默认值",0);}}));
输入一个年龄为16
Student student = new Student("zhangsan",16);Optional<Student> optionalStudent = Optional.ofNullable(student);Optional<Student> optionalStudent1 = optionalStudent.filter(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() > 18;}});System.out.println(optionalStudent1.orElseGet(new Supplier<Student>() {@Overridepublic Student get() {return new Student("默认值",0);}}));
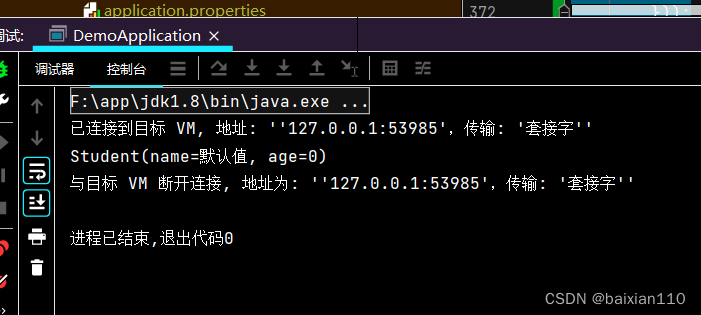
Student student = new Student("zhangsan",20);Optional<Student> optionalStudent = Optional.ofNullable(student);Optional<Student> optionalStudent1 = optionalStudent.filter(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() > 18;}});System.out.println(optionalStudent1.orElseGet(new Supplier<Student>() {@Overridepublic Student get() {return new Student("默认值",0);}}));
4.5 数据转换
Optional和Stream流一样,同样有一个map方法来实现数据转化
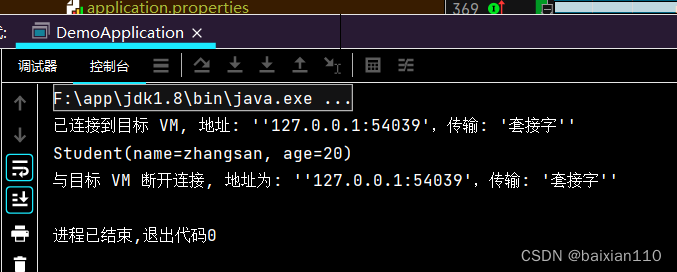
如果输入的student是一个null值
Student student1 = null;Optional<Student> optionalStudent = Optional.ofNullable(student1);Optional<String> s = optionalStudent.map(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}});System.out.println(s.orElseGet(new Supplier<String>() {@Overridepublic String get() {return "默认值";}}));
如果输入的是一个正常值
Student student1 = new Student("张三",1);Optional<Student> optionalStudent = Optional.ofNullable(student1);Optional<String> s = optionalStudent.map(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}});System.out.println(s.orElseGet(new Supplier<String>() {@Overridepublic String get() {return "默认值";}}));

在了解完Lambda表达式和stream流之后,我们再来总结一下函数式接口
函数式接口常见的有四大类型
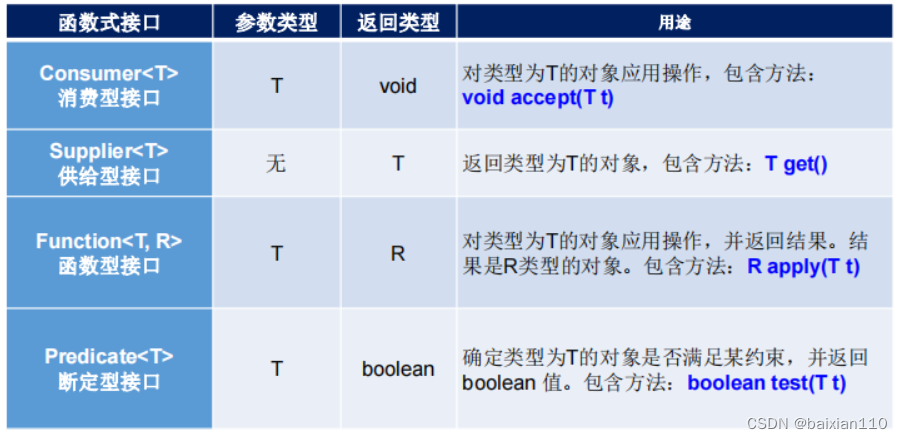
上述是四个,实际上JDK中的函数式接口远不止四个。
我们随便打开一个函数式接口,然后再在项目结构的左上角点击一个圆圈
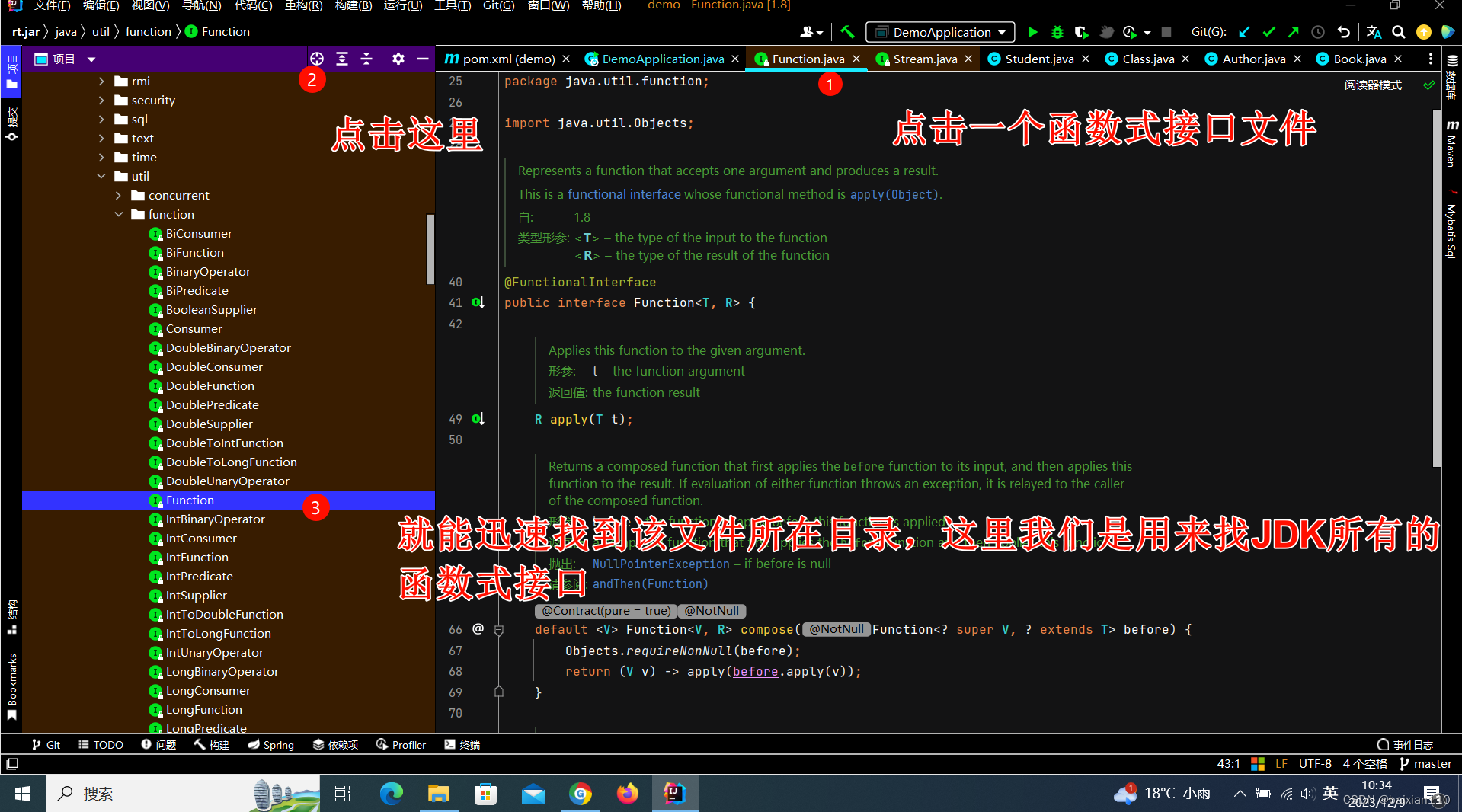
这里说一下,以Bi开头的函数式接口实际表示有两个入参。
接口中的默认方法与静态方法
这里需要额外再提一提java的又一新特性,对于接口,可以定义全局常量,抽象方法,默认方法以及静态方法。
默认方法
定义
Java 8中允许接口中包含具有具体实现的方法,该方法称为“默认方法”,默认方法使用 default 关键字修饰。
”类优先”原则
默认方法的执行遵循“类优先”原则
若一个接口中定义了一个默认方法,而另外一个父类或接口中又定义了一个同名的方法时
(情况一)选择父类中的方法。如果一个父类提供了具体的实现,那么接口中具有相同名称和参数的默认方法会被忽略。
(情况二)接口冲突。如果一个父接口提供一个默认方法,而另一个接口也提供了一个具有相同名称和参数列表的方法(不管方法是否是默认方法),那么必须覆盖该方法来解决冲突
函数式接口中的默认方法
很多函数式接口除了抽象方法外都有默认方法
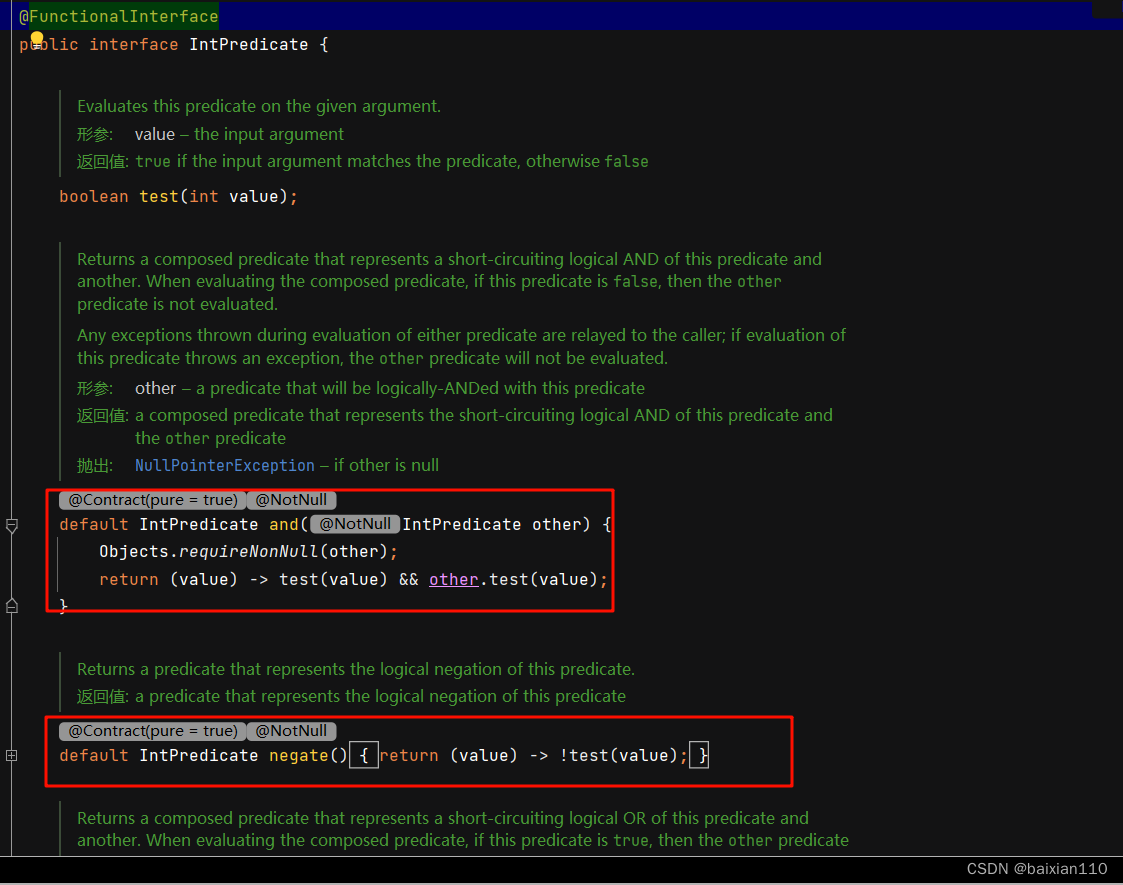
比如说在Predicate接口中(Stream中fiter这个API会实例这个接口)中就有and 和 or 这两个接口。
他的作用实际上和我们一贯的and 和 or作为逻辑判断式一样的作用。
比如说我们需要打印年龄在18-22之间的学生姓名
Student student1 = new Student("张三",18);Student student2 = new Student("李四", 21);Student student3 = new Student("王五", 22);Student student4 = new Student("赵六", 19);Student student5 = new Student("朱八", 20);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);List<String> nameList = list1.stream().filter(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() < 22;}}.and(new Predicate<Student>() {@Overridepublic boolean test(Student student) {return student.getAge() > 18;}})).map(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}}).collect(Collectors.toList());System.out.println(nameList);

List<String> nameList = list1.stream().filter(((Predicate<Student>) student -> student.getAge() < 22).and(student -> student.getAge() > 18)).map(student -> student.getName()).collect(Collectors.toList());System.out.println(nameList);
方法引用
什么是方法引用
当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!
方法引用可以看做是Lambda表达式深层次的表达。换句话说,方法引用就是Lambda表达式,也就是函数式接口的一个实例,通过方法的名字来指向一个方法,可以认为是Lambda表达式的一个语法糖。
方法引用的规则
实现接口的抽象方法的参数列表和返回值类型,必须与方法引用的方法的参数列表和返回值类型保持一致!((针对于情况1和情况2))
格式
使用操作符 “::” 将类(或对象) 与 方法名分隔开来。
使用方法
我们可以先举个例子看一下
在上一个例子中mapAPI中我们使用的lambda就可以转化为方法引用,我们将鼠标放在lambda上,就可以显示出下面的图。然后直接转化就行。
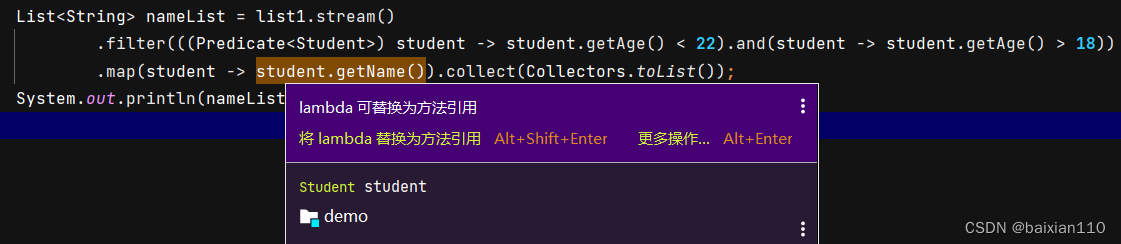
List<String> nameList = list1.stream().filter(((Predicate<Student>) student -> student.getAge() < 22).and(student -> student.getAge() > 18)).map(Student::getName).collect(Collectors.toList());System.out.println(nameList);
那么什么情况Lambda可以变成方法引用呢?
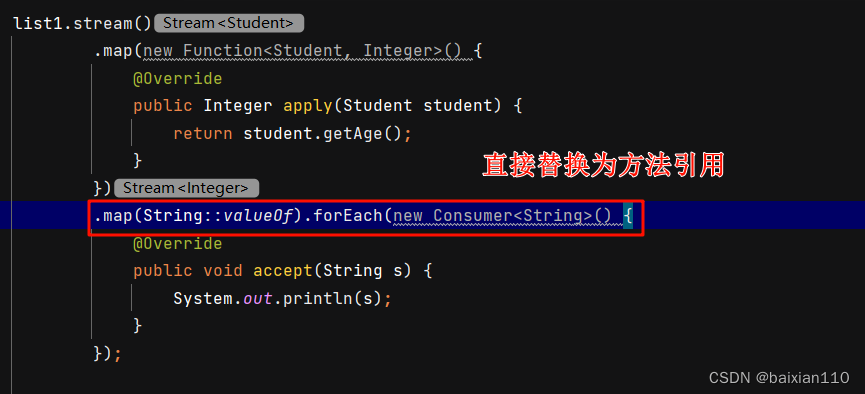
1.引用类的静态方法
格式:
类名::方法名
使用前提:
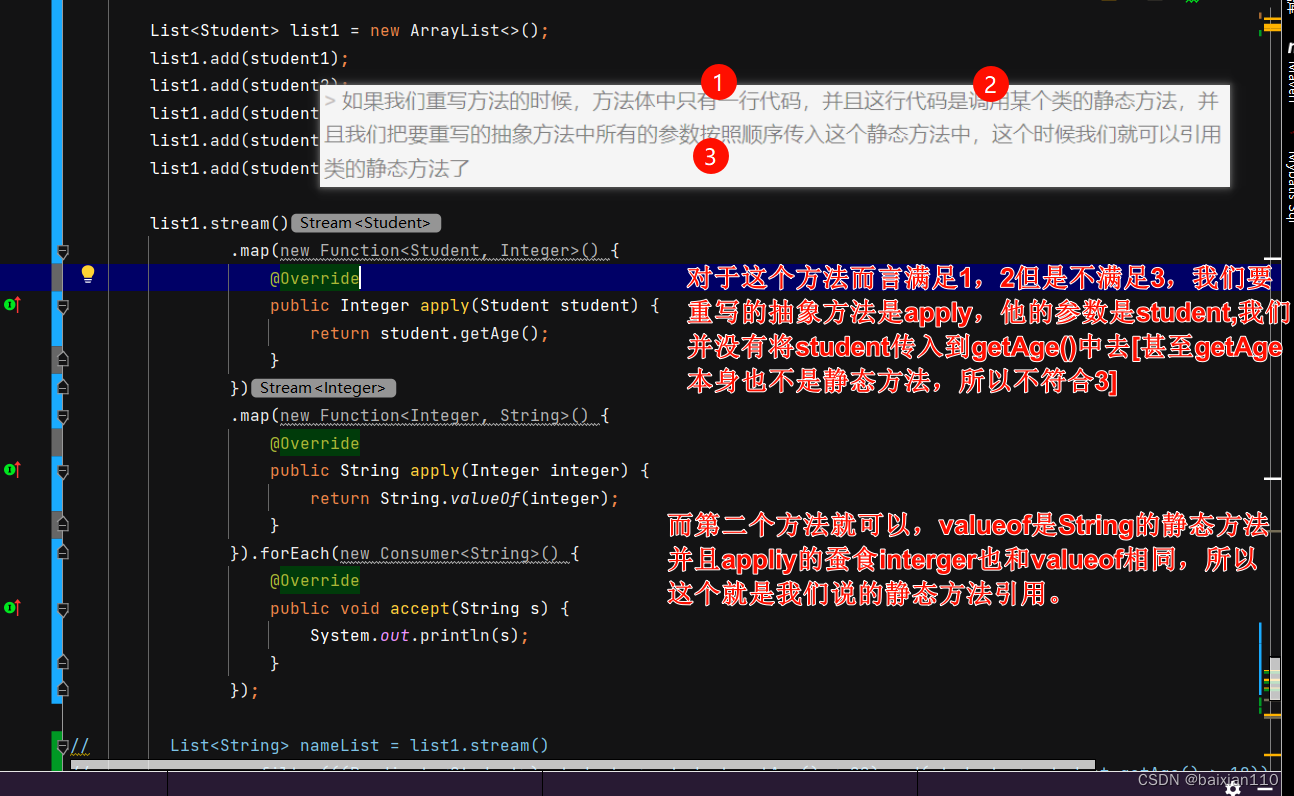
如果我们重写方法的时候,方法体中只有一行代码,并且这行代码是调用某个类的静态方法,并且我们把要重写的抽象方法中所有的参数按照顺序传入这个静态方法中,这个时候我们就可以引用类的静态方法了
例子:
我们来看下面的代码:
Student student1 = new Student("张三",18);Student student2 = new Student("李四", 21);Student student3 = new Student("王五", 22);Student student4 = new Student("赵六", 19);Student student5 = new Student("朱八", 20);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);list1.stream().map(new Function<Student, Integer>() {@Overridepublic Integer apply(Student student) {return student.getAge();}}).map(new Function<Integer, String>() {@Overridepublic String apply(Integer integer) {return String.valueOf(integer);}}).forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}});
2.引用对象的实例方法
格式:
对象名::方法名
使用前提
如果我们在重写方法的时候,方法体中只有一行代码,并且这行代码是调用了某个对象的成员方法,并且我们要把重写的抽象方法中的所有参数都按照顺序传到这个成员方法里面,这个时候我们就可以引用对象的实例方法。
例子:
Student student1 = new Student("张三",18);Student student2 = new Student("李四", 21);Student student3 = new Student("王五", 22);Student student4 = new Student("赵六", 19);Student student5 = new Student("朱八", 20);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);StringBuilder stringBuilder = new StringBuilder();list1.stream().map(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}}).forEach(new Consumer<String>() {@Overridepublic void accept(String s) {stringBuilder.append(s);}});
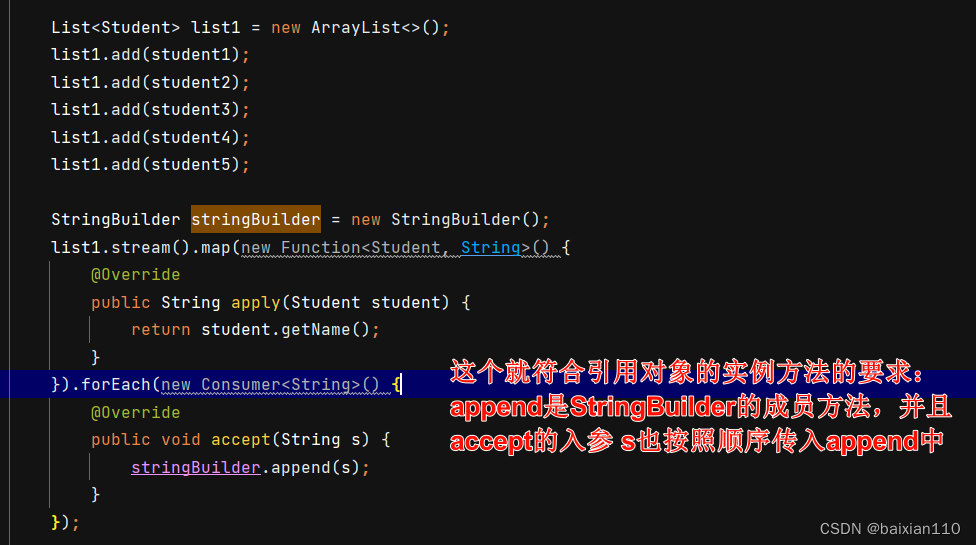
StringBuilder stringBuilder = new StringBuilder();list1.stream().map(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}}).forEach(stringBuilder::append);
3.引用类的实例方法
格式
类名::方法名
使用前提
如果我们在重写方法的时候,方法体只有一行代码,并且这行代码是调用了第一个参数的成员方法,并且我们把要重写的抽象方法中剩余参数都按照顺序传入到这个成员方法中,这个时候我们就可以引用类的实例方法了。
例子
public static void main(String[] args) {subName("baixian", new UseString() {@Overridepublic String use(String str, int start, int length) {return str.substring(start,length);}});}interface UseString{String use(String str,int start,int length);}public static String subName(String name,UseString useString){int start = 0;int length = 1;return useString.use(name,start,length);}
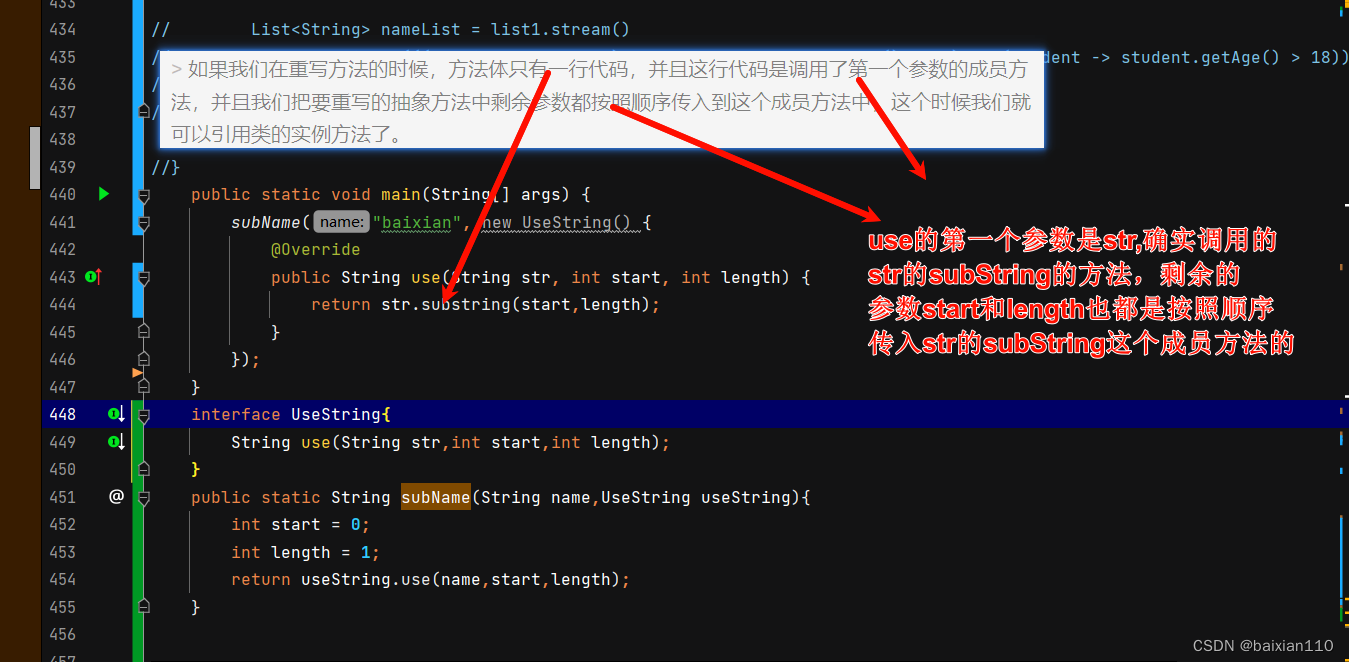
public static void main(String[] args) {subName("baixian", String::substring);}interface UseString{String use(String str,int start,int length);}public static String subName(String name,UseString useString){int start = 0;int length = 1;return useString.use(name,start,length);}
看完这个,会发现,这个是不是很难记,所以学这个知识的最好方法就是不记!(因为用的不太多,这个可读性也不好。)
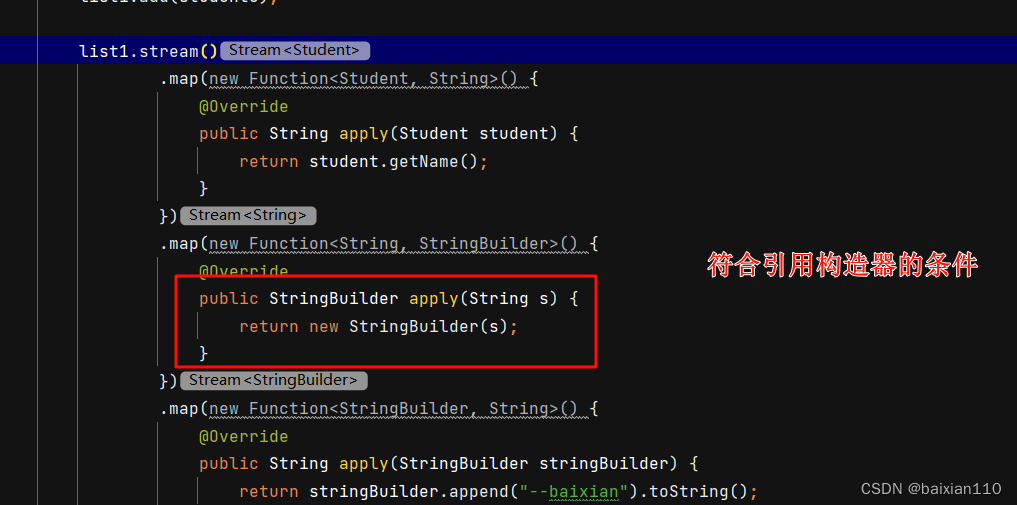
4.构造器引用
格式
类名::new
使用前提
如果我们在重写方法的时候,方法体只有一行代码,并且这行代码是调用某个类的构造方法,并且我们把要重写的抽象方法中的所有的参数都按照顺序传入这个构造方法中,这个时候我们就可以引用构造器了。
例子
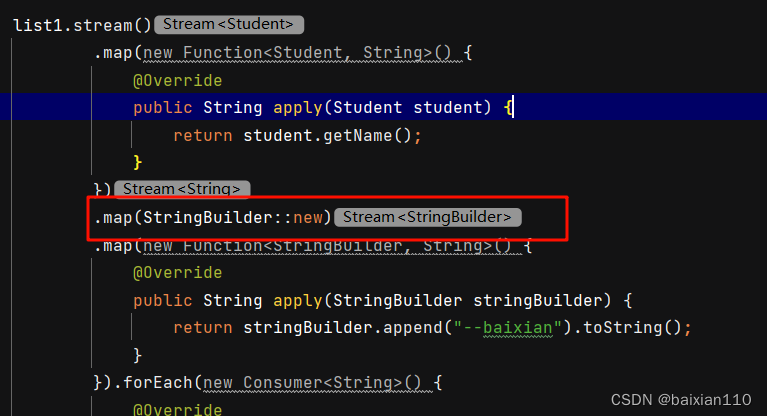
Student student1 = new Student("张三",18);Student student2 = new Student("李四", 21);Student student3 = new Student("王五", 22);Student student4 = new Student("赵六", 19);Student student5 = new Student("朱八", 20);List<Student> list1 = new ArrayList<>();list1.add(student1);list1.add(student2);list1.add(student3);list1.add(student4);list1.add(student5);list1.stream().map(new Function<Student, String>() {@Overridepublic String apply(Student student) {return student.getName();}}).map(new Function<String, StringBuilder>() {@Overridepublic StringBuilder apply(String s) {return new StringBuilder(s);}}).map(new Function<StringBuilder, String>() {@Overridepublic String apply(StringBuilder stringBuilder) {return stringBuilder.append("--baixian").toString();}}).forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}});
五、并行流
5.1 并行流的创建
有时候,再数据处理不需要串行操作的时候,我们可以使用并行流对数据进行处理,可以更快的获取到结果。对于并行流的获取,一般有两种方式
Stream<Student> parallel = list1.stream().parallel();Stream<Student> studentStream = list1.parallelStream();
5.2 流的监视
比如说我要去看并行流和串行流的线程情况
并行流
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);Integer integer = stream.parallel().peek(new Consumer<Integer>() {@Overridepublic void accept(Integer integer) {System.out.println(integer+"---"+Thread.currentThread().getName());}}).filter(o -> o > 2).reduce((result, ele) -> result + ele).get();System.out.println(integer);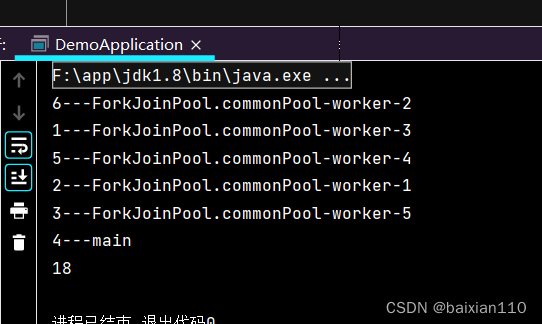
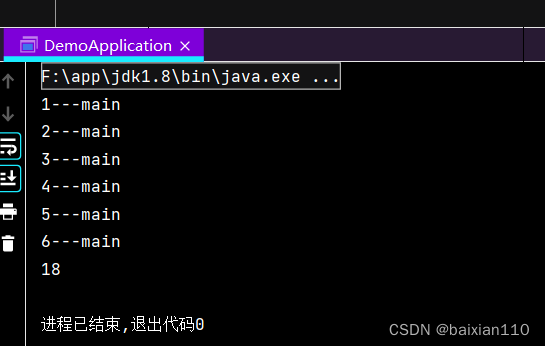
串行流
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);Integer integer = stream.peek(new Consumer<Integer>() {@Overridepublic void accept(Integer integer) {System.out.println(integer+"---"+Thread.currentThread().getName());}}).filter(o -> o > 2).reduce((result, ele) -> result + ele).get();System.out.println(integer);}
写在最后:
java8的新特性之一函数式编程就暂时介绍到这里了!
再次感谢本文章所参考的视频和文章作者,本博客不用于商业用途,如有侵权烦请告知!
本博文有不足、错误、遗漏等处欢迎评论区或者私信指出。
本篇博文耗时一周多的时间完成,都看到这里了,不如三连之后再走吧!

)
)


——软件安装与使用(5))









以及进程回收)



