聚簇索引和非聚簇索引
聚簇索引和非聚簇索引是 InnoDB 里面的叫法
一张表它一定有聚簇索引,一张表只有一个聚簇索引在物理上也是连续存储的
它产生的过程如下:
- 表中有无有主键索引,如果有,则使用主键索引作为聚簇索引;
- 如果没有主键索引,则看表中有无唯一索引,那么使用第一个唯一索引;
- 如果以上两个条件都不满足,InnoDB 则会生成隐藏聚簇索引。
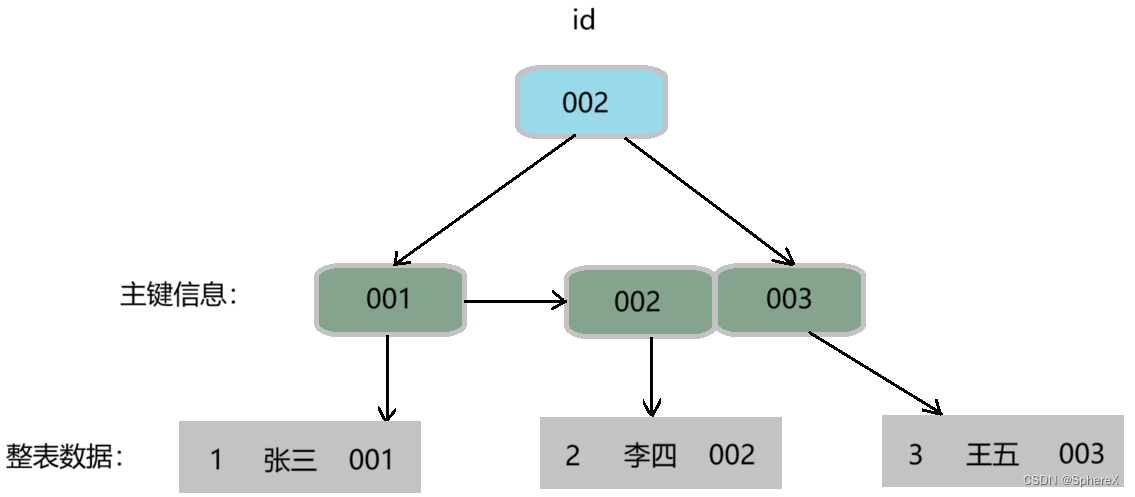
聚簇索引
聚簇索引一般是主键索引,
例如主键索引 id 对应的聚簇索引结构图(叶子节点存储整表数据):
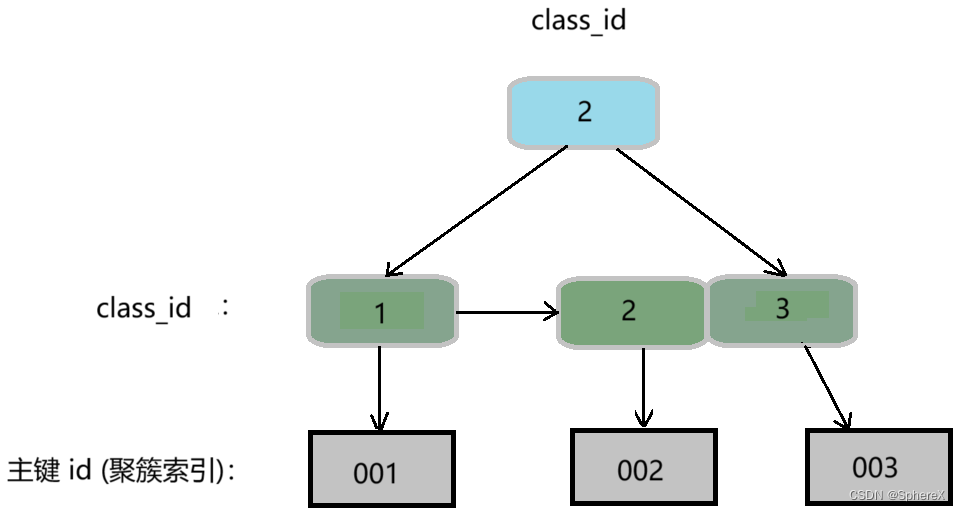
非聚簇索引
非聚簇索引在 InnoDB 也叫做二级索引,非聚簇索引是普通列的索引(非主键索引)
例如普通 class_id 对应的非聚簇索引结构图(叶子节点存储的是聚簇索引):
MySQL的InnoDB索引数据结构是B+树
聚簇索引叶子结点存储的是行数据,而非聚簇索引叶子节点存储的是聚簇索引,因此通过聚簇索引可以找到真正的行数据;
由于非聚簇索引的叶子结点存储的是聚簇索引,因此使用非聚簇索引还需要进行回表查询,所以在查询效率方面,聚簇索引要高于非聚簇索引;
聚簇索引一般为主键索引,而一个表中只能有一个主键,因此一个表中也只能有一个聚簇索引,而非聚簇索引则没有数量上的限制。
什么是回表查询
由于非聚簇索引的叶子节点存储的不是真正的数据,而是聚簇索引,所以在使用普通索引进行查询操作时,会先查询到聚簇索引,然后再去聚簇索引对应的 B+ 数去查询真正的数据,这个过程就叫做回表查询。
例子
下面我们创建了一个学生表,做三种查询,来说明什么情况下是聚簇索引,什么情况下不是。
create table student (id bigint,no varchar(20) ,name varchar(20) ,address varchar(20) ,PRIMARY KEY (`branch_id`) USING BTREE,UNIQUE KEY `idx_no` (`no`) USING BTREE
)ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;第一种,直接根据主键查询获取所有字段数据,此时主键是聚簇索引,因为主键对应的索引叶子节点存储了id=1的所有字段的值。
select * from student where id = 1
第二种,根据编号查询编号和名称,编号本身是一个唯一索引,但查询的列包含了学生编号和学生名称,当命中编号索引时,该索引的节点的数据存储的是主键ID,需要根据主键ID重新查询一次,所以这种查询下no不是聚簇索引
select no,name from student where no = 'test'
第三种,我们根据编号查询编号(有人会问知道编号了还要查询?要,你可能需要验证该编号在数据库中是否存在),这种查询命中编号索引时,直接返回编号,因为所需要的数据就是该索引,不需要回表查询,这种场景下no是索引覆盖
select no from student where no = 'test'
主键一定是聚簇索引,MySQL的InnoDB中一定有主键,即便研发人员不手动设置,则会使用unique索引,没有unique索引,则会使用数据库内部的一个行的id来当作主键索引,其它普通索引需要区分SQL场景,当SQL查询的列就是索引本身时,我们称这种场景下该普通索引也可以叫做聚簇索引,MyisAM引擎没有聚簇索引。
什么是索引覆盖
索引覆盖是指在一个查询语句中,某个索引已经 "覆盖了" 需要被查询出来的列,此时就不需要进行回表查询了,这就叫做索引覆盖!!(索引覆盖它是非聚簇索引中的一个特殊情况)
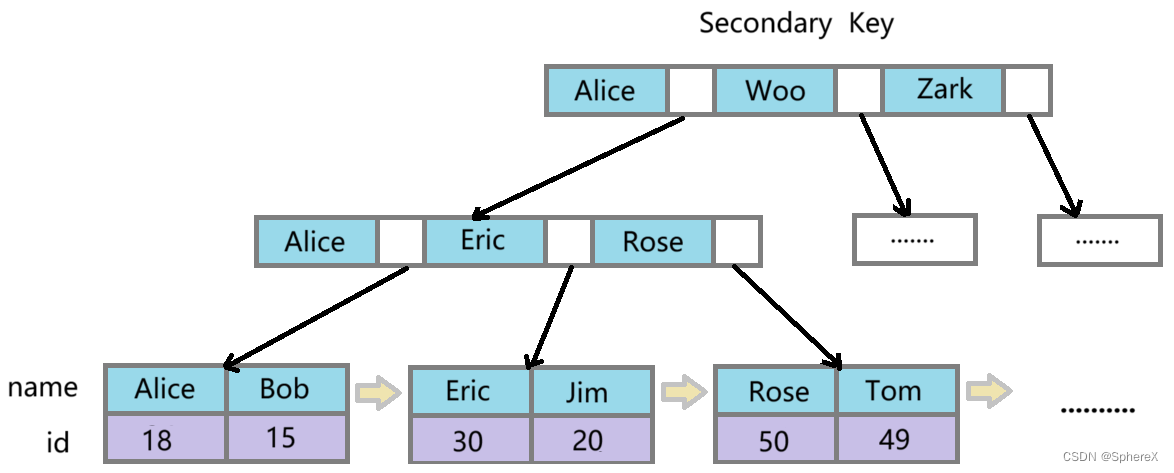
当我们写了这样一个 SQL,实际上它走的是辅助索引,结构如下图:
select id from student where name = 'Bob';
- 辅助索引(非聚簇索引)中的查询,一般是需要查询两次,第一次查询出聚簇索引,然后根据聚簇索引回表查询,最终拿到行数据。
- 但是此处我的查询需求刚好就是聚簇索引,因此一次查询就可以拿到需要的列,不需要进行回表,这就是索引覆盖~
以下四种情况都属于索引覆盖 >>
// 联合索引 (name,age)
select name from student where.....
select age from student where.....
select name,age from student where.....
select address,name,age from student where address = '深圳';
最后一个 SQL 因为 where 条件后面可以知道 address,所以也不需要回表查询!!
索引下推
索引下推是指在查询非聚簇索时,拿到了叶子结点的聚簇索引,然后对聚簇索引中包含的字段先做判断,直接过滤掉不满足条件的记录,从而减少回表次数,这就是索引下推!!(索引下推是在 MySQL 5.6 之后才引入的,它属于非聚簇索引中功能)
以 user 表中的联合索引(name,age)为例:
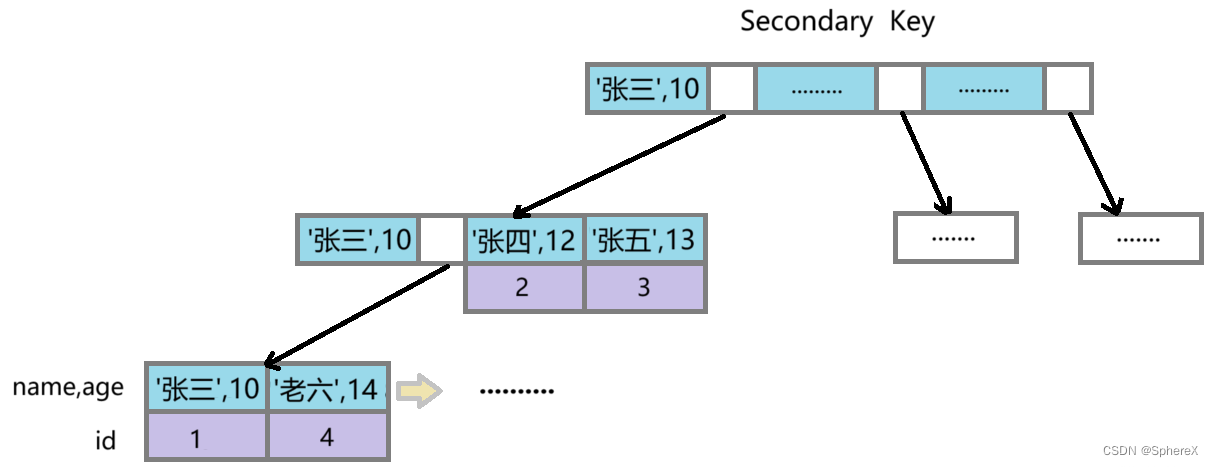
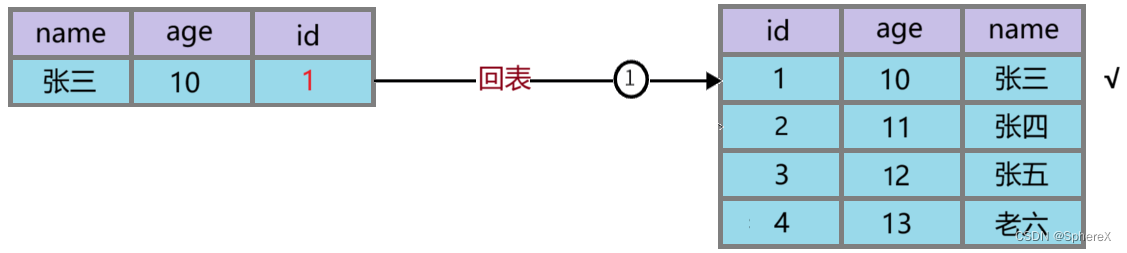
select * from user where name='张%' and age='10';// 表中有四条数据
// 1 张三 10
// 2 张四 11
// 3 张五 12
// 4 老六 13MySQL 5.6 之前没有索引下推,它的执行流程如下:
① 在非聚簇索引中根据 name='张%' 查到聚簇索引中匹配的 id
② 使用匹配的 id 进行回表查询
此时会进行三次回表操作,而联合索引中的 age 字段就没用上。
MySQl 5.6 之后引入索引下推,它会根据 name='张%' 和 age 一起过滤数据:
【好处】:它的第二步操作就可以节省回表的次数
② 使用匹配的 id 进行回表查询
引入索引下推后,只执行了一次回表查询,这就是索引下推的好处。
什么是最左匹配原则
- 最左匹配原则是指索引以最左边的为起点,任何连续的索引都能匹配上,
- 当遇到范围查询 (>、<、between、like) 就会停止匹配。
比如联合索引 index(a,b,c),以下 SQL 来理解什么是最左匹配原则:
select * from user where a=1; // 只使用索引 aselect * from user where b=2; // 不使用索引select * from user where c=3; // 不使用索引select * from user where a=1 and b=2; // 只使用索引 a,bselect * from user where a=1 and c=3; // 只是用索引 aselect * from user where b=2 and c=3; // 不使用索引select * from user where a=1 and b=2 and c=3; // 使用索引 a,b,cselect * from user where a=1 and b like '%xxx' and c=3; // 只使用索引 a,b【疑惑一】
不是说使用了 like,就停止匹配了吗,为什么前面的索引下推使用了 name='张%' 还能再拿 age 进行过滤呢 ?
对于 like 查询,它的常见写法有三种:
模糊匹配后面任意字符:like '张%'
模糊匹配前面任意字符:like '%张'
模糊匹配前后任意字符:like '%张%'
这三种情况,只有第一种情况是会走索引的,其他的都会导致索引失效,所以前面索引下推例子中的 name='张%' 是不会停止匹配的~
【疑惑二】
当我们写出这样的条件语句 where a=1 and c=3 and b=2 时,引擎为什么不把它调整为 a,b,c 的顺序呢?
MySQL 8.0 之后才涉及到这样的调优,但是具体会不会调优,是不一定的,因为索引调优的主动权在索引的优化器里面的,而优化器这个东西,它很玄学,所以不知道它会不会进行调优。