前言
前段时间有同学在微信群里提问,要使用.NET开发一个简单的爬虫功能但是没有做过无从下手。今天给大家推荐一个轻量、灵活、高性能、跨平台的分布式网络爬虫框架(可以帮助 .NET 工程师快速的完成爬虫的开发):DotnetSpider。
注意:为了自身安全请在国家法律允许范围内开发网络爬虫功能。
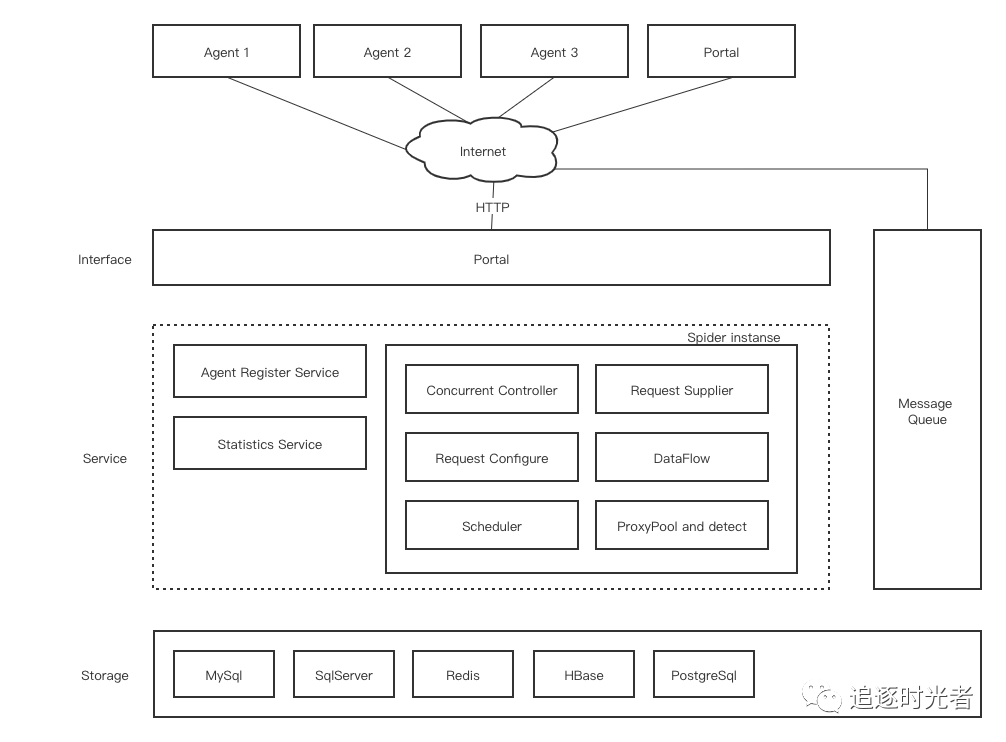
框架设计图
整个爬虫设计是纯异步的,利用消息队列进行各个组件的解耦,若是只需要单机爬虫则不需要做任何额外的配置,默认使用了一个内存型的消息队列;若是想要实现一个纯分布式爬虫,则需要引入一个消息队列即可,后面会详细介绍如何实现一个分布式爬虫。
框架源码
开发爬虫需求
爬取博客园10天推荐排行第一页的文章标题、文章简介和文章地址,并将其保存到对应的txt文本中。
请求地址:https://www.cnblogs.com/aggsite/topdiggs

快速开始
创建SpiderSample控制台
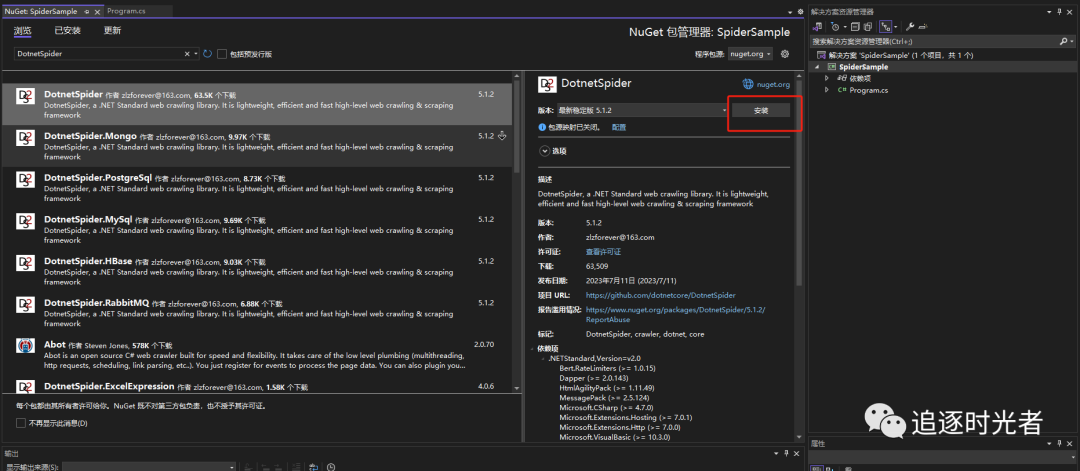
安装DotnetSpider Nuget包
搜索:DotnetSpider
添加Serilog日志组件
搜索:Serilog.AspNetCore

RecommendedRankingModel
public class RecommendedRankingModel{/// <summary>/// 文章标题/// </summary>public string ArticleTitle { get; set; }/// <summary>/// 文章简介/// </summary>public string ArticleSummary { get; set; }/// <summary>/// 文章地址/// </summary>public string ArticleUrl { get; set; }}RecommendedRankingSpider
public class RecommendedRankingSpider : Spider{public RecommendedRankingSpider(IOptions<SpiderOptions> options,DependenceServices services,ILogger<Spider> logger) : base(options, services, logger){}public static async Task RunAsync(){var builder = Builder.CreateDefaultBuilder<RecommendedRankingSpider>();builder.UseSerilog();builder.UseDownloader<HttpClientDownloader>();builder.UseQueueDistinctBfsScheduler<HashSetDuplicateRemover>();await builder.Build().RunAsync();}protected override async Task InitializeAsync(CancellationToken stoppingToken = default){// 添加自定义解析AddDataFlow(new Parser());// 使用控制台存储器AddDataFlow(new ConsoleStorage());// 添加采集请求await AddRequestsAsync(new Request("https://www.cnblogs.com/aggsite/topdiggs"){// 请求超时10秒Timeout = 10000});}class Parser : DataParser{public override Task InitializeAsync(){return Task.CompletedTask;}protected override Task ParseAsync(DataFlowContext context){var recommendedRankingList = new List<RecommendedRankingModel>();// 网页数据解析var recommendedList = context.Selectable.SelectList(Selectors.XPath(".//article[@class='post-item']"));foreach (var news in recommendedList){var articleTitle = news.Select(Selectors.XPath(".//a[@class='post-item-title']"))?.Value;var articleSummary = news.Select(Selectors.XPath(".//p[@class='post-item-summary']"))?.Value?.Replace("\n", "").Replace(" ", "");var articleUrl = news.Select(Selectors.XPath(".//a[@class='post-item-title']/@href"))?.Value;recommendedRankingList.Add(new RecommendedRankingModel{ArticleTitle = articleTitle,ArticleSummary = articleSummary,ArticleUrl = articleUrl});}using (StreamWriter sw = new StreamWriter("recommendedRanking.txt")){foreach (RecommendedRankingModel model in recommendedRankingList){string line = $"文章标题:{model.ArticleTitle}\r\n文章简介:{model.ArticleSummary}\r\n文章地址:{model.ArticleUrl}";sw.WriteLine(line+ "\r\n ==========================================================================================");}}return Task.CompletedTask;}}}Program调用
internal class Program{static async Task Main(string[] args){Console.WriteLine("Hello, World!");await RecommendedRankingSpider.RunAsync();Console.WriteLine("数据抓取完成");}}抓取数据和页面数据对比
抓取数据:

页面数据:

项目源码地址
更多项目实用功能和特性欢迎前往项目开源地址查看👀,别忘了给项目一个Star支持💖。
GitHub源码地址:GitHub - dotnetcore/DotnetSpider: DotnetSpider, a .NET standard web crawling library. It is lightweight, efficient and fast high-level web crawling & scraping framework
GitHub wiki:Home · dotnetcore/DotnetSpider Wiki · GitHub
优秀项目和框架精选
该项目已收录到C#/.NET/.NET Core优秀项目和框架精选中,关注优秀项目和框架精选能让你及时了解C#、.NET和.NET Core领域的最新动态和最佳实践,提高开发工作效率和质量。坑已挖,欢迎大家踊跃提交PR推荐或自荐(让优秀的项目和框架不被埋没🤞)。
https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.md
文章转载自:追逐时光者
原文链接:https://www.cnblogs.com/Can-daydayup/p/17884311.html








SpringBoot实现雪花算法id注册功能)
聊天)









)