感觉Redis变慢了,这些可能的原因你查了没 ?(下)
Redis变慢排查的上一篇【感觉Redis变慢了,这些可能的原因你查了没 ?(上)】,我们是基于Redis命令为入口,比如命令使用不得当,bigkey问题,以及集中过期问题来看现象和如何进行优化处理的,认真读过的同学想必大家对这些现象和处理方式有了比较深的印象。
本期将基于存储层,比如AOF和RDB持久化、内存分配机制、系统层以及一些额外的影响因素,来看看这些情况是如何导致对Redis造成影响的!
先看下篇的大纲:
持久化
在服务层影响Redis性能的因素中,在存储层就涉及到持久化可能导致的影响,那到底是在什么情况下会发生呢!
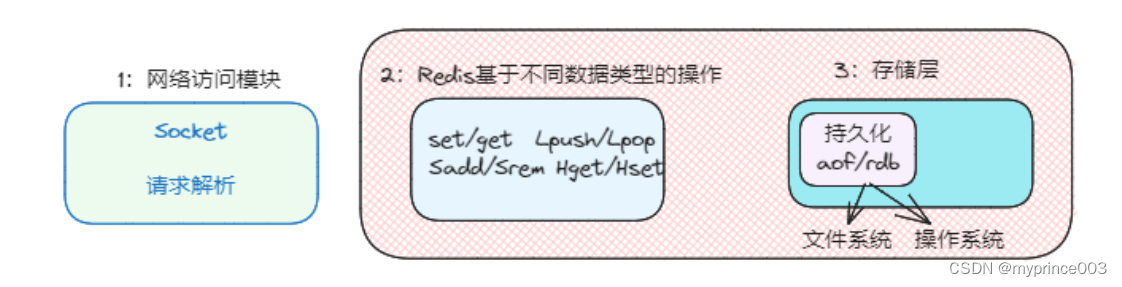
AOF持久化到磁盘
大家可能想过没,在数据持久化方面,还有影响 Redis 性能的因素,这就是AOF 数据持久化。
这里回顾一下AOF机制和三种刷盘策略
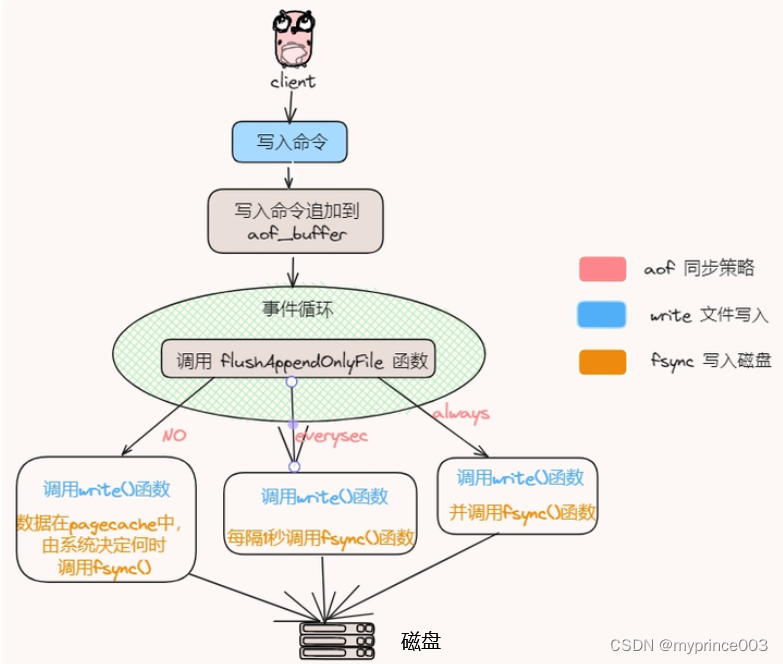
Redis开启AOF后,工作原理如下:
1:客户端发送命令到服务器,在服务器在执行完一个写命令之后,会以Redis协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾,要是再执行一个写命令,那么会继续追加到aof_buf 缓冲区末尾,这就是追加方式
2:通过 write() 函数,将 aof_buf 缓冲区的数据写入到 AOF 文件
3:在主服务进程死循环的最后,会调用flushAppendOnlyFile函数,该函数会将aof_buf中的数据写入到内核缓冲区,然后判断使用何种策略进行同步
AOF三种刷盘机制如下图:

通过同种对三种刷盘机制的分析,可以看出如果一般不建议采用always刷盘方式,这个机制会严重拖慢Redis的性能
如果只是将Redis作为缓存,不计较数据丢失的话,可以使用 no方式
大多数人会选择比较折中的方案 everysec同步机制,既保证了数据安全又兼顾了性能,那这种机制就没有任何问题了吗?
方案没有最完美的,everysec同步机制同样存在导致Redis延迟变慢的情况。
AOF耗时的刷盘操作不是已经创建了一个后台线程去处理吗,怎么还会影响Redis主进程呢?
不过这里有个知识点需要注意,就是:
当后台线程(aof_fsync 线程)调用 fsync 函数同步 AOF 文件时,需要等待,直到写入完成。
当磁盘压力太大的时候,会导致 fsync 操作发生阻塞,主线程调用 write 函数时也会被阻塞。fsync 完成后,主线程执行 write 才能成功返回
也就是说压力到了磁盘IO这边,因此磁盘IO压力过大,同样可能导致Redis主进程阻塞,主进程阻塞了,自然处理用户命令变慢了
排查方式:
1:info Persistence,查看aof_delayed_fsync指标,一直在增加,说明主线程频繁出现被阻塞情况
2:系统日志会有提示信息【Asynchronous AOF fsync is taking too long …】
AOF重写
先看AOF重写机制,这个大多数朋友都很清楚了,这里再回顾一下:
• fork 出一条子线程来将文件重写,在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子线程创建新 AOF 文件期间,记录服务器执行的所有写命令。
• 当子线程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。
• 最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作
看起来是是很正常的,但是刷盘策略和重写机制一起就可能出现以外
127.0.0.1:6379> config get *append*
1) "no-appendfsync-on-rewrite"
2) "no"
3) "appendonly"
4) "yes"
5) "appendfsync"
6) "everysec"
我们看到redis配置可以得出以下结论:
1:Redis实例使用AOF进行持久化,appendfsync策略采用的是everysec刷盘
2:AOF的文件会越来越大,Redis还有一个rewrite策略,实现AOF文件的重写瘦身
3:但是no-appendfsync-on-rewrite的策略是 no,这就会导致在进行rewrite操作时,append fsync会被阻塞
4:而fsync阻塞,会导致Redis主进程也会阻塞
总结起来就是说,AOF重写机制和AOF持久化刷盘一起发生了,冲突了!
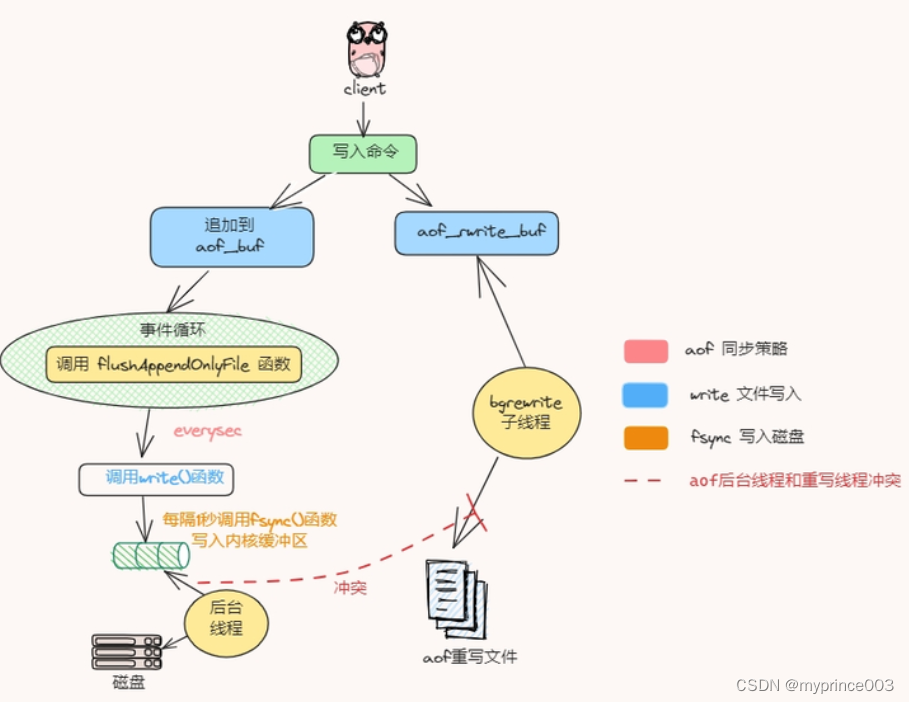
不过我们可以进行配置将 no-appendfsync-on-rewrite 设置为 yes 。这样可以避免AOF rewrite 重写期间,后台子线程不执行刷盘操作,但是在rewrite 期间会有AOF丢失的风险,需要自己权衡好利弊!
不过我看到过一个相对比较折中的方案,分享给大家:
1:给当前Redis实例添加slave节点,当前节点设置为master, 然后master节点关闭AOF,slave节点开启AOF
2:在master 节点设置将 no-appendfsync-on-rewrite 设置为 yes(避免重写时造成和fsync写磁盘的冲突)
3:为了防止AOF文件越来越大,配置在凌晨低峰期定时手动执行bgrewriteaof命令完成每日一次的AOF重写
4:为避免硬盘空间不足或者IO使用率高影响重写功能,添加磁盘空报警和IO使用率报警保障重写的正常进行
技术问题的处理方案有时候没有最完美的,往往是选择合适自己的方案
fork子进程耗时
先来看看fork是什么
fork 是unix和linux这种操作系统的一个api,而不是Redis的api,fork()用于创建一个子进程,不是子线程
有一点我们可以知道的是fork 的目的最终一定是为了不阻塞主进程来提升 Redis 服务的可用性。
而Redis 开启了后台 RDB 和 AOF rewrite 后,在执行时,都需会主进程创建出一个子进程进行数据的持久化,而这个过程会调用操作系统的fork()操作。
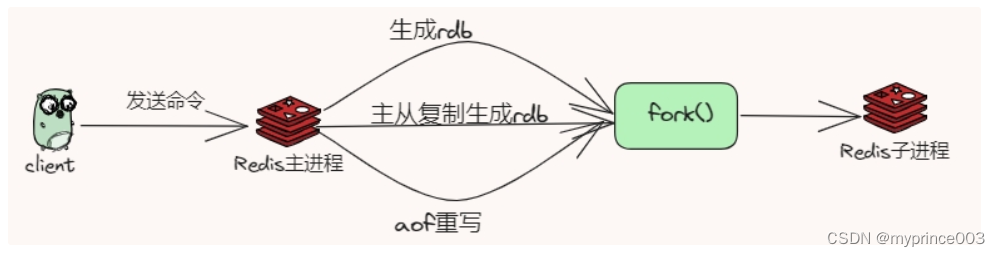
想具体了解如何进行fork的同学可以看我之前的文章分享:redis aof和rdb
Redis中fork 对内存数据的 copy-On-Write (写时复制) 机制最廉价的实现内存镜像
虚拟内存表是在 fork 的瞬间就需要分配,所以这个操作会造成主线程短时间的卡顿(停止所有读写操作),不过卡顿时间跟Redis内存使用量有关。
GB 量级的 Redis 进行 fork 操作的时间在毫秒级 如果这个Redis实例很大,CPU负载再高些,那么 fork 的耗时就会更长,甚至达到秒级,也就会严重影响 Redis 的访问响应时间
这也就是为什么fork()子进程可能导致Redis变慢的原因了
我们可以通过命令去查看延迟大小
//执行 INFO 命令,查看 latest_fork_usec ,时间微秒latest_fork_usec:15699
碎片化过大
什么是内存碎片?
你可以将内存碎片简单地理解为那些不可用的空闲内存
举个例子:操作系统为你分配了 16 字节的连续内存空间,而你存储数据实际只需要使用 12 字节内存空间,那这多余出来的 4 字节内存空间如果后续没办法再被分配存储其他数据的话,就可以被称为内存碎片

Redis 内存碎片产生比较常见的 2 个原因:
1、存储存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间
2、频繁修改 Redis 中的数据
我们可以通过info memory命令查看内存相关的信息,可以计算出内存碎片率
内存碎片率可通过参数计算:mem_fragmentation_ratio (内存碎片率)= used_memory_rss (操作系统实际分配给 Redis 的物理内存空间大小)/ used_memory(内存分配器为了存储数据实际申请使用的内存空间大小)
Redis清理内存碎片的方式有两种:
• Redis 4.0 以前的低版本,只能通过重启实例来解决,不能自动配置回收
• 从 4.0版本以后,提供了一种内存碎片自动回收的方法,可以通过配置动态开启碎片整理
碎片整理
注意开启内存碎片整理,有可能导致 Redis 服务性能下降
Redis 的碎片整理工作是在主线程中执行的,当其进行碎片整理时,操作系统会把多份数据拷贝到新位置以把原有空间释放出来,这会带来时间开销,而这个过程就会阻塞Redis处理请求
为了降低碎片整理带来的性能影响,Redis 为自动内存碎片整理机制提供了多个参数,具体有:
#是否开启碎片整理
activedefrag yes #碎片大小超过 500MB 时才会触发整理
active-defrag-ignore-bytes 500mb #碎片大小占操作系统分配总空间比超过 20% 时触发整理
active-defrag-threshold-lower 20#碎片整理过程占用的CPU比例不低于 15%,保证整理可以正常执行
active-defrag-cycle-min 15 #碎片整理过程占用的CPU比例不高于70%,一旦超过就暂停整理,
#避免大量的内存拷贝等整理过程占用过多的CPU进而影响正常请求
active-defrag-cycle-max 70 #碎片整理过程中,对于 Hash、List、Set、ZSet 等成员集合类型一次扫描的元素数量
active-defrag-max-scan-fields 500
在开启碎片自动整理时,一定要优先评估当前 Redis 服务的负载状态,以及应用程序可接受的响应延迟,合理设置碎片整理的参数值和回收时间段【比如放到凌晨程序定时触发】,来尽可能降低碎片整理期间对Redis服务的影响。
操作系统层Swap被使用
先来了解下什么是Swap
操作系统为了缓解内存不足对应用程序的影响,允许把一部分内存中的数据换到磁盘上,以达到应用程序对内存使用的缓冲,这些内存数据被换到磁盘上的区域,等到那些程序要运行时,再从Swap中恢复保存的数据到内存中,这就是 Swap。
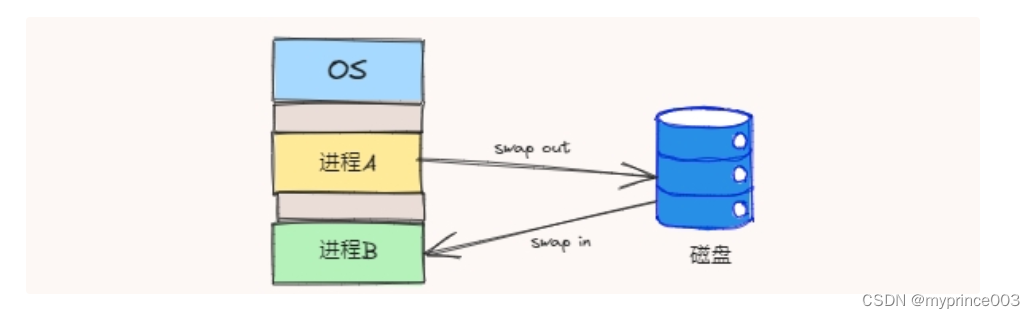
也就是说内存中的数据被交换到了磁盘中,再次访问数据时,就需要从磁盘上读取,而我们知道访问磁盘的速度是比访问内存慢几个等级的。
Redis作为内存数据库,有个常识一定要记住:所有的数据默认都是在内存中,不存在一部分在内存一部分在磁盘中的情况,除非被迫发生了SWAP。
可以通过以下方式来查看 Redis 进程是否使用到了 Swap:
# 获取Redis 的进程 ID
[root@VM-12-10-opencloudos ~]# redis-cli info | grep process_id
process_id:2600003# 查看 Redis Swap 使用情况
[root@VM-12-10-opencloudos ~]# cat /proc/260003/smaps | egrep '^(Swap|Size)'Size: 1296 kB
Swap: 0 kB
SwapPss: 0 kB
Size: 4 kB
Swap: 0 kB
SwapPss: 0 kB
Size: 20 kB
Swap: 0 kB
SwapPss: 0 kB
...
每一行 Size 表示 Redis 所用的一块内存大小,Size 下面的 Swap 就表示这块 Size 大小的内存,有多少数据已经被换到磁盘上了
如果这两个值相等,说明这块内存的数据都已经完全被换到磁盘上了
如果真的交换到了内存,对于Redis这种性能要求较高的,对这种延迟还是需要谨慎对待!
针对Swap情况可以参考以下解决方案:
• 建议将Redis的预留内存提高,可以多留个20%左右
• 单独不是Redis实例,避免和其他服务进程竞争使用内存
• 整理内存空间,释放出足够的内存供 Redis 使用,然后释放 Redis 的 Swap
总的来说这种内存余量和Swap情况还是要进行监控,毕竟不可能等到出现了问题才去查,那么只能做事后补救处理了
网络带宽被打满
Redis的性能问题,除了前面提到的各种可能影响因素之外,别忘了还有网络IO也可能存在瓶颈,如果网络存在瓶颈,一样会严重影响Redis性能的。
放在后面讲是默认我们认为网络环境是良好的,一般排查问题会从Redis服务去查,不过如果出现带宽过载情况的话,服务器在 TCP 层和网络层就会出现数据包发送延迟、丢包等情况。
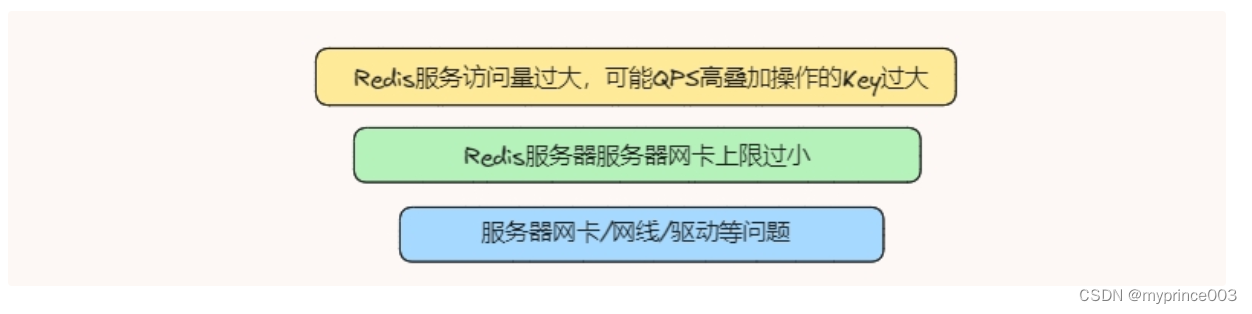
如果因为流量确实大,那么可以考虑进行扩容,不过最好在运维层就Redis的这些指标进行监控,包括网络流量。
其他因素
除了上面主要列出的一些可能因素,这里也有一些其他可能导致影响的原因
Redis服务配置不合理
比如连接数配置啊,内存上限、前面我们讲的AOF持久化和重写的一些配置等等,合理的配置会尽量避免一些问题的出现
使用连接池
应该使用长连接操作 Redis,避免使用短连接模式,频繁的连接创建与销毁,在高QPS访问时网络开销巨大
cpu绑定进程影响
Redis是单线程模型处理处理用户需求,那么处理的吞吐、效率就会极度依赖CPU的处理能力
为了提高服务性能,降低应用程序在多个 CPU 核心之间的上下文切换带来的性能损耗,通常采用的方案是进程绑定 CPU 的方式提高性能
但是Redis的绑核操作过于复杂,对于单机多实例的管理挑战过高,不建议绑定 CPU来处理,这里也不做深入说明,我也没具体深入了解过了
总结
到这里,关于影响Redis性能的因素下篇就分享完了。
相信如果能耐心地看到这里的同学,想必你肯定已经对 Redis 的变慢该如何处理有了很大的收获,同样对Redis如何进行调优也收获很大。
但是通过上下两篇的内容发现 Redis 的性能问题,涉及到的知识点非常广,几乎涵盖了 CPU、内存、网络、甚至磁盘的方方面面。


 配合网络调试助手测试)






概述)
:认识系统服务(daemons))


》)




)

