一、在Java开发中,有许多常见的数据库连接池可供选择。以下是一些常见的Java数据库连接池:不使用数据库连接池的特性:
优点:实现简单 缺点:网络 IO 较多数据库的负载较高响应时间较长及 QPS 较低应用频繁的创建连接和关闭连接,导致临时对象较多,GC 频繁在关闭连接后,会出现大量 TIME_WAIT 的 TCP 状态(在 2 个 MSL 之后关闭)
HikariCP:HikariCP是一个轻量级、高性能的数据库连接池,被广泛认为是目前性能最好的连接池之一。它专注于快速的连接获取和释放,适用于高并发的应用程序。
- Hikaricp.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.3.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><modelVersion>4.0.0</modelVersion><artifactId>HikariCP-Boot</artifactId><dependencies><!-- 实现对数据库连接池的自动化配置 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.48</version></dependency><!-- 写单元测试 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies></project>
private Logger logger = LoggerFactory.getLogger(Application.class);@Resource(name = "ordersDataSource")private DataSource ordersDataSource;@Resource(name = "usersDataSource")private DataSource usersDataSource;public static void main(String[] args) {// 启动 Spring Boot 应用SpringApplication.run(Application.class, args);}@Overridepublic void run(String... args) {// orders 数据源try (Connection conn = ordersDataSource.getConnection()) {// 这里,可以做点什么logger.info("[run][ordersDataSource 获得连接:{}]", conn);} catch (SQLException e) {throw new RuntimeException(e);}// users 数据源try (Connection conn = usersDataSource.getConnection()) {// 这里,可以做点什么logger.info("[run][usersDataSource 获得连接:{}]", conn);} catch (SQLException e) {throw new RuntimeException(e);}}}
参考配置:
# 连接池名称
spring.datasource.hikari.pool-name = SpringTutorialHikariPool
# 最大连接数,小于等于 0 会被重置为默认值 10;大于零小于 1 会被重置为 minimum-idle 的值
spring.datasource.hikari.maximum-pool-size = 10
# 最小空闲连接,默认值10,小于 0 或大于 maximum-pool-size,都会重置为 maximum-pool-size
spring.datasource.hikari.minimum-idle = 10
# 连接超时时间(单位:毫秒),小于 250 毫秒,会被重置为默认值 30 秒
spring.datasource.hikari.connection-timeout = 60000
# 空闲连接超时时间,默认值 600000(10分钟),大于等于 max-lifetime 且 max-lifetime>0,会被重置为0;不等于 0 且小于 10 秒,会被重置为 10 秒
# 只有空闲连接数大于最大连接数且空闲时间超过该值,才会被释放
spring.datasource.hikari.idle-timeout = 600000
# 连接最大存活时间,不等于 0 且小于 30 秒,会被重置为默认值 30 分钟。该值应该比数据库所设置的超时时间短
spring.datasource.hikari.max-lifetime = 1800000
C3P0:C3P0是一个开源的数据库连接池,具有许多配置选项,可用于调整连接池的行为。它是一种稳定的连接池,被许多Java应用程序使用。
c3p0连接java:
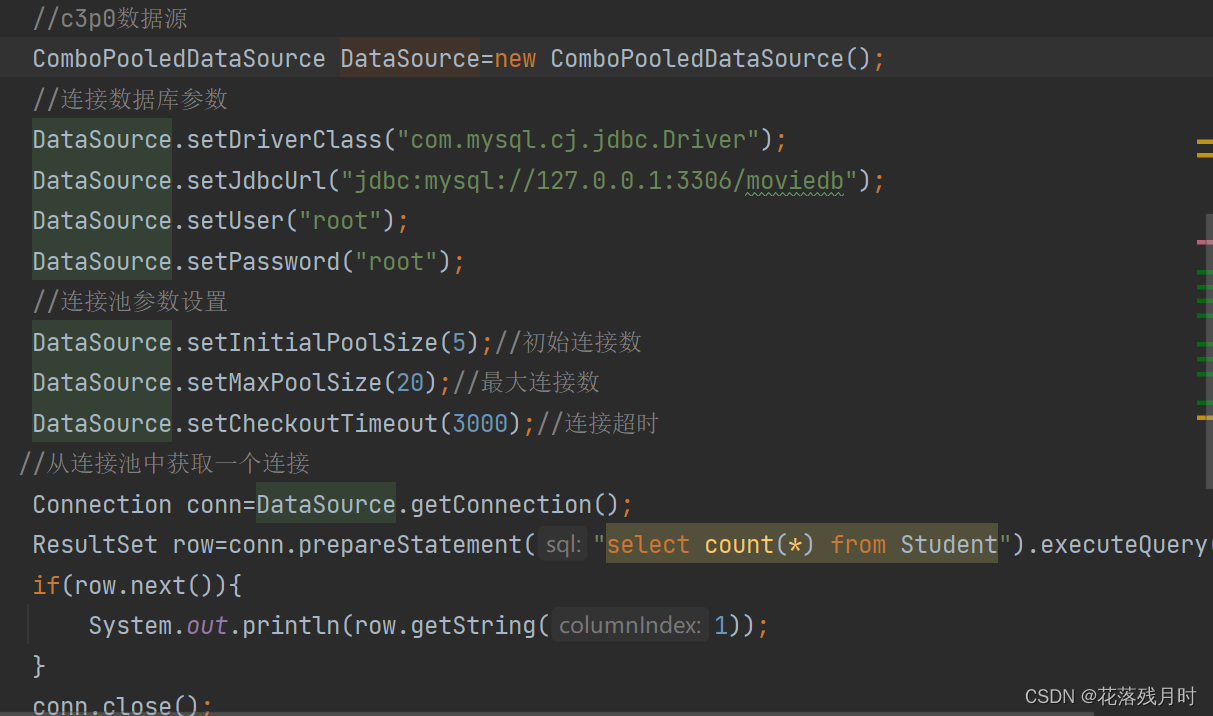
参数配置:
<c3p0-config><!--使用默认的配置读取数据库连接池对象 --><default-config><!-- 连接参数 --><property name="driverClass">com.mysql.cj.jdbc.Driver</property><property name="jdbcUrl">jdbc:mysql://localhost:3306/bankdb</property><property name="user">root</property><property name="password">root</property><!-- 连接池参数 --><!--初始化申请的连接数量--><property name="initialPoolSize">5</property><!--最大的连接数量--><property name="maxPoolSize">10</property><!--超时时间--><property name="checkoutTimeout">3000</property></default-config><named-config name="otherc3p0"><!-- 连接参数 --><property name="driverClass">com.mysql.cj.jdbc.Driver</property><property name="jdbcUrl">jdbc:mysql://127.0.0.1:3306/yiyuanDB</property><property name="user">root</property><property name="password">root</property><!-- 连接池参数 --><property name="initialPoolSize">5</property><property name="maxPoolSize">8</property><property name="checkoutTimeout">1000</property></named-config>
</c3p0-config>
Druid:Druid是一个开源的数据库连接池,具有监控和统计功能,可以帮助开发人员分析数据库连接的使用情况和性能。
druid连接java:
@Test
public void Test() throws Exception{//加载配置文件 第一种方法Properties properties=new Properties();properties.load(new FileInputStream("druid.properties"));//第二种方法HashMap map=new HashMap();map.put("driverClassName","com.mysql.cj.jdbc.Driver");map.put("url","jdbc:mysql://localhost:3306/homework1128db?useServerPrepStmts=true");map.put("username","root");map.put("password","root");map.put("initialSize","10");map.put("maxActive","30");map.put("maxWait","1000");//hikaricp DBCP//在工厂中创建一个数据源,数据源的连接信息来源于properties配置文件DataSource dataSource= DruidDataSourceFactory.createDataSource(properties);Connection connection=dataSource.getConnection();ResultSet rs=connection.prepareStatement("select count(*) from student").executeQuery();if(rs.next()){System.out.println(rs.getString(1));}connection.close();
}
参数配置:
#驱动名称(连接mysql)
driverClassName = com.mysql.cj.jdbc.Driver
#参数?rewriteBatcheStatements=true表示支持批处理机制
url = jdbc:mysql://localhost:3306/homework1128db?useServerPrepStmts=true
#用户名 注意这里一个是按“username”来读取
username = root
#密码
password = root
#最小连接数量
initialSize = 10
#最大连接数量
maxActive = 30
#超时时间5000m(在等待队列中的最长等待时间,若超过,放弃此次请求)
maxWait = 1000
DBCP:DBCP(数据库连接池)是Apache软件基金会的一个项目,提供了一个稳定和可靠的连接池。它是许多Java应用程序的首选选择。
连接参数:
dataSource:要连接的datasource (通常我们不会定义在server. xml)
defaultAutoCommit:对于事务是否autoCommit,默认值为truedefault
ReadOnly:对于数据库是否只能读取,默认值为falsedriver
ClassName:连接数据库所用的JDBC Driver Class,
maxActive:可以从对象池中取出的对象最大个数,为0则表示没有限制,默认为8
maxldle:最大等待连接中的数量,设0为没有限制(对象池中对象最大个数)
minldle:对象池中对象最小个数
maxWait:最大等待秒数,单位为ms,超过时间会丢出错误信息
password:登陆数据库所用的密码
url:连接数据库的URL
username:登陆数据库所用的帐号
validationQuery:验证连接是否成功, SQL SELECT指令至少要返回一行
removeAbandoned:是否自我中断,默认是false
removeAbandonedTimeout:几秒后会自我中断,
removeAbandoned必须为truelogAbandoned:是否记录中断事件,默认为false
minEvictableldleTimeMillis: 大于0,进行连接空闲时间判断,或为0,对空闲的连接不进行验证;
timeBetweenEvictionRunsMillis:失效检查线程运行时间间隔,如果小于等于O,不会启动检查线程,
1testOnBorrow:取得对象时是否进行验证,检查对象是否有效,默认为false
testOnReturn:返回对象时是否进行验证,检查对象是否有效,默认为
falsetestWhileldle:空闲时是否进行验证,检查对象是否有效,默认为
falseinitialSize:初始化线程数
二、当讨论连接词(连接池)时,可以通过生活中的一个例子来形象地理解它们的区别:
HikariCP 就像是一家高效的自来水公司,它专注于提供最快速的自来水供应。它的供水管道(连接池)设计得非常流畅,可以迅速响应城市中不同区域的需求,确保每家每户都能够获得所需的水。这家自来水公司以其高性能和响应速度而著称。
C3P0 可以比作另一家自来水公司,它提供了许多不同的自来水供应计划,可以根据客户的需求进行定制。这家公司提供了灵活的供水方案,允许客户根据他们的特定需求来调整水的流量和质量。
Druid 就像是一个有水质检测设备的自来水公司,它不仅提供水供应,还监控水的质量,并提供统计数据以帮助客户了解他们的水消耗情况。
DBCP 可以类比为一个城市自来水公司,它负责向一座城市供水。这个水公司(连接池)管理着水的分配和流动,确保城市里的每户家庭都可以获得他们所需的水(数据库连接)。虽然它提供了稳定和可靠的供水服务,但它的运作可能不一定是最高效的,因为它可能需要一些时间来响应不同地区的需求。








)


-墨者)


)



特性和属性)
