主页:CoSeR: Bridging Image and Language for Cognitive Super-Resolution (coser-main.github.io)
图像超分辨率技术旨在将低分辨率图像转换为高分辨率图像,从而提高图像的清晰度和细节真实性。这项技术在手机拍照等领域有着广泛的应用和需求。随着超分技术的发展和手机硬件性能的提升,人们期望拍摄出更加清晰的照片。然而,现有的超分方法存在一些局限性,如图2所示,主要有以下两个方面:
-
一是缺乏泛化能力。为了实现更好的超分效果,通常需要针对特定场景使用特定传感器采集到的数据来进行模型训练,这种学习方式拟合了某种低清图像和高清图像间的映射,但在其他场景下表现不佳。此外,逐场景训练的方式计算成本较高,不利于模型的部署和更新。
-
二是缺乏理解能力。现有的超分方法主要依赖于从大量数据中学习图像的退化分布,忽视了对图像内容的理解,无法利用常识来准确恢复物体的结构和纹理。
人类在处理信息时,有两种不同的认知反馈系统。诺贝尔奖经济学得主丹尼尔·卡尔曼在《思考,快与慢》中将它们称为系统一和系统二,如图3所示。系统一是快速的、直觉的、基于记忆的反馈,比如,我们可以脱口而出十以内的加减运算。系统二是缓慢的、多步的反馈,比如,28x39往往需要逐步运算。现有的超分方法更贴近系统一,它们主要依赖于从大量数据中学习图像的退化分布,忽视了对图像内容的理解,无法按照常识来准确恢复物体的结构和纹理,也无法处理域外的退化情况。本文认为,真正能有效应用于真实场景的画质大模型应该具备类似系统二的多步修复能力,即基于对图像内容的认知,结合先验知识来实现图像超分(Cognitive Super-Resolution,CoSeR)。

CoSeR模仿了人类专家修复低质量图像自上而下的思维方式,首先建立对图像内容的全面认知,包括识别场景和主要物体的特征,随后将重点转移到对图像细节的检查和还原。本文的主要贡献如下:
-
提出了一种通用的万物超分画质大模型CoSeR,它能够从低清图像中提取认知特征,包括场景内容理解和纹理细节信息,从而提高模型的泛化能力和理解能力。
-
提出了一种基于认知特征的参考图像生成方法,它能够生成与低清图像内容一致的高质量参考图像,用于指导图像的恢复过程,增强图像的保真度和美感度。
-
提出了一种“All-in-Attention”模块,它能够将低清图像、认知特征、参考图像三个条件注入到模型当中,实现多源信息的融合和增强。
-
在多个测试集和评价指标上,相较于现有方法,CoSeR均取得了更好的效果。同时,CoSeR在真实场景下也展现颇佳。
方法介绍
图4展示了CoSeR的整体架构。CoSeR首先使用认知编码器来对低清图像进行解析,将提取到的认知特征传递给Stable Diffusion模型,用以激活扩散模型中的图像先验,从而恢复更精细的细节。此外,CoSeR利用认知特征来生成与低清图像内容一致的高质量参考图像。这些参考图像作为辅助信息,有助于提升超分辨率效果。最终,CoSeR使用提出的“All-in-Attention”模块,将低清图像、认知特征、参考图像三个条件注入到模型当中,进一步提升结果的保真度。
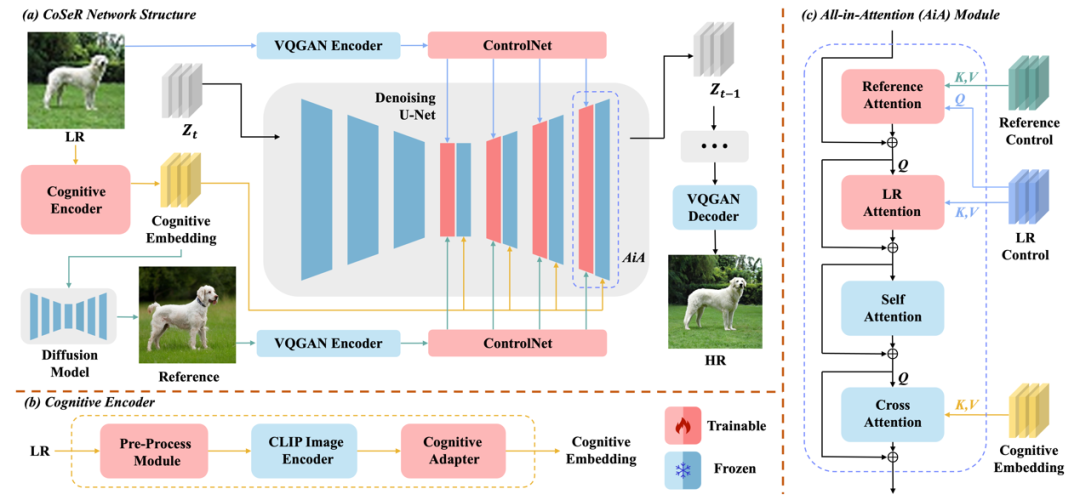
图4. 本文提出的万物超分画质大模型CoSeR
图5展示了CoSeR参考图像生成的效果。与直接从低清图像中获取描述的方法相比,CoSeR的认知特征保留了细粒度的图像特征,在生成具有高度相似内容的参考图像时具有优势。在图5的第一行,使用BLIP2从低清图像生成的描述无法准确识别动物的类别、颜色和纹理。此外,CoSeR的认知特征对于低清图像更加鲁棒。例如,在图5的第二行,由于输入分布的差异,BLIP2会生成错误的图像描述,而CoSeR生成了内容一致的高质量参考图像。最后,相比于BLIP2大模型接近7B的参数量,CoSeR的认知编码器只有其3%的参数量,极大提升了推理速度。




)

输入和输出怎么回事?)













