Flink 系列文章
1、Flink 专栏等系列综合文章链接
文章目录
- Flink 系列文章
- 一、Flink的23种算子说明及示例
- 1、maven依赖
- 2、java bean
- 3、map
- 4、flatmap
- 5、Filter
本文主要介绍Flink 的3种常用的operator(map、flatmap和filter)及以具体可运行示例进行说明.
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)
一、Flink的23种算子说明及示例
1、maven依赖
下文中所有示例都是用该maven依赖,除非有特殊说明的情况。
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-scala-bridge_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version></dependency><!-- 日志 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency></dependencies>2、java bean
下文所依赖的User如下
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author alanchan**/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {private int id;private String name;private String pwd;private String email;private int age;private double balance;
}
3、map
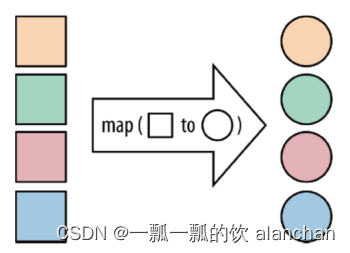
[DataStream->DataStream]
这是最简单的转换之一,其中输入是一个数据流,输出的也是一个数据流。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;/*** @author alanchan**/
public class TestMapDemo {/*** @param args* @throws Exception*/public static void main(String[] args) throws Exception {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// source// transformationmapFunction5(env);// sink// executeenv.execute();}// 构造一个list,然后将list中数字乘以2输出,内部匿名类实现public static void mapFunction1(StreamExecutionEnvironment env) throws Exception {List<Integer> data = new ArrayList<Integer>();for (int i = 1; i <= 10; i++) {data.add(i);}DataStreamSource<Integer> source = env.fromCollection(data);SingleOutputStreamOperator<Integer> sink = source.map(new MapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer inValue) throws Exception {return inValue * 2;}});sink.print();
// 9> 12
// 4> 2
// 10> 14
// 8> 10
// 13> 20
// 7> 8
// 12> 18
// 11> 16
// 5> 4
// 6> 6}// 构造一个list,然后将list中数字乘以2输出,lambda实现public static void mapFunction2(StreamExecutionEnvironment env) throws Exception {List<Integer> data = new ArrayList<Integer>();for (int i = 1; i <= 10; i++) {data.add(i);}DataStreamSource<Integer> source = env.fromCollection(data);SingleOutputStreamOperator<Integer> sink = source.map(i -> 2 * i);sink.print();
// 3> 4
// 4> 6
// 9> 16
// 7> 12
// 10> 18
// 2> 2
// 6> 10
// 5> 8
// 8> 14
// 11> 20}// 构造User数据源public static DataStreamSource<User> source(StreamExecutionEnvironment env) {DataStreamSource<User> source = env.fromCollection(Arrays.asList(new User(1, "alan1", "1", "1@1.com", 12, 1000), new User(2, "alan2", "2", "2@2.com", 19, 200),new User(3, "alan1", "3", "3@3.com", 28, 1500), new User(5, "alan1", "5", "5@5.com", 15, 500), new User(4, "alan2", "4", "4@4.com", 30, 400)));return source;}// lambda实现用户对象的balance×2和age+5功能public static SingleOutputStreamOperator<User> mapFunction3(StreamExecutionEnvironment env) throws Exception {DataStreamSource<User> source = source(env);SingleOutputStreamOperator<User> sink = source.map((MapFunction<User, User>) user -> {User user2 = user;user2.setAge(user.getAge() + 5);user2.setBalance(user.getBalance() * 2);return user2;});sink.print();
// 10> User(id=1, name=alan1, pwd=1, email=1@1.com, age=17, balance=2000.0)
// 14> User(id=4, name=alan2, pwd=4, email=4@4.com, age=35, balance=800.0)
// 11> User(id=2, name=alan2, pwd=2, email=2@2.com, age=24, balance=400.0)
// 12> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 13> User(id=5, name=alan1, pwd=5, email=5@5.com, age=20, balance=1000.0)return sink;}// lambda实现balance*2和age+5后,balance》=2000和age》=20的数据过滤出来public static SingleOutputStreamOperator<User> mapFunction4(StreamExecutionEnvironment env) throws Exception {SingleOutputStreamOperator<User> sink = mapFunction3(env).filter(user -> user.getBalance() >= 2000 && user.getAge() >= 20);sink.print();
// 15> User(id=1, name=alan1, pwd=1, email=1@1.com, age=17, balance=2000.0)
// 1> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 16> User(id=2, name=alan2, pwd=2, email=2@2.com, age=24, balance=400.0)
// 3> User(id=4, name=alan2, pwd=4, email=4@4.com, age=35, balance=800.0)
// 2> User(id=5, name=alan1, pwd=5, email=5@5.com, age=20, balance=1000.0)
// 1> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)return sink;}// lambda实现balance*2和age+5后,balance》=2000和age》=20的数据过滤出来并通过flatmap收集public static SingleOutputStreamOperator<User> mapFunction5(StreamExecutionEnvironment env) throws Exception {SingleOutputStreamOperator<User> sink = mapFunction4(env).flatMap((FlatMapFunction<User, User>) (user, out) -> {if (user.getBalance() >= 3000) {out.collect(user);}}).returns(User.class);sink.print();
// 8> User(id=5, name=alan1, pwd=5, email=5@5.com, age=20, balance=1000.0)
// 7> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 6> User(id=2, name=alan2, pwd=2, email=2@2.com, age=24, balance=400.0)
// 9> User(id=4, name=alan2, pwd=4, email=4@4.com, age=35, balance=800.0)
// 5> User(id=1, name=alan1, pwd=1, email=1@1.com, age=17, balance=2000.0)
// 7> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)
// 7> User(id=3, name=alan1, pwd=3, email=3@3.com, age=33, balance=3000.0)return sink;}}4、flatmap
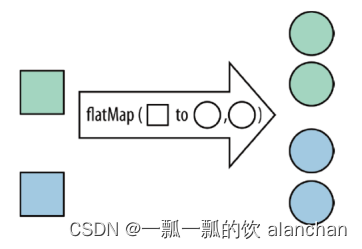
[DataStream->DataStream]
FlatMap 采用一条记录并输出零个,一个或多个记录。将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author alanchan**/
public class TestFlatMapDemo {/*** @param args* @throws Exception*/public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();flatMapFunction3(env);env.execute();}// 构造User数据源public static DataStreamSource<String> source(StreamExecutionEnvironment env) {List<String> info = new ArrayList<>();info.add("i am alanchan");info.add("i like hadoop");info.add("i like flink");info.add("and you ?");DataStreamSource<String> dataSource = env.fromCollection(info);return dataSource;}// 将句子以空格进行分割-内部匿名类实现public static void flatMapFunction1(StreamExecutionEnvironment env) throws Exception {DataStreamSource<String> source = source(env);SingleOutputStreamOperator<String> sink = source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] splits = value.split(" ");for (String split : splits) {out.collect(split);}}});sink.print();
// 11> and
// 10> i
// 8> i
// 9> i
// 8> am
// 10> like
// 11> you
// 10> flink
// 8> alanchan
// 9> like
// 11> ?
// 9> hadoop}// lambda实现public static void flatMapFunction2(StreamExecutionEnvironment env) throws Exception {DataStreamSource<String> source = source(env);SingleOutputStreamOperator<String> sink = source.flatMap((FlatMapFunction<String, String>) (input, out) -> {String[] splits = input.split(" ");for (String split : splits) {out.collect(split);}}).returns(String.class);sink.print();
// 6> i
// 8> and
// 8> you
// 8> ?
// 5> i
// 7> i
// 5> am
// 5> alanchan
// 6> like
// 7> like
// 6> hadoop
// 7> flink}// lambda实现public static void flatMapFunction3(StreamExecutionEnvironment env) throws Exception {DataStreamSource<String> source = source(env);SingleOutputStreamOperator<String> sink = source.flatMap((String input, Collector<String> out) -> Arrays.stream(input.split(" ")).forEach(out::collect)).returns(String.class);sink.print();
// 8> i
// 11> and
// 10> i
// 9> i
// 10> like
// 11> you
// 8> am
// 11> ?
// 10> flink
// 9> like
// 9> hadoop
// 8> alanchan}}5、Filter
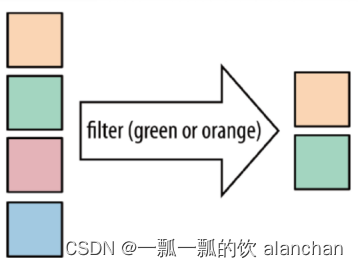
DataStream → DataStream
Filter 函数根据条件判断出结果。按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;/*** @author alanchan**/
public class TestFilterDemo {// 构造User数据源public static DataStreamSource<User> sourceUser(StreamExecutionEnvironment env) {DataStreamSource<User> source = env.fromCollection(Arrays.asList(new User(1, "alan1", "1", "1@1.com", 12, 1000), new User(2, "alan2", "2", "2@2.com", 19, 200),new User(3, "alan1", "3", "3@3.com", 28, 1500), new User(5, "alan1", "5", "5@5.com", 15, 500), new User(4, "alan2", "4", "4@4.com", 30, 400)));return source;}// 构造User数据源public static DataStreamSource<Integer> sourceList(StreamExecutionEnvironment env) {List<Integer> data = new ArrayList<Integer>();for (int i = 1; i <= 10; i++) {data.add(i);}DataStreamSource<Integer> source = env.fromCollection(data);return source;}// 过滤出大于5的数字,内部匿名类public static void filterFunction1(StreamExecutionEnvironment env) throws Exception {DataStream<Integer> source = sourceList(env);SingleOutputStreamOperator<Integer> sink = source.map(new MapFunction<Integer, Integer>() {public Integer map(Integer value) throws Exception {return value + 1;}}).filter(new FilterFunction<Integer>() {@Overridepublic boolean filter(Integer value) throws Exception {return value > 5;}});sink.print();
// 1> 10
// 14> 7
// 16> 9
// 13> 6
// 2> 11
// 15> 8}// lambda实现public static void filterFunction2(StreamExecutionEnvironment env) throws Exception {DataStream<Integer> source = sourceList(env);SingleOutputStreamOperator<Integer> sink = source.map(i -> i + 1).filter(value -> value > 5);sink.print();
// 12> 7
// 15> 10
// 11> 6
// 13> 8
// 14> 9
// 16> 11}// 查询user id大于3的记录public static void filterFunction3(StreamExecutionEnvironment env) throws Exception {DataStream<User> source = sourceUser(env);SingleOutputStreamOperator<User> sink = source.filter(user -> user.getId() > 3);sink.print();
// 14> User(id=5, name=alan1, pwd=5, email=5@5.com, age=15, balance=500.0)
// 15> User(id=4, name=alan2, pwd=4, email=4@4.com, age=30, balance=400.0)}/*** @param args*/public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();filterFunction3(env);env.execute();}}本文主要介绍Flink 的3种常用的operator及以具体可运行示例进行说明。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)