简介
ScyllaDB 是一种开源的 NoSQL 数据库,它提供了高性能、低延迟的数据处理能力,同时保持了与 Apache Cassandra 高度的兼容性。ScyllaDB 使用了一种名为 “Seastar” 的高效并行编程框架,并采用了 C++ 进行开发,因此它能够充分利用现代多核和多线程硬件的能力。
原理介绍
接下来我们会从名词介绍入手,再介绍到具体的 ScyllaDB 架构设计。
名词介绍
ScyllaDB 是一个可横向扩展的数据库,其采用了 Apache Cassandra 项目的大部分分布式横向扩展设计(该项目采用了 Amazon Dynamo 的分布式概念和 Google BigTable 的数据建模概念)。
以下是 ScyllaDB 的一些基础概念:
- 服务器架构层级:
- 集群(Cluster):Scylla 节点的集合,可视化为环。节点之间是同质的,通过 Gossip 协议(Scylla 5.2 版本以前)或 Raft 协议(Scylla 5.2 版本及以后)进行通信,协同工作。
- 节点(Node):Scylla 单个实例,可以是单独的本地服务器,也可以是公共云实例,整个集群的数据尽可能均匀地分布在这些节点上。
- 分片(Shard):每个 Scylla 节点内部被划分为多个分片,每个分片都是一个绑定到专用核心的独立线程。每个数据分片都拥有自己的 CPU、RAM、持久存储和网络资源,并尽可能高效地利用这些资源。这种被称为“无共享”设计的模式,能极大地减少资源争用并降低对昂贵的处理锁的需求。
- 数据架构层级:
- Apache Cassandra 查询语言(CQL):与 ScyllaDB 通信的主要语言,类似于 SQL。
- 键空间(Keyspace):具有定义如何在节点上复制数据的属性的表的集合,类似于 SQL 中的数据库概念。
- 表(Table):由架构定义的列和行的标准集合,其中列按聚类键排序。
- 分区(Partition):存储在节点上并跨节点复制的数据子集。在 CQL 中,分区显示为一组已排序的行,并且是查询数据的访问单位;在物理层,分区是存储在节点上的数据单元,由分区键标识。
- 分区器(Partitioner):分区哈希函数,通过计算每个分区键的令牌来确定数据在集群中给定节点上的存储位置。
- 主键(Primary key):指定分区键和聚类键,作为每个分区和分区中的行的唯一标识。
- 分区键(Partition key):分区的唯一标识符,决定哪个虚拟节点获得第一个分区副本。
- 聚类键(Clustering key):指定数据(行)在给定分区内的排序方式。
- 环架构层级:
- 令牌(Token):用于标识节点和分区。 Scylla 集群中的每个节点都会获得一个初始令牌,用于定义节点处理范围的末尾值。
- 虚拟节点(Virtual Node):指定数据与物理节点的所属关系,即每个 Scylla 节点拥有的令牌范围,一个物理节点可以被分配多个不连续的虚拟节点。
- 复制(Replication):集群中节点之间复制数据的过程。
- 复制因子(Replication Factor, RF):集群中的复制器节点总数。 RF 为 1 意味着数据将仅存在于集群中的单个节点上,并且不会具有任何容错能力,可以为每个表定义不同的 RF。
- 一致性级别(Consistency Level, CL):指定集群中必须确认读取或写入操作的副本数量,该值由客户端根据每个操作设置。对于 CQL Shell(CQLSh),读写操作的一致性级别默认为 ONE。
- 告密者(Snitch):定义了复制策略用来放置副本节点和路由请求所使用的拓扑信息,用于确定节点属于哪些数据中心和机架,和通知 ScyllaDB 有关网络拓扑的信息。
- 存储架构层级:
- 内存表(Memtable):在 ScyllaDB 的写入路径中,数据首先放入内存表中,存储在 RAM 中,这些数据会及时刷新到磁盘以进行持久化。
- 提交日志(Commitlog):本地节点操作的仅附加日志,在数据发送到内存表时同时写入。能在节点关闭的情况下提供数据持久性,当节点重新启动时,提交日志可用于恢复内存表。
- 排序字符串表(SSTable):数据使用称为排序字符串表 (SSTables) 的不可变(不可更改、只读)文件以每个分片的形式持久存储在 ScyllaDB 中,该文件使用日志结构合并 (LSM) 树格式。一旦数据从内存表刷新到 SSTable,内存表(以及关联的提交日志段)就可以被删除。对记录的更新不会写入原始 SSTable,而是记录在新的 SSTable 中。 ScyllaDB 具有了解特定记录的哪个版本是最新版本的机制。
- 墓碑(Tombstones):当从 SSTable 中删除一行时,ScyllaDB 会将一个称为逻辑删除的标记放入新的 SSTable 中。这可以提醒数据库忽略被删除的原始数据。
- 压缩(Compaction):将多个 SSTable 写入磁盘后,ScyllaDB 将进行压缩,这是一个仅存储记录的最新副本的过程,并删除任何标有逻辑删除的记录。一旦新的压缩的 SSTable 被写入,旧的、过时的 SSTable 就会被删除,并释放磁盘上的空间。
- 压缩策略(Compaction Strategy):ScyllaDB 使用不同的算法(策略)来确定何时以及如何最好地运行压缩。该策略决定了写入、读取和空间放大之间的权衡。
- 读放大(Read Amplification, RA):每个查询的磁盘读取次数。过多的读取请求需要许多 SSTable,当需要读取很多页面来回答查询时,就会出现高 RA。
- 写放大(Write Amplification, WA):写入存储的字节数与写入数据库的字节数之比。当对相同数据的过度压缩时,每秒写入存储的字节数将多于实际写入数据库的字节数,就会出现高 WA。
- 空间放大(Space Amplification, SA):磁盘上数据库文件的大小与实际数据大小的比率。当使用的磁盘空间多于数据大小时,就会出现高 SA。
架构介绍
整体架构
KKV 架构是什么
我们需要声明的是,ScyllaDB 的数据模型通常用“键-键-值”来体现分区键和聚类键,下图是 ScyllaDB 多个分区的示例:
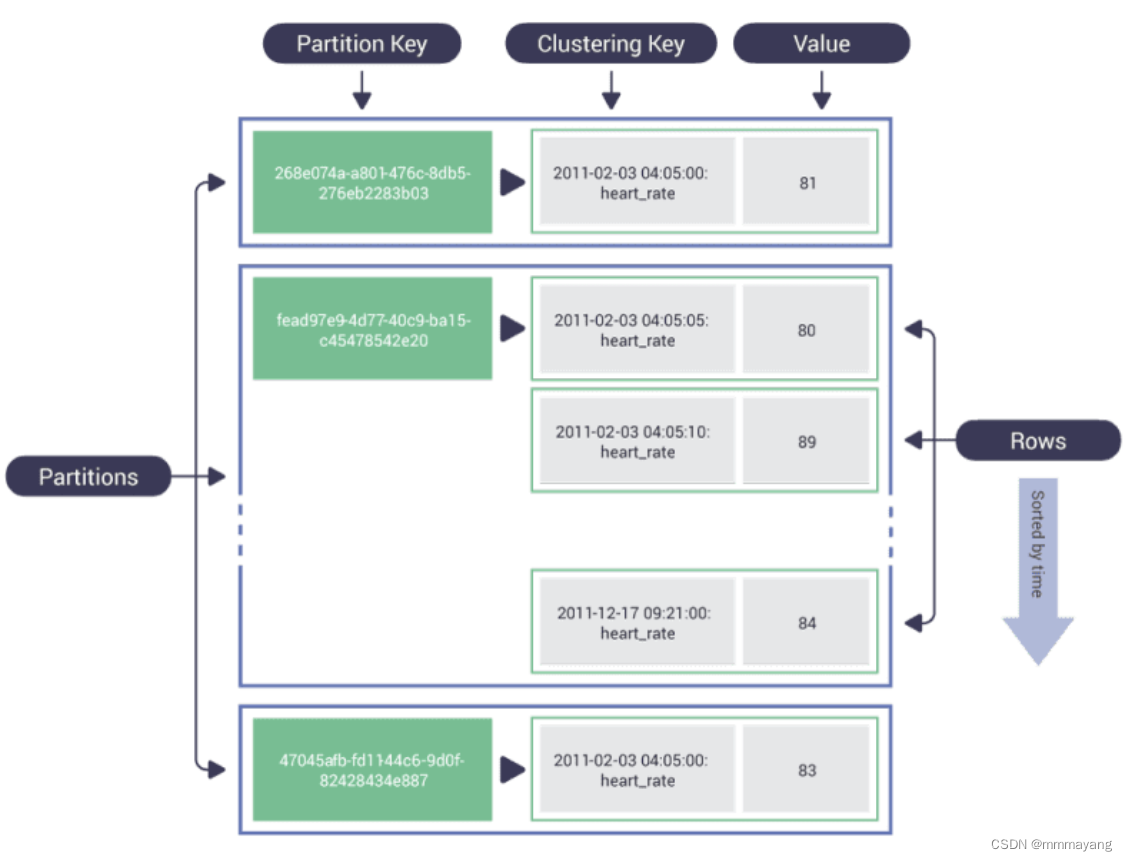
在 ScyllaDB 中,键空间是表的集合,类似于 SQL 中的数据库;
在键空间内,数据存储在单独的表中,表是由列和行组成的二维数据结构,表的属性定义了如何在节点上复制数据。由于表可能非常大,通常以 TB 为单位,因此表被分为更小的块(称为分区),以便尽可能均匀地分布在分片上。每个分区包含按特定顺序排序的一行或多行数据。
ScyllaDB 中表的主键(Primary Key)由一个或多个分区键(Partition key)和零个或多个聚类键(Clustering key)组成,其中顺序始终将分区键放在第一位,然后是聚类键。
分区键的主要目标是将数据尽可能均匀地分散到集群的所有节点上并高效地查询数据;聚类键的主要作用是决定同一个分区内相同分区键数据的排序,默认为升序,可以在建表语句中使用 WITH CLUSTERING ORDER BY ( ASC/DESC)手动设置聚类键排序的方式。
数据架构
ScyllaDB 的集群架构和每核分片设计如下图:
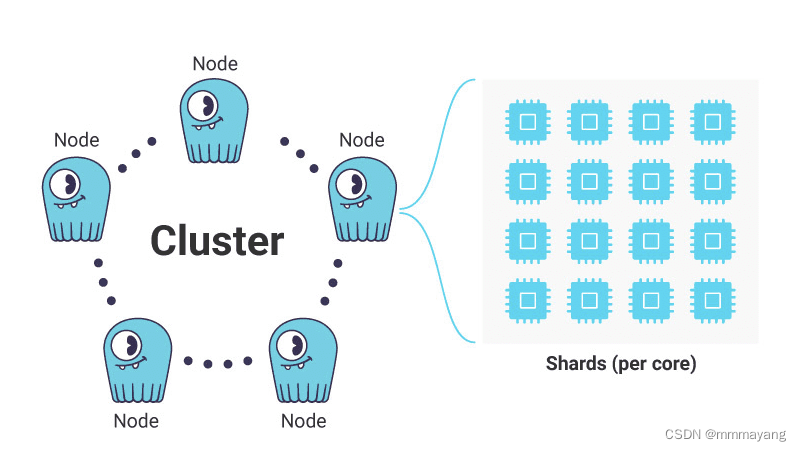
集群是组织成虚拟环架构的互连节点的集合,数据分布在虚拟环架构中。从点对点的意义上来说,所有节点都被认为是平等的。
节点是 Scylla 单个实例,可以是单独的本地服务器,也可以是公共云实例,整个集群的数据尽可能均匀地分布在这些节点上。此外,ScyllaDB 使用称为虚拟节点 (Virtual Node) 的逻辑单元来更好地分布数据以获得更均匀的性能。集群可以在不同节点上存储相同数据的多个副本以确保可靠性。
ScyllaDB 进一步划分数据,通过将节点中总数据的片段分配给特定 CPU 及其关联的内存和持久存储来创建分片。分片主要作为独立运行的单元运行,称为“无共享”设计。这大大减少了争用以及对昂贵的处理锁的需求。
一致性介绍
一致性级别(CL)指定集群中的多少个副本必须确认读取或写入操作才能被视为成功,该值由客户端根据每个操作设置。对于 CQL Shell(CQLSh),读写操作的一致性级别默认为 ONE,如果设置存在冲突,CQLSh 设置将取代一致性级别全局设置。需注意,无论一致性级别如何,写入始终会发送到由复制因子设置的所有副本。一致性级别控制客户端何时被确认,而不是更新多少副本。
| 一致性级别(CL) | 哪些副本必须响应 | 一致性 | 可用性 |
|---|---|---|---|
| ANY | 由告密者确定的在环上最接近的副本。如果所有节点均异常,则在提示移交后返回写成功,提供低写延迟,保证写入永不失败。 | 最低(写) | 最高(写) |
| ONE | 由告密者确定的在环上最接近的一个副本。(写入任何一个节点成功就算成功,跟 ANY 的区别是 ANY 写入提示移交也算写入成功。) | 最低(读) | 最高(读) |
| TWO | 由告密者确定的在环上最接近的两个副本。 | 较低 | 较高 |
| THREE | 由告密者确定的在环上最接近的三个副本。 | 较低 | 较高 |
| QUORUM | 所有数据中心的所有副本的简单多数,允许一定程度的故障。(写入大多数节点成功才算成功,可以使用公式 RF/2 + 1 计算 QUORUM ,其中 RF 是复制因子) | 较高 | 较低 |
| ALL | 集群中的所有副本。(写入所有节点成功才算成功) | 最高 | 最低(可能会导致性能问题) |
| SERIAL | 返回包含最新数据的结果,不支持写入,但支持读取事务。 | 线性化(每个操作具有顺序原子性) |
需要注意的是:
- 一致性级别和复制因子都会影响性能。一致性级别和/或复制因子越低,读取或写入操作越快。但是,如果节点出现故障,容错能力就会降低。
- 一致性级别本身会影响可用性。一致性级别越高(需要在线的节点越多)意味着可用性越低,节点故障的容忍度也越低。较低的一致性级别意味着更高的可用性和更高的容错能力。
- CQL 中的每个操作的一致性级别都是可调的,这称为可调一致性。有时响应延迟更为重要,因此有必要调整每个查询或操作级别的设置以覆盖键空间甚至数据中心范围的一致性设置。换句话说,一致性级别设置允许您在一致性与延迟之间进行权衡。
存储原理
其中,scyllaDB 存储架构的图长这样
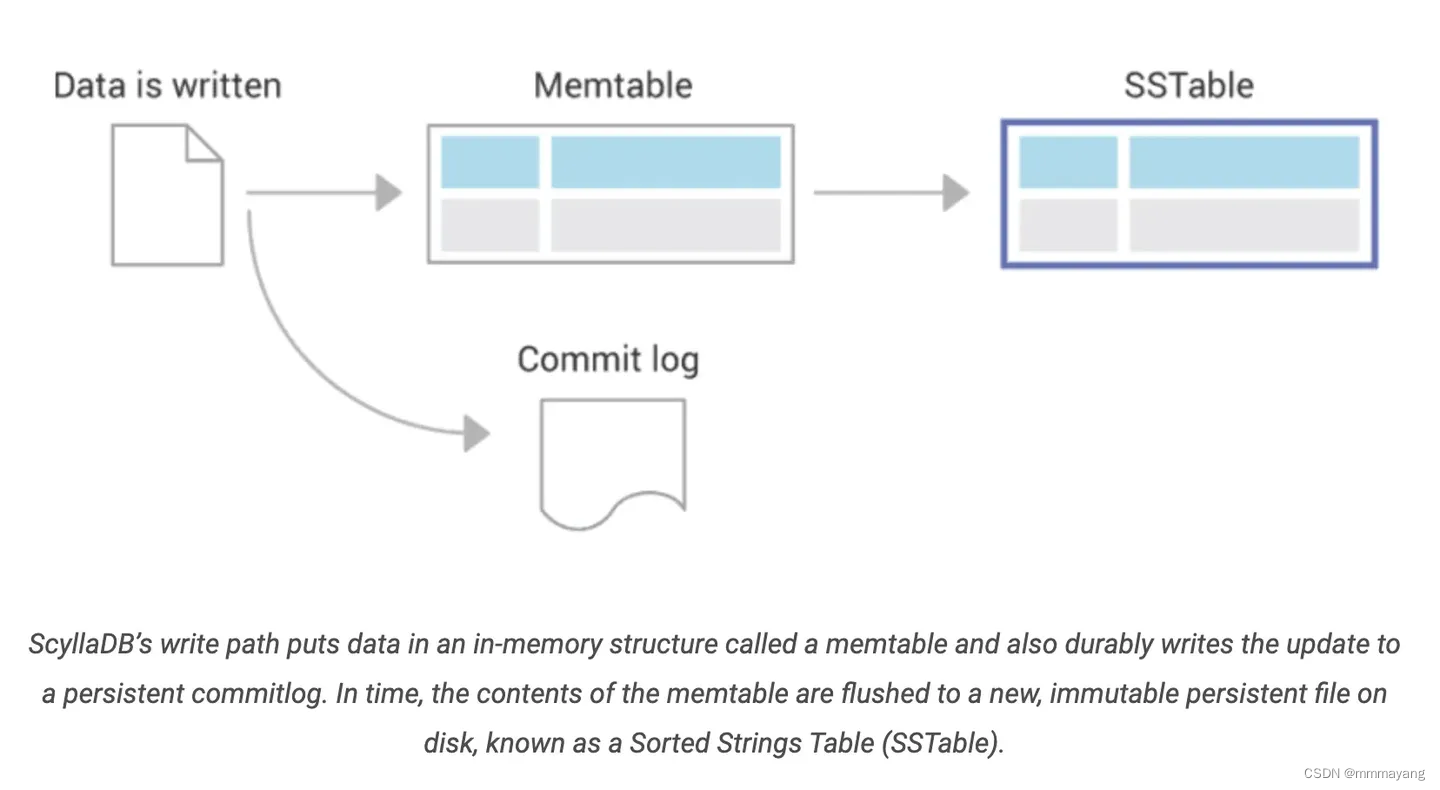
Memtable:在 ScyllaDB 的写入路径中,数据首先放入内存表中,存储在 RAM 中。 这些数据会及时刷新到磁盘以进行持久化。
Commitlog:本地节点操作的仅附加日志,在数据发送到内存表时同时写入。 这在节点关闭的情况下提供持久性(数据持久性); 当服务器重新启动时,提交日志可用于恢复内存表。
SSTables:在 ScyllaDB 中使用排序字符串表(SSTables)形式对每个分片的数据永久存储。SSTables 采用 LSM 格式,只读且不可更改。一旦数据从内存表刷新到 SSTable,内存表(以及关联的提交日志段)就可以被删除。 对记录的更新不会写入原始 SSTable,而是记录在新的 SSTable 中。 ScyllaDB 具有了解特定记录的哪个版本是最新版本的机制。
Tombstones(墓碑):当从 SSTable 中删除一行时,ScyllaDB 会将一个称为墓碑的标记放入新的 SSTable 中。这可以提醒数据库忽略被删除的原始数据。
Compactions:将多个 SSTable 写入磁盘后,ScyllaDB 知道要运行压缩,这是一个仅存储记录的最新副本的过程,并删除任何标有墓碑的记录。 一旦新的压缩的 SSTable 被写入,旧的、过时的 SSTable 就会被删除,并释放磁盘上的空间。
Compaction Strategy:ScyllaDB 使用不同的算法(称为策略)来确定何时以及如何最好地运行压缩。 该策略决定了写入、读取和空间放大之间的权衡。 ScyllaDB Enterprise 甚至支持一种称为增量压缩策略的独特方法,该方法可以显着节省磁盘开销。
对于上述提到的写入机制,说写入 memtable 与 CommitLog 是同时的,在我理解上,结合 WAL 机制的话,这里应该是有什么机制保证了同步写入的一致性,假如 commitLog 写入失败,那么写入 memtable 应该也需要失败。这两个地方的内容写入应该是要保证事务性的。否则在业务场景下,我写入了 memtable,但是我没写入 commitLog 成功,这时候数据还未曾落盘到 SST 文件中,那么此时 scyllaDB 宕机,恢复的时候其实在业务看来是没有这一条数据的,但是当时返回给用户的是存在的。那么这时候就会造成业务问题。(个人看法)
ScyllaDB 中的网络通信
Client-to-Server
ScyllaDB 支持多种网络协议,作用于客户端—服务器之间的 RPC Streaming 通信。Cassandra Query Language (CQL)、Apache Thrift、HTTP/HTTPS RESTful API。
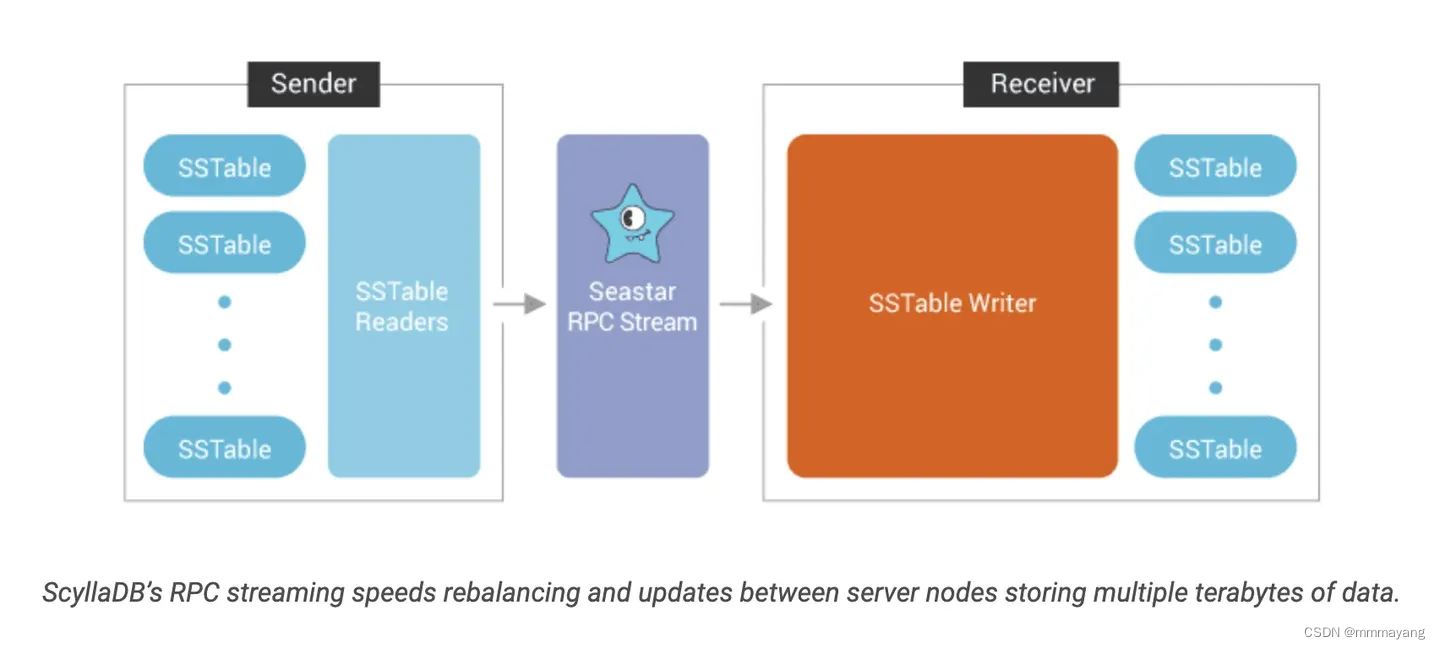
Server-to-Server
服务器—服务器使用时 RPC Streaming 进行通信。在 ScyllaDB 本身内,服务器到服务器的通信使用高效的 Seastar RPC 流,并使用暗示切换等反熵机制保持彼此同步。
Secure Networking
ScyllaDB 认真对待网络威胁,并应用强大的安全方法和协议,包括身份验证、基于角色的访问控制 (RBAC)、授权和加密。 用户可以对客户端和服务器节点之间以及服务器节点之间传输的数据应用加密。
ScyllaDB 性能
ScyllaDB 有着卓越的性能表现,具体见测试数据。得益于其优秀的架构设计外,还有上面提到的采用 C++编写充分利用 Linux 底层原语优势,利用现代多核、多处理器 NUMA 服务器硬件。
“无共享”设计
ScyllaDB 采用分片(Shard)设计,每个分片分配给特定 CPU 及其关联的内存 (RAM) 和持久存储(例如 NVMe SSD)。分片作为独立运行的单元运行,ScyllaDB 底层基于 Seastar 框架,采用高度异步、无共享设计。 每个数据分片都分配有 CPU、RAM、持久存储和网络资源,并尽可能高效地使用这些资源。 这大大减少了竞争以及对昂贵的处理锁的需求。 在无法避免内核之间通信的情况下,Seastar 提供高度可扩展的异步无锁内核间通信。
避免用户态内核态切换:
当在 SSTable 中找到一行时,需要通过网络将其发送到客户端。这涉及将数据从用户空间复制到内核空间。ScyllaDB 通过使用 Seastar 的网络堆栈来处理这个问题。Seastar 的网络堆栈在用户空间中运行,并利用DPDK实现更快的数据包处理。DPDK 绕过内核将数据直接复制到 NIC 缓冲区,并使其在最短的 CPU 周期得到处理。
卓越的内存管理:
当您有顺序 I/O 并且数据以有线格式存储在磁盘中时,页面缓存非常有用。然而,在 ScyllaDB 中,有 SSTable 形式的数据,页缓存以相同的格式存储数据,小数据会占用大量内存,并且在传输时需要序列化/反序列化。ScyllaDB 不依赖页缓存,而是将大部分内存分配给行缓存。Row-Cache 以优化的内存格式存储数据,占用空间更少,并且不需要序列化/反序列化使用行缓存的另一个优点是,当页面缓存受到冲击时发生压缩时,行缓存不会被删除。
此外,ScyllaDB Enterprise 和 ScyllaDB Cloud 中 提供了一个内存表(In-Memory Tables)的数据结构用来存储标准 CQL 可查询 SSTable,使得查询更快延迟更低。
其他:
ScyllaDB 还有许多其他的底层优化,这里有不全部展开了。
功能特性以及适用场景
cyllaDB 是一种高性能的 NoSQL 分布式数据库,以其独特的特性和性能优势在数据库领域占有一席之地。以下是 ScyllaDB 的一些主要特性,以及这些特性带来的优缺点和适用场景。
特性
兼容 Apache Cassandra: ScyllaDB 与 Cassandra 完全兼容,这意味着它可以无缝替换 Cassandra。
基于 C++ 的实现: 与 Cassandra 的 Java 实现相比,ScyllaDB 使用 C++ 编写,这提高了性能和效率。
分布式架构: 它采用分布式架构,可以横向扩展,易于处理大量数据。
自调优功能: ScyllaDB 具备自动化的资源管理和调优功能,能根据负载动态调整。
低延迟: 由于其高效的设计,ScyllaDB 提供极低的读写延迟。
高吞吐量: 它能够支持高并发读写操作,适合大规模数据处理。
弹性伸缩: 支持无停机的集群扩缩容。
强大的数据复制和一致性模型: 类似 Cassandra,提供高效的数据复制和灵活的一致性控制。
优点
性能高效: 由于 C++ 实现和自调优机制,提供了比许多同类产品更优秀的性能。
扩展性强: 能够轻松处理大规模数据,适合快速增长的应用需求。
兼容性好: 可以替换现有的 Cassandra 应用,降低迁移成本。
缺点
复杂性: 对于小型应用或者初学者来说,其复杂的配置和管理可能是一个挑战。
资源消耗: 高性能的代价是较高的资源消耗,尤其是在大规模部署时。
社区和支持: 相比于一些更成熟的数据库解决方案,ScyllaDB 的社区和支持可能不那么强大。
使用场景
推荐使用
大数据应用: 如数据仓库、实时大数据处理,尤其适合需要高吞吐量和低延迟的场景。
高并发应用: 如在线广告、推荐系统等需要快速响应的服务。
Cassandra 替代: 对于现有的 Cassandra 用户,ScyllaDB 是一个性能更优的替代品。
特定场景的 IM 系统: 可以结合考虑是否需要写多读少的场景,如果可以的话,scyllaDB 是个不错的选择。可以参考 discord 实现。
不推荐使用
小型或简单应用: 对于小规模数据或简单的应用,ScyllaDB 的高性能和复杂性可能是过剩的。
资源有限的环境: 在资源受限的环境下,ScyllaDB 的资源消耗可能成为问题。
总体而言,ScyllaDB 是一个非常强大的数据库选择,特别是在需要处理大量数据和高并发场景下。然而,它的复杂性和资源需求可能使它不适合所有类型的项目。同时使用时设置分区键的时候应该考虑热 Key 问题,如果有大 V 等场景,应该尽量避免造成热读写的问题。
总结
ScyllaDB 适合写操作偏多,读操作偏少的情况。这个操作量是相对的,如果你不是很确定你的业务需要哪一种,建议是多考虑多调研多测试,不要盲目的跟风使用 ScyllaDB,一旦使用了对于其他的 database 迁移支持并不友好(如果不能一直长期维护使用下去的话)。维护起来也比较麻烦,同时 ScyllaDB 使用起来可能还会有一些 bug。(博主遇见过 limit 限制不住分页查询的 bug,导致慢 CQL 导致业务语句超时。)
总之挑选最适合自己业务的才是最重要的。
其他
参考:
https://discord.com/blog/how-discord-stores-billions-of-messages
https://link.zhihu.com/?target=https%3A//www.scylladb.com/product/technology/
https://zhuanlan.zhihu.com/p/662212721


















