目录
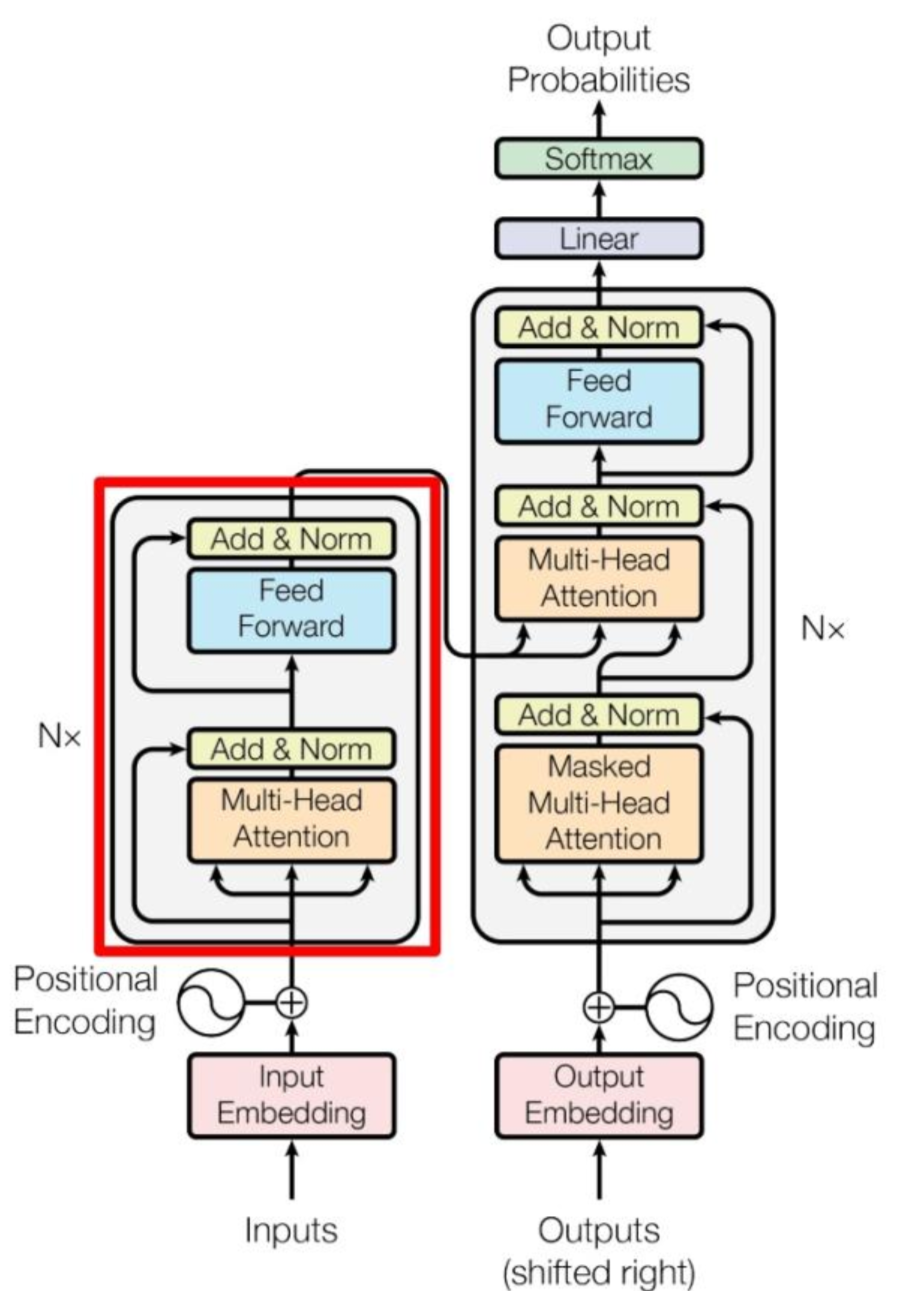
Encoder
Add&Norm:(LayerNorm)Transformer中的归一化(五):Layer Norm的原理和实现 & 为什么Transformer要用LayerNorm - 知乎 (zhihu.com)
LayerNorm怎么做的?
Feed Forward:
FeedForward代码:
公式:
FeedForward的作用是什么?
Decoder:
output:
它的output 是什么?
为什么output要进行shifted right操作?
Mask Muti-Head Attention---Mask:
什么是masked的操作?
masked代码:
为什么需要进行mask?
Muti-Head Attention:
相较于Encoder的不同点:
小结:
学习资料:7-位置编码与多层堆叠1.mp4_哔哩哔哩_bilibili
Transformer代码及解析(Pytorch) - 知乎 (zhihu.com)

Encoder
如图所示:
Add&Norm:(LayerNorm)Transformer中的归一化(五):Layer Norm的原理和实现 & 为什么Transformer要用LayerNorm - 知乎 (zhihu.com)
将多头注意力的输入和多头注意力的输出进行拼接,再进行LayerNorm。
拼接需要维度相同:
输入X(mxn m表示词数量,n表示词维度),Q,K,V的权重为W_q,W_k,W_v,其维度均为(nxn),
X与三个权重分别相乘得到Q,K,V,其维度均为(mxn),通过Attention公式计算可以得到Attention输出为mxn,和输出的X的维度相同。
拼接操作就是多头注意力的输入和多头注意力的输出两个矩阵的对应元素相加,得到的结果维度仍然是mxn.
LayerNorm怎么做的?

batch表示样本的数量,在上图中每一列表示一个词向量,对每个词向量的所有特征进行归一化。(d_model表示词向量的维度)
原输入为 batchxd_model 输出为batchx1:
self.layer_norm1 = nn.LayerNorm(d_model)Feed Forward:
对Transformer中FeedForward层的理解_transformer feed forward_江 东的博客-CSDN博客
FeedForward代码:
class FeedForward(nn.Module):def __init__(self, input_size, hidden_size, num_classes):super(FeedForward, self).__init__()self.input_size = input_sizeself.l1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.l2 = nn.Linear(hidden_size, num_classes)def forward(self, x):out = self.l1(x)out = self.relu(out)out = self.l2(out)return out
公式:
FeedForward的作用是什么?
FeedForward中增加了ReLU函数,它可以保留正数部分,对负数部分映射为0,将输入映射到了正数区间。这种做法使FFN并不是仅仅由线性模型y=wx+b构成,更符合实际问题的需求。比如进行房价预测时,可能X只包括收入和地段,y=wx+b只能研究收入和地段对房价的影响,但在实际情况还存在许多不确定因素,并不是简单的线性关系能描述的。
Decoder:
学习资料:机器学习-31-Transformer详解以及我的三个疑惑和解答_transformer不收敛-CSDN博客
output:
它的output 是什么?
如果该Transformer的任务是中英文转换,那么Encoder的输入是我是中国人,
Decoder的输入是分词进行的,一次输入一个词,逐词翻译。(假设当只有一个注意力头时)
输入s 预测出I的Attention值
输入s和I,预测出am的Attention值
输入s,I,am,预测出Chinese的Attention值
Decoder的输出是I am Chinese 终止符<f>
为什么output要进行shifted right操作?
shifted right就是右移的意思,I am Chinese右移,在最左端添加s,表示模型开始预测。
Decoder中的embedding,Add&Norm以及FeedForward和Encoder一样。
Mask Muti-Head Attention---Mask:
什么是masked的操作?
希望在翻译的时候,Decoder不能看到未来的翻译数据;即在翻译I时,不能知道 am和Chinese,要翻译出I,只能依靠起始符<s>
masked代码:
https://github.com/jadore801120/attention-is-all-you-need-pytorch github.com/jadore801120/attention-is-all-you-need-pytorch
def get_subsequent_mask(seq):''' For masking out the subsequent info. '''sz_b, len_s = seq.size()# torch.triu(diagonal=1)保留矩阵上三角部分,其余部分(包括对角线)定义为0。subsequent_mask = (1 - torch.triu(torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool()return subsequent_mask 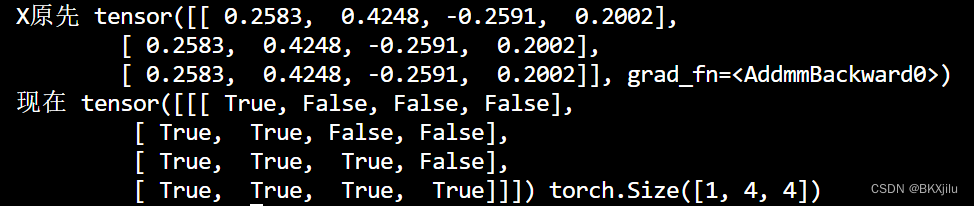
输入X(4x4)输入四个四维词向量,masked操作将X的上三角部分舍弃。
[True,False,False,False]表示输入<s>
[True,True,False,False]表示输入<s>+I
为什么需要进行mask?
s表示起始,E表示结束
下一行表示输入,上一行表示输出;j
像前面说的,我们是逐词进行翻译的,哪怕不使用masked,在翻译you时,我们也不能得到后续信息,完全不需要对后续信息进行mask操作:
但是Transformer实际上存在多头注意力,<s> I am Chinese可以在多个头里面并行求Attention,这时候掩码的存在就很有必要了。
Muti-Head Attention:
相较于Encoder的不同点:
输入有三个(1.masked muti-head Attention 的输出,2.l另外两个都是Encoder的muti-head Attention的Attention)
masked muti-head Attention 的输出和权重W_Q相乘 产生新的Q
Attention分别和W_K,W_V相乘,产生新的K和V。
小结:
1.LayerNorm表示对输入样本的所有特征进行归一化;
2.激活函数例如ReLu可以增加非线性信息,可以拟合更加复杂的情况,更贴合实际需要;
3.在并行化处理词向量时,mask的操作是必要的。

)


)


)
- 写一个 Hello World 并在华为手机上跑起来)
刷题关键点总结03【数组的改变、移动】)









