文章构建了一个通用单变量概率时间预测模型 Lag-Llama,在来自Monash Time Series库中的大量时序数据上进行了训练,并表现出良好的零样本预测能力。在介绍Lag-Llama之前,这里简单说明什么是概率时间预测模型。概率预测问题是指基于历史窗口内的序列值以及相关的一些协bianliang去预测一定窗口内未来值的联合分布
文章地址:https://arxiv.org/pdf/2310.08278v1.pdf
代码地址:https://github.com/kashif/pytorch-transformer-ts

将论文中的方案进行落地时,如果有问题,可以找我们一起来聊
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
本文源代码已梳理完毕,建了技术交流群&星球!想要进交流群或者资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流
方案介绍
注意到上面概率预测的定义中考虑了协变量C,Lag-Llama考虑的并不是像Nbeadts或TSMixer中的外部变量,而是来自序列本身的值。通常考虑一定的时间滞后,例如季度、月度、周度、日度、小时和秒级等,选取序列值,以匹配时间序列数据的周期性变化。当然作者指出也可以将单序列分成存在重叠的多个patch作为协变量,但这些patch中的数据点可能不再遵循时间上的因果性,因此作者更推荐第一种。
Lag-Llama的backbone是最新的LlaMA [43] 架构,通过RMSNorm实现预归一化,并在每个注意力层的Q和K表示中加入了旋转位置编码(RoPE),这里就不详细说明了,大家有兴趣可以参考:
-
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
-
https://ai.meta.com/blog/large-language-model-llama-meta-ai/
下面回到Lag-Llama模型,如下: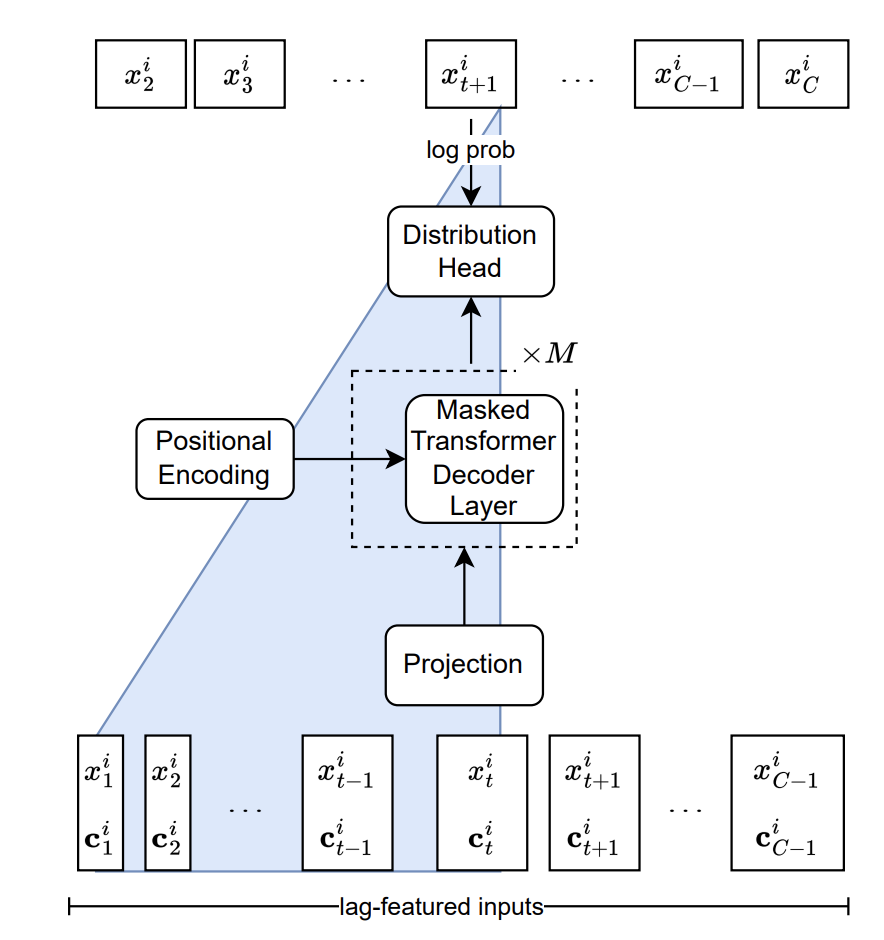
模型遵循自回归的模式,以历史时刻单变量的值以及对应的协变量为输入,经过M个transformer-based Decoder层,得到历史数据的表征,最后再经过一个Distribution head输出下个时刻预测值的概率分布,如上图蓝色三角形所示,最终通过最小化对数似然训练整个模型。
对于Distribution head,可以选择不同形式的分布与模型的表征能力相结合以输出任何形式的分布。文章中实验选择了student t分布,通过并通过Distribution head输出了与这个分布对应的三个参数,即其自由度、均值和尺度。在后续的工作中,大家或许可以选择更加复杂的分布形式,例如Normalizing flows概率模型、混合高斯模型、Copulas模型等。
相比于图片和语料数据,时序数据建模面临一个挑战,即量纲,数据集中的时间序列的取值可以是任意范围的。因此,文章对一定时间窗内的数据计算均值和方差,并进行归一化来去除量纲的影响,对于预测值,从指定分布采样后再对其进行反归一化来获取最终值。同时为了防止过拟合,模型在训练过程中对每个batch的数据都进行了Freq-Mix和Freq-Mask,这个大家感兴趣的可以去查看具体代码。
实验
训练数据集:
-
https://openreview.net/pdf?id=wEc1mgAjU-
-
https://arxiv.org/pdf/1906.05264.pdf
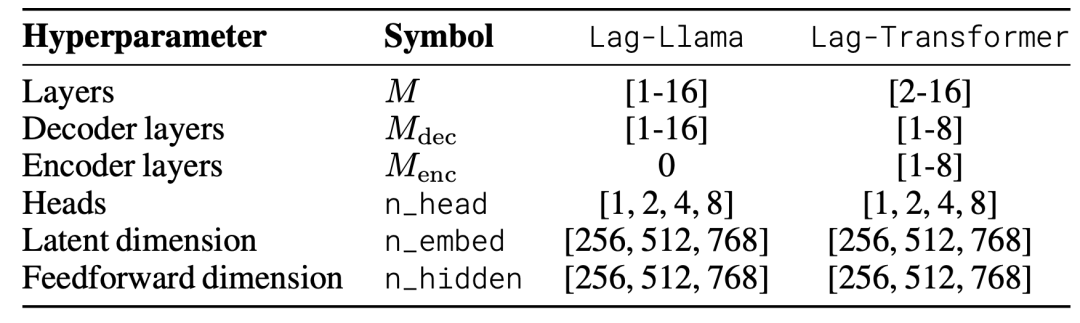
模型训练参数:
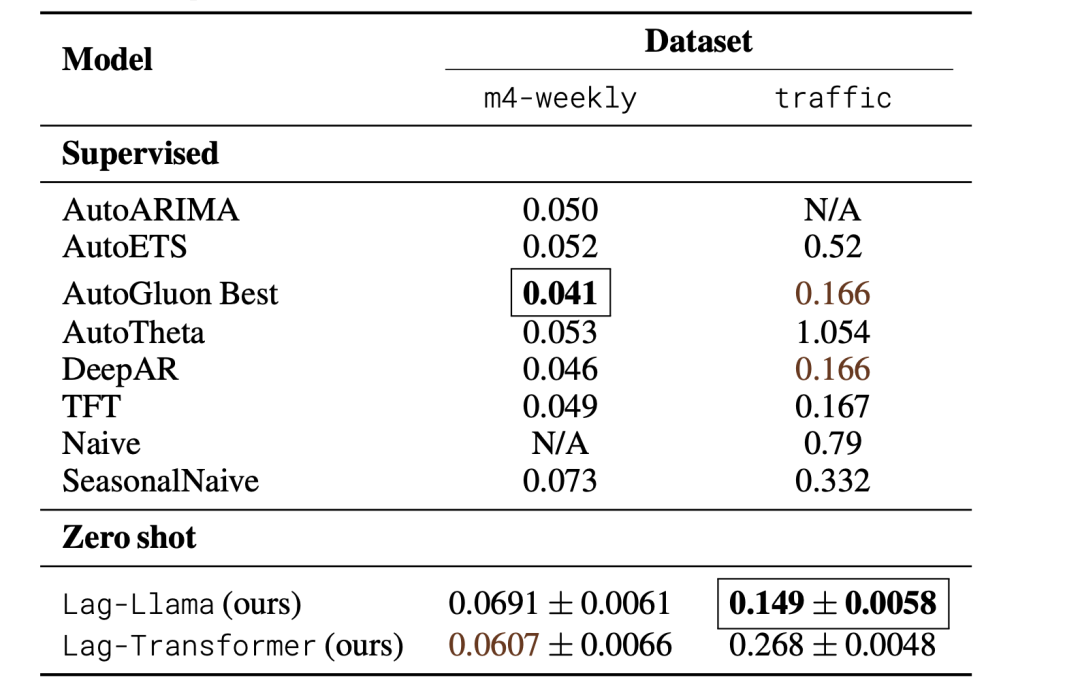
零样本数据集测试结果:
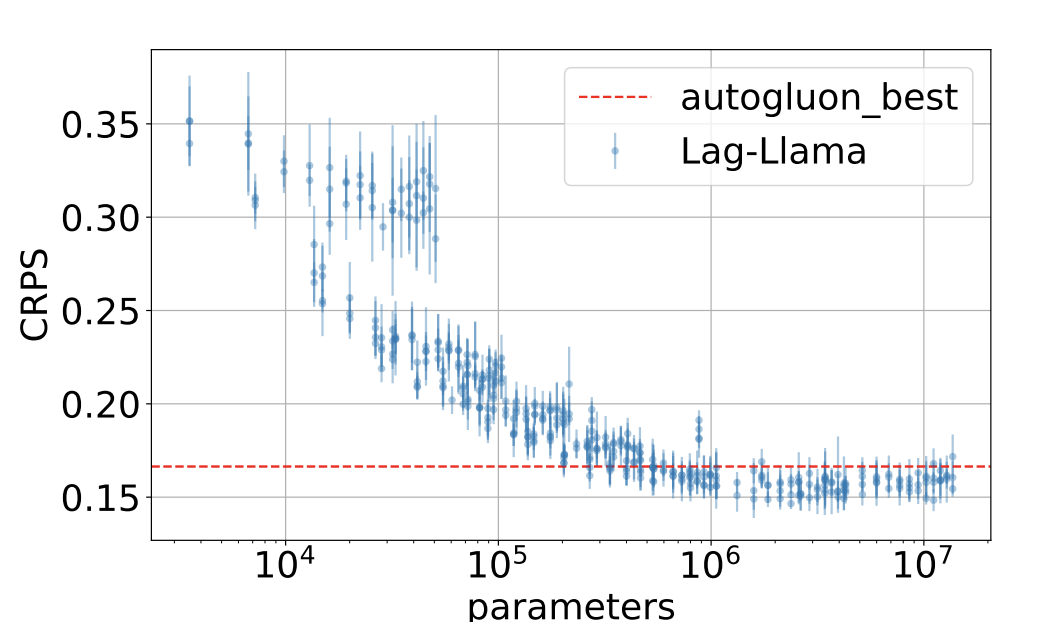
不同参数量的Lag-Llama模型在traffic数据集上的表现:参数量大于后,模型的性能就趋于稳定了。

)



笔记)
安装教程)





技术的优势和挑战-AI生成版)
)
![[山东大学操作系统课程设计]实验三](http://pic.xiahunao.cn/[山东大学操作系统课程设计]实验三)

)


