arxiv:[2212.10846] From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models (arxiv.org)
一、介绍
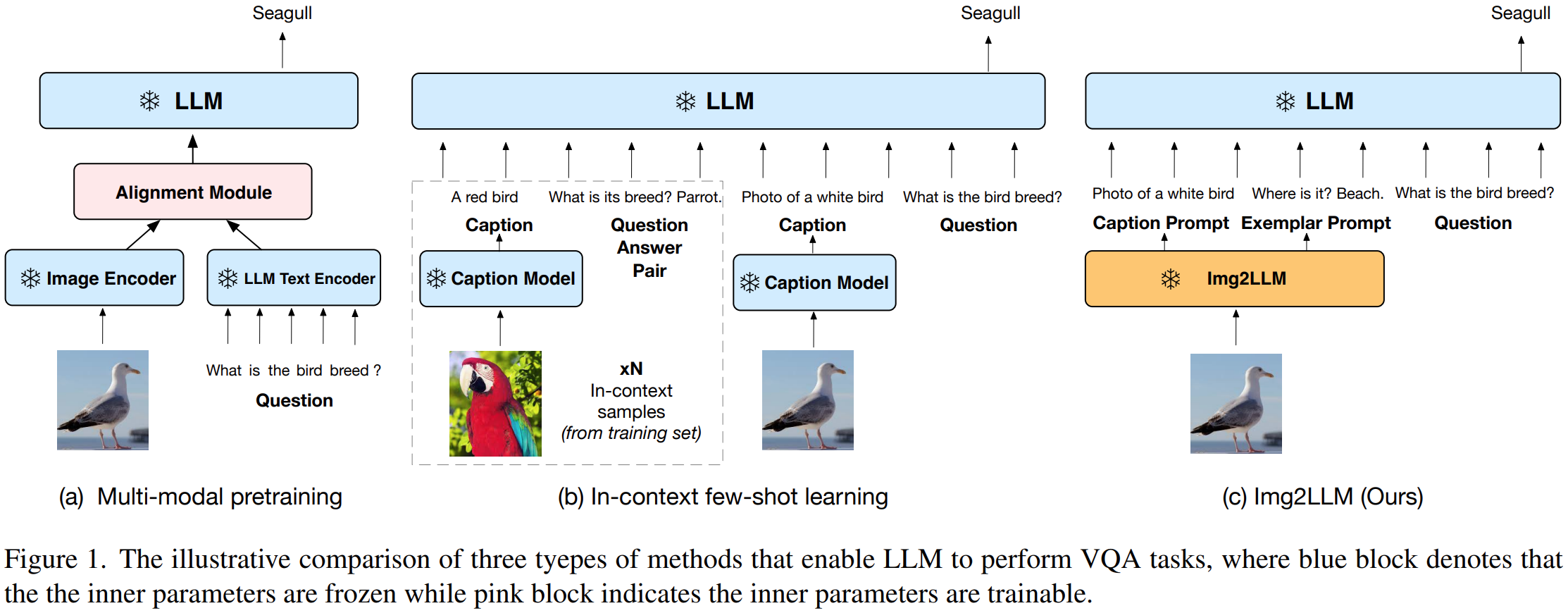
使用大语言模解决VQA任务的方法大概两种:multi-modal pretraining and language-mediated VQA,即多模态预训练的方法和以语言模型为媒介的VQA。
Multi-modal pretraining:训练一个额外的模块对齐视觉和语言向量。这类方法有两个很大的缺点,一是计算资源大,训练Flamingo需要1536 TPUv4,耗时两周。另外是灾难性遗Catastrophic forgetting. 如果LLM与视觉模型联合训练,则对齐步骤可能对LLM的推理能力不利。
Language-mediated VQA:这种VQA范式直接采用自然语言作为图像的中间表示,不再需要昂贵的预训练,不需要将图片向量化表示。PICa这种方法在few-shot setting中,为图片生成描述,然后从训练样本中选择in-context exemplars范例,但是当没有样本时,其性能会显著下降;另外还有一种方法生成与问题相关的标题。由于零样本的要求,它无法提供上下文中的范例,也无法获得上下文中学习的好处。因此,它必须依赖于特定QA的LLM,UnifiedQAv2,以实现高性能。
以语言为媒介的VQA,模态连接是通过将图片转化为语言描述,而不是稠密向量。任务连接是通过few-shot in-context exemplars或者大模型直接在文本问答上微调。
Img2LLM:本文提出的方法Img2LLM是,为图片生成问答范例,即从当前图像中生成合成的问答对作为上下文示例。也就是这些示例不仅演示了QA任务,而且还将图像的内容传达给LLM以回答问题Q。
三种方式比较:
二、Method

1. Answer Extraction
寻找可以作为合成问题答案的单词。方法是,使用现成的描述模块生成图片描述,然后从里面提取候选答案。提取时,提取名词短语(包括命名实体)、动词短语、形容词短语、数字和布尔型单词(如“是”和“否”)作为候选答案。
2. Question Generation
有了候选答案后可以使用现成的任意的问题生成模型为每一个候选答案生成具体的问题。
生成问题有两中方式:基于模板的方式和基于神经网络的方式。
Template-based Question Generation
For example, for answers that are nouns, we use the question “What object is in this image?” For verb answers, we use the question “What action is being taken in this image?
就是有个模板,然后填文本,生成问题。
Neural Question Generation
微调一个T5-large模型从答案里面产生问题。
training 输入:“Answer: [answer]. Context: [context]”,[answer] denotes the answer text,[context] denotes the context text from textual QA datasets。
inference:replace [answer] with an extracted answer candidate and [context] with the generated caption from which the answer was extracted.
在5个textual QA数据集上训练:SQuAD2.0, MultiRC, BookQA, Common-senseQA and Social IQA
有一个prompt组成的对比数据:

3. Question-relevant Caption Prompt
除了合成的QA对,和问题相关的图片描述也会输入模型。
问的问题可能会询问图像中的特定对象或区域,但现有网络生成的通用描述可能不包含相关信息。比如,在图2中,“什么东西在后台旋转,可以用来控制电力?”这个问题只与风力涡轮机有关。然而,从整个图像中生成的描述可能会集中在突出或倾斜的船上,使LLM没有信息来回答这个问题。为了解决这个问题,我们生成关于图像中与问题相关的部分的标题,并将其包含在LLM的提示中。
那么,怎么做到生成关于图像中与问题相关的部分的标题?使用了两个模型:Imagegrounded Text Encoder (ITE) in BLIP,GradCAM。ITE可以计算图片和问题的相似度,GradCAM可以生成一个粗略的定位图,突出显示给定问题的匹配图像区域。得到每个块和问题的相关度之后,根据概率采样一些图像块,然后为每个图像块生成图像描述。但是由于采样的不确定性,图片描述模型可能会生成对性能有负面影响的噪声字幕。为了去除有噪声的字幕,我们使用ITE来计算生成的字幕和采样的问题相关图像补丁之间的相似性得分,并过滤匹配得分小于0.5的字幕。总的来说,这个过程产生了与问题相关的、多样化的、干净的合成字幕,在视觉和语言信息之间架起了一座桥梁。
4. Prompt Design
到现在为止,合成了QA对question-answer pairs,图片描述question-relevant captions。
把这些instruction, captions, and QA exemplars拼接concatenate成一个完整的prompt。
instruction:“Please reason the answers of question according to the contexts.”
Contexts:[all captions]
Question:[question] Answer: [answer]
最后一个要问的问题放到最后,不写答案:
Question: [question]. Answer:
因为LM有输入字数的限制,所以生成的这些答案】描述不能都输进去。所以有一些答案、描述选择策略。为了选择信息量最大的提示,我们首先统计100个生成的字幕中合成答案候选者的频率。然后,我们选择30个频率最高的候选答案,并为每个答案生成一个问题。此外,我们还包括30个频率最低的答案和一个包含每个答案的标题。
三、实验部分
use BLIP to generate captions and perform image-question matching.
To localize the image regions relevant to the question, we generate GradCam from the cross-attention layer of BLIP image-grounded text encoder. Then sample K′ = 20 image patches based on GradCam, and use them to obtain 100 question-relevant captions.
LLMs:opensource OPT model with multiple different sizes.
四、其他


)



-请求参数格式的确定)







:坐标系关系查看与一个案例)






:基于本地知识库的检索增强生成RAG)