逻辑回归、激活函数及其代价函数
线性回归的可行性
对分类算法,其输出结果y只有两种结果{0,1},分别表示负类和正类,代表没有目标和有目标。
在这种情况下,如果用传统的方法以线性拟合 ( h θ ( x ) = θ T X ) (h_θ (x)=θ^T X) (hθ(x)=θTX),对于得到的函数应当对y设置阈值a,高于a为一类,低于a为一类。

对于分类方法,这种拟合的方式极易受到分散的数据集的影响而导致损失函数的变化,以至于对于特定的损失函数,其阈值的设定十分困难。
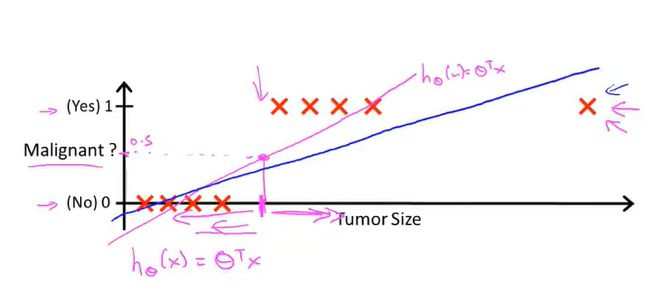
除此之外, h θ ( x ) h_θ (x) hθ(x)(在分类算法中称为分类器)的输出值很可能非常大或者非常小,并不与{0,1}完全相符
假设表示
基于上述情况,要使分类器的输出在[0,1]之间,可以采用假设表示的方法。
设 h θ ( x ) = g ( θ T x ) h_θ (x)=g(θ^T x) hθ(x)=g(θTx),
其中 g ( z ) = 1 ( 1 + e − z ) g(z)=\frac{1}{(1+e^{−z} )} g(z)=(1+e−z)1, 称为逻辑函数(Sigmoid function,又称为激活函数,生物学上的S型曲线)
h θ ( x ) = 1 ( 1 + e − θ T X ) h_θ (x)=\frac{1}{(1+e^{−θ^T X} )} hθ(x)=(1+e−θTX)1
其两条渐近线分别为h(x)=0和h(x)=1
在分类条件下,最终的输出结果是:
h θ ( x ) = P ( y = 1 │ x , θ ) h_θ (x)=P(y=1│x,θ) hθ(x)=P(y=1│x,θ)
其代表在给定x的条件下 其y=1的概率
P ( y = 1 │ x , θ ) + P ( y = 0 │ x , θ ) = 1 P(y=1│x,θ)+P(y=0│x,θ)=1 P(y=1│x,θ)+P(y=0│x,θ)=1
决策边界( Decision boundary)
对假设函数设定阈值 h ( x ) = 0.5 h(x)=0.5 h(x)=0.5,
当 h ( x ) ≥ 0.5 h(x)≥0.5 h(x)≥0.5 时,输出结果y=1.
根据假设函数的性质,当 x ≥ 0 时, x≥0时, x≥0时,h(x)≥0.5
用 θ T x θ^T x θTx替换x,则当 θ T x ≥ 0 θ^T x≥0 θTx≥0时, h ( x ) ≥ 0.5 , y = 1 h(x)≥0.5,y=1 h(x)≥0.5,y=1
解出 θ T x ≥ 0 θ^T x≥0 θTx≥0,其答案将会是一个在每一个 x i x_i xi轴上都有的不等式函数。
这个不等式函数将整个空间分成了y=1 和 y=0的两个部分,称之为决策边界。
激活函数的代价函数
在线性回归中的代价函数:
J ( θ ) = 1 m ∑ i = 1 m 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 J(θ)=\frac{1}{m}∑_{i=1}^m \frac{1}{2} (h_θ (x^{(i)} )−y^{(i)} )^2 J(θ)=m1i=1∑m21(hθ(x(i))−y(i))2
令 C o s t ( h θ ( x ) , y ) = 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 Cost(hθ (x),y)=\frac{1}{2}(h_θ (x^{(i)} )−y^{(i)} )^2 Cost(hθ(x),y)=21(hθ(x(i))−y(i))2,
Cost是一个非凹函数,有许多的局部最小值,不利于使用梯度下降法。对于分类算法,设置其代价函数为:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) ∗ l o g ( 1 − h θ ( x ( i ) ) ) ] J(θ)=-\frac{1}{m}∑_{i=1}^m [y^{(i)}log(h_θ (x^{(i)}) )−(1-y^{(i)})*log(1-h_θ (x^{(i)}))] J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))−(1−y(i))∗log(1−hθ(x(i)))]
对其化简:
C o s t ( h θ ( x ) , y ) = − y l o g ( h θ ( x ) ) − ( ( 1 − y ) l o g ( 1 − h θ ( x ) ) ) Cost(h_θ (x),y)=−ylog(h_θ (x))−((1−y)log(1−h_θ (x))) Cost(hθ(x),y)=−ylog(hθ(x))−((1−y)log(1−hθ(x)))
检验:
当 y = 1 y=1 y=1时, − l o g ( h θ ( x ) ) −log(h_θ (x)) −log(hθ(x))
当 y = 0 y=0 y=0时, − l o g ( 1 − h θ ( x ) ) −log(1−h_θ (x)) −log(1−hθ(x))
那么代价函数可以写成:
J ( θ ) = − 1 m [ ∑ i = 1 m y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] J(θ)=-\frac{1}{m}[∑_{i=1}^m y^{(i)} log(h_θ(x^{(i)} ))+(1−y^{(i)}) log(1−h_θ (x^{(i)}))] J(θ)=−m1[i=1∑my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
对于代价函数,采用梯度下降算法求θ的最小值:
θ j ≔ θ j − α ∂ J ( θ ) ∂ θ j θ_j≔θ_j−α\frac{∂J(θ)}{∂θ_j} θj:=θj−α∂θj∂J(θ)
代入梯度:
θ j ≔ θ j − α ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j i θ_j≔θ_j−α∑_{i=1}^m(h_θ (x^{(i)} )−y^{(i)} ) x_j^i θj:=θj−αi=1∑m(hθ(x(i))−y(i))xji



)


:集成学习)



)







)
