一、介绍
职位招聘管理与推荐系统。本系统使用Python作为主要开发语言,以WEB网页平台的方式进行呈现。前端使用HTML、CSS、Ajax、BootStrap等技术,后端使用Django框架处理用户请求。
系统创新点:相对于传统的管理系统,本系统使用协同过滤推荐算法,基于用户对职位的评分为数据基础,对当前用户进行个性化的职位推荐。
主要功能如下:
- 系统分为管理员和用户两个角色权限
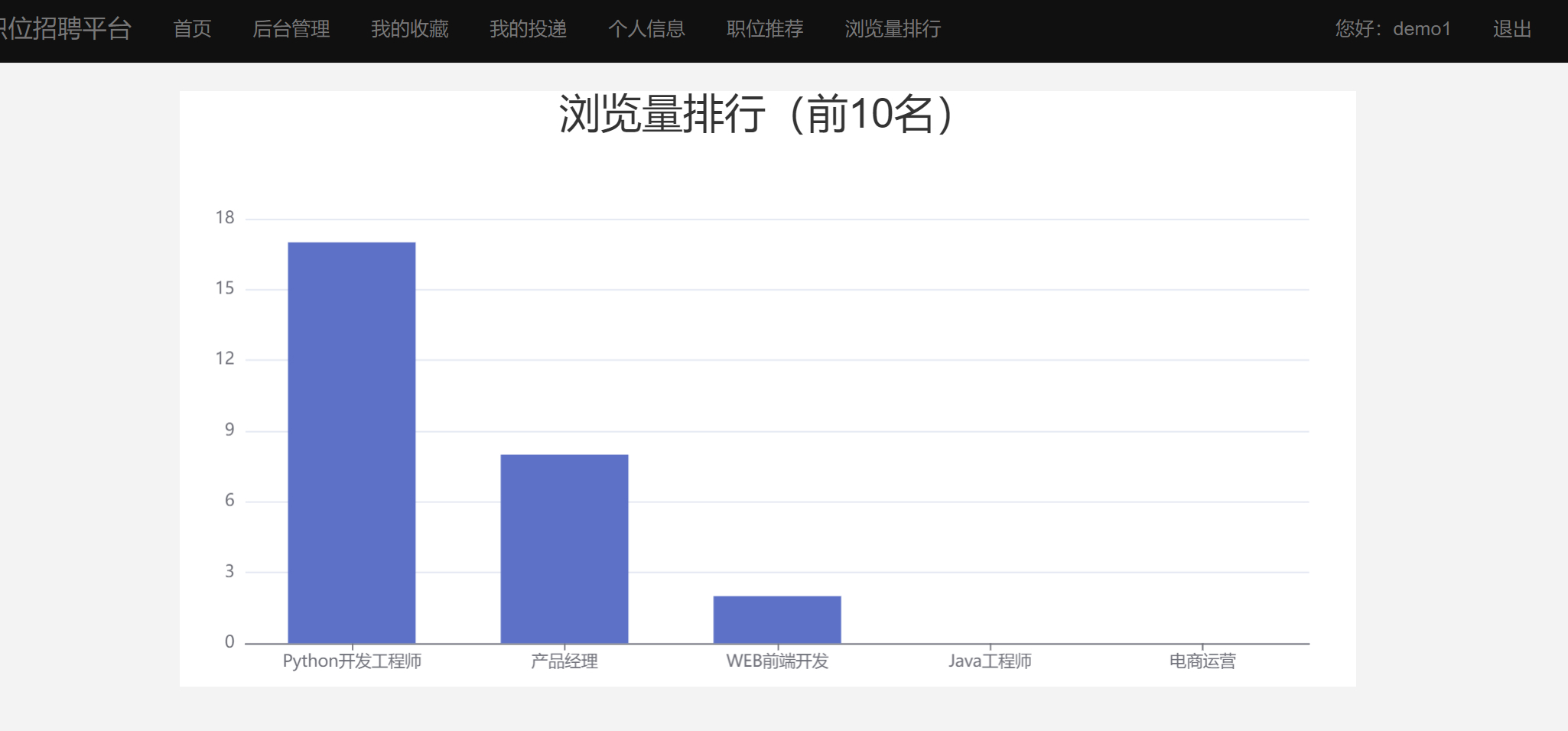
- 用户可以注册、登录、查看职位、发表评论、对职位进行打分、收藏职位、投递简历,查看投递状态、编辑个人简历信息、查看浏览量柱状图、职位推荐等
- 管理员在登录后台管理系统中可以对职位和用户信息进行管理
二、系统部分效果图片展示
三、演示视频+代码+安装
地址:https://www.yuque.com/ziwu/yygu3z/hfnmohf9n5gqfnd7
四、协同过滤推荐算法介绍
协同过滤算法是推荐系统的核心技术之一,起源于20世纪90年代。它的基本思想是:如果两个人在过去喜欢相似的东西,那么他们在未来也可能喜欢相似的东西。协同过滤可以分为两类:基于用户的和基于物品的。
基于用户的协同过滤(User-based Collaborative Filtering)关注于找出拥有相似喜好的用户。例如,如果用户A和用户B在过去喜欢了许多相同的电影,那么用户A喜欢的其他电影也可能会被用户B喜欢。它的特点是直观、易于实现。
接下来,我将用Python实现一个简单的基于用户的协同过滤算法。
import numpy as np# 生成一个示例用户-物品评分矩阵
ratings = np.array([[5, 4, 0, 1],[4, 0, 4, 1],[1, 2, 3, 3],[0, 1, 2, 4],
])# 计算用户之间的相似度
def calculate_similarity(ratings):# 用户数量n_users = ratings.shape[0]# 初始化相似度矩阵similarity = np.zeros((n_users, n_users))for i in range(n_users):for j in range(n_users):# 计算用户i和用户j的相似度rating_i = ratings[i, :]rating_j = ratings[j, :]# 只考虑双方都评分的项目common_ratings = np.where((rating_i > 0) & (rating_j > 0))[0]if len(common_ratings) == 0:similarity[i, j] = 0else:# 使用余弦相似度similarity[i, j] = np.dot(rating_i[common_ratings], rating_j[common_ratings]) / (np.linalg.norm(rating_i[common_ratings]) * np.linalg.norm(rating_j[common_ratings]))return similarity# 生成推荐
def recommend(ratings, similarity, user_index):scores = np.dot(similarity, ratings)# 除以每个用户的相似度总和sum_similarity = np.array([np.abs(similarity).sum(axis=1)])scores = scores / sum_similarity.T# 返回推荐结果return scores[user_index]# 计算用户相似度
user_similarity = calculate_similarity(ratings)
# 为第一个用户生成推荐
user_recommendation = recommend(ratings, user_similarity, 0)print("推荐分数:", user_recommendation)
在这段代码中,首先创建了一个简单的用户-物品评分矩阵,然后计算了用户之间的相似度,并基于这些相似度生成了针对特定用户的推荐。这里使用了余弦相似度来衡量用户之间的相似程度,这是协同过滤中常见的方法之一。

)





-Part.10 创建集群)
)



)






