Elasticsearch 排序允许你根据特定条件对搜索结果进行排序。 然而,在排序时处理区分大小写时,Elasticsearch 将大写和小写字母视为不同的字符,分别对它们进行排序。 这是因为 ASCII 表顺序是从大写 A 到小写 z。
默认情况下,Elasticsearch 按以下顺序对字符串进行排序:首先是数字,然后是大写字母,最后是小写字母。 例如,如果您有术语 “Apple”、“apple”、“banana”、“Carrot” 和 “1apple”,它们将按升序排序为“1apple”、“Apple”、“Carrot”、“ apple”、“banana”。
POST /test_casing/_bulk
{ "index" : {} }
{ "my_field" : "Apple" }
{ "index" : {} }
{ "my_field" : "apple" }
{ "index" : {} }
{ "my_field" : "banana" }
{ "index" : {} }
{ "my_field" : "Carrot" }
{ "index" : {} }
{ "my_field" : "1apple" }
这种默认行为可能并不总是令人满意。 例如,如果你对值 “Apple”、“banana” 和 “Carrot” 建立了索引,并且使用升序排列,那么你将得到 “Apple”、“Carrot” 和“banana”。 但是,你可能想要 “Apple”、“banana”、“Carrot”。
为此,你可以使用 Elasticsearch 中称为规范化器(normalizer)的功能。 规范化器与关键字字段类型一起使用,允许你以类似于分析文本的方式预处理关键字字段的输入。
然而,与分析器不同,规范化器不会将输入分解为标记。 这使得它适合需要对整个输入进行索引或排序的关键字字段类型。
PUT /test_casing2
{"settings": {"analysis": {"normalizer": {"my_normalizer": {"type": "custom","filter": ["lowercase"]}}}},"mappings": {"properties": {"my_field": {"type": "keyword","normalizer": "my_normalizer"}}}
}POST /test_casing2/_bulk
{"index":{}}
{"my_field":"Apple"}
{"index":{}}
{"my_field":"apple"}
{"index":{}}
{"my_field":"banana"}
{"index":{}}
{"my_field":"bananA"}
{"index":{}}
{"my_field":"Carrot"}
需要注意的是,使用标准化器会改变索引中的值。 如果你想保留原始值,例如带有大写 “A” 的 “Apple”,你可以使用子字段(sub-fields)。 这允许你保留原始字段值和标准化字段值。 在聚合结果中,Elasticsearch 将仅显示你在聚合中使用的字段。
不幸的是,Elasticsearch 不支持直接在术语聚合中进行不区分大小写的排序。 即使使用脚本聚合和标准化器,也不可能以不区分大小写的方式排序并区分大小写地显示结果。 这是用户在使用 Elasticsearch 时应该注意的限制。
如何向现有索引添加标准化器?
让我们看一下在 Elasticsearch 中向现有索引添加规范器的过程的实际示例。 此过程涉及几个步骤:关闭索引、更新设置、重新打开索引、更新映射、更新数据索引,最后运行查询。
首先,你需要使用以下命令关闭索引:
POST test_casing/_close接下来,你更新索引的设置以添加标准化器。 在本例中,我们添加一个应用小写过滤器的自定义规范化器:
PUT test_casing/_settings
{"analysis": {"normalizer": {"my_normalizer": {"type": "custom","filter": ["lowercase"]}}}
}更新设置后,你可以重新打开索引:
POST test_casing/_open现在,你需要更新索引的映射以使用规范器。 在这里,我们向 “my_field” 添加一个使用标准化器的子字段:
PUT test_casing/_mapping
{"properties": {"my_field": {"type": "text","fields": {"normalized": {"type": "keyword","normalizer": "my_normalizer"}}}}
}请注意,my_field.normalized 是字段名称。
接下来,你可以通过运行 update_by_query 来更新数据索引,这将在 my_field.normalized 字段内添加数据:
POST test_casing/_update_by_query最后,你可以对索引运行搜索查询。 在本例中,我们在新的标准化字段上运行聚合:
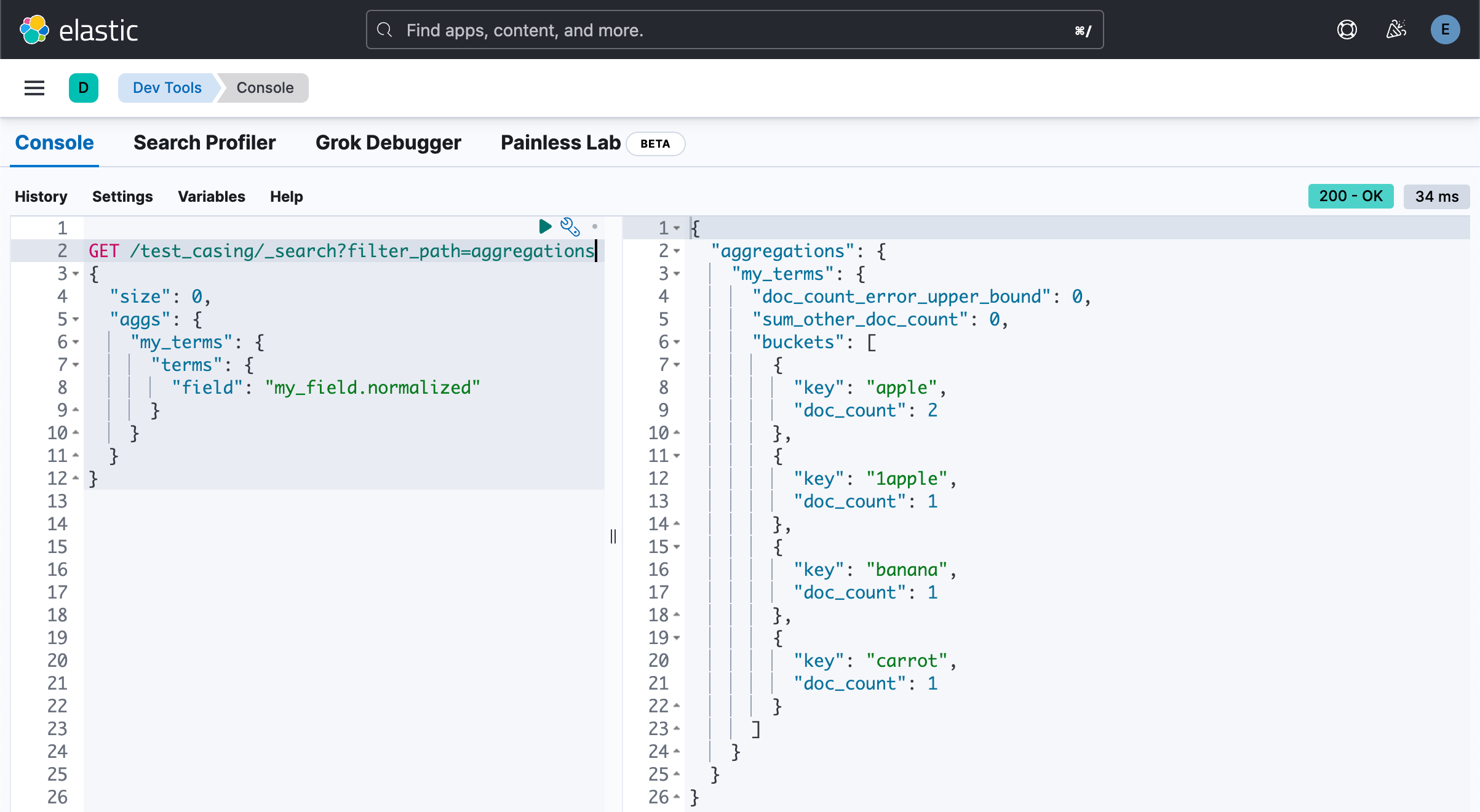
GET /test_casing/_search
{"size": 0,"aggs": {"my_terms": {"terms": {"field": "my_field.normalized"}}}
}此过程演示了如何将规范器添加到 Elasticsearch 中的现有索引,从而使你能够更灵活地处理区分大小写的问题。

:DDR SDRAM组成与工作过程)


- ACodec(一))


)

)









