目录
- 准备工作
- 创建集群
- 注意点
- 1. kubeconfig未正常加载
- 2. container runtime is not running
- 3. The connection to the server 172.16.190.132:6443 was refused - did you specify the right host or port?
- 4. 集群重置
- 5.加入子节点
- 代码调试
准备工作
apple m1芯片
- 安装vmware fusion,然后使用ubuntu 64位 ARM server 22.04.3
- 安装docker,这个在装系统的时候勾选上就好了,装系统的时候会自动装上
- 安装
kubelet kubeadm kubectl
官方文档
首先添加Kubernetes软件包签名密钥
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
然后添加kubernetes软件包仓库
sudo apt-add-repository "deb http://apt.kubernetes.io/ kubernetes-xenial main"
更新软件包列表
sudo apt-get update
安装
sudo apt-get install -y kubelet kubeadm kubectl
注意:如有网络问题请自行解决
禁用交换分区
swapoff -a
允许iptables检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOFcat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOFsudo sysctl --system
创建集群
sudo kubeadm init \
--apiserver-advertise-address=172.16.190.135 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
--kubernetes-version为控制平面选择一个特定的 Kubernetes 版本。--pod-network-cidr指明 Pod 网络可以使用的 IP 地址段。如果设置了这个参数,控制平面将会为每一个节点自动分配 CIDR。--apiserver-advertise-addressAPI 服务器所公布的其正在监听的 IP 地址,设置为master节点的ip地址。如果未设置,则使用默认网络接口。
出现下面的画面,说明控制面成功初始化了
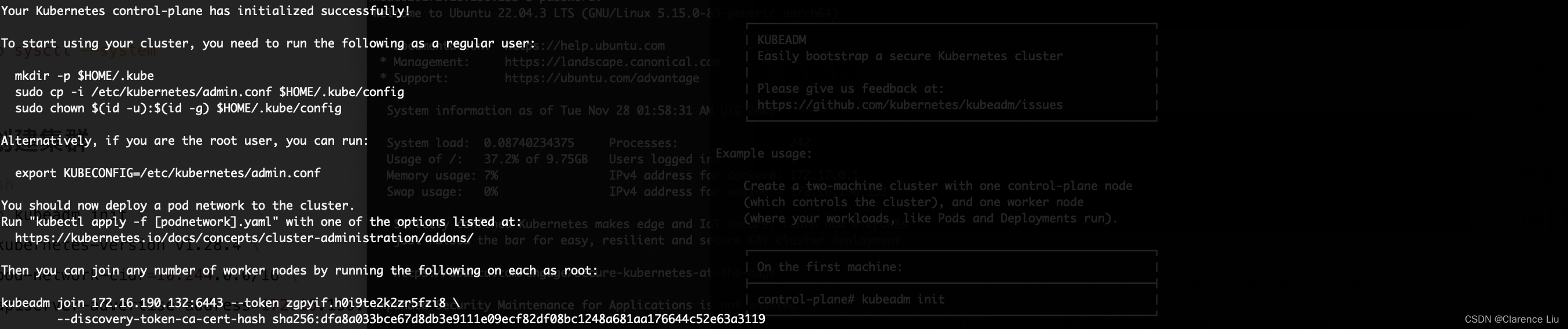
- 然后按照提示,使用如下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
- 这样就会生成
~/.kube/config文件,就是集群的kubeconfig文件
如果是root用户,可以使用如下命令
export KUBECONFIG=/etc/kubernetes/admin.conf
在主节点机器上运行下面的命令
sudo kubeadm token create --print-join-command
把得到的结果复制到子节点机器上运行
sudo kubeadm join 172.16.190.132:6443 --token wih5po.h3gmincq4q7ew12f --discovery-token-ca-cert-hash sha256:dfa8a033bce67d8db3e9111e09ecf82df08bc1248a681aa176644c52e63a3119
这样就可以把ip为172.16.190.132的节点加到集群中
- 现在node的状态应该是notReady,这时候需要添加Flannel网络插件
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
之后节点状态就变成了Ready
注意点
1. kubeconfig未正常加载
- 使用
kubectl config view结果如果是下面这样,说明kubeconfig文件普通用户没有权限或者没有配置到环境变量中
apiVersion: v1
clusters: null
contexts: null
current-context: ""
kind: Config
preferences: {}
users: null
- 这时候需要
sudo chmod 666 /etc/kubernetes/admin.conf,即可解决
2. container runtime is not running
参考https://www.cnblogs.com/ztxd/articles/16505585.html
3. The connection to the server 172.16.190.132:6443 was refused - did you specify the right host or port?
- 这个问题的表现是每隔一会核心组件都开始重启,kubectl命令失效
- 这种情况下要到
/var/log/pods/目录下看组件日志,kubernetes上的集群节点组件的系统级别日志存储在这里,系统级别的日志文件通常会包含更多的底层系统信息和组件级别的错误。注意kubectl命令看到的日志是针对容器化的kubernetes组件在容器中产生的日志,这些日志通常不会直接写入到/var/log目录中,而是通过容器运行时的机制(如Docker、containerd)进行收集和管理 - 我看到etcd的日志中有以下日志
2023-11-29T06:41:05.691880439Z stderr F {"level":"info","ts":"2023-11-29T06:41:05.69144Z","caller":"embed/serve.go:250","msg":"serving client traffic securely","traffic":"grpc+http","address":"127.0.0.1:2379"}
2023-11-29T06:41:17.617799496Z stderr F {"level":"info","ts":"2023-11-29T06:41:17.617594Z","caller":"osutil/interrupt_unix.go:64","msg":"received signal; shutting down","signal":"terminated"}
2023-11-29T06:41:17.617860196Z stderr F {"level":"info","ts":"2023-11-29T06:41:17.617684Z","caller":"embed/etcd.go:376","msg":"closing etcd server","name":"master","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://172.16.190.135:2380"],"advertise-client-urls":["https://172.16.190.135:2379"]}
2023-11-29T06:41:17.618113328Z stderr F {"level":"warn","ts":"2023-11-29T06:41:17.617968Z","caller":"embed/serve.go:212","msg":"stopping secure grpc server due to error","error":"accept tcp 172.16.190.135:2379: use of closed network connection"}
2023-11-29T06:41:17.618121536Z stderr F {"level":"warn","ts":"2023-11-29T06:41:17.61803Z","caller":"embed/serve.go:214","msg":"stopped secure grpc server due to error","error":"accept tcp 172.16.190.135:2379: use of closed network connection"}
2023-11-29T06:41:17.618223064Z stderr F {"level":"warn","ts":"2023-11-29T06:41:17.618176Z","caller":"embed/serve.go:212","msg":"stopping secure grpc server due to error","error":"accept tcp 127.0.0.1:2379: use of closed network connection"}
2023-11-29T06:41:17.618367669Z stderr F {"level":"warn","ts":"2023-11-29T06:41:17.61832Z","caller":"embed/serve.go:214","msg":"stopped secure grpc server due to error","error":"accept tcp 127.0.0.1:2379: use of closed network connection"}
2023-11-29T06:41:17.638942763Z stderr F {"level":"info","ts":"2023-11-29T06:41:17.638737Z","caller":"etcdserver/server.go:1465","msg":"skipped leadership transfer for single voting member cluster","local-member-id":"aff1bc4be5440e1","current-leader-member-id":"aff1bc4be5440e1"}
2023-11-29T06:41:17.640764851Z stderr F {"level":"info","ts":"2023-11-29T06:41:17.640624Z","caller":"embed/etcd.go:579","msg":"stopping serving peer traffic","address":"172.16.190.135:2380"}
2023-11-29T06:41:17.640807803Z stderr F {"level":"info","ts":"2023-11-29T06:41:17.640736Z","caller":"embed/etcd.go:584","msg":"stopped serving peer traffic","address":"172.16.190.135:2380"}
2023-11-29T06:41:17.640883668Z stderr F {"level":"info","ts":"2023-11-29T06:41:17.640778Z","caller":"embed/etcd.go:378","msg":"closed etcd server","name":"master","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://172.16.190.135:2380"],"advertise-client-urls":["https://172.16.190.135:2379"]}
- etcd异常关闭,导致apiserver连不上2379端口,grpc调用失败,最后导致apiserver crash
- 可以看到有一条日志
{"level":"info","ts":"2023-11-29T06:41:17.617594Z","caller":"osutil/interrupt_unix.go:64","msg":"received signal; shutting down","signal":"terminated"},说明系统中断导致etcd关闭,那么究竟是什么原因导致的?经过排查发现容器运行时没配置cgroup驱动,我们在/etc/containerd/config.toml文件中写入如下内容
version = 2
[plugins][plugins."io.containerd.grpc.v1.cri"][plugins."io.containerd.grpc.v1.cri".containerd][plugins."io.containerd.grpc.v1.cri".containerd.runtimes][plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]runtime_type = "io.containerd.runc.v2"[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]SystemdCgroup = true
- 简单来说,containerd的作用是对linux进程组进行资源限制和控制,以便于集群的稳定性和性能,在上面的例子中,我们没有配置这个东西,那么个人认为我们不同的pod之间可能就会出现一些资源竞争问题,导致pod不稳定
- 重启containerd,
systemctl restart containerd,集群恢复正常
参考
https://kubernetes.io/zh-cn/docs/setup/production-environment/container-runtimes/#containerd
https://github.com/etcd-io/etcd/issues/13670
4. 集群重置
要使用kubeadm reset重置,然后将kubeconfig文件夹删掉,重新部署
5.加入子节点
理论上kubeadm init之后会给你加入节点的语句,如果token过期了,可以使用下面的语句重新生成
kubeadm token create --print-join-command
然后在子节点所在的机器输入命令即可
代码调试
- 经过上面的步骤,我们已经构建了三节点的集群,其中有一个master节点和两个node节点
- 接下来我们要做的是本地起一个kube-apiserver,让集群中各组件都与我们本地的kube-apiserver交互
- 为了达成这个目标,我们需要配置一个本地的ca证书供apiserver使用
- 我们按照以下的步骤进行,以下最好使用root账户操作,否则可能会出问题
- 拉取kubernetes master分支代码到本地
git clone -b master https://github.com/kubernetes/kubernetes.git
- 生成服务器私钥文件
openssl genrsa -out server.key 2048
- 生成服务器csr证书申请文件(Certificate Signing Request)
openssl req -newkey rsa:2048 -nodes -keyout server.key -subj "/CN=*.wsc.com" -out server.csr
- 生成服务器证书文件
openssl x509 -req -extfile <(printf "subjectAltName=DNS:wsc.com,DNS:www.wsc.com") -days 365 -in server.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out server.crt
- 生成客户端私钥文件
openssl genrsa -out client.key 2048
- 生成客户端csr证书申请文件,注意
/opt/homebrew/etc/openssl@3/openssl.cnf文件的具体位置要使用openssl version -a|grep OPENSSLDIR命令获取,在我的macos本地的路径是/opt/homebrew/etc/openssl@3/openssl.cnf
openssl req -new -sha256 -key client.key -subj "/CN=*.wsc.com" -reqexts SAN -extensions SAN -config <(cat /opt/homebrew/etc/openssl@3/openssl.cnf <(printf "[SAN]\nsubjectAltName=DNS:wsc.com,DNS:www.wsc.com")) -out client.csr
- 生成客户端证书文件
openssl x509 -req -in client.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out client.crt -days 5000
- 指定kubeconfig的文件目录,这里写你自己的kubeconfig位置
export KUBECONFIG=/Users/xxx/.kube/config
- 指定kube-apiserver连接地址,这里使用之前ca证书生成的CN域名
kubectl config set-cluster kubernetes --certificate-authority=/etc/kubernetes/pki/ca.crt --embed-certs=true --server=https://wsc.com:6443
- 指定用户
kubectl config set-credentials wsc --client-certificate=client.crt --client-key=client.key --embed-certs=true
- 指定集群上下文名称,这里使用了刚才的客户端连接证书
kubectl config set-credentials wsc --client-certificate=client.crt --client-key=client.key --embed-certs=true
- 指定集群上下文名称
kubectl config set-context wsc --cluster=kubernetes --user=wsc
- 设置使用的上下文
kubectl config use-context wsc
- 然后需要给用户授权,创建一条角色绑定,注意这条最好使用集群的admin角色来执行,否则可能会失败
kubectl create clusterrolebinding root-cluster-admin-binding --clusterrole=cluster-admin --user=*.wsc.com
- 这样所有的配置都完成了
参考了https://www.cnblogs.com/wushc/p/15478800.html
- 接着我们启动goland,找到kube-apiserver启动文件,如下图
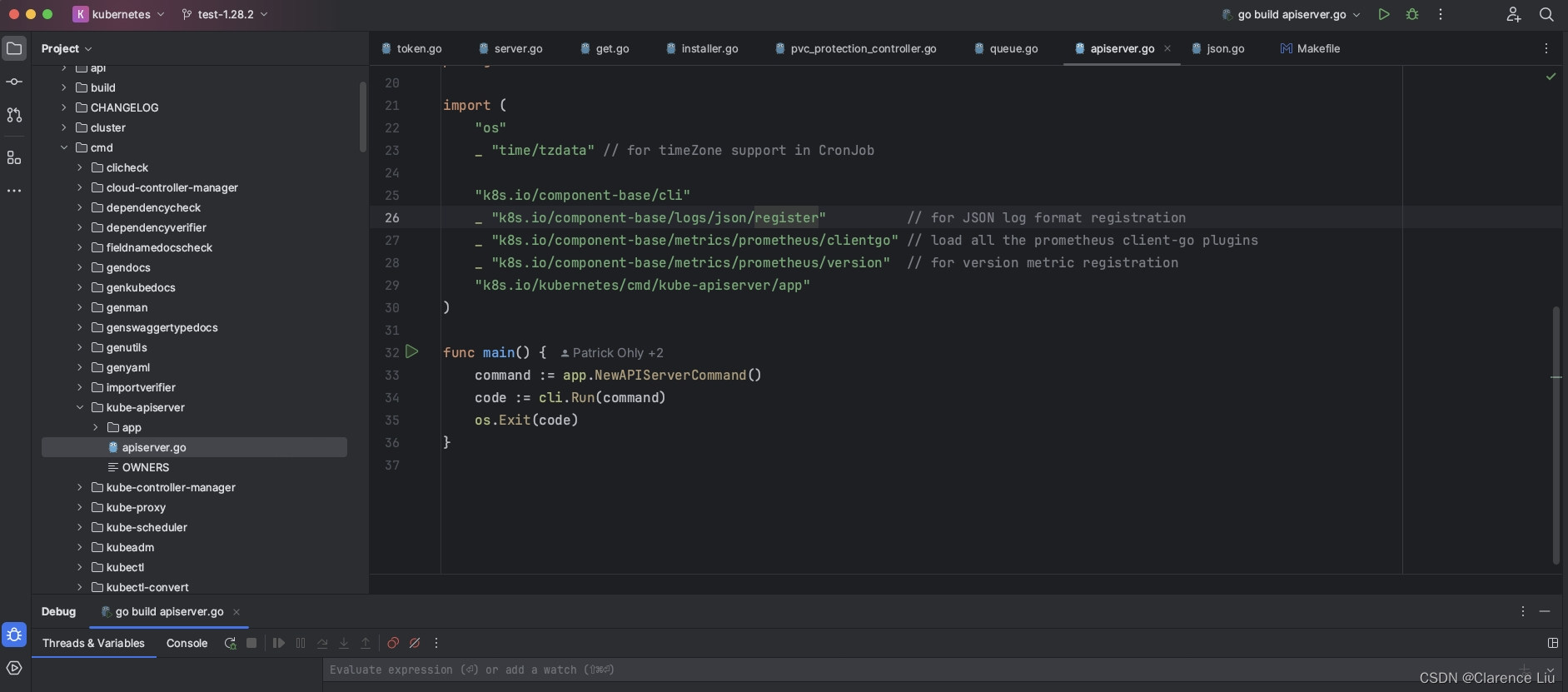
- 在下面这个位置把apiserver的启动参数写上
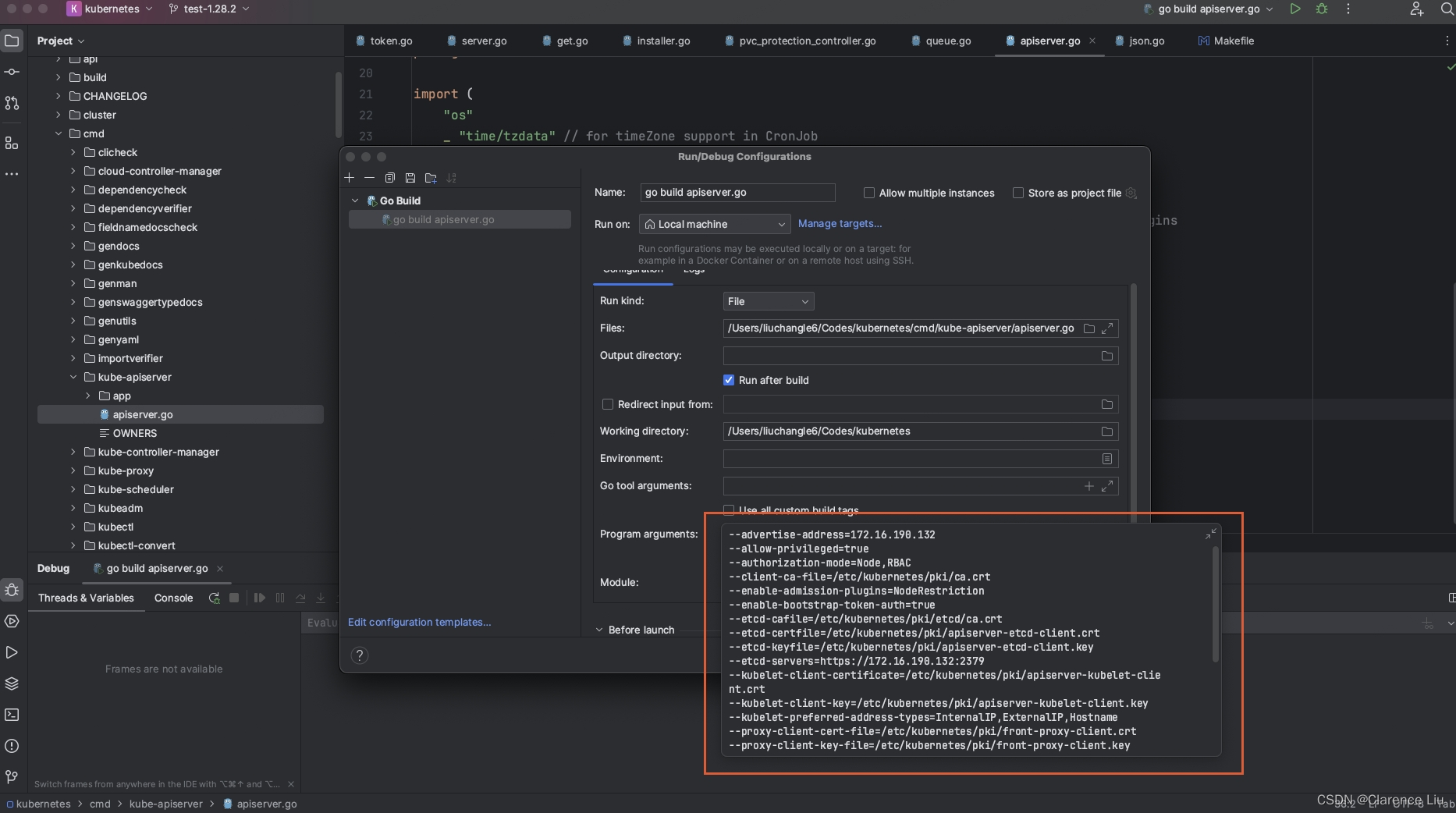
--advertise-address=172.16.190.132
--allow-privileged=true
--authorization-mode=Node,RBAC
--client-ca-file=/etc/kubernetes/pki/ca.crt
--enable-admission-plugins=NodeRestriction
--enable-bootstrap-token-auth=true
--etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
--etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
--etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
--etcd-servers=https://172.16.190.132:2379
--kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt
--kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key
--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key
--requestheader-allowed-names=front-proxy-client
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--secure-port=6443
--service-account-issuer=https://kubernetes.default.svc.cluster.local
--service-account-key-file=/etc/kubernetes/pki/sa.pub
--service-account-signing-key-file=/etc/kubernetes/pki/sa.key
--service-cluster-ip-range=10.96.0.0/12
--tls-cert-file=/etc/kubernetes/tmp/server.crt
--tls-private-key-file=/etc/kubernetes/tmp/server.key
- 注意最后两条要换成刚才生成的的server.crt和server.key文件的位置
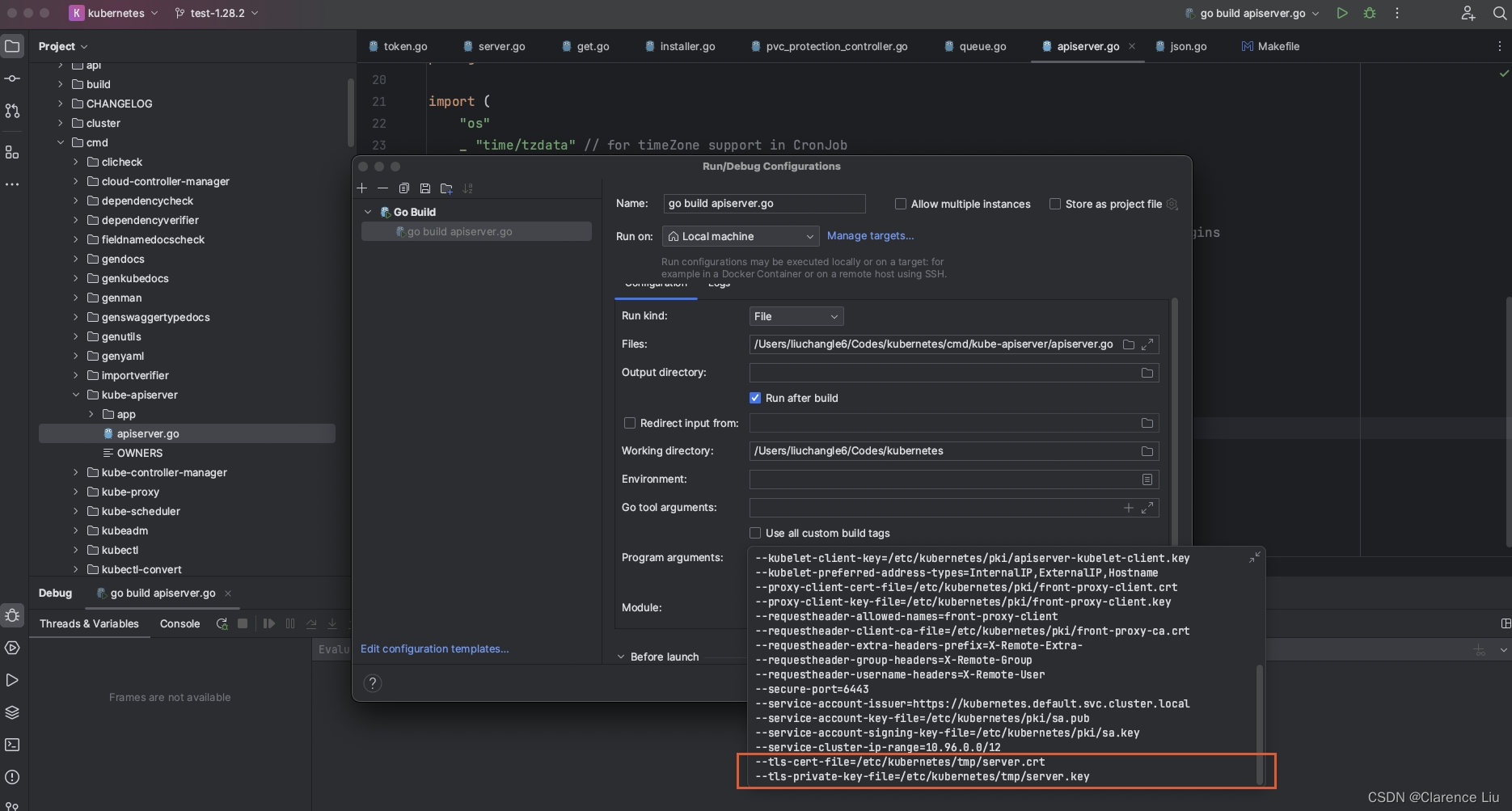
- 这样最终实现的效果如下图
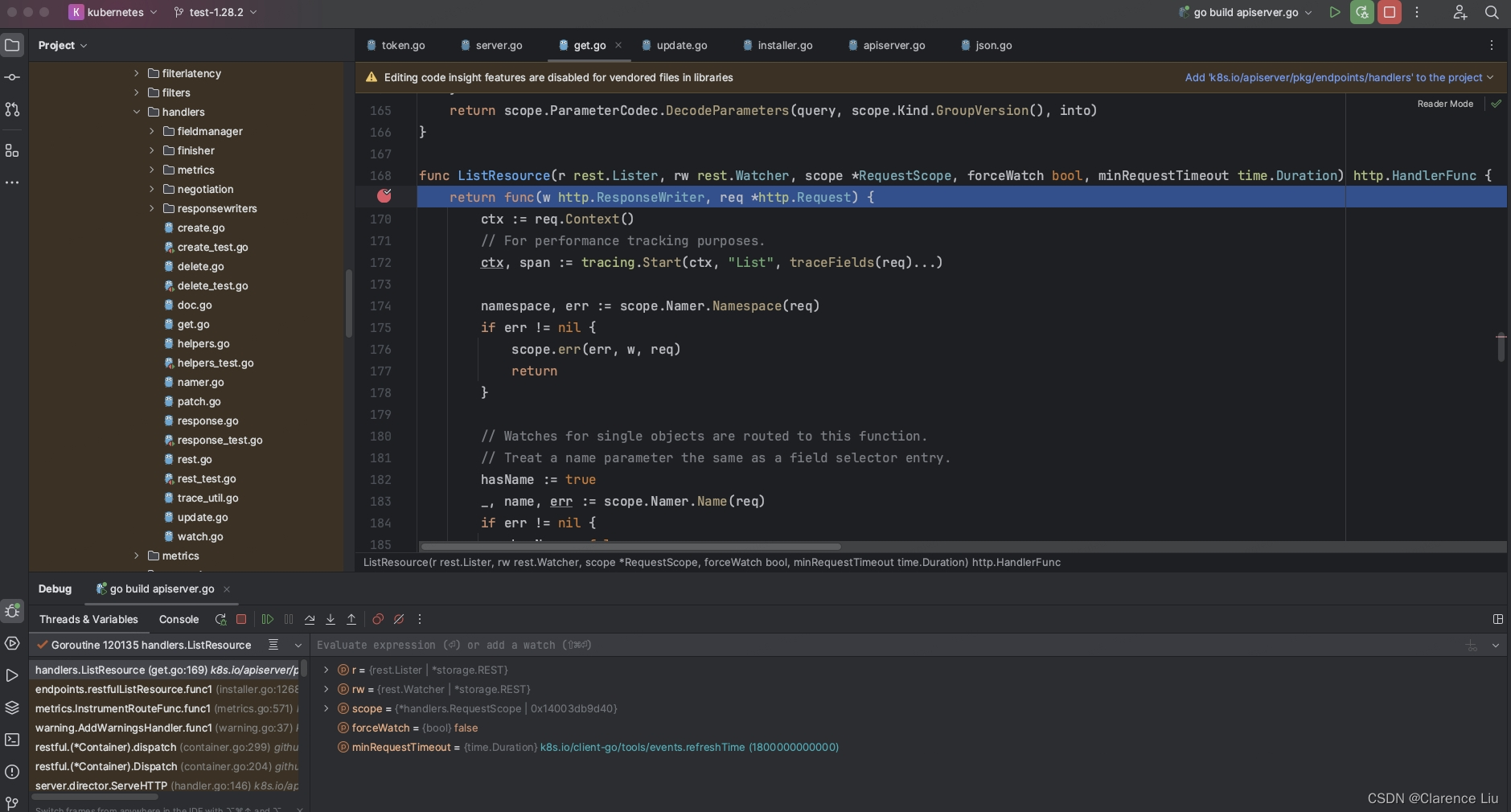

)
:Doris简单查询)
之buildroot配置软件包)
)

)




-什么是文件系统)







![[读论文]meshGPT](http://pic.xiahunao.cn/[读论文]meshGPT)