一、本文介绍
本文给大家带来的改进内容是AKConv(可变核卷积)是一种创新的卷积神经网络操作,它旨在解决标准卷积操作中的固有缺陷(采样形状是固定的),AKConv的核心思想在于它为卷积核提供了任意数量的参数和任意采样形状,能够使用任意数量的参数(如1, 2, 3, 4, 5, 6, 7等)来提取特征,这在标准卷积和可变形卷积中并未实现。AKConv能够根据硬件环境,使卷积参数的数量呈线性增减(非常适用于轻量化模型的读者)。本文通过先介绍AKConv的基本网络结构和原理让大家对该卷积有一个大概的了解,然后教大家如何将该卷积添加到自己的网络结构中。
(同时我修改了AKConv官方版本在训练到最后一个轮次报错和版本警告的问题RuntimeError: CUDA error: device-side assert triggered)
适用检测目标:所有的目标检测均有一定的提点(既轻量又提点)
推荐指数:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
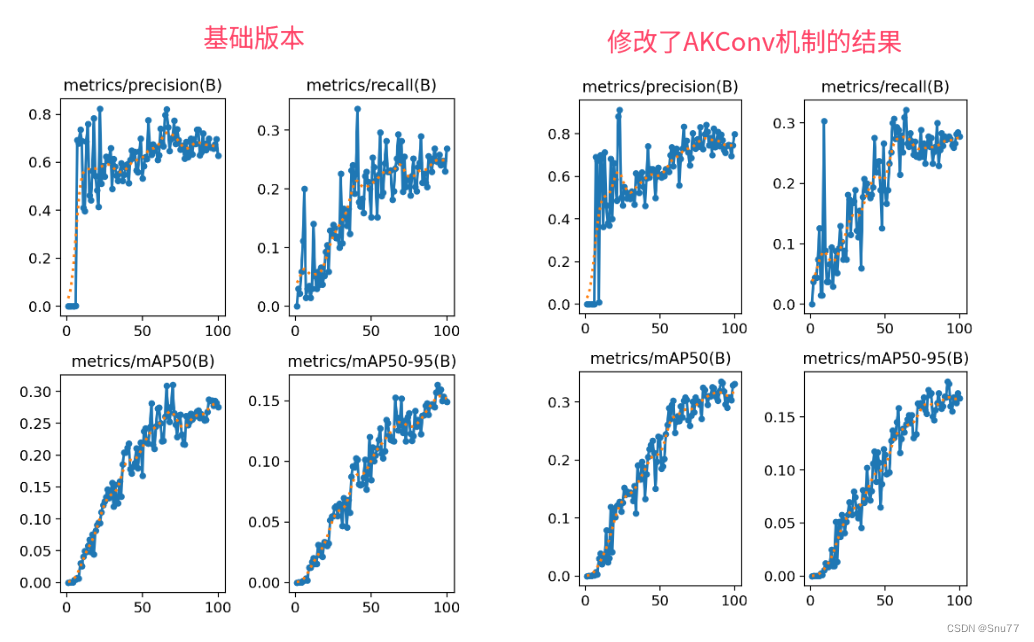
训练结果对比图->
因为资源有限我发的文章都要做对比实验所以本次实验我只用了一百张图片检测的是火灾训练了一百个epoch,该结果只能展示出该机制有效,但是并不能产生决定性结果,因为具体的效果还要看你的数据集和实验环境所影响
大家可以看出mAP(50)从0.288提高到了0.333(值得一提的是该卷积的GFLOPs降低了0.1左右适合轻量化的读者)

目录
一、本文介绍
二、AKConv网络结构讲解
2.1 AKConv的主要思想和改进
2.1.1 灵活的卷积核设计
2.1.2 初始采样坐标算法
2.1.3 适应性采样位置调整
2.1.4 线性增减卷积参数的数量
三、AKConv的代码
3.1 AKConv的核心代码
四、手把手教你添加AKConv
4.1 AKConv的添加教程
4.2 AKConv的yaml文件和训练截图
4.2.1 AKConv的yaml文件
4.2.2 AKConv的训练过程截图
五、AKConv可添加的位置
5.1 推荐AKConv可添加的位置
5.2 图示AKConv可添加的位置
六、本文总结
二、AKConv网络结构讲解

论文地址:官方论文地址
代码地址:官方代码地址

2.1 AKConv的主要思想和改进
AKConv的主要思想:AKConv(可变核卷积)主要提供一种灵活的卷积机制,允许卷积核具有任意数量的参数和采样形状。这种方法突破了传统卷积局限于固定局部窗口和固定采样形状的限制,从而使得卷积操作能够更加精准地适应不同数据集和不同位置的目标。
AKConv的改进点:
-
灵活的卷积核设计:AKConv允许卷积核具有任意数量的参数,这使得其可以根据实际需求调整大小和形状,从而更有效地适应目标的变化。
-
初始采样坐标算法:针对不同大小的卷积核,AKConv提出了一种新的算法来生成初始采样坐标,这进一步增强了其在处理各种尺寸目标时的灵活性。
-
适应性采样位置调整:为适应目标的不同变化,AKConv通过获得的偏移量调整不规则卷积核的采样位置,从而提高了特征提取的准确性。
-
减少模型参数和计算开销:AKConv支持线性增减卷积参数的数量,有助于在硬件环境中优化性能,尤其适合于轻量级模型的应用。
个人总结:总的来说,AKConv通过其创新的可变核卷积设计,为卷积神经网络带来了显著的性能提升。其能够根据不同的数据集和目标灵活调整卷积核的大小和形状,从而实现更高效的特征提取。
图片展示了AKConv结构的详细示意图,并附上我个人的过程理解:
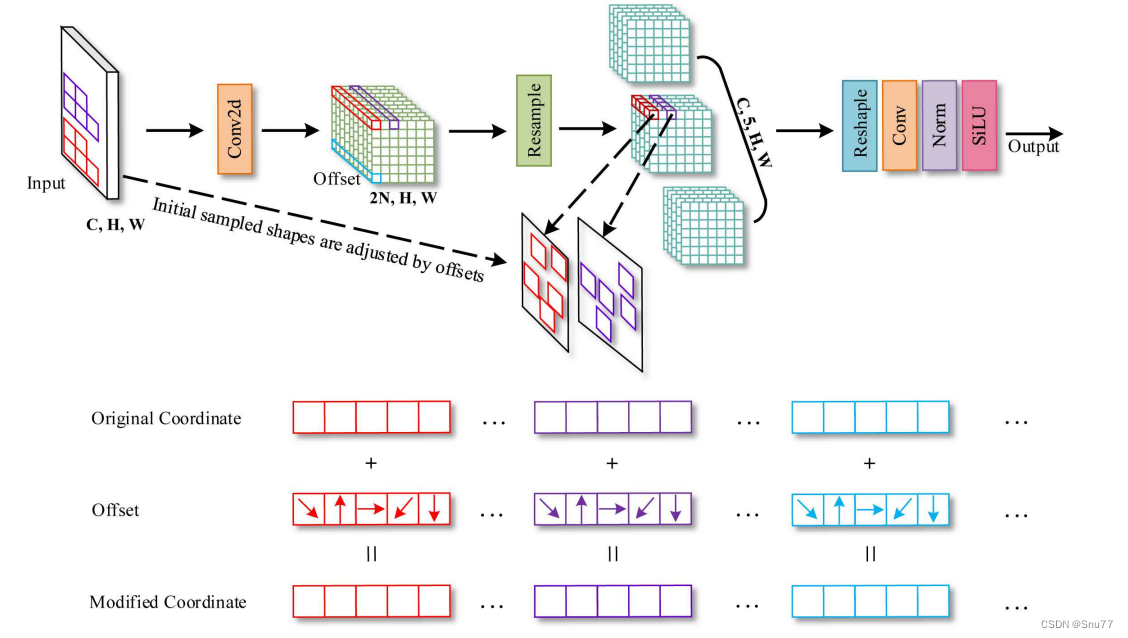
1. 输入:输入图像具有维度(C, H, W),其中C是通道数,H和W分别是图像的高度和宽度。
2. 初始采样形状:这一步是AKConv特有的,它给出了卷积核的初始采样形状。
3. 卷积操作:使用Conv2d对输入图像执行卷积操作。
4. 偏移:通过学习得到的偏移量来调整初始采样形状。这一步是AKConv的关键,允许卷积核形状动态调整以适应图像的特征。
5. 重采样:根据调整后的采样形状对特征图进行重采样。
6. 输出管道:重采样后的特征图经过重塑、再次卷积、标准化,最后通过激活函数SiLU输出最终结果。
底部的三行展示了采样坐标的变化:
- 原始坐标:显示了卷积核在没有任何偏移的情况下的初始采样位置。
- 偏移:展示了学习到的偏移量,这些偏移量将应用于原始坐标。
- 修改后的坐标:应用偏移后的采样坐标。
总结:官方这个图说明了AKConv如何为任意大小的卷积分配初始采样坐标,并通过可学习的偏移调整采样形状。与原始采样形状相比,每个位置的采样形状都通过重采样进行了改变,这使得AKConv可以根据图像内容动态调整其操作,为卷积网络提供了前所未有的灵活性和适应性。
2.1.1 灵活的卷积核设计
AKConv中的灵活卷积核设计是一种创新的机制,旨在使卷积网络更加适应性和有效率。以下是其主要原理和机制的总结:
主要原理
-
任意参数数量:传统的卷积核通常具有固定的尺寸和形状,例如3x3或5x5的方形网格。而AKConv的核心原理是允许卷积核具有任意数量的参数。这意味着卷积核不再局限于标准的方形网格,而是可以根据图像特征和任务需求,采用更多样化和灵活的形状(如下图所示,任意参数数量)。
-
自适应采样形状:在处理不同的图像和目标时,AKConv的卷积核能够自动调整其采样形状。这是通过引入一种新的坐标生成算法实现的,该算法能够为不同大小和形状的卷积核生成初始采样坐标(如下图所示,自适应采样形状)。
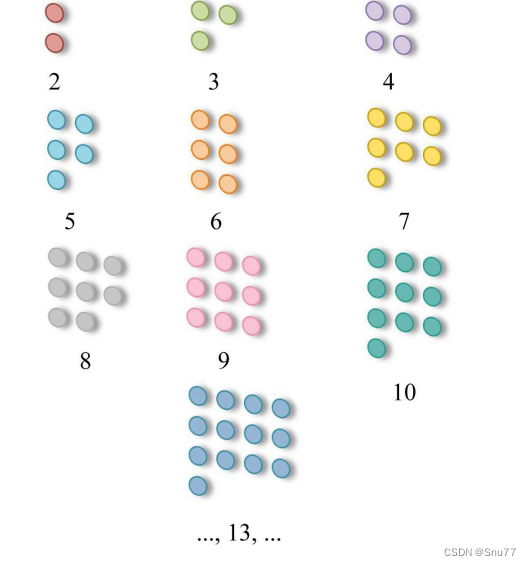
工作机制
-
初始坐标生成:AKConv首先通过其坐标生成算法确定卷积核的初始采样位置。这些位置不再是固定不变的,而是可以根据图像中的特征和目标动态变化。
-
采样位置调整:为了更好地适应图像中目标的大小和形状变化,AKConv会根据目标的特点调整卷积核的采样位置。这种调整是通过添加偏移量来实现的,使得卷积操作更加灵活和适应性强。
个人总结:通过这种灵活的设计,AKConv能够有效地适应各种大小和形状的目标,提高了特征提取的准确性和效率。它在标准卷积核基础上引入了更多的灵活性和自适应性,从而使得卷积神经网络在处理复杂和多样化的图像数据时更为高效。这种灵活的卷积核设计不仅提升了模型的性能,还为减少模型参数和计算开销提供了可能,特别是在轻量级模型的应用中显示出其优势。
2.1.2 初始采样坐标算法
AKConv中的初始采样坐标算法是其核心特征之一,这个算法为AKConv的灵活性和适应性提供了基础。以下是该算法的主要原理和机制的概述:
主要原理
-
针对多样化尺寸的适应性:传统卷积操作通常使用固定尺寸的卷积核,这限制了其在处理不同尺寸和形状目标时的效果。AKConv的初始采样坐标算法旨在解决这一问题,通过允许卷积核适应不同大小的目标,增强其灵活性和有效性。
-
动态采样坐标生成:该算法能够根据目标的尺寸和形状动态生成卷积核的初始采样坐标。这种动态生成方式使卷积核能够更精确地覆盖和处理图像中的不同区域,从而提高特征提取的精度。
工作机制
-
适应不同目标尺寸:对于每一个卷积操作,算法首先考虑目标的尺寸。基于这一信息,它生成一组初始坐标,这些坐标定义了卷积核将要采样的位置。
-
灵活的坐标调整:生成的初始坐标不是固定不变的,而是可以根据图像中的特征动态调整。这意味着卷积核可以根据图像内容的不同而改变其采样策略,从而更有效地提取特征。
个人总结:通过引入这种初始采样坐标算法,AKConv能够更灵活地处理各种尺寸的目标,无论是大尺寸还是小尺寸的目标,都能得到更准确的特征提取。
2.1.3 适应性采样位置调整
AKConv的适应性采样位置调整机制是其核心之一,该机制允许卷积核基于图像内容进行动态调整。这里是对这一机制的概述:
-
动态采样调整:传统的卷积网络使用固定形状的卷积核在图像上滑动来提取特征,这种方法忽略了图像中对象形状和尺寸的多样性。AKConv采用一种新颖的方法,它允许卷积核的形状和位置根据图像内容动态调整,更好地匹配和覆盖目标区域。
-
偏移量学习:在AKConv中,卷积核的位置可以通过学习到的偏移量来调整。在训练过程中,网络学习到对于特定图像和目标最有效的偏移量,以便在采样过程中自动调整卷积核的位置。
-
提高特征提取准确性:通过这种自适应调整,AKConv能够更准确地对齐并提取图像中的关键特征,特别是当目标的形状和大小在不同图像中有所变化时。

个人总结:AKConv的适应性采样位置调整为卷积网络提供了前所未有的灵活性和适应性,使其能够对各种不同形状和尺寸的目标实现更精确的特征提取。
2.1.4 线性增减卷积参数的数量
AKConv通过其独特的设计减少了模型参数和计算开销实现方式如下:
1. 线性参数调整:AKConv允许卷积核的参数数量根据需要进行线性调整。这与传统卷积网络中参数数量随着卷积核尺寸平方级增长的情况形成对比。通过支持参数数量的线性调整,AKConv能够根据任务需求和硬件能力灵活地增减模型的复杂度。
2. 优化性能:在硬件资源有限的环境中,AKConv能够通过减少不必要的参数来优化性能。这样不仅减轻了对存储和计算资源的需求,还有助于加快模型的训练和推理速度,同时降低能耗。
3. 轻量级模型设计:AKConv特别适合于轻量级模型的设计,这类模型需要在保持高性能的同时,尽可能地减少参数数量。AKConv的这一特性使其成为设计紧凑而高效模型的理想选择,特别是在移动设备、嵌入式系统和物联网设备等资源受限的平台上。
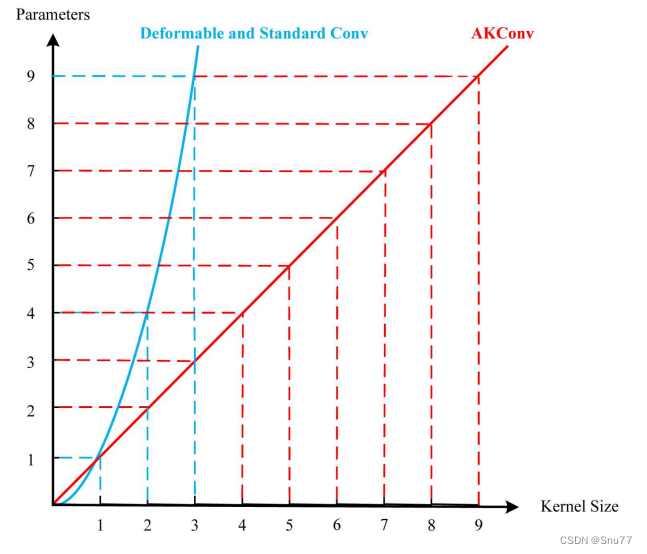
总结:AKConv通过支持卷积参数的线性增减,提供了一种在不牺牲性能的前提下,降低模型参数和计算开销的有效方法。这使得AKConv不仅在实现高精度的特征提取方面表现出色,而且在实际应用中具有显著的资源效率优势。
三、AKConv的代码
3.1 AKConv的核心代码
在AKConv的官方代码中有一个版本的警告我给进行了一定的处理解决了,该代码的使用方式我们看章节四进行使用。
(同时我修改了AKConv官方版本在训练到最后一个轮次报错和版本警告的问题RuntimeError: CUDA error: device-side assert triggered)
import torch.nn as nn
import torch
from einops import rearrange
import mathclass AKConv(nn.Module):def __init__(self, inc, outc, num_param, stride=1, bias=None):super(AKConv, self).__init__()self.num_param = num_paramself.stride = strideself.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),nn.BatchNorm2d(outc),nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.p_conv.weight, 0)self.p_conv.register_full_backward_hook(self._set_lr)@staticmethoddef _set_lr(module, grad_input, grad_output):grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))def forward(self, x):# N is num_param.offset = self.p_conv(x)dtype = offset.data.type()N = offset.size(1) // 2# (b, 2N, h, w)p = self._get_p(offset, dtype)# (b, h, w, 2N)p = p.contiguous().permute(0, 2, 3, 1)q_lt = p.detach().floor()q_rb = q_lt + 1q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)# clip pp = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)# bilinear kernel (b, h, w, N)g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))# resampling the features based on the modified coordinates.x_q_lt = self._get_x_q(x, q_lt, N)x_q_rb = self._get_x_q(x, q_rb, N)x_q_lb = self._get_x_q(x, q_lb, N)x_q_rt = self._get_x_q(x, q_rt, N)# bilinearx_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \g_rb.unsqueeze(dim=1) * x_q_rb + \g_lb.unsqueeze(dim=1) * x_q_lb + \g_rt.unsqueeze(dim=1) * x_q_rtx_offset = self._reshape_x_offset(x_offset, self.num_param)out = self.conv(x_offset)return out# generating the inital sampled shapes for the AKConv with different sizes.def _get_p_n(self, N, dtype):base_int = round(math.sqrt(self.num_param))row_number = self.num_param // base_intmod_number = self.num_param % base_intp_n_x, p_n_y = torch.meshgrid(torch.arange(0, row_number),torch.arange(0, base_int), indexing='xy')p_n_x = torch.flatten(p_n_x)p_n_y = torch.flatten(p_n_y)if mod_number > 0:mod_p_n_x, mod_p_n_y = torch.meshgrid(torch.arange(row_number, row_number + 1),torch.arange(0, mod_number),indexing='xy')mod_p_n_x = torch.flatten(mod_p_n_x)mod_p_n_y = torch.flatten(mod_p_n_y)p_n_x, p_n_y = torch.cat((p_n_x, mod_p_n_x)), torch.cat((p_n_y, mod_p_n_y))p_n = torch.cat([p_n_x, p_n_y], 0)p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)return p_n# no zero-paddingdef _get_p_0(self, h, w, N, dtype):p_0_x, p_0_y = torch.meshgrid(torch.arange(0, h * self.stride, self.stride),torch.arange(0, w * self.stride, self.stride),indexing='xy')p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)return p_0def _get_p(self, offset, dtype):N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)# (1, 2N, 1, 1)p_n = self._get_p_n(N, dtype)# (1, 2N, h, w)p_0 = self._get_p_0(h, w, N, dtype)p = p_0 + p_n + offsetreturn pdef _get_x_q(self, x, q, N):b, h, w, _ = q.size()padded_w = x.size(3)c = x.size(1)# (b, c, h*w)x = x.contiguous().view(b, c, -1)# (b, h, w, N)index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y# (b, c, h*w*N)index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)# 根据实际情况调整index = index.clamp(min=0, max=x.shape[-1] - 1)x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)return x_offset# Stacking resampled features in the row direction.@staticmethoddef _reshape_x_offset(x_offset, num_param):b, c, h, w, n = x_offset.size()# using Conv3d# x_offset = x_offset.permute(0,1,4,2,3), then Conv3d(c,c_out, kernel_size =(num_param,1,1),stride=(num_param,1,1),bias= False)# using 1 × 1 Conv# x_offset = x_offset.permute(0,1,4,2,3), then, x_offset.view(b,c×num_param,h,w) finally, Conv2d(c×num_param,c_out, kernel_size =1,stride=1,bias= False)# using the column conv as follow, then, Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')return x_offset
四、手把手教你添加AKConv
4.1 AKConv的添加教程
添加教程这里不再重复介绍、因为专栏内容有许多,添加过程又需要截特别图片会导致文章大家读者也不通顺如果你已经会添加注意力机制了,可以跳过本章节,如果你还不会,大家可以看我下面的文章,里面详细的介绍了拿到一个任意机制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的网络结构中去。
这个卷积也可以放在C2f和Bottleneck中进行使用可以即插即用,个人觉得放在Bottleneck中效果比较好。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
4.2 AKConv的yaml文件和训练截图
4.2.1 AKConv的yaml文件
下面的配置文件为我修改的AKConv的位置。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, AKConv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, AKConv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, AKConv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, AKConv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, AKConv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, AKConv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
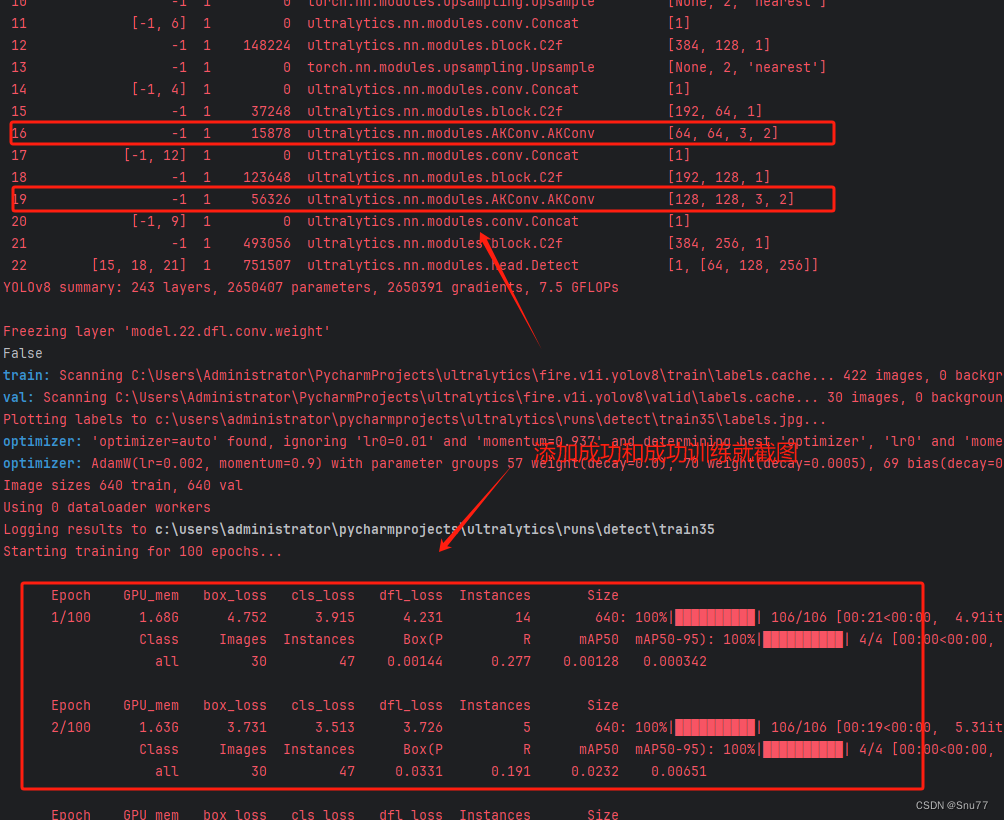
4.2.2 AKConv的训练过程截图
下面是添加了AKConv的训练截图。
(最近有人说我改的代码是没有发全的,我不知道这群人是怎么说出这种话的,希望大家如果用我的代码成功的可以在评论区支持一下,我也好发更多的改进毕竟免费给大家看。同时有问题皆可在评论区留言我看到都会回复)
五、AKConv可添加的位置
5.1 推荐AKConv可添加的位置
AKConv是一种即插即用的模块,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入AKConv
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加修改后的AKConv可以帮助模型更有效地融合不同层次的特征。
检测头中的卷积:在最终的输出层前加入AKConv可以使模型在做出最终预测之前,更加集中注意力于最关键的特征。
文字大家可能看我描述不太懂,大家可以看下面的网络结构图中我进行了标注。
5.2 图示AKConv可添加的位置
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备




:)



)








![[Android] c++ 通过 JNI 调用 JAVA函数](http://pic.xiahunao.cn/[Android] c++ 通过 JNI 调用 JAVA函数)
详解)

