The Power of Prompting:提示的力量,仅通过提示,GPT-4可以被引导成为多个领域的特定专家。
微软研究院发布了一项研究,展示了在仅使用提策略的情况下让GPT 4在医学基准测试中表现得像一个专家。
研究显示,GPT-4在相同的基准测试中超越了专门为医学应用微调的领先模型Med-PaLM 2,并且优势显著。
研究表明,仅通过提示策略就可以有效地从通用基础模型中引发特定领域的专业知识。
以前,要想激发这些能力,需要使用特别策划的数据对语言模型进行微调,以在特定领域中达到最佳性能。
现在仅通过提示,GPT-4可以被引导成为多个领域的特定专家。
Medprompt不仅在医学领域取得了显著进步,还在电气工程、机器学习、哲学、会计、法律、护理和临床心理学等领域的评估中展现了其通用性。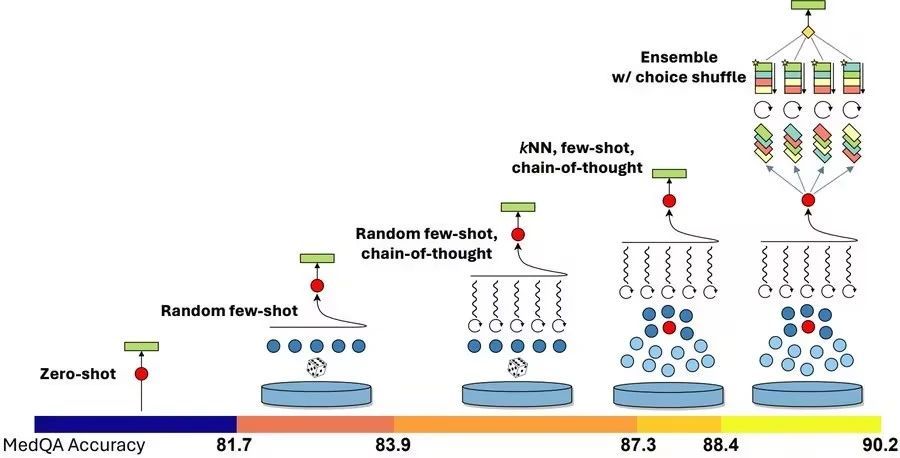 研究的方法:Medprompt策略:研究中提出了一种名为“Medpromcpt”的方法,它结合了几种不同的提示策略来引导GPT-4。
研究的方法:Medprompt策略:研究中提出了一种名为“Medpromcpt”的方法,它结合了几种不同的提示策略来引导GPT-4。
Medprompt使用了三种主要技术:动态少量样本选择、自动生成的思维链(Chain of Thought,CoT)和选择重排集成(Choice Shuffle Ensembling)。
Medprompt 方法包括以下几个关键方面:
1、多样化提示:Medprompt 使用了多种不同类型的提示,以提高模型在医学领域问题上的表现。这些提示可能包括问题的不同表述、相关的背景信息、专业术语的解释等。
2、上下文学习:为了让模型更好地理解医学领域的特定上下文,Medprompt 使用了上下文学习技术。这意味着在给定的问题前后添加相关的信息,以帮助模型建立起更加全面的理解。
3、思维链条方法:这种方法鼓励模型在做出回答之前模拟一系列的思考步骤,类似于专业医生在诊断问题时的思维过程。这可以帮助模型更准确地识别关键信息并提出更合理的答案。
4、选择洗牌集成:这是一种提高模型表现的技术,它通过结合多个不同提示生成的回答来提高整体的准确性。通过这种方式,即使某些提示没有产生最佳答案,其他提示可能仍然能够提供有价值的信息。
5、跨数据集应用:Medprompt 被设计为可在多个不同的医学数据集上有效运作,从而增加了其适用性和灵活性。
这一方法的成功展示了利用创新的提示技术可以显著提升基础模型在专业领域的能力,从而为解决复杂问题提供了新的途径。基准测试这些技术被组合应用于不同的数据集,包括MedQA、MedMCQA、PubMedQA和MMLU的多个子集。在一项名为MedQA的研究中,使用Medprompt的GPT-4在没有集成的情况下,仅通过自动生成的CoT提示就比专家制作的CoT提示提高了3.1个百分点。
研究使用了MedQA数据集和MultiMedQA套件中的九个基准数据集来测试GPT-4在医学领域的表现。
通过这些测试,研究人员评估了GPT-4在医学知识方面的表现,并与专门为医学应用微调的模型进行了比较。
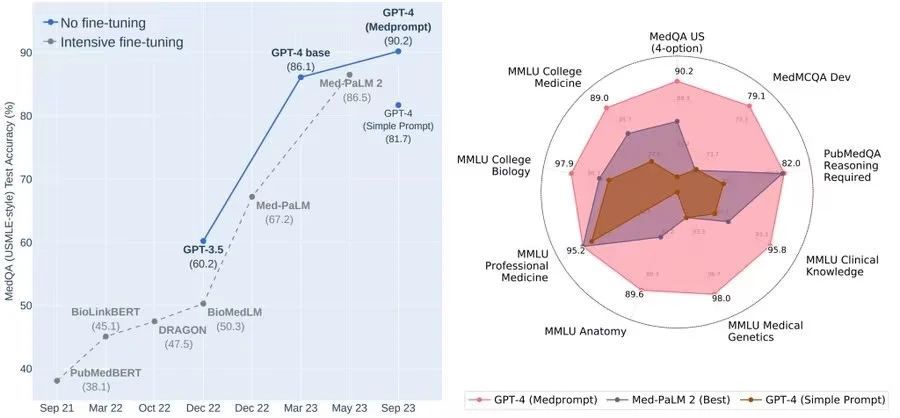
性能评估研究结果显示,使用 Medprompt 的GPT-4
- 在MedQA数据集上的表现首次超过90%
- 在MultiMedQA套件的所有九个基准数据集上取得了最佳报告结果。
- 在MedQA上,与MedPaLM 2相比,GPT-4的错误率降低了27%。
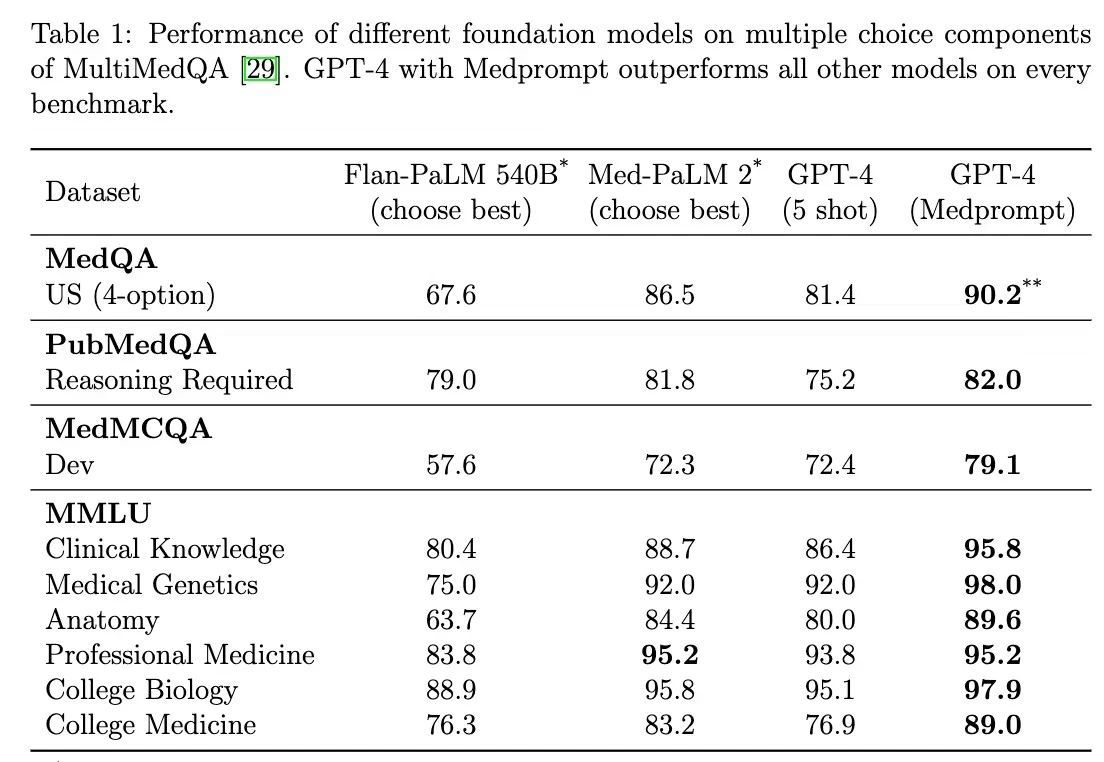
Medprompt在多项基准测试中表现卓越,不仅在医学领域取得了显著进步,还在电气工程、机器学习、哲学、会计、法律、护理和临床心理学等领域的评估中展现了其通用性。
此外,研究也进行了消融研究(Ablation Study),以评估Medprompt各组成部分的贡献度,并发现GPT-4自动生成的CoT、动态少量样本提示和选择重排集成分别对性能的提升有显著贡献。研究的意义
1、展示通用模型的领域专业性:这项研究证明了通用模型如GPT-4能够在没有特定领域微调的情况下,通过提示策略在特定领域(如医学)展现出专家级的能力。
这对于自然语言处理(NLP)领域是一个重要的进步,因为它表明通用模型可以通过适当的提示策略而不是通过昂贵的专门训练来适应特定的应用场景。
2、减少资源和成本:传统上,要使模型在特定领域表现出色,需要对其进行专门的微调,这通常涉及到使用专家标注的数据集和大量的计算资源。通过有效的提示策略,可以减少这种需求,从而为中小型组织提供了使用高级AI技术的可能性。
3、跨领域的应用潜力:研究还表明,这种提示方法在多个领域的专业能力考试中都显示出价值,这意味着其应用潜力不限于单一领域。
官方介绍:https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/论文:https://arxiv.org/abs/2311.16452






:抽象工厂——Abstract Factory)


——支持向量机(升维打击))







——图片像素访问与多种局部放大效果的实现代码)

