题目
试题编号: 201809-3
试题名称: 元素选择器
时间限制: 1.0s
内存限制: 256.0MB
问题描述:



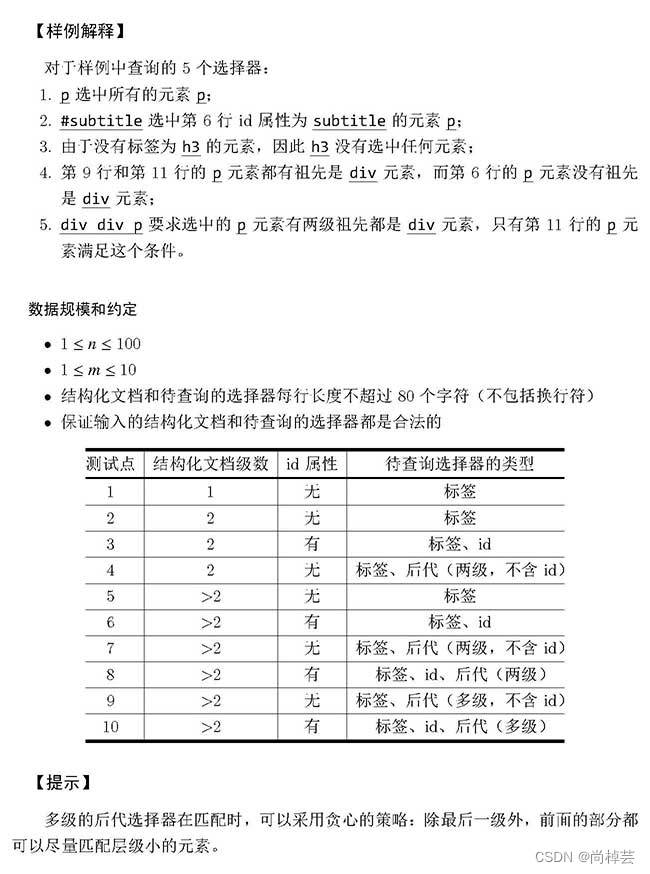
题目分析(个人理解)
- 还是先理解题意,关于html的部分,可以按照样例画出树状图(html数据结构类似树,画图更清楚的明白子类父类的关系)。两个点就是第一层级,四个点就是第二层级,依次类推。
- 如图所示,框起来的就是后代选择器,查找要做的就是返回他们在html文档的行号。
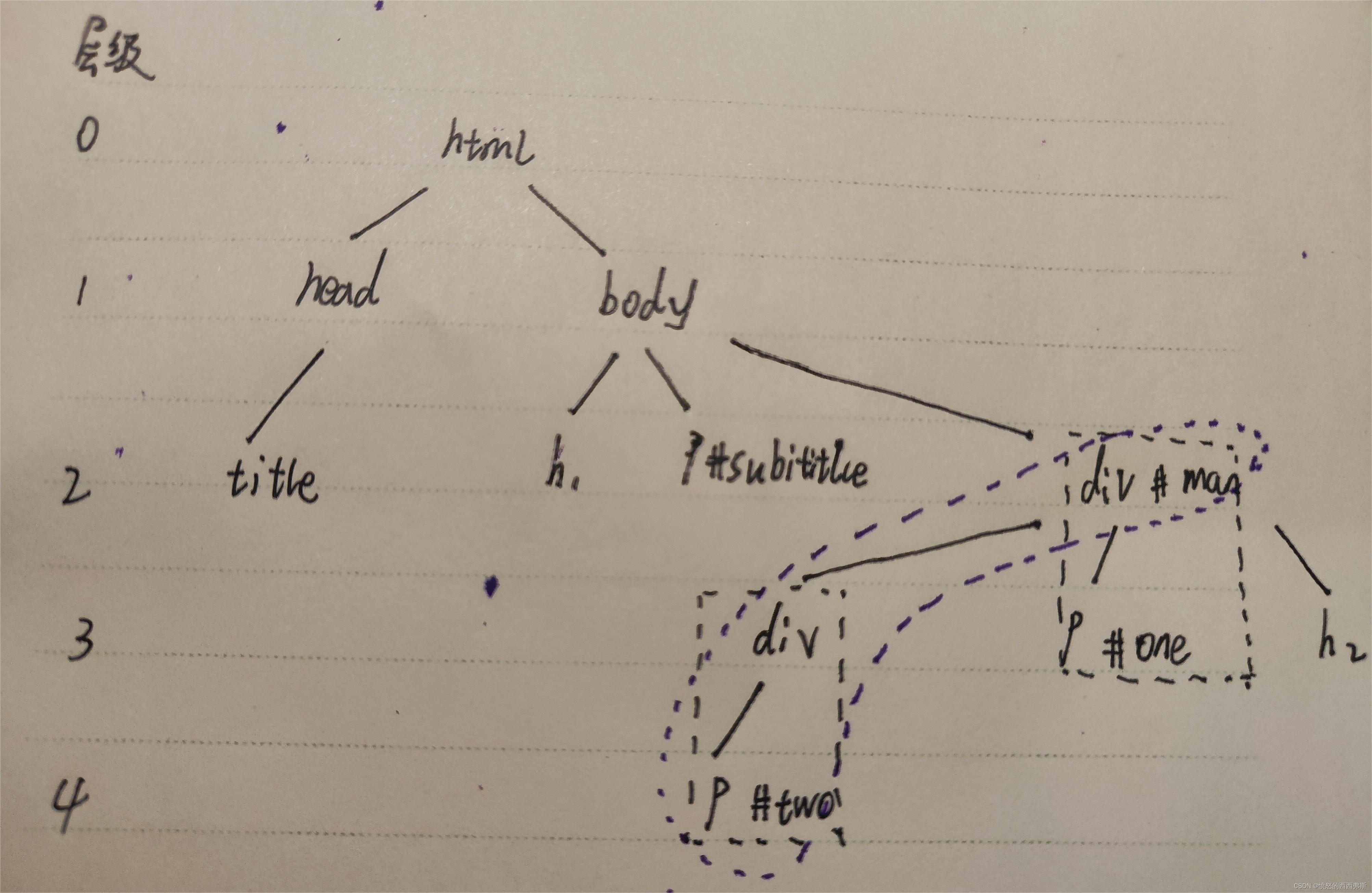
- 对于html的内容无非是查找时的选择器的种类不同,对于查找有三种情况:(1)单个标签选择器(2)单个id选择器(3)对于此题理解的有难度的地方在于出现后代选择器的情况,迭代选择器出现的情况有两种,第一种多个标签选择器,第二种多个ID选择器。
- 做此类模拟题要根据输出选择输入内容的容器类型,(本人🌨️的教训)此题最后返回的是行数,又因为要判断标签还是id还是后代选择器还要判断父子关系,因此在存入html文档的内容时采用字典存储。存储每一行html文档的层级,标签和id选择器内容。对于查询语句的存储还是选择列表,利用split方法切分字符串,再用append方法追加写入即可。
- 下面进行判断,到底是查找的哪种情况,很容易,如果查询语句的长度是1则是ID或标签选择器;否则就是后代选择器。
- 之后利用函数分别实现三种选择器的方法,进入的参数是查询的语句,返回值是满足条件的行号。后面的代码注释写的非常清楚了,我就不多赘述。
- 上代码!!!
def Level(String):#此函数将实现存储html文档每一行的内容;并且以字典的形式返回缩进层级,标签和IDfor i in range(len(String)):if String[i] != '.':#统计表示缩进的符号breaklevel = i // 2#计算当前缩进label = ''#存储标签ID = ''#存储IDif len(String[i:].split()) == 1:#只有一个选择器label = String[i:]#写入else:#后代迭选择器label, ID = String[i:].split()#写入return {'level': level,'label': label, 'id': ID}row, test = map(int, input().split())#输入html总行号和测试数量
html = [None] # 存放html文档全部内容,位序表示行号;由于从一开始,列表位序从0开始所以,0号位用None占位html[]内的元素表示{'level': level,'label': label, 'id': ID}
#print(html)
for i in range(row):#输入html.append(Level(input()))#直接进入函数判断,注意返回的是字典
search = []#存放查询的操作
for i in range(test):search.append(list(input().split()))#存放到对应列表def LabelOrId(String):#判断是哪种选择器,ID还是标签temp = [0]#设置选择器个数初始值for i in range(1, len(html)):#遍历整个html文件的结构if String.lower() == html[i]['label'].lower() or String == html[i]['id']:#判断查询的标签是否在输入的html文档中;如果存在temp[0] += 1#temp[0]表示有几个选择器(IDorLabel)temp[1]表示行号;也就是temp[]存储的是每一行选择器的个数temp.append(i)return tempdef ParentRow(row):#利用缩进关系确定html文档的父子关系if row == 0:#html文档没内容return 0else:#有内容level = html[row]['level']#返回html文档最高缩进层数for i in range(row, 0, -1): # html第0位为Noneif html[i]['level'] == level - 1:#只相差一层则存在父节点;注意存在爷爷父亲儿子的情况(三级或更多)return i#返回父节点行号return 0 # 不存在父节点def Descendant(List):#后迭代选择器;参数是search[]row = []#存放合法的,满足条件的行数、行号(输出的内容)temp_answer = LabelOrId(List[-1])#前面都是相同的ID选择器或者元素选择器;返回的是最后一个选择器的行号for i in range(temp_answer[0]):#遍历html文档flag = []#利用此列表判断合法性son_row = temp_answer[i + 1]#返回子节点行号;family_row = [son_row]#把最小层级子节点行号存入family_row[]while True:parent_row = ParentRow(son_row)#返回存在子节点的行号if parent_row == 0:#没有子节点breakelse:family_row.append(parent_row)#把存在子节点的行号存入family_row[]son_row = parent_row#更新子节点行号family_row.reverse()#翻转;此时family_row[]的元素是从小到大的子节点行号j, k = 0, 0#j记录查询个数,k记录子节点个数while k < len(family_row):if List[j].lower() == html[family_row[k]]['label'].lower() or List[j] == html[family_row[k]]['id']:#判断输入合法性flag.append(True)k += 1j += 1if j >= len(List): breakelse:k += 1if flag == [True] * len(List):#全部合法row.append(temp_answer[i + 1])#返回子节点的行号l = len(row)row.insert(0, l)#等价于row[0]记录row的长度return rowresult = []
for i in range(test):if len(search[i]) == 1:#长度为一不存在迭代answer = LabelOrId(search[i][0]) # 标签和ID选择器result.append(answer)else:#迭代answer = Descendant(search[i]) # 后代选择器result.append(answer)for i in range(len(result)):#按照格式输出print(' '.join(map(str, result[i])))# 测试样例
'''
11 5
html
..head
....title
..body
....h1
....p #subtitle
....div #main
......h2
......p #one
......div
........p #two
p
#subtitle
h3
div p
div div p
'''总结
Joker!

,从设计架构说起)









 |字体加密通杀方案)

)


)



