1、Scrapy框架初识(点击前往查阅)
2、Scrapy框架持久化存储(点击前往查阅)
3、Scrapy框架内置管道(点击前往查阅)
4、Scrapy框架中间件

Scrapy 是一个开源的、基于Python的爬虫框架,它提供了强大而灵活的工具,用于快速、高效地提取信息。Scrapy包含了自动处理请求、处理Cookies、自动跟踪链接、下载中间件等功能
Scrapy框架的架构图(今天的中间件看完,回头来看下) 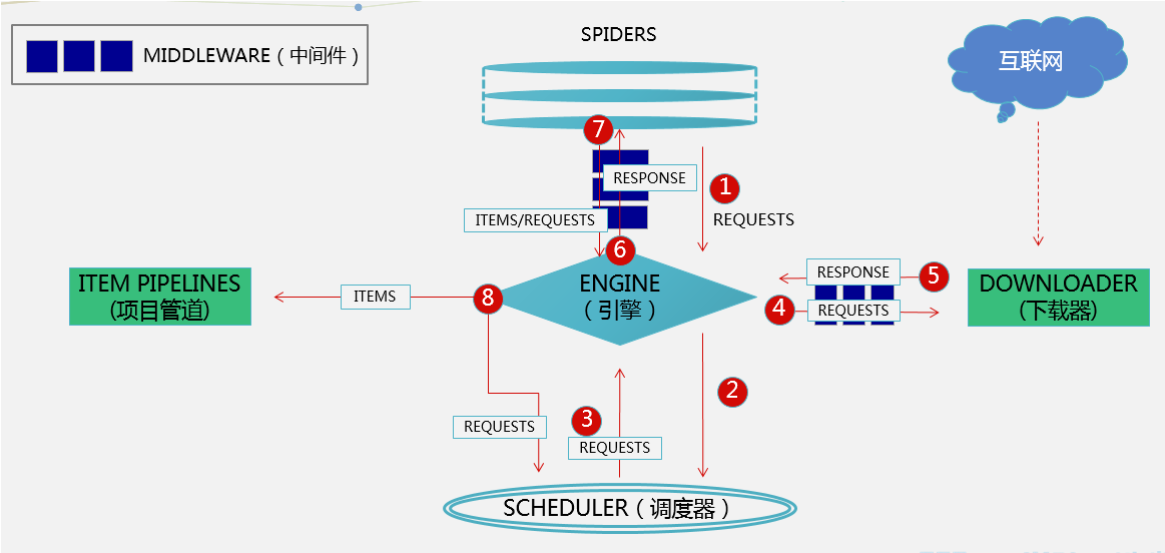
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
什么是中间件?
-
Scrapy的中间件有两个:
-
爬虫中间件(一般不会去用,就不多赘述了)
-
下载中间件
-
-
中间件在五大核心组件的什么位置:
-
下载中间件位于引擎和下载器之间。
-
引擎会给下载器传递请求对象,下载器会给引擎返回响应对象。
-
-
根据位置了解中间件的作用:
-
可以拦截到scrapy框架中所有的请求和响应。
-
拦截请求干什么?
-
修改请求的ip,修改请求的头信息,设置请求的cookie。
-
-
拦截响应干什么?
-
可以修改响应数据。
-
-
-
一、中间件的应用
前置 settings 设置:(需要开启中间件)
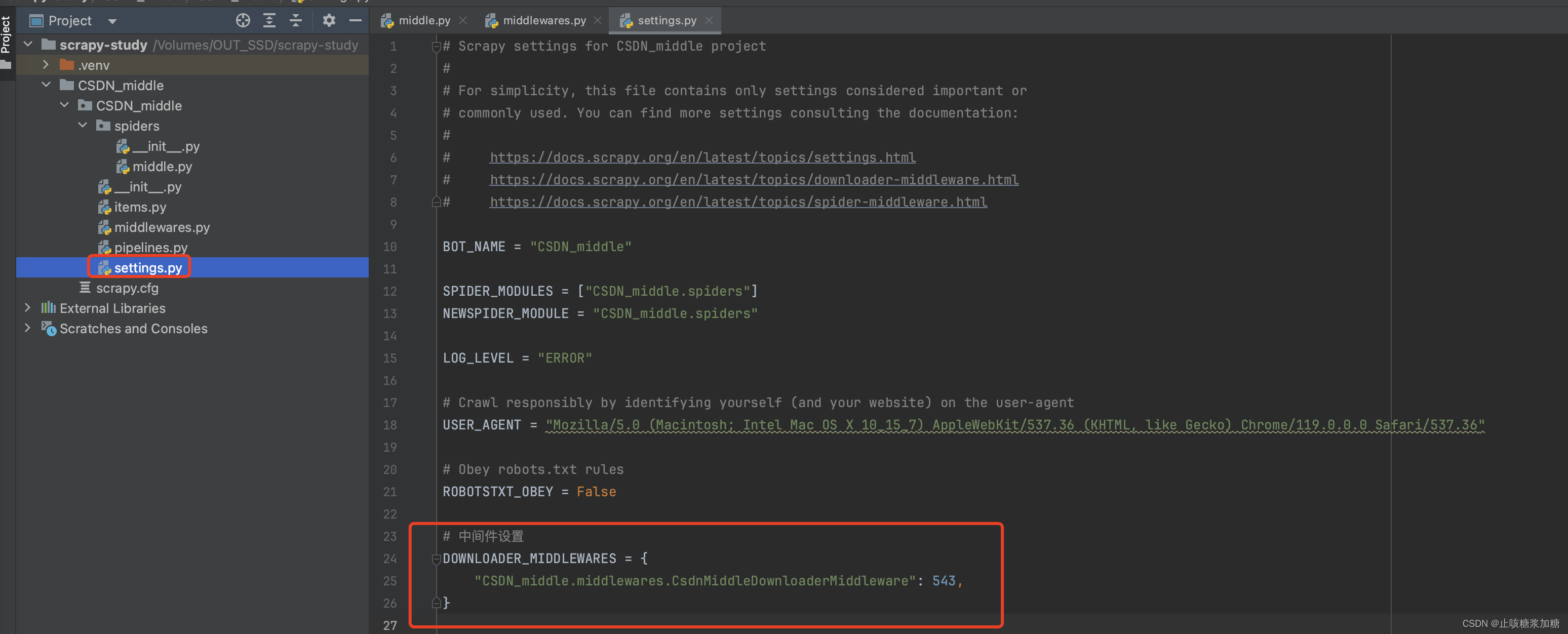
1:中间件的介绍
- 这就是2个中间件,其中 爬虫中间件 很少用到,为了简介明了,我们给他删除或者注释掉就行了。
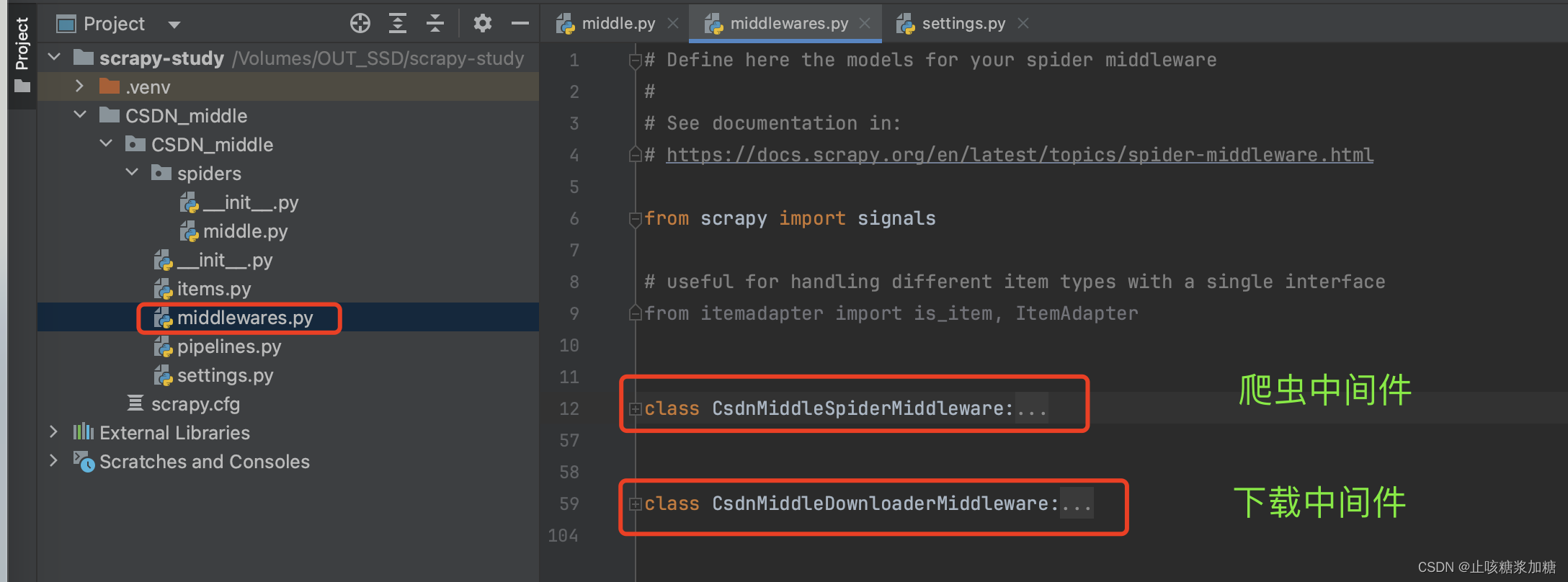
- 下载中间件图片中的2个也用不到啥,就删除即可了

- 精简完的代码,也就是我们需要改写的与操作的(主要参数作用介绍)。
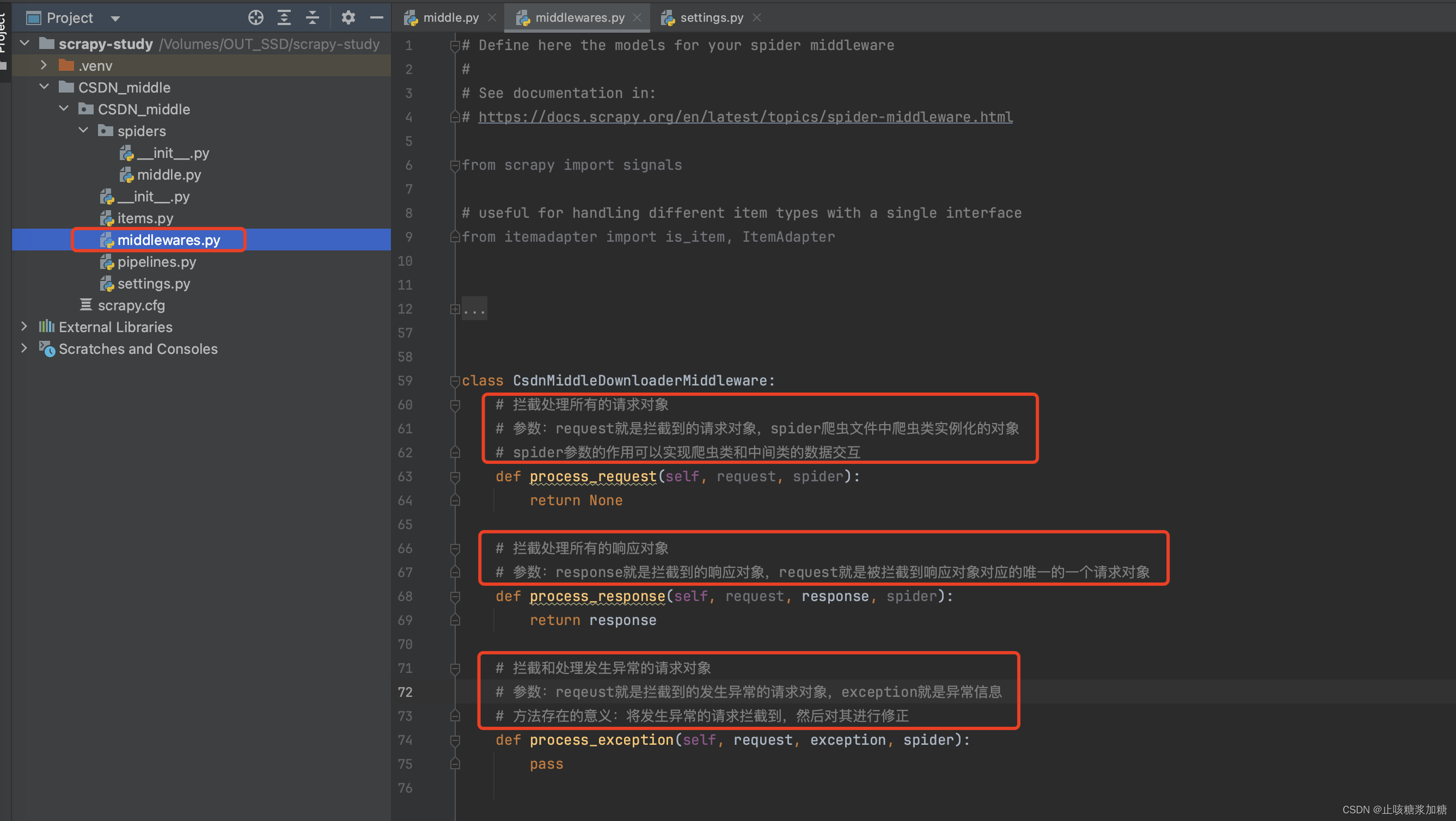
1.1:中间件的运行顺序
下图可知:
- 先执行 process_request :发起的请求先经过该函数。
- 然后执行 process_respons :返回的数据先经过该函数。
- 最后才会获取到:返回的响应数据。
process_exception 函数,为啥没执行???
答:因为没报错,process_exception函数 只有在报错才会触发(图二)。

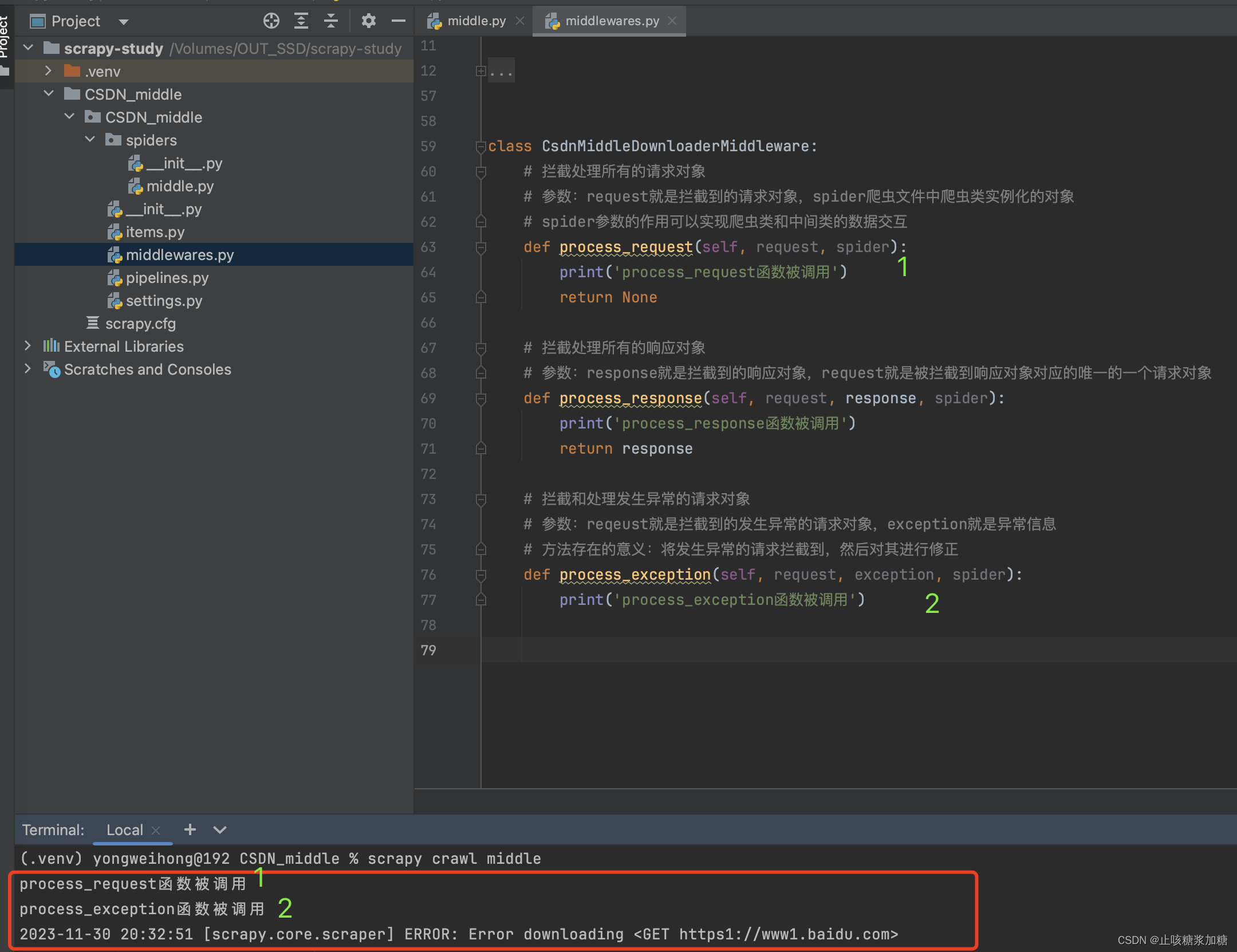
So :当我们知道了这个,那可操作的空间就很大了。
例如:
- 在 process_request 函数中:我们可以设置 UA请求头、Cookie、代理等其他请求头。
- 在 process_response 函数中:我们可以修改响应回来的数据。
- 在 process_exception 函数中:我们可以获取错误,并修改错误,重新发起请求(修改错误这个难度太大了,知道有这个功能就行了。)
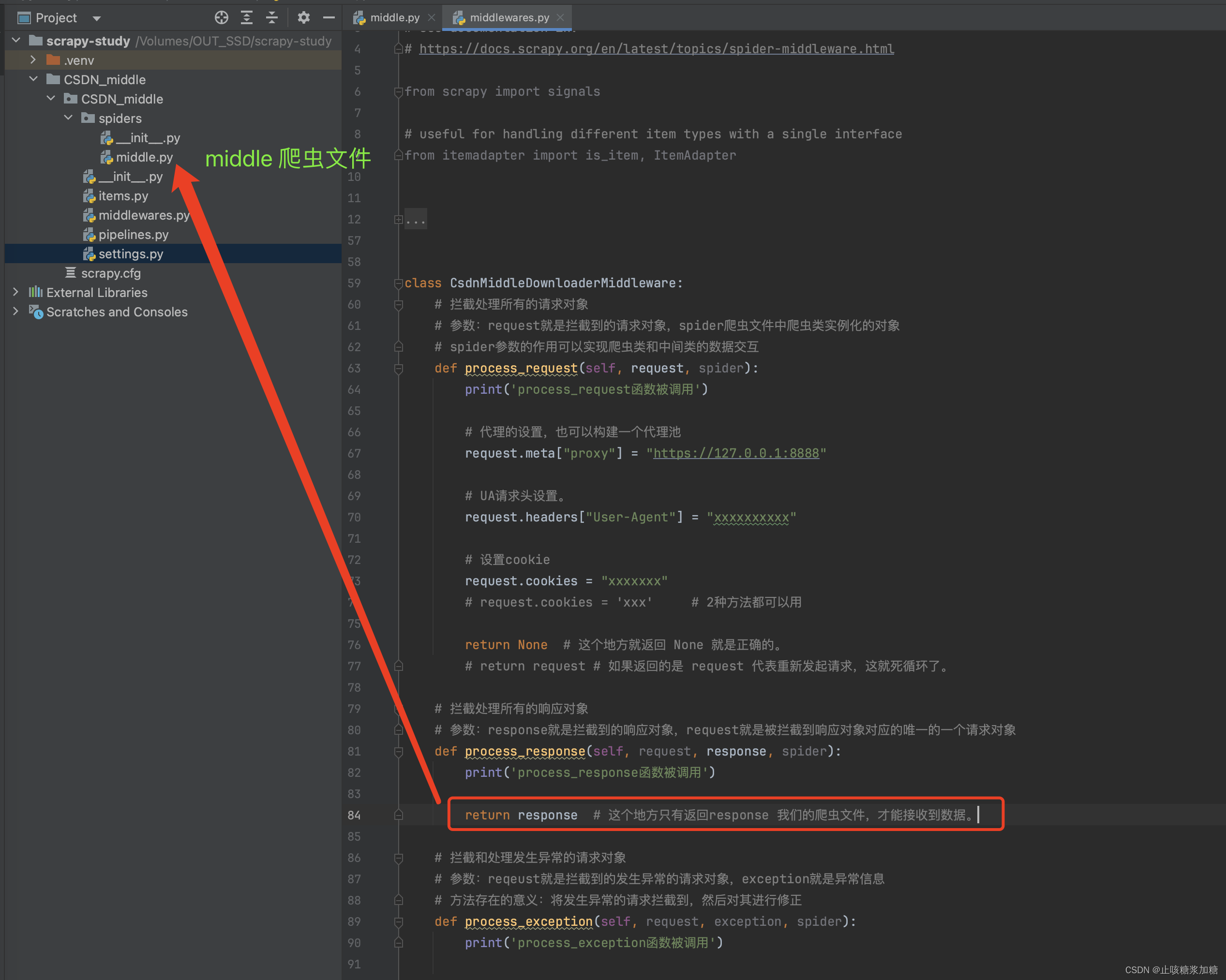
2:process_request 拦截修改请求
在该函数中,我们做哪些设置和操作呢?
1:开发代理中间件
-
request.meta['proxy'] = proxy

2:开发UA中间件
- request.headers['User-Agent'] = ua
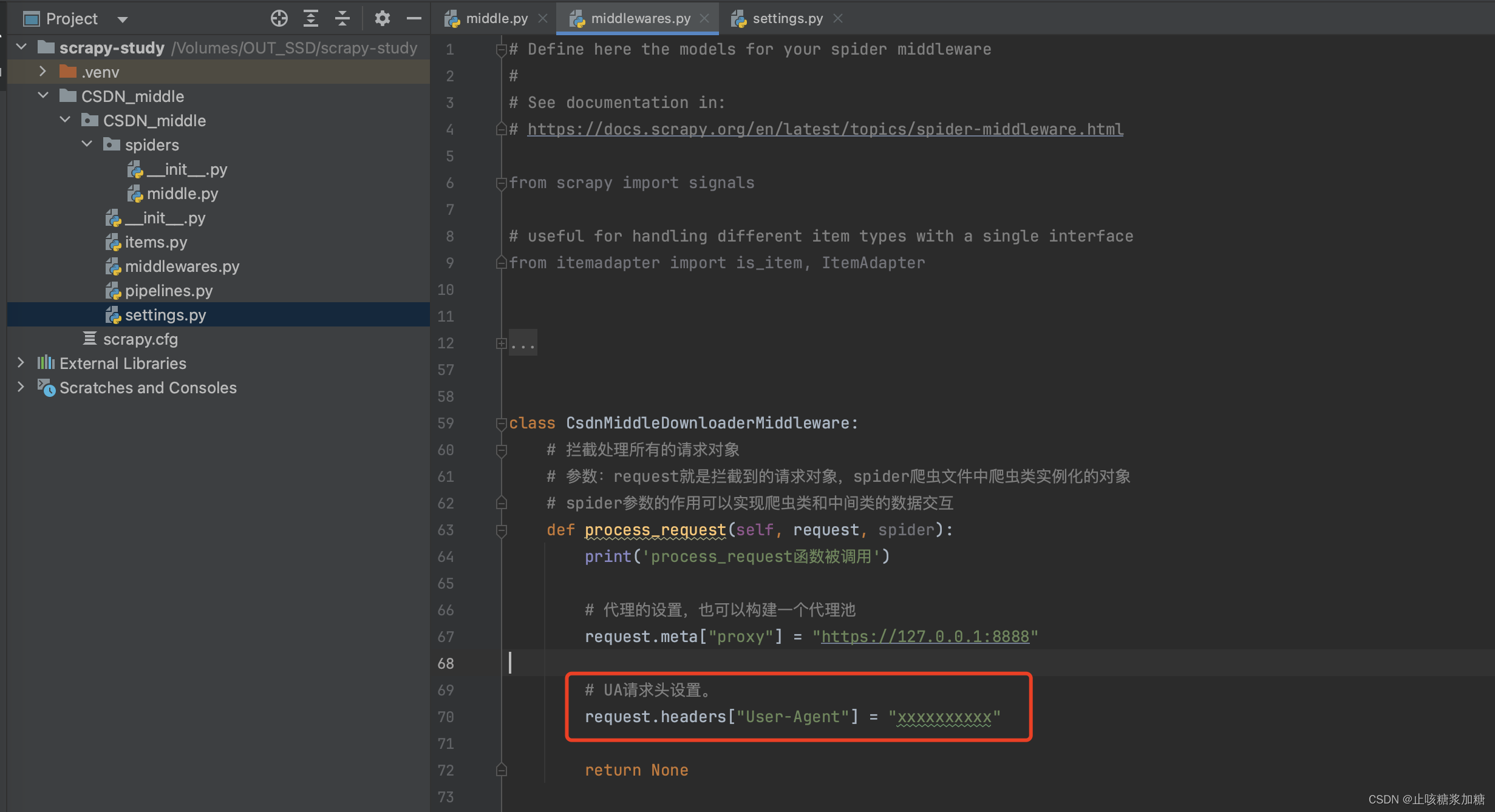
3:开发Cookie中间件
- request.cookies = cookies

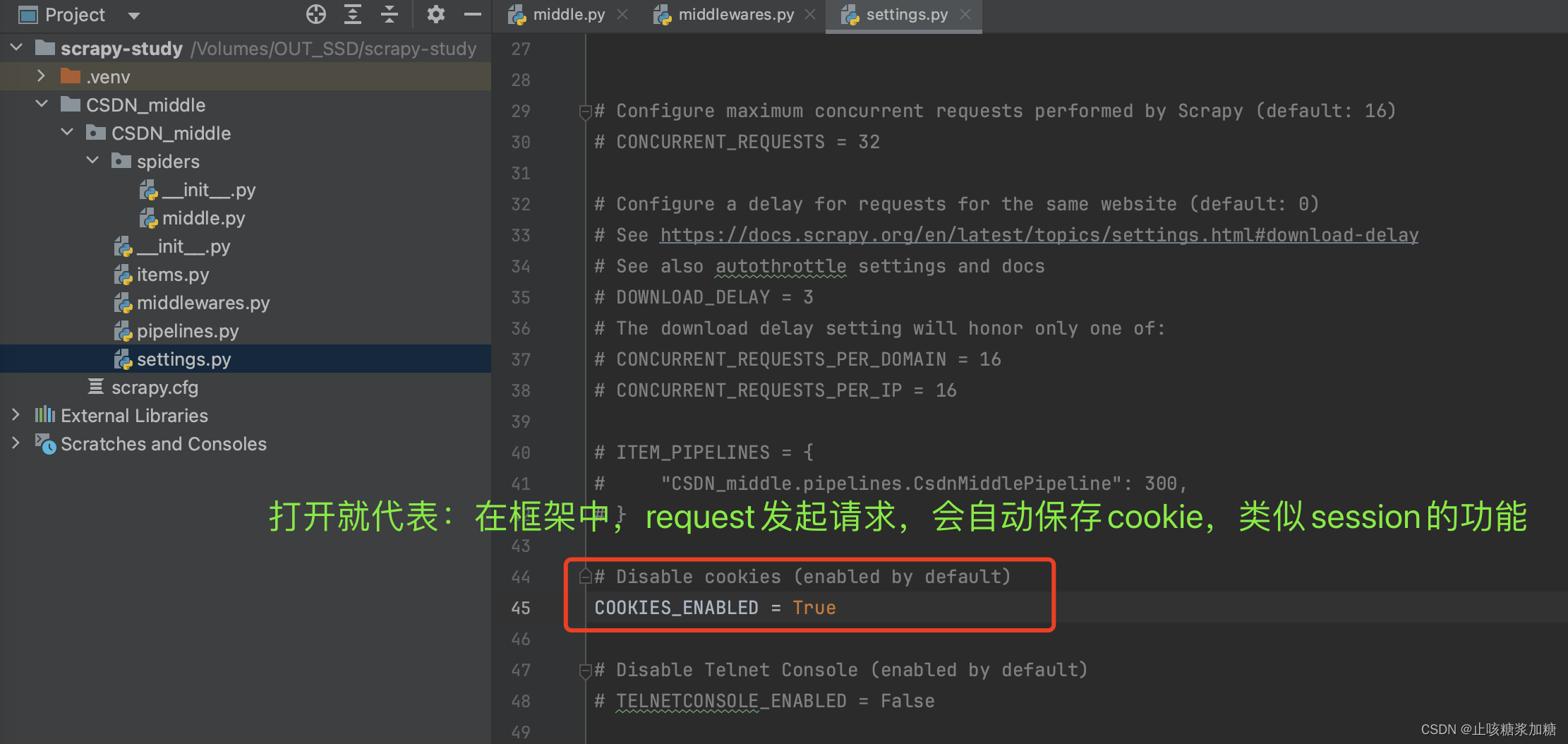
Cookie补充:(具有session的功能)
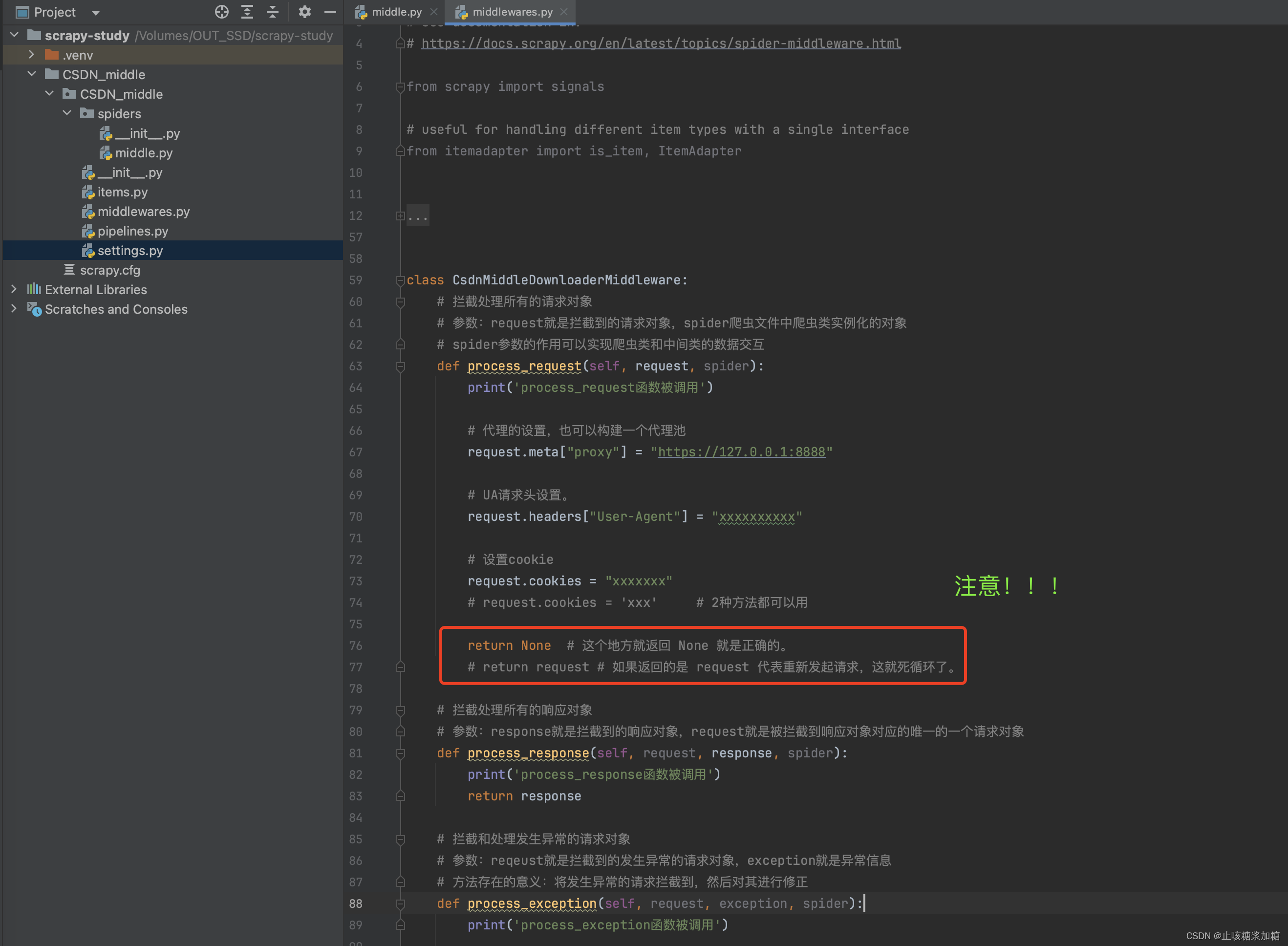
补充:return返回值
return None # 这个地方就返回 None 就是正确的。# return request # 如果返回的是 request 代表重新发起请求,这就死循环了。
3:process_response 拦截修改响应
1:修改响应数据
数据的修改需要用到新的模块,需要导入一下:
from scrapy.http import HtmlResponse参数:
- request:接收传入的响应对象
- body:修改后的数据
- url:就是当前拦截到的请求url
- encoding:定义编码格式
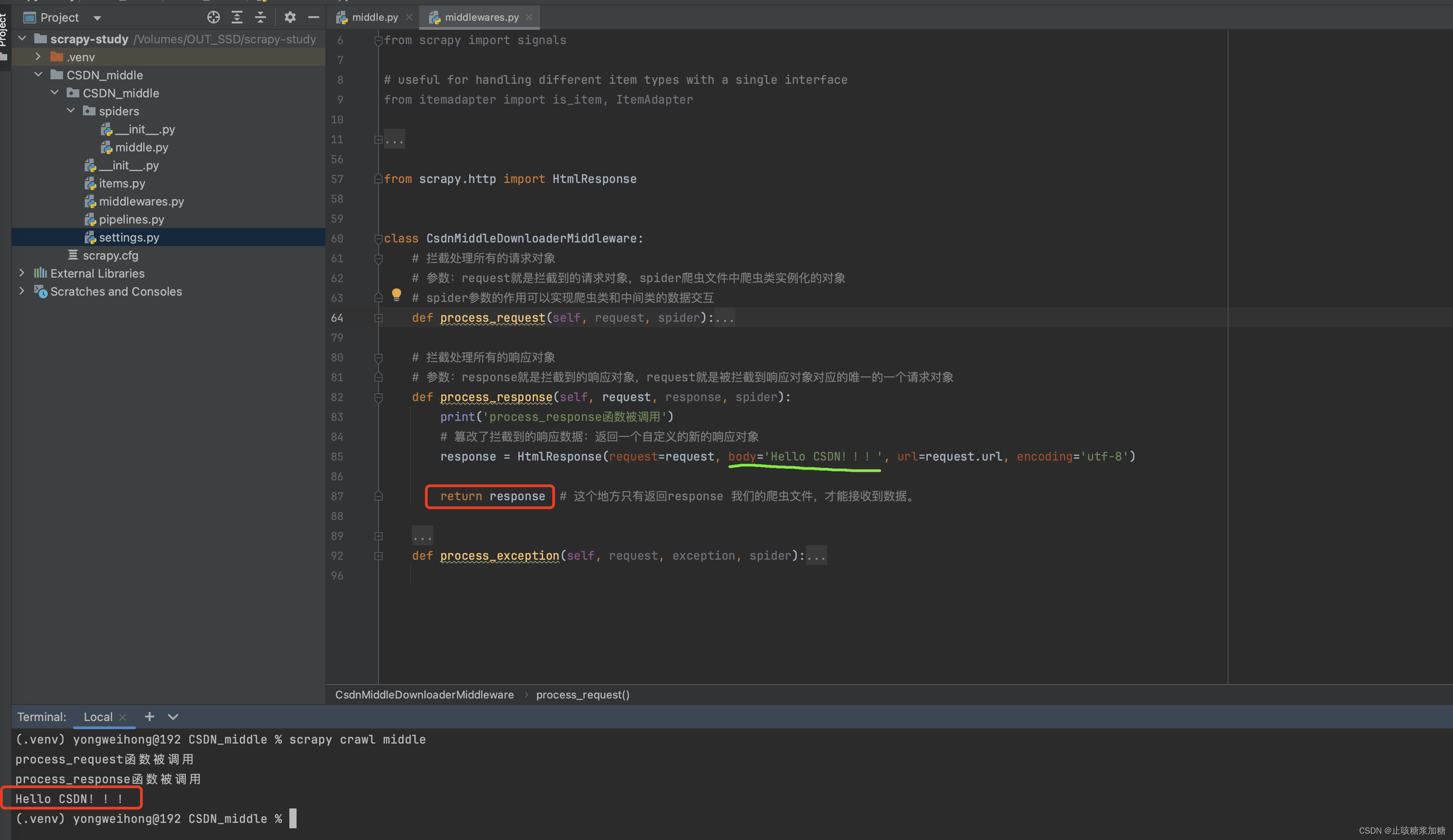
补充:return返回值
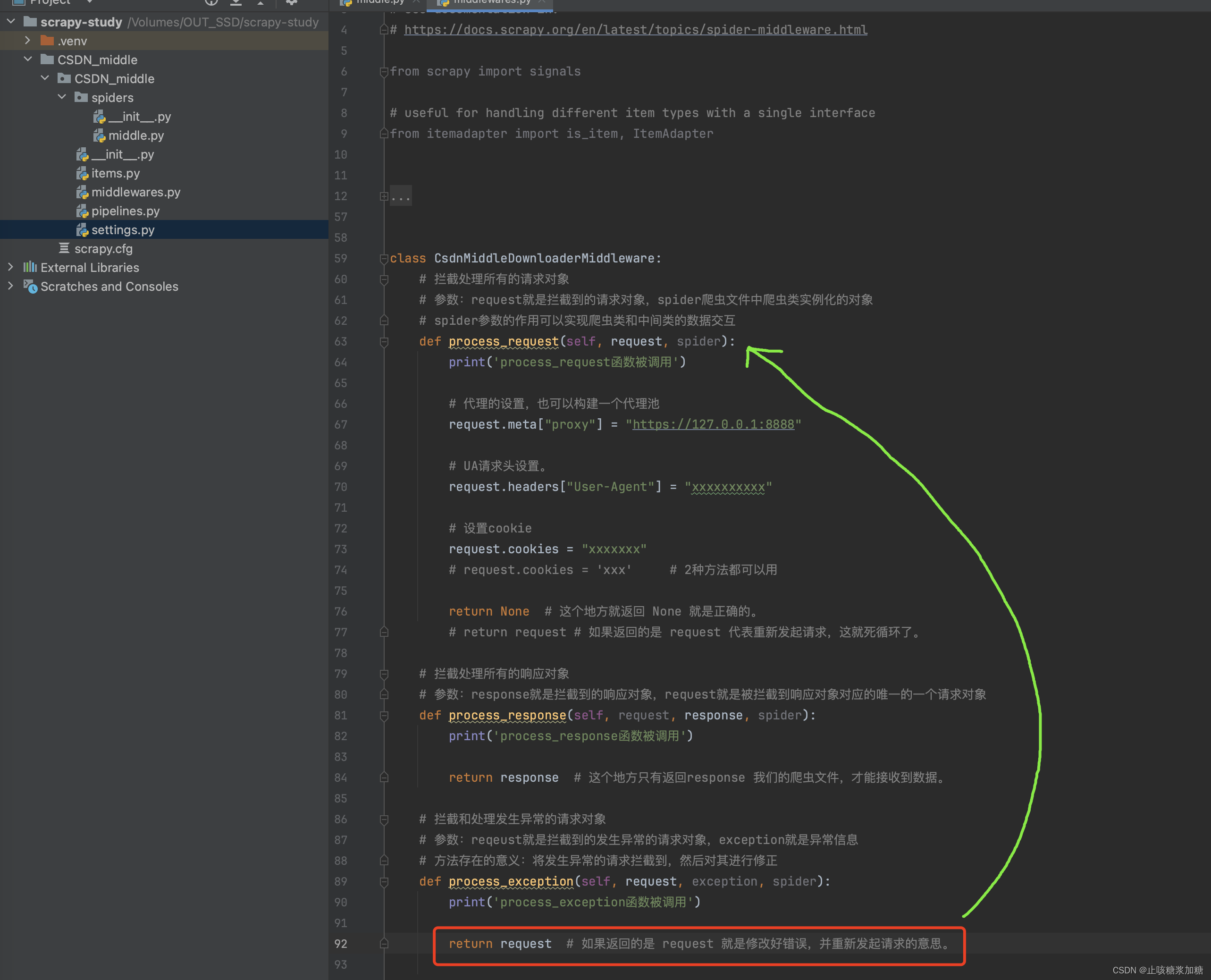
4、process_exception 拦截错误
- 拦截和处理发生异常的请求对象。
- 参数:reqeust就是拦截到的发生异常的请求对象,exception就是异常信息。
- 方法存在的意义:将发生异常的请求拦截到,然后对其进行修正
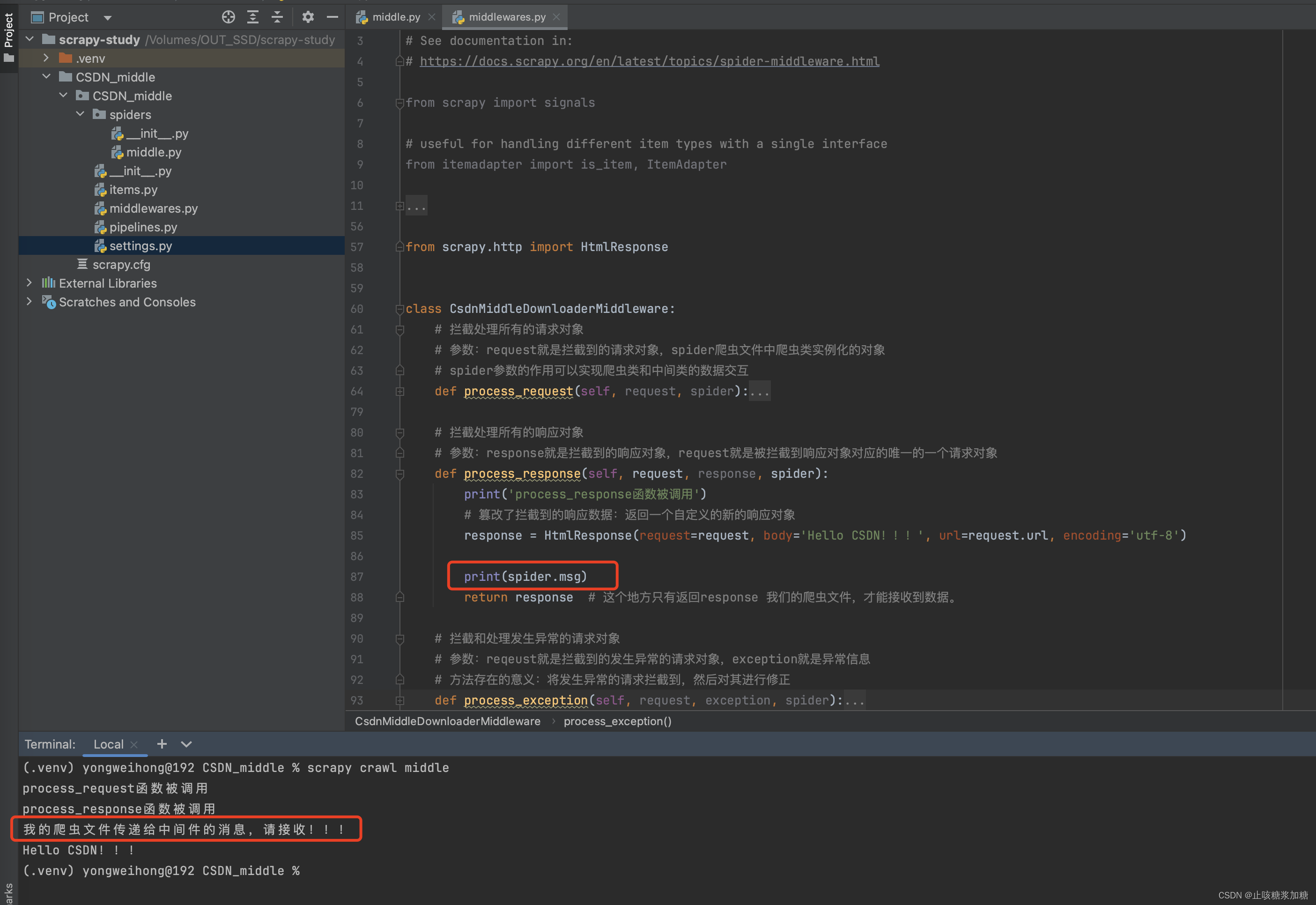
5、spider的作用 (数据交互)
在中间件的3个函数中,都有 spider 这个参数,那这个参数是做啥的?

答:数据交互!
那如何数据交互呢?接着往下看⬇️⬇️⬇️
例如:
图一中:我们在爬虫文件中,设置了一个变量 msg
图二中:我们利用 spider.msg 就可以调用变量 msg
总结:由此我们可以得出,在中间件中只要有参数 spider 就可以调用 爬虫文件中的数据,进行数据交互(spider 就相当于 爬虫文件中类的实例化对象)。
图一: ⬇️
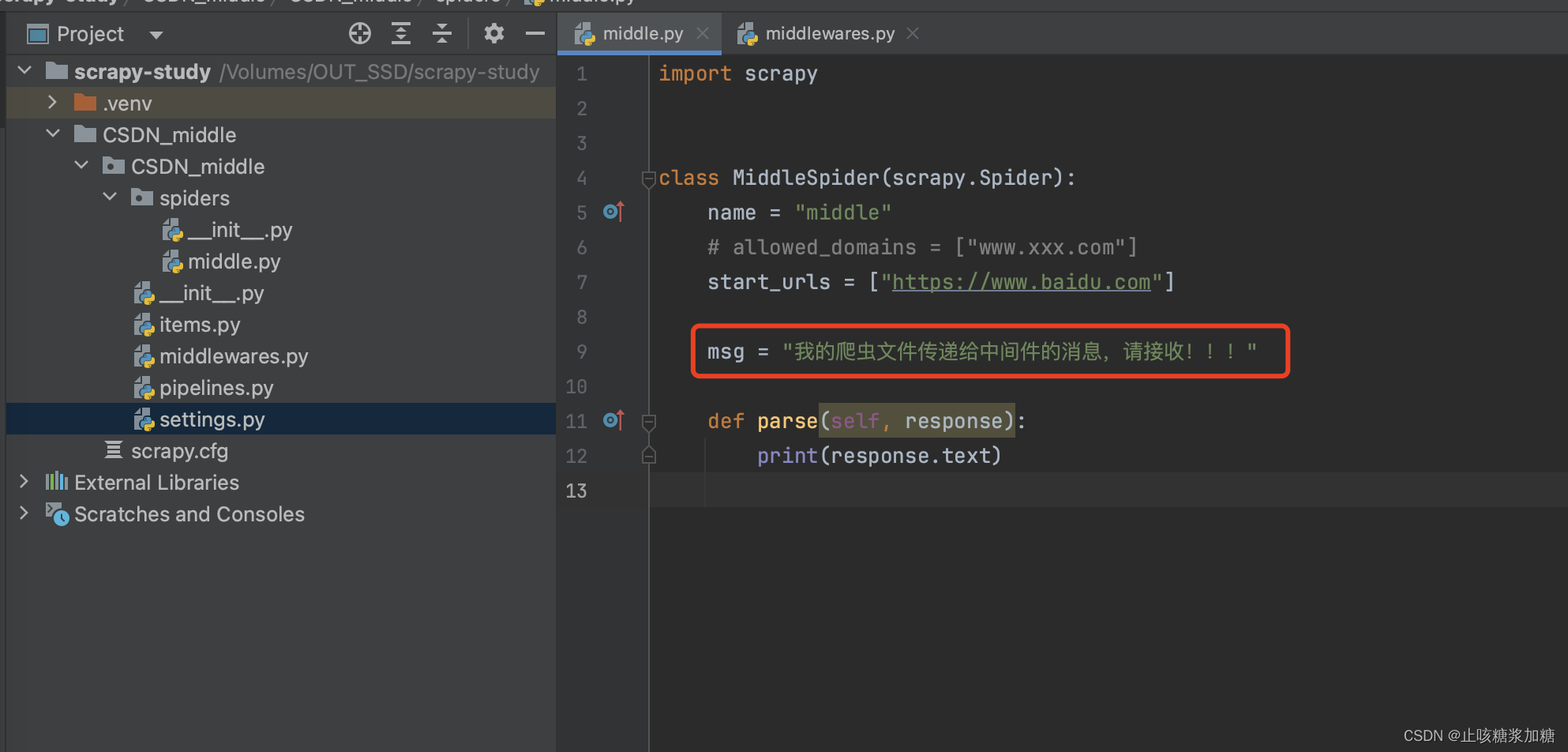
图二:⬇️
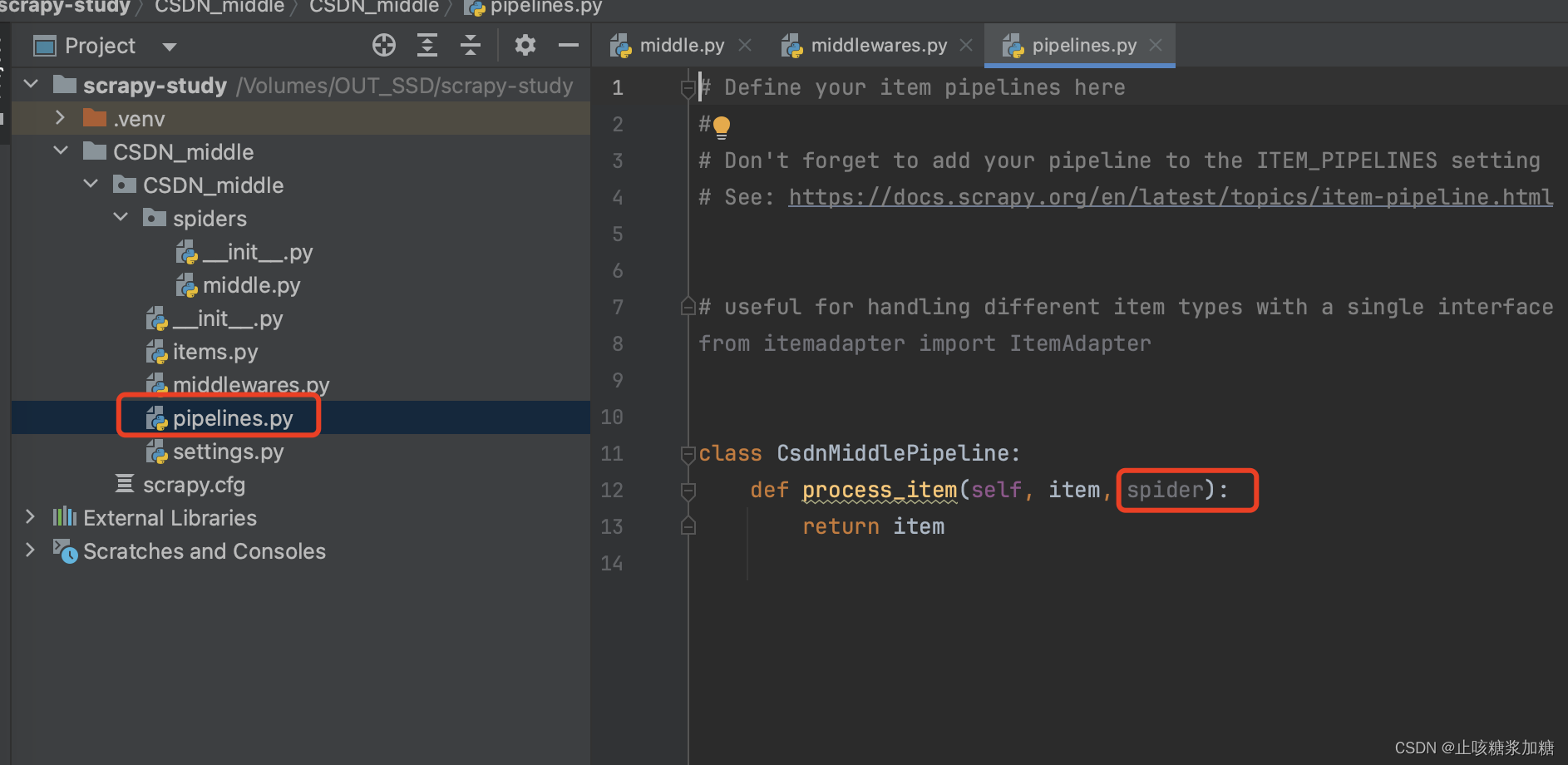
补充:管道中 spider 作用
如下图:
- 管道中的 spider 功能都是一样的,也是用于数据交互的。




异常检测)


动态规划)





抽象类方法、接口和实现类、枚举等示例)

![[c语言c++]手写你自己的swap交换函数](http://pic.xiahunao.cn/[c语言c++]手写你自己的swap交换函数)
第十一周实验(2)设计一个24秒倒计时器)

、isEnabled()、isSelected())
