目录
一、全文检索查询
1、match查询
语法:
2、multi_match查询
语法:
3、match和mult_match的区别
二、精确查询
1、term查询:
语法:
2、range查询:(范围查询)
语法:
三、地理查询
1、geo_bounding_box查询:
语法:
2、geo_distance查询:
语法:
四、复合查询
1、fuction score:
(1)词条频率
(2)TF-IDF算法
(3)BM25算法
2、总结
五、Function Score Query
1、bool查询
一、全文检索查询
1、match查询
全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索。
语法:
GET /indexName/_search
{"query": {"match": {"FIELD": "TEXT"}}
}2、multi_match查询
与match查询类似,只不过允许同时查询多个字段。
语法:
GET /indexName/_search
{"query": {"multi_match": {"query": "TEXT","fields": ["FIELD1","FIELD2"]}}
}3、match和mult_match的区别
- match:根据一个字段查询
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
二、精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。
1、term查询:
根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
value中的值要确保和文档中的一模一样。
语法:
GET /indexName/_search
{"query": {"term": {"FIELD": {"value": "VALUE"}}}
}2、range查询:(范围查询)
根据数值范围查询,可以是数值、日期的范围
gte表示范围下限,lte表示范围上限;
gt表示大于而不等于,lt表示小于而不等于;
语法:
GET /indexName/_search
{"query": {"range": {"FIELD": {"gte": 10,"lte": 20}}}
}三、地理查询
1、geo_bounding_box查询:
查询geo_point值落在某个矩形范围的所有文档
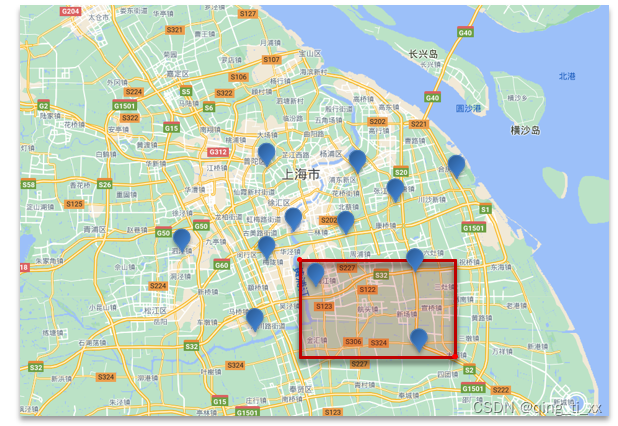
语法:
GET /indexName/_search
{"query": {"geo_bounding_box":{"FIELD":{"top_left":{"lat":31.1,"lon":121.5},"bottom_right":{"lat":30.9,"lon":121.7}}}}
}2、geo_distance查询:
查询到指定中心点小于某个距离值的所有文档
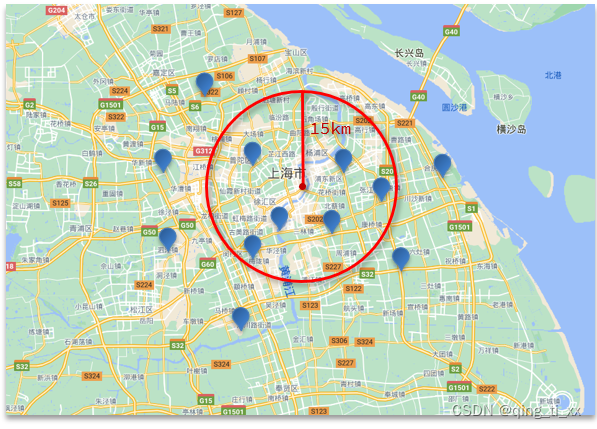
语法:
GET /indexName/_search
{"query": {"geo_distance":{"distance":"15km","FIELD":"31.21.121.5"}}
}四、复合查询
复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。
1、fuction score:
算分函数查询,可以控制文档相关性算分,控制文档排名。
(1)词条频率

例子:
“你你你你你,是是是,我我我我,的的,谁”,一共有15个字。
“你”的频率是
,”是“的频率是
。
频率越高,分数越高,搜索结果越靠前。
(2)TF-IDF算法

例子:
若我要搜索钢铁侠,在搜索结果中,一共有三个文档:
《你是钢铁侠》
《我是钢铁下》
《都是钢铁虾》
其中”钢铁“出现了三次,而文档个数是三次,它的逆文档频率就是
= 0,分数也就是0,
所以”钢铁“就不代表权重了,而”侠“字只出现了一次,所以它的权重大,此搜索结果也就靠前。
(3)BM25算法

BM25是一种用于信息检索的算法,它是基于词频和文档长度的统计方法,用于计算查询与文档之间的相关性得分。BM25算法是一种改进的TF-IDF算法,它考虑了文档长度的影响,以及对于一些高频词汇的惩罚。BM25算法的公式如下:
score(D,Q) = ∑(i=1 to n) IDF(qi) * ((k+1)*f(qi,D))/(f(qi,D)+k*(1-b+b*(|D|/avgdl)))
其中,D表示文档,Q表示查询,qi表示查询中的第i个词,f(qi,D)表示文档D中qi出现的频率,|D|表示文档D的长度,avgdl表示所有文档的平均长度,IDF(qi)表示逆文档频率,k和b是两个可调参数。
BM25算法的优点是可以处理长文档和短文档,而且对于高频词汇的处理也比较合理。但是,BM25算法的计算复杂度较高,需要对所有文档进行扫描和计算,因此在大规模数据集上的应用需要考虑效率问题。
2、总结

五、Function Score Query
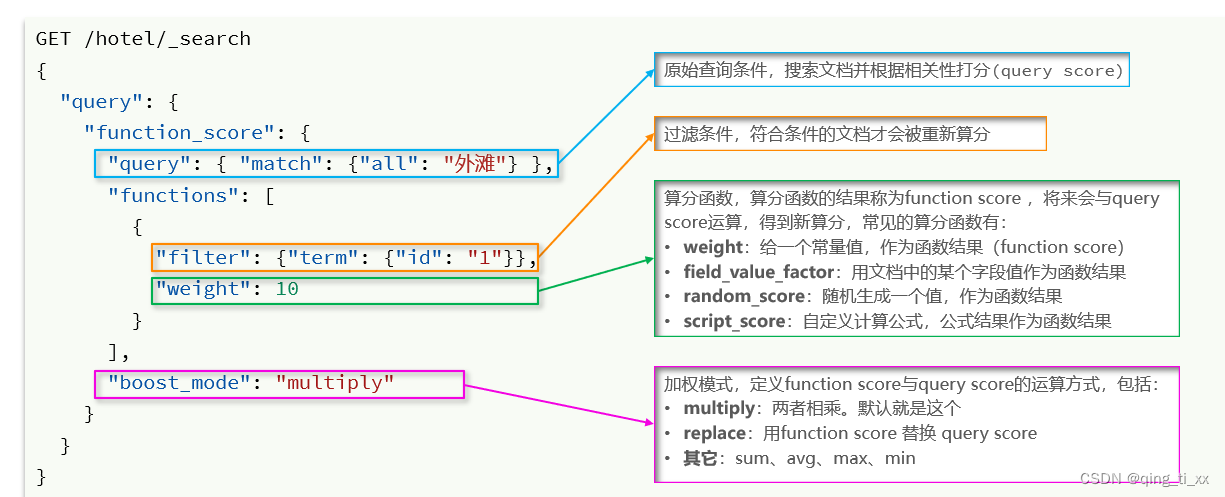
1、bool查询












)




)


