上个章节我们讲解了TiDB的发展和特性,这节我们讲下TiDB具体的架构和应用场景。首先我们回顾下TiDB的优势。
TiDB的优势
与传统的单机数据库相比,TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL的语法,在大多数场景下可以直接替换
- MySQL默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
TiDB的组件
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server,此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件。
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
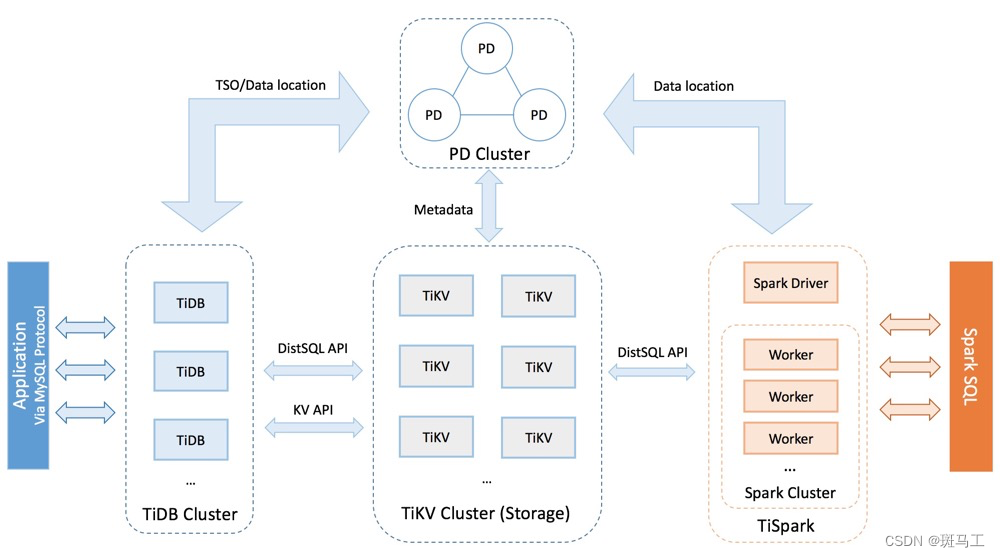
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD (Placement Driver) Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
- 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
- 二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
- 三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
TiFlash
TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
TiKV整体架构
与传统的整节点备份方式不同的,TiKV是将数据按照 key 的范围划分成大致相等的切片(下文统称为 Region),每一个切片会有多个副本(通常是 3 个),其中一个副本是 Leader,提供读写服务。TiKV 通过 PD 对这些 Region 以及副本进行调度,以保证数据和读写负载都均匀地分散在各个 TiKV 上,这样的设计保证了整个集群资源的充分利用并且可以随着机器数量的增加水平扩展。
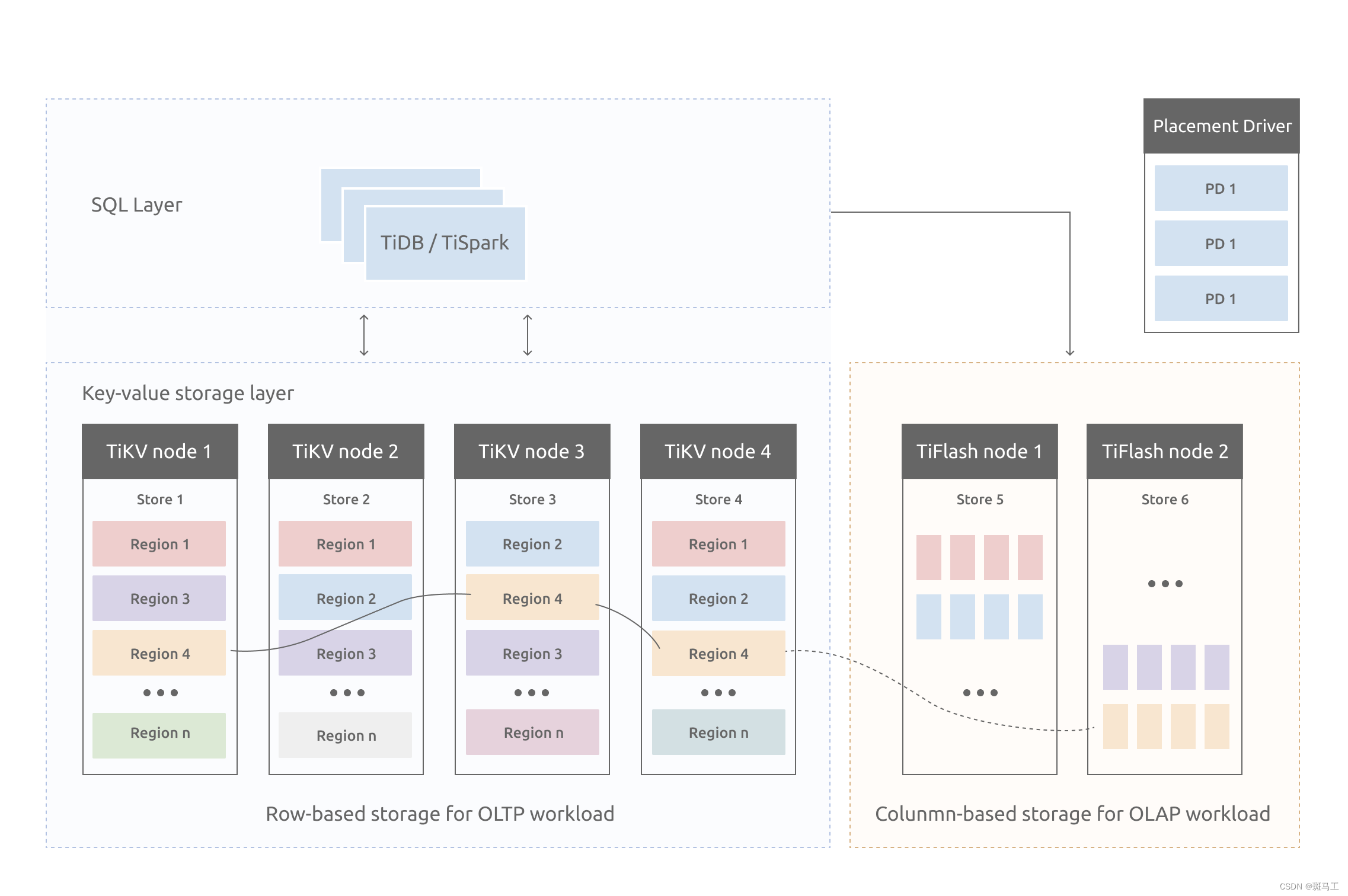
Region分裂与合并
当某个 Region 的大小超过一定限制(默认是 144MB)后,TiKV 会将它分裂为两个或者更多个 Region,以保证各个 Region 的大小是大致接近的,这样更有利于 PD 进行调度决策。同样,当某个 Region 因为大量的删除请求导致 Region 的大小变得更小时,TiKV 会将比较小的两个相邻 Region 合并为一个。
Region调度
Region 与副本之间通过 Raft 协议来维持数据一致性,任何写请求都只能在 Leader 上写入,并且需要写入多数副本后(默认配置为 3 副本,即所有请求必须至少写入两个副本成功)才会返回客户端写入成功。
当 PD 需要把某个 Region 的一个副本从一个 TiKV 节点调度到另一个上面时,PD 会先为这个 Raft Group 在目标节点上增加一个 Learner 副本(复制 Leader 的数据)。当这个 Learner 副本的进度大致追上 Leader 副本时,Leader 会将它变更为 Follower,之后再移除操作节点的 Follower 副本,这样就完成了 Region 副本的一次调度。
Leader 副本的调度原理也类似,不过需要在目标节点的 Learner 副本变为 Follower 副本后,再执行一次 Leader Transfer,让该 Follower 主动发起一次选举成为新 Leader,之后新 Leader 负责删除旧 Leader 这个副本。
分布式事务
TiKV 支持分布式事务,用户(或者 TiDB)可以一次性写入多个 key-value 而不必关心这些 key-value 是否处于同一个数据切片 (Region) 上,TiKV 通过两阶段提交保证了这些读写请求的 ACID 约束。
高可用架构
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
TiDB高可用
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
PD高可用
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
TiKV高可用
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 10 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
应用场景
MySQL分片与合并
TiDB 应用的第一类场景是 MySQL 的分片与合并。对于已经在用 MySQL 的业务,分库、分表、分片、中间件是常用手段,随着分片的增多,跨分片查询是一大难题。TiDB 在业务层兼容 MySQL 的访问协议,PingCAP 做了一个数据同步的工具——Syncer,它可以把TiDB 作为一个 MySQL Slave,将 TiDB 作为现有数据库的从库接在主 MySQL 库的后方,在这一层将数据打通,可以直接进行复杂的跨库、跨表、跨业务的实时 SQL 查询。
直接替换MySQL
第二类场景是用 TiDB 直接去替换 MySQL。如果你的IT架构在搭建之初并未考虑分库分表的问题,全部用了 MySQL,随着业务的快速增长,海量高并发的 OLTP 场景越来越多,如何解决架构上的弊端呢?
在一个 TiDB 的数据库上,所有业务场景不需要做分库分表,所有的分布式工作都由数据库层完成。TiDB 兼容 MySQL 协议,所以可以直接替换 MySQL,而且基本做到了开箱即用,完全不用担心传统分库分表方案带来繁重的工作负担和复杂的维护成本,友好的用户界面让常规的技术人员可以高效地进行维护和管理。另外,TiDB 具有 NoSQL 类似的扩容能力,在数据量和访问流量持续增长的情况下能够通过水平扩容提高系统的业务支撑能力,并且响应延迟稳定。
数据仓库
TiDB 本身是一个分布式系统,第三种使用场景是将 TiDB 当作数据仓库使用。TPC-H 是数据分析领域的一个测试集,TiDB 2.0 在 OLAP 场景下的性能有了大幅提升,原来只能在数据仓库里面跑的一些复杂的 Query,在 TiDB 2.0 里面跑,时间基本都能控制在 10 秒以内。当然,因为 OLAP 的范畴非常大,TiDB 的 SQL 也有搞不定的情况,为此 PingCAP 开源了 TiSpark,TiSpark 是一个 Spark 插件,用户可以直接用 Spark SQL 实时地在 TiKV 上做大数据分析。
作为其他系统的模块
TiDB 是一个传统的存储跟计算分离的项目,其底层的 Key-Value 层,可以单独作为一个 HBase 的 Replacement 来用,它同时支持跨行事务。TiDB 对外提供两个 API 接口,一个是 ACID Transaction 的 API,用于支持跨行事务;另一个是 Raw API,它可以做单行的事务,换来的是整个性能的提升,但不提供跨行事务的 ACID 支持。用户可以根据自身的需求在两个 API 之间自行选择。例如有一些用户直接在 TiKV 之上实现了 Redis 协议,将 TiKV 替换一些大容量,对延迟要求不高的 Redis 场景。




软件包内容详细介绍(5))








![nginx: [alert] could not open error log file](http://pic.xiahunao.cn/nginx: [alert] could not open error log file)





-requests发送post请求)