Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例
21、Flink 的table API与DataStream API 集成(完整版)
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
31、Flink的SQL Gateway介绍及示例
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
33、Flink 的Table API 和 SQL 中的时区
35、Flink 的 Formats 之CSV 和 JSON Format
36、Flink 的 Formats 之Parquet 和 Orc Format
41、Flink之Hive 方言介绍及详细示例
40、Flink 的Apache Kafka connector(kafka source的介绍及使用示例)-1
40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2
40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
45、Flink 的指标体系介绍及验证(1)-指标类型及指标实现示例
45、Flink 的指标体系介绍及验证(2)-指标的scope、报告、系统指标以及追踪、api集成示例和dashboard集成
45、Flink 的指标体系介绍及验证(3)- 完整版
46、Flink 的table api与sql之配项列表及示例
47、Flink 的指标报告介绍(graphite、influxdb、prometheus、statsd和datalog)及示例(jmx和slf4j示例)
48、Flink DataStream API 编程指南(1)- DataStream 入门示例
48、Flink DataStream API 编程指南(2)- DataStream的source、transformation、sink、调试
48、Flink DataStream API 编程指南(3)- 完整版
文章目录
- Flink 系列文章
- 一、Flink DataStream API 编程指南
- 1、DataStream 是什么?
- 2、Flink 程序剖析
- 3、第一个完整示例
- 4、入门示例
- 1)、maven依赖
- 2)、代码
- 3)、验证
本文介绍了Flink DataStream API的编程指南第一部分,即介绍flink的source、transformation和sink的编程过程以及入门示例。其中source和sink各自的内容分别给出了具体的示例以及关于transformation的关联文章介绍。
本专题内容较长,故分为三个部分,即:
48、Flink DataStream API 编程指南(1)- DataStream 入门示例
48、Flink DataStream API 编程指南(2)- DataStream的source、transformation、sink、调试
48、Flink DataStream API 编程指南(3)- 完整版
本文由于是在IDE中做的例子,基本上不依赖外部环境,除了具体的示例,比如读nc等则需要相应的环境。
本文分为4个部分,即介绍datastream、flink的编程模型、入门示例几部分。
本文的示例是在Flink 1.17和Flink 1.13.5版本中运行。
一、Flink DataStream API 编程指南
Flink 中的 DataStream 程序是对数据流(例如过滤、更新状态、定义窗口、聚合)进行转换的常规程序。数据流的起始是从各种源(例如消息队列、套接字流、文件)创建的。结果通过 sink 返回,例如可以将数据写入文件或标准输出(例如命令行终端)。Flink 程序可以在各种上下文中运行,可以独立运行,也可以嵌入到其它程序中。任务执行可以运行在本地 JVM 中,也可以运行在多台机器的集群上。
为了创建你自己的 Flink DataStream 程序,建议从 Flink 程序剖析开始,然后逐渐添加自己的 stream transformation。其余部分作为附加的算子和高级特性的参考。
1、DataStream 是什么?
DataStream API 得名于特殊的 DataStream 类,该类用于表示 Flink 程序中的数据集合。你可以认为 它们是可以包含重复项的不可变数据集合。这些数据可以是有界(有限)的,也可以是无界(无限)的,但用于处理它们的API是相同的。
DataStream 在用法上类似于常规的 Java 集合,但在某些关键方面却大不相同。它们是不可变的,这意味着一旦它们被创建,你就不能添加或删除元素。你也不能简单地察看内部元素,而只能使用 DataStream API 操作来处理它们,DataStream API 操作也叫作转换(transformation)。
你可以通过在 Flink 程序中添加 source 创建一个初始的 DataStream。然后,你可以基于 DataStream 派生新的流,并使用 map、filter 等 API 方法把 DataStream 和派生的流连接在一起。
2、Flink 程序剖析
Flink 程序看起来像一个转换 DataStream 的常规程序。每个程序由相同的基本部分组成:
- 获取一个执行环境(execution environment);
- 加载/创建初始数据;
- 指定数据相关的转换;
- 指定计算结果的存储位置;
- 触发程序执行。
现在我们将对这些步骤逐一进行概述,更多细节请参考相关章节。请注意,Java DataStream API 的所有核心类都可以在 org.apache.flink.streaming.api 中找到。
StreamExecutionEnvironment 是所有 Flink 程序的基础。
可以使用 StreamExecutionEnvironment 的如下静态方法获取 StreamExecutionEnvironment:
/*** Creates an execution environment that represents the context in which the program is* currently executed. If the program is invoked standalone, this method returns a local* execution environment, as returned by {@link #createLocalEnvironment()}.** @return The execution environment of the context in which the program is executed.*/public static StreamExecutionEnvironment getExecutionEnvironment() {return getExecutionEnvironment(new Configuration());}/*** Creates an execution environment that represents the context in which the program is* currently executed. If the program is invoked standalone, this method returns a local* execution environment, as returned by {@link #createLocalEnvironment(Configuration)}.** <p>When executed from the command line the given configuration is stacked on top of the* global configuration which comes from the {@code flink-conf.yaml}, potentially overriding* duplicated options.** @param configuration The configuration to instantiate the environment with.* @return The execution environment of the context in which the program is executed.*/public static StreamExecutionEnvironment getExecutionEnvironment(Configuration configuration) {return Utils.resolveFactory(threadLocalContextEnvironmentFactory, contextEnvironmentFactory).map(factory -> factory.createExecutionEnvironment(configuration)).orElseGet(() -> StreamExecutionEnvironment.createLocalEnvironment(configuration));}/*** Creates a {@link LocalStreamEnvironment}. The local execution environment will run the* program in a multi-threaded fashion in the same JVM as the environment was created in. The* default parallelism of the local environment is the number of hardware contexts (CPU cores /* threads), unless it was specified differently by {@link #setParallelism(int)}.** @return A local execution environment.*/public static LocalStreamEnvironment createLocalEnvironment() {return createLocalEnvironment(defaultLocalParallelism);}/*** Creates a {@link LocalStreamEnvironment}. The local execution environment will run the* program in a multi-threaded fashion in the same JVM as the environment was created in. It* will use the parallelism specified in the parameter.** @param parallelism The parallelism for the local environment.* @return A local execution environment with the specified parallelism.*/public static LocalStreamEnvironment createLocalEnvironment(int parallelism) {return createLocalEnvironment(parallelism, new Configuration());}/*** Creates a {@link LocalStreamEnvironment}. The local execution environment will run the* program in a multi-threaded fashion in the same JVM as the environment was created in. It* will use the parallelism specified in the parameter.** @param parallelism The parallelism for the local environment.* @param configuration Pass a custom configuration into the cluster* @return A local execution environment with the specified parallelism.*/public static LocalStreamEnvironment createLocalEnvironment(int parallelism, Configuration configuration) {Configuration copyOfConfiguration = new Configuration();copyOfConfiguration.addAll(configuration);copyOfConfiguration.set(CoreOptions.DEFAULT_PARALLELISM, parallelism);return createLocalEnvironment(copyOfConfiguration);}/*** Creates a {@link LocalStreamEnvironment}. The local execution environment will run the* program in a multi-threaded fashion in the same JVM as the environment was created in.** @param configuration Pass a custom configuration into the cluster* @return A local execution environment with the specified parallelism.*/public static LocalStreamEnvironment createLocalEnvironment(Configuration configuration) {if (configuration.getOptional(CoreOptions.DEFAULT_PARALLELISM).isPresent()) {return new LocalStreamEnvironment(configuration);} else {Configuration copyOfConfiguration = new Configuration();copyOfConfiguration.addAll(configuration);copyOfConfiguration.set(CoreOptions.DEFAULT_PARALLELISM, defaultLocalParallelism);return new LocalStreamEnvironment(copyOfConfiguration);}}/*** Creates a {@link LocalStreamEnvironment} for local program execution that also starts the web* monitoring UI.** <p>The local execution environment will run the program in a multi-threaded fashion in the* same JVM as the environment was created in. It will use the parallelism specified in the* parameter.** <p>If the configuration key 'rest.port' was set in the configuration, that particular port* will be used for the web UI. Otherwise, the default port (8081) will be used.*/@PublicEvolvingpublic static StreamExecutionEnvironment createLocalEnvironmentWithWebUI(Configuration conf) {checkNotNull(conf, "conf");if (!conf.contains(RestOptions.PORT)) {// explicitly set this option so that it's not set to 0 laterconf.setInteger(RestOptions.PORT, RestOptions.PORT.defaultValue());}return createLocalEnvironment(conf);}/*** Creates a {@link RemoteStreamEnvironment}. The remote environment sends (parts of) the* program to a cluster for execution. Note that all file paths used in the program must be* accessible from the cluster. The execution will use no parallelism, unless the parallelism is* set explicitly via {@link #setParallelism}.** @param host The host name or address of the master (JobManager), where the program should be* executed.* @param port The port of the master (JobManager), where the program should be executed.* @param jarFiles The JAR files with code that needs to be shipped to the cluster. If the* program uses user-defined functions, user-defined input formats, or any libraries, those* must be provided in the JAR files.* @return A remote environment that executes the program on a cluster.*/public static StreamExecutionEnvironment createRemoteEnvironment(String host, int port, String... jarFiles) {return new RemoteStreamEnvironment(host, port, jarFiles);}/*** Creates a {@link RemoteStreamEnvironment}. The remote environment sends (parts of) the* program to a cluster for execution. Note that all file paths used in the program must be* accessible from the cluster. The execution will use the specified parallelism.** @param host The host name or address of the master (JobManager), where the program should be* executed.* @param port The port of the master (JobManager), where the program should be executed.* @param parallelism The parallelism to use during the execution.* @param jarFiles The JAR files with code that needs to be shipped to the cluster. If the* program uses user-defined functions, user-defined input formats, or any libraries, those* must be provided in the JAR files.* @return A remote environment that executes the program on a cluster.*/public static StreamExecutionEnvironment createRemoteEnvironment(String host, int port, int parallelism, String... jarFiles) {RemoteStreamEnvironment env = new RemoteStreamEnvironment(host, port, jarFiles);env.setParallelism(parallelism);return env;}/*** Creates a {@link RemoteStreamEnvironment}. The remote environment sends (parts of) the* program to a cluster for execution. Note that all file paths used in the program must be* accessible from the cluster. The execution will use the specified parallelism.** @param host The host name or address of the master (JobManager), where the program should be* executed.* @param port The port of the master (JobManager), where the program should be executed.* @param clientConfig The configuration used by the client that connects to the remote cluster.* @param jarFiles The JAR files with code that needs to be shipped to the cluster. If the* program uses user-defined functions, user-defined input formats, or any libraries, those* must be provided in the JAR files.* @return A remote environment that executes the program on a cluster.*/public static StreamExecutionEnvironment createRemoteEnvironment(String host, int port, Configuration clientConfig, String... jarFiles) {return new RemoteStreamEnvironment(host, port, clientConfig, jarFiles);}/*** Gets the default parallelism that will be used for the local execution environment created by* {@link #createLocalEnvironment()}.** @return The default local parallelism*/@PublicEvolvingpublic static int getDefaultLocalParallelism() {return defaultLocalParallelism;}/*** Sets the default parallelism that will be used for the local execution environment created by* {@link #createLocalEnvironment()}.** @param parallelism The parallelism to use as the default local parallelism.*/@PublicEvolvingpublic static void setDefaultLocalParallelism(int parallelism) {defaultLocalParallelism = parallelism;}
通常,只需要使用 getExecutionEnvironment() 即可,因为该方法会根据上下文做正确的处理:如果你在 IDE 中执行你的程序或将其作为一般的 Java 程序执行,那么它将创建一个本地环境,该环境将在你的本地机器上执行你的程序。如果你基于程序创建了一个 JAR 文件,并通过命令行运行它,Flink 集群管理器将执行程序的 main 方法,同时 getExecutionEnvironment() 方法会返回一个执行环境以在集群上执行你的程序。
为了指定 data sources,执行环境提供了一些方法,支持使用各种方法从文件中读取数据:你可以直接逐行读取数据,像读 CSV 文件一样,或使用任何第三方提供的 source。
如果你只是将一个文本文件作为一个行的序列来读取,那么可以使用:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> users = env.readTextFile("file:///D:/workspace/bigdata-component/hadoop/test/in/flink/");
这将生成一个 DataStream,然后你可以在上面应用转换(transformation)来创建新的派生 DataStream。
你可以调用 DataStream 上具有转换功能的方法来应用转换。例如,一个 map 的转换如下所示:
DataStream<Tuple3<Integer, String, Integer>> parsed = users.map(new MapFunction<String, Tuple3<Integer, String, Integer>>() {@Overridepublic Tuple3<Integer, String, Integer> map(String value) {// 文件数据格式形如:1|107860|7191String[] line = value.split(",");return Tuple3.of(Integer.valueOf(line[0]), line[1], Integer.valueOf(line[2]));}});这将通过把原始集合中的每一行转换为一个Tuple3<Integer, String, Integer>来创建一个新的 DataStream。
一旦你有了包含最终结果的 DataStream,你就可以通过创建 sink 把它写到外部系统。下面是一些用于创建 sink 的示例方法:
parsed.print();parsed.writeAsText("file:///D:/workspace/bigdata-component/hadoop/test/out/flink");一旦指定了完整的程序,需要调用 StreamExecutionEnvironment 的 execute() 方法来触发程序执行。根据 ExecutionEnvironment 的类型,执行会在你的本地机器上触发,或将你的程序提交到某个集群上执行。
execute() 方法将等待作业完成,然后返回一个 JobExecutionResult,其中包含执行时间和累加器结果。
如果不想等待作业完成,可以通过调用 StreamExecutionEnvironment 的 executeAsync() 方法来触发作业异步执行。它会返回一个 JobClient,你可以通过它与刚刚提交的作业进行通信。如下是使用 executeAsync() 实现 execute() 语义的示例。
final JobClient jobClient = env.executeAsync();final JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
关于程序执行的最后一部分对于理解何时以及如何执行 Flink 算子是至关重要的。所有 Flink 程序都是延迟执行的:当程序的 main 方法被执行时,数据加载和转换不会直接发生。相反,每个算子都被创建并添加到 dataflow 形成的有向图。当执行被执行环境的 execute() 方法显示地触发时,这些算子才会真正执行。程序是在本地执行还是在集群上执行取决于执行环境的类型。
延迟计算允许你构建复杂的程序,Flink 会将其作为一个整体的计划单元来执行。
3、第一个完整示例
- maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency></dependencies>
- 代码
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author alanchan**/
public class TestFileSystemDemo {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> orders = env.readTextFile("file:///D:/workspace/bigdata-component/hadoop/test/in/flink/");DataStream<Tuple3<Integer, String, Integer>> parsed = orders.map(new MapFunction<String, Tuple3<Integer, String, Integer>>() {@Overridepublic Tuple3<Integer, String, Integer> map(String value) {// 文件数据格式形如:1|107860|7191String[] line = value.split(",");return Tuple3.of(Integer.valueOf(line[0]), line[1], Integer.valueOf(line[2]));}});parsed.print();parsed.writeAsText("file:///D:/workspace/bigdata-component/hadoop/test/out/flink");env.execute();}}
- 运行结果
控制台输出结果
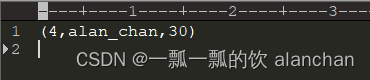
8> (1,alan,15)
16> (4,alan_chan,30)
13> (3,alanchanchn,25)
3> (5,alan_chan_chn,45)
10> (2,alanchan,20)
文件输出结果见下图
4、入门示例
如下是一个完整的、可运行的程序示例,它是基于流窗口的单词统计应用程序,计算 5 秒窗口内来自 Web 套接字的单词数。
1)、maven依赖
见本文上述示例中的maven依赖。
2)、代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;/*** @author alanchan**/
public class TestWindowWordCount {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Tuple2<String, Integer>> dataStream = env.socketTextStream("192.168.10.42", 9999).flatMap(new Splitter()).keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).sum(1);dataStream.print();env.execute("Window WordCount");}public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {for (String word : sentence.split(",")) {out.collect(new Tuple2<String, Integer>(word, 1));}}}}
3)、验证
前提是nc已经安装好了。
- 启动nc并输入数据
# 在192.168.10.42上使用nc -lk 9999 向指定端口发送数据
# nc是netcat的简称,原本是用来设置路由器,我们可以利用它向某个端口发送数据
# 如果没有该命令可以下安装 yum install -y nc
[alanchan@server2 bin]$ nc -lk 9999
alan,alach,alanchan,hello
alan_chan,hi,flink
alan,flink,good
alan,alach,alanchan,hello
hello,123- 启动应用程序,并观察控制台输出
应用程序启动后,再在nc中输入数据
13> (alan,1)
5> (alanchan,1)
8> (alach,1)
5> (hello,1)
16> (alan_chan,1)
13> (flink,1)
6> (hi,1)
13> (alan,1)
11> (good,1)
13> (flink,1)
8> (alach,1)
5> (alanchan,1)
13> (alan,1)
5> (hello,1)
5> (hello,1)
4> (123,1)如果想查看大于 1 的计数,在 5 秒内重复输入相同的单词即可(如果无法快速输入,则可以将窗口大小从 5 秒增加 )。
以上,本文介绍了Flink DataStream API的编程指南第一部分,即介绍flink的source、transformation和sink的编程过程以及入门示例。其中source和sink各自的内容分别给出了具体的示例以及关于transformation的关联文章介绍。
本专题内容较长,故分为三个部分,即:
48、Flink DataStream API 编程指南(1)- DataStream 入门示例
48、Flink DataStream API 编程指南(2)- DataStream的source、transformation、sink、调试
48、Flink DataStream API 编程指南(3)- 完整版



















)