
一、说明
概率校准,指的是对于分类器而言,对应多种类别,概率最大就将样本归入,这个事实没有考虑置信度的问题。sklearn的calibration就是指的这种情形,参考本文。
二、关于sklearn.calibration的概念
执行分类时,您通常首先需要预测类标签,其次要获得相应标签的概率。这个概率让你对预测有一定的信心。有些模型可能会给您提供较差的类概率估计,有些甚至不支持概率预测(例如 的某些实例 SGDClassifier)。校准模块允许您更好地校准给定模型的概率,或添加对概率预测的支持。
校准良好的分类器是概率分类器, predict_proba方法的输出可以直接解释为置信水平。例如,一个校准良好的(二元)分类器应该对样本进行分类,使得在它给出的Predict_proba值接近 0.8的样本中,大约 80% 实际上属于正类。
在展示如何重新校准分类器之前,我们首先需要一种方法来检测分类器的校准效果如何。
注意
严格正确的概率预测评分规则,例如 sklearn.metrics.brier_score_loss评估 sklearn.metrics.log_loss模型的校准(可靠性)和判别力(分辨率),以及数据的随机性(不确定性)。这是从著名的 Murphy [ 1 ]的 Brier 分数分解得出的。由于尚不清楚哪一项占主导地位,因此分数对于单独评估校准的用途有限(除非计算分解的每一项)。例如,较低的 Brier 损失并不一定意味着更好的校准模型,它也可能意味着更差的校准模型,具有更大的辨别力,例如使用更多的特征。
1.16.1 校准曲线
校准曲线,也称为可靠性图(Wilks 1995 [ 2 ]),比较二元分类器的概率预测的校准程度。它绘制了正标签的频率(更准确地说,是 条件事件概率的估计 在 y 轴上与x 轴上模型的预测概率Predict_proba相对应。棘手的部分是获取 y 轴的值。在 scikit-learn 中,这是通过对预测进行分箱来实现的,使得 x 轴代表每个分箱中的平均预测概率。y 轴是给定该箱的预测的正例的分数,即类别为正类的样本的比例(在每个箱中)。
顶部校准曲线图是使用 创建的 CalibrationDisplay.from_estimator,用于calibration_curve计算每个箱的平均预测概率和阳性分数。 CalibrationDisplay.from_estimator 将拟合分类器作为输入,用于计算预测概率。因此分类器必须具有Predict_proba方法。对于少数没有Predict_proba方法的分类器,可以使用它CalibratedClassifierCV来校准分类器输出的概率。
底部直方图通过显示每个预测概率箱中的样本数量来深入了解每个分类器的行为。
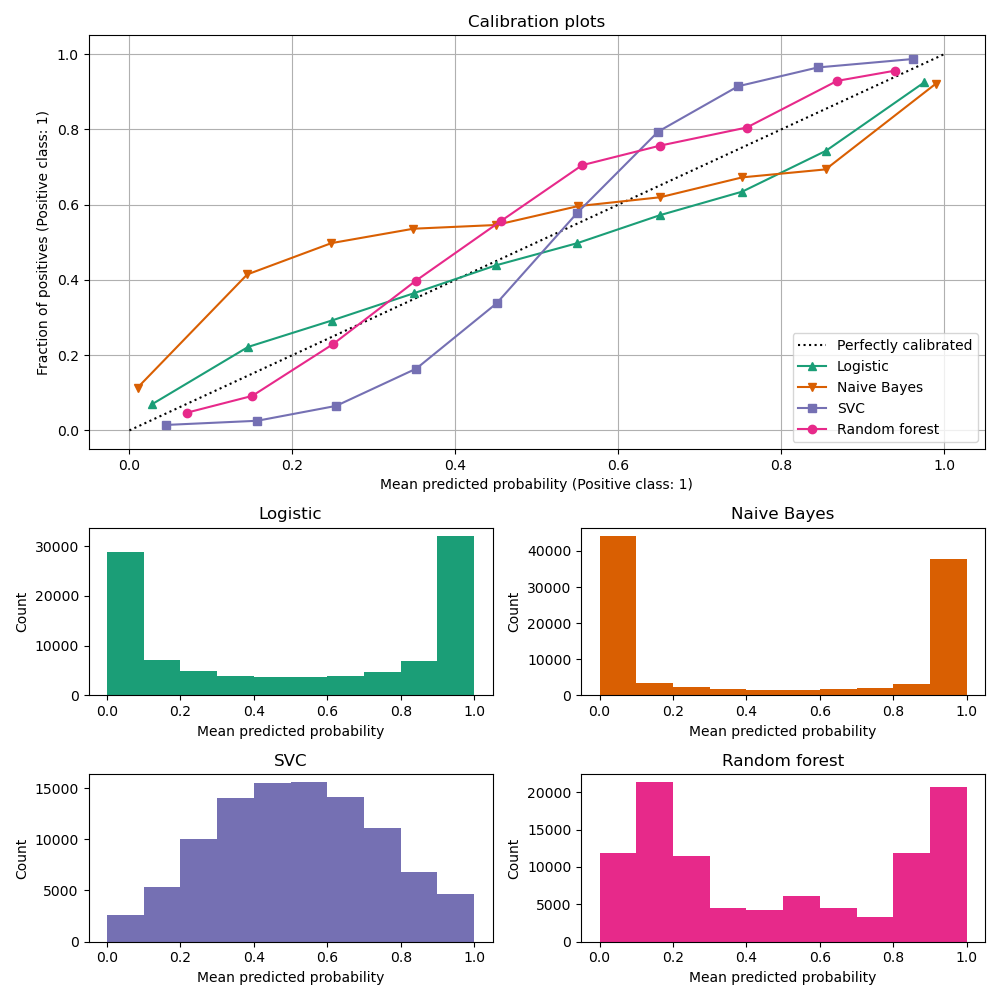
LogisticRegression默认情况下返回经过良好校准的预测,因为它具有针对其损失的规范链接函数,即Log loss的 logit-link 。这就引出了所谓的平衡性,参见[ 8 ]和 Logistic回归。与此相反,其他显示的模型返回有偏差的概率;每个模型有不同的偏差。
GaussianNB(朴素贝叶斯)倾向于将概率推至 0 或 1(注意直方图中的计数)。这主要是因为它假设特征在给定类别的情况下是条件独立的,但在包含 2 个冗余特征的数据集中,情况并非如此。
RandomForestClassifier显示相反的行为:直方图在大约 0.2 和 0.9 的概率处显示峰值,而接近 0 或 1 的概率非常罕见。Niculescu-Mizil 和 Caruana [ 3 ]给出了对此的解释:“诸如装袋和随机森林之类的方法,从一组基本模型中进行平均预测可能很难在 0 和 1 附近进行预测,因为底层基本模型中的方差将偏差预测应该与这些值接近零或一。由于预测仅限于区间 [0,1],因此方差引起的误差往往是单边接近零和一的。例如,如果模型应预测某种情况下的 p = 0,则 bagging 实现此目的的唯一方法是所有 bagged 树预测为零。如果我们向 bagging 平均的树添加噪声,这种噪声将导致某些树在这种情况下预测值大于 0,从而使 bagged 集成的平均预测远离 0。我们在随机情况下最强烈地观察到这种效应森林,因为用随机森林训练的基础层树由于特征子集化而具有相对较高的方差。” 因此,校准曲线显示出特征性的 S 形形状,表明分类器可以更信任其“直觉”,并且通常返回更接近 0 或 1 的概率。
LinearSVC(SVC) 显示出比随机森林更 S 形的曲线,这是最大边际方法的典型特征(比较 Niculescu-Mizil 和 Caruana [ 3 ]),该方法侧重于难以对接近决策边界的样本进行分类(支持向量)。
1.16.2. 校准分类器
校准分类器包括拟合回归器(称为 校准器),该回归器将分类器的输出(由Decision_function或Predict_proba给出 )映射到 [0, 1] 中的校准概率。将给定样本的分类器的输出表示为,校准器尝试预测条件事件概率
。
理想情况下,校准器适合于独立于最初用于拟合分类器的训练数据的数据集。这是因为分类器在其训练数据上的性能会比新数据上的性能更好。因此,使用训练数据的分类器输出来拟合校准器将导致校准器有偏差,该校准器映射到的概率比应有的更接近 0 和 1。
1.16.3。用法
该类CalibratedClassifierCV用于校准分类器。
CaliberatedClassifierCV 使用交叉验证方法来确保始终使用无偏数据来拟合校准器。数据被分成 k (train_set, test_set) 对(由 cv 确定)。当 ensemble=True (默认)时,对于每个交叉验证分割独立地重复以下过程:首先在训练子集上训练 base_estimator 的克隆。然后,使用其对测试子集的预测来拟合校准器(S形回归器或等渗回归器)。这会产生 k 个(分类器、校准器)对的集合,其中每个校准器将其相应分类器的输出映射到 [0, 1]。每对都在 caliblated_classifiers_ 属性中公开,其中每个条目都是一个校准分类器,具有输出校准概率的 Predict_proba 方法。主 CaliberatedClassifierCV 实例的 Predict_proba 输出对应于 caliblated_classifiers_ 列表中 k 个估计器的预测概率的平均值。预测的输出是概率最高的类。
当 ensemble=False 时,交叉验证用于通过 cross_val_predict 获得所有数据的“无偏”预测。然后使用这些无偏预测来训练校准器。属性 caliblated_classifiers_ 仅由一对(分类器、校准器)组成,其中分类器是在所有数据上训练的基本估计器。在这种情况下,CalibrateClassifierCV 的 Predict_proba 输出是从单个(分类器、校准器)对获得的预测概率。
ensemble=True 的主要优点是受益于传统的集成效果(类似于 Bagging 元估计器)。得到的集成应该经过良好校准,并且比 ensemble=False 稍微更准确。使用 ensemble=False 的主要优点是计算性的:它通过仅训练单个基分类器和校准器对来减少总体拟合时间,减小最终模型大小并提高预测速度。
或者,可以通过设置 cv="prefit" 来校准已安装的分类器。在这种情况下,数据不会被分割,所有数据都用于拟合回归器。用户需要确保用于拟合分类器的数据与用于拟合回归器的数据不相交。
CalibratedClassifierCV支持使用两种回归技术通过method参数进行校:"sigmoid"和"isotonic"。
1.16.3.1 sigmoid
sigmoid 回归器method="sigmoid"基于 Platt 的逻辑模型[ 4 ]:
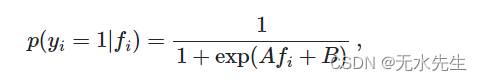
在这里 是样品的真实标签i和
是样本的未校准分类器的输出i。A 和B是通过最大似然拟合回归器时要确定的实数。
sigmoid 方法假设 可以通过将 sigmoid 函数应用于原始预测来校正校准曲线。在 Platt 1999 [ 4 ]的第 2.1 节中,在各种基准数据集上具有通用核函数的支持向量机的情况下,这一假设已得到经验证明,但通常不一定成立。此外,如果校准误差是对称的,则逻辑模型效果最佳,这意味着每个二元类的分类器输出呈具有相同方差的正态分布[ 7 ]。对于高度不平衡的分类问题,这可能是一个问题,其中输出不具有相等的方差。
一般来说,此方法对于小样本量或当未校准模型信心不足并且高输出和低输出具有相似的校准误差时最有效。
1.16.3.2 Isotonic等渗透回归
拟合method="isotonic"一个非参数等渗回归器,它输出一个逐步非递减函数,请参见sklearn.isotonic。它最大限度地减少:

总体而言,当有足够的数据(大于约 1000 个样本)以避免过度拟合时,“isotonic”的性能将与“sigmoid”一样好甚至更好[ 3 ]。
注意事项
对 AUC 等排名指标的影响
通常预计校准不会影响 ROC-AUC 等排名指标。然而,使用时校准后这些指标可能会有所不同 method="isotonic",因为等渗回归在预测概率中引入了联系。这可以被视为在模型预测的不确定性范围内。如果您严格希望保留排名并因此保留 AUC 分数,请使用 method="logistic"严格单调变换,从而保留排名。
1.16.3.3。多类别支持
等渗回归器和 sigmoid 回归器均仅支持一维数据(例如,二元分类输出),但如果base_estimator支持多类预测,则可扩展用于多类分类。对于多类预测, 以OneVsRestClassifier方式CalibratedClassifierCV单独校准每个类[ 5 ]。在预测概率时,分别预测每个类别的校准概率。由于这些概率不一定总和为 1,因此执行后处理以将它们标准化。
例子:
-
概率校准曲线
-
三级分类的概率校准
-
分类器的概率校准
-
分类器校准比较
参考:
References:
[1] Allan H. Murphy (1973). “A New Vector Partition of the Probability Score” Journal of Applied Meteorology and Climatology
[2] On the combination of forecast probabilities for consecutive precipitation periods. Wea. Forecasting, 5, 640–650., Wilks, D. S., 1990a
[3] [Predicting Good Probabilities with Supervised Learning
1.16. Probability calibration — scikit-learn 1.3.2 documentation




资源管理-03)



)










)