数据接入模块
大数据工程的数据来源包含企业内部数据和企业外部数据,其中企业内部数据由资源服务平台、综合资源库、各业务系统生产库中的结构化数据和文件服务器上的文本、图片等非结构化数据组成,其中包括人财物记录、财物报表、原材料、顾客信息、气测数据以及企业的文化和规章制度等;企业外部数据由社会数据、互联网数据和设备采集数据组成,外部数据一般包括地理环境、人口数据、经济市场、金融数据、社会关系、社交数据等等.。
在数据接入之前,首先需要进行数据采集,如图 12 所示:数据采集基于云计算和分布存储之上的采集工具,采用标准化、规范化的抽取模式,实现结构化、半结构化、非结构化资源的统一抽取、整合、加工、转换和装载。数据采集工具主要包括了数据层、接入层、交互层和监控层,其中工具的数据层即涉及整个采集平台中总体架构的数据层即数据支撑层,工具背后的接入层是采集逻辑处理部分,交互层即对应总体架构的采集门户。
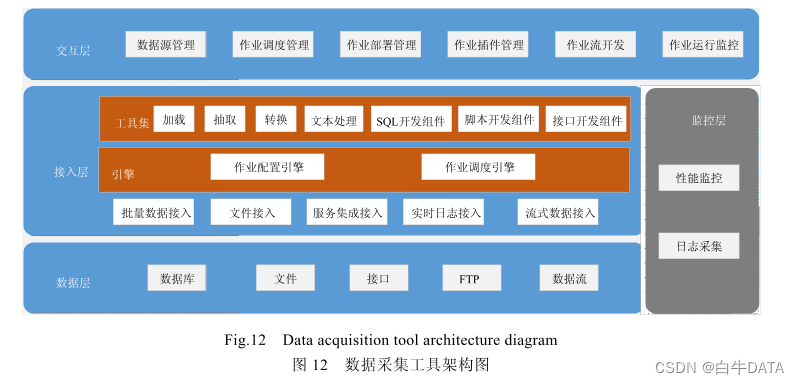
数据层指出企业内部和企业外部数据的主要数据来源方式,数据库可以是指业务系统的 Oracle;文件方式是各种文件或 FTP 接入的文件包;接口主要是用来企业对接外部系统使用的;数据流是指可以使用 Kafka 平台处理的实时数据流式方式这种来源。接入层主要提供丰富的工具集,针对不同的数据接入方式提供相应的工具组件,依赖作业配置引擎和作业调度引擎实现数据抽取。监控层可监控作业执行情况,采集作业日志,对问题作业及时告警,方便后期用户排除故障、维护作业。交互层提供可视化页面便捷地实现数据接入与作业管理。
对采集后各种类型的源数据进行数据抽取,该模型的数据抽取支持 3 种方式:全量抽取、增量抽取、实时抽取,将经过数据抽取后的数据汇入到汇聚库中;对于其他的数据库系统,可以直接通过数据交换平台,把数据汇入到汇聚库中.。
数据治理模块
数据治理模块主要包括对汇聚库中的数据进行数据清洗和数据规范,必要时进行主题划分和数据关联,然后进行数据集成,治理完成后的数据汇聚到数据共享中心中。
数据清洗是对数据进行审查和校验,过滤不合规数据、删除重复数据、纠正错误数据、完成格式转换,并进行清洗前后的数据一致性检查,保证清洗结果集的质量。数据清洗的方法除了以上介绍的几种基本方法以外,该模型还支持自定义清洗规则,数据清洗规则是由业务需求人员与开发人员配合制定数据处理逻辑,经过这些规则进行数据清洗后,保证数据的一致性、准确性和规范性更能满足业务上的需求。
数据服务模块
数据服务模块以数据共享中心构建知识图谱为起点,早在 2006 年,Web 创始人 Berners-Lee 就提出数据链接的思想,随后掀起了语义网络的狂潮,知识图谱在此基础上形成。但是直到 2012 年,知识图谱的概念才被谷歌正式提出。知识图谱是由节点和边组成的巨型知识网络,节点代表实体,边代表实体之间的关系,每个实体还由(key-value)键值对来描述实体的内在特性。新的知识图谱中还增加了实体与实体之间的事件,即边表示关系或事件。
数据服务模块基于知识图谱面向不同用户提供多渠道、多维度的数据服务,面向使用者提供模型管理、智能发现、模型探索、数据探索、数据订阅等数据服务,面向专业人员提供挖掘分析、专家建模等智能数据服务。模型管理主要是对实体、关系进行编辑和处理;智能发现是根据日志等元信息,将配置到系统的数据源反向推导出物理模型关系,将多个异构物理模型归一到同一实体后自动生成语义层的业务视图;模型探索是支持关键词搜索实体、关系等,将搜索结果拖拽到画布探索实体之间以及关系之间的核对关系,用户在了解业务模型的同时,也可以了解到业务模型背后对应的物理模型,以及物理数据表的生产血缘关系;数据探索是对业务模型视图可以进行知识问答式的搜索,在路径的任意节点上设置标签的条件,再在另外的节点上设定对应标签的答案,使得用户对数据的业务关系充分地了解;数据订阅满足外部其他平台对本平台各类数据的需求,通过对不同用户下放的不同权限,再结合数据资源目录服务的开放数据内容,为外部用户提供数据订阅/退订流程,并通过资源总线服务完成最终的数据投递。
专家们可以根据知识图谱中的实体、关系、属性等核心数据进行建模,并进行高层次的数据挖掘分析和加工,可以同知识图谱、数据分析与加工模块(AI)和组织智能(OI)相互交互和协同,实现 HAO智能的大智慧问题求解。
本文引用软件学报吴信东,董丙冰,杨威《数据治理技术》,有删减,有改动,如有侵权,请联系删除。





)


:视频帧处理并用SDL渲染播放)

:从数据中发现洞察力)








真题解析#中国电子学会#全国青少年软件编程等级考试)