
😉😉 学习交流群:
✅✅1:这是孙哥suns给大家的福利!
✨✨2:我们免费分享Netty、Dubbo、k8s、Mybatis、Spring...应用和源码级别的视频资料
🥭🥭3:QQ群:583783824 📚📚 工作微信:BigTreeJava 拉你进微信群,免费领取!
🍎🍎4:本文章内容出自上述:Spring应用课程!💞💞
💞💞5:以上内容,进群免费领取呦~ 💞💞💞💞
第一个Spring应用程序目录
一:第一个Spring程序
1:Spring依赖
2:Spring核心配置文件
(一):Spring配置文件的要求
(二):Spring核心API
二:程序开发
1:Spring核心配置文件
2:Java代码
3:实现思路
4:补充说明
三:细节分析
1:什么叫做Bean或者组件
2:Spring工厂提供的一些方法
3:Bean标签的特殊写法
四:Spring工厂实现问答
一:第一个Spring程序
1:Spring依赖
当前我们都是基于maven进行jar包的管理,我们只需要引入相应的坐标就可以了。maven会自动为我们下载我们所以来的jar包和依赖的依赖进行下载下来,单纯的使用一个Spring的IOC的话,spring-context就够用了,我们使用的版本是spring-context 5.1.4release版本。
一个spring-context一个junit单元测试,对于我们编写第一个Spring程序就够了!
<dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.1.4.RELEASE</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version></dependency>2:Spring核心配置文件
(一):Spring配置文件的要求
任何一个框架都需要进行配置文件,Spring框架的配置文件,不要求具体的放置位置,在项目中都可以,也没有具体的配置名称。但是ApplicationContext.xml是Spring官方推荐的配置名称, 日后应用Spring框架时需要进行配置文件路径的配置,需要告诉Spring我们的配置文件的位置在哪里,在创建对象的时候有体现。
在Spring核心配置文件的根标签是一个Beans标签,在里边引入了Spring的一个默认的Schema【书写提示】,方便进行获取标签中的xml语法书写提示
(二):Spring核心API
ApplicationContext是Spring的核心Api就是指的spring的核心类,这是一个框架最核心的类。这是一个接口。Spring当中最为核心的API就是提出的那个工厂ApplicationContext.java工厂主要作用是对象的创建,他的好处就是解耦合。
为什么spring进行设计的时候会把核心Api设计成接口:
Spring设计工厂的时候会设计成接口,接口的最主要的目的是为了屏蔽实现的差异,提供规范性作者考虑到这个工厂会应用到不同的开发环境(例如web与非web),为了屏蔽具体工厂类型之间的差异,Spring将工厂API设计成了接口,可以屏蔽具体工厂之间的差异,提供规范性。
Spring当中提供的常用的两种工厂类型:
1:非web环境:ClassPathXmlApplicationContext (main junit)
2:web环境: XmlWebApplicationContext
补充说明:
1:以上是Spring中主要提供了两种类型的工厂
2:对于web环境,我们很熟悉,非web英勇主要指的是我们的,main函数和Junit单元测试,在main函数和Junit单元测试里边是不启动服务器的,在main函数和Junit当中和在web当中用到的工厂类是不一样的
3:查看继承关系,idea快捷键是ctrl+h,如果查看继承关系图当中没有这个类的话,是因为没有导入相关的web依赖。添加依赖的快捷键是<dep
为什么ApplicationContext是一个重量级资源
1:ApplicationContext工厂的对象会占用大量内存资源。
2:ApplicationContext工厂对象不会频繁的创建,一个应用只会有一个工厂对象。
3:ApplicationContext工厂一定是线程安全的。
重量级资源都具有以下三种特性:
1:区分一个资源或者对象的轻重量级的区别在于在内存中占用资源的多少,如果一个对象占用内存比较小,就是一个轻量级资源,重量级资源就是会占用大量内存
2:我们在这值得工厂是他的具体的实现类,主要指的是那两种的实现类,我们不会频繁的创建这两个的对象,一个应用只会创建一个工厂对象
3:在一个项目中只有一个这个对象,在一个项目中只会有一个这个对象实例,大家都会访问,那么就会产生比并发访问问题,但凡是这种重量级资源可以被多线程多用户访问,说明他们一定是线程安全的,一定做了锁的设置,它是线程安全的,可以被多线程并发访问

二:程序开发
1:Spring核心配置文件
<!--id属性:起个名字,要求:唯一--><!--class属性:写全限定类名--><bean id = "person" class = "com.pactera.spring.Person"/>2:Java代码
//获取spring的工厂对象,这里我们在单元测试当中指定的是非web工厂。ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");//getBean返回的是Object对象。Person person = (Person)clx.getBean("person");//这里边传入的是id值。System.out.println(person.getClass());
3:实现思路
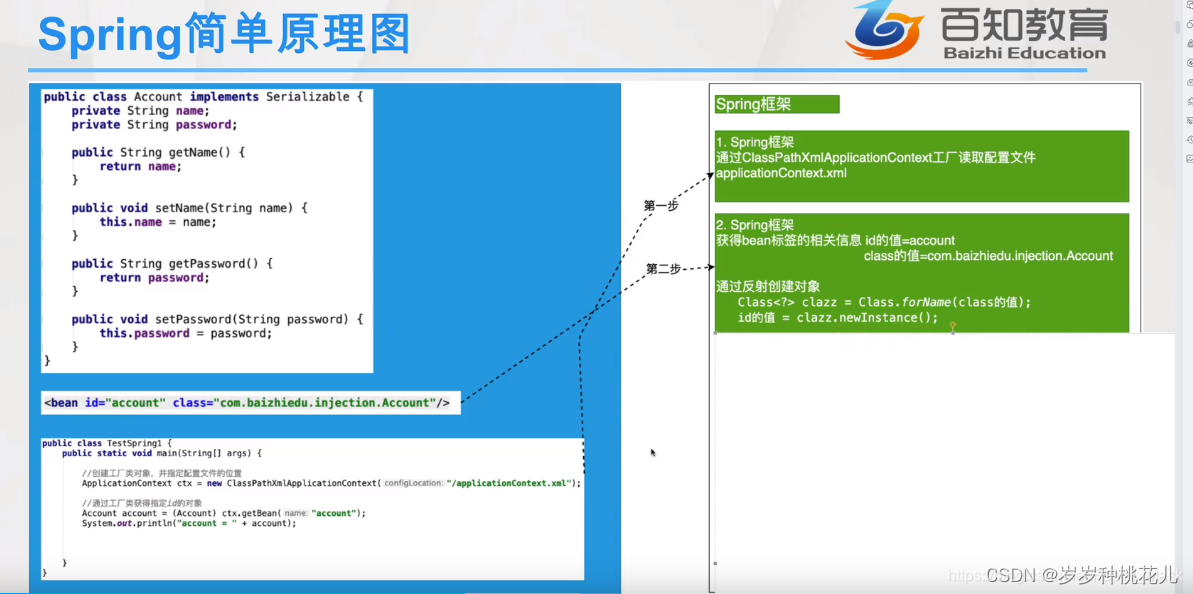
1:创建Bean的类文件。
2:在ApplicationContext.xml文件中配置该对象属性;
3:使用spring原生工厂类获取对象;
4:补充说明
Spring最大的特点就是为我们提供了工厂对象,而这个工厂创建对象起到了一个很好的解耦合的作用,Spring提供的工厂和我们写的工厂本质上是没有区别的,都是创建对象解耦合,对于Spring工厂和通用工厂模式是没有本质区别的
如果在Junit当中进行测试的话,应该使用ClassPathXmlApplicationContext这个类
三:细节分析
1:什么叫做Bean或者组件
Spring工厂为我们创建对象,由spring为我们创建的对象叫做bean或者组件(Component)这些指的都是spring工厂为我们创建的对象
2:Spring工厂提供的一些方法
这些都是Spring工厂为我们提供的获取Bean的方法!
ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");
Person person = (Person)clx.getBean("person");
Person person = clx.getBean("person", Person.class);
Person person1 = clx.getBean(Person.class);package com.pactera.spring;import org.junit.jupiter.api.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;public class TestSpring {/*** 研究目的:用于测试第一个spring的程序。* */@Testpublic void test03(){//获取spring的工厂对象,这里我们在单元测试当中指定的是非web工厂。ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");Person person = (Person)clx.getBean("person");//这里边传入的是id值。System.out.println(person.getClass());}/*** 用于测试Spring工厂为我们提供的其他的方法。* 研究目的:Spring工厂对象核心方法getBean方法的重载。* */@Testpublic void test04(){ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");//这个重载的getBean的方法的好处在于不用进行强制类型转换了。Person person = clx.getBean("person", Person.class);System.out.println("person="+person);//person=com.pactera.spring.Person@2a4fb17bSystem.out.println("person="+person.getClass());//person=class com.pactera.spring.Person//这个重载的getBean的方法的好处在于不用进行强制类型转换了。//如果是这种方式://<bean id = "person" class = "com.pactera.spring.Person"/>//<bean id = "person1" class = "com.pactera.spring.Person"/>//使用getBean(Person.class)会抛出异常,因为无法保证一个唯一性。//使用这个方法的时候必须保证spring配置文件中标签的唯一性。//Person person1 = clx.getBean(Person.class);//expected single matching bean but found 2/*** 在上边创建了一次Person的对象,将这个对象储存了起来,如果下边使用的话直接拿给我们* spring当中的当前这个对象只创建了一次,默认是单例设计模式。* *///System.out.println("person1="+person1);//person1=com.pactera.spring.Person@2a4fb17b//获取spring核心配置文件当中所有的id值;//---bean的定义:就是在spring核心配置文件当中的bean标签就叫做bean的定义//---bean定义的名字就是获取的是:id的值,返回的是是一个名字的数组。String[] beanDefinitionNames = clx.getBeanDefinitionNames();for (String beanDefinitionName : beanDefinitionNames) {System.out.println("beanDefinitionName="+beanDefinitionName);}//根据类型获取spring配置文件当中的所有的id值//---获取工厂类型当中所有Person类的值。获取的都是idString[] beanNamesForType = clx.getBeanNamesForType(Person.class);for (String id : beanNamesForType) {System.out.println("id="+id);}//判断spring工厂中是否存在这个bean,参数传入的是id值;boolean b = clx.containsBeanDefinition("a");System.out.println("b="+b);//判断spring工厂中是否存在指定id的beanSystem.out.println(clx.containsBean("person"));//目前角度来讲这两个方法是没啥区别的。}/*** 研究目的:在spring核心配置文件中的bean标签当中值配置class,spring可以不可以创建对象。* :可以* :spring会不会为他默认分配一个id值呢?* :会,默认是 全限定名+#+num,这个id是spring按照一定的算法生成的。这个num是因为在* 配置文件当中可能默认不止配置一次。* 应用场景:如果这个bean只使用一次,那么就可以省略id值,如果这个bean会被使用多次,或者被其他bean* 就需要进行设置。* 研究目的2:name属性在spring配置文件中的使用* :为bean对象定义别名,小名。id是大名,是唯一标识,name属性定义的内容是别名,是小名,* spring当中通过大名和小名都是找到这个bean对象的,可以获取到这个bean对象。* */@Testpublic void test05(){ApplicationContext ctx = new ClassPathXmlApplicationContext("/applicationContext.xml");Person person = ctx.getBean(Person.class);System.out.println("person="+person);//person=com.pactera.spring.Person@128d2484String[] beanDefinitionNames = ctx.getBeanDefinitionNames();for (String beanDefinitionName : beanDefinitionNames) {System.out.println("beanDefinitionName="+beanDefinitionName);//beanDefinitionName=com.pactera.spring.Person#0}}/***研究目的2:name属性在spring配置文件中的使用* :为bean对象定义别名,小名。id是大名,是唯一标识,name属性定义的内容是别名,是小名,* spring当中通过大名和小名都是找到这个bean对象的,可以获取到这个bean对象。*应用场景:id和name有共性,他们相同的地方在于都能使用获取对象,相同的地方在于<bean id,class/>等效与* <bean name,class/>都可以定义一个对象。* :区别在于别名可以定义多个,别名之间用,间隔就可以了使用任何一个别名都可以找到这个。,id只能定义一个,* applicationContext.xml(xml语法导致的区别)这个文件当中id属性值命名的时候必须以字母开头,后面可以根字母、数字、下划线、连字符。* name属性定义的时候比较灵活没有要求,可以明明在特殊场景下,比方说\的使用* 到了今天xml里的id属性的限制已经不存在了,已经没有这个约束了。* :区别当中的类的 containsBeanDefinition()和containsBean;** */@Testpublic void test06(){ApplicationContext ctx = new ClassPathXmlApplicationContext("/applicationContext.xml");Person person = (Person)ctx.getBean("p");System.out.println("person="+person);//person=com.pactera.spring.Person@2a4fb17bPerson person1 = (Person)ctx.getBean("p",Person.class);System.out.println("person1="+person1);//person=com.pactera.spring.Person@2a4fb17bboolean p1 = ctx.containsBean("p1");//既能判断id也能判断name属性。System.out.println(p1);//trueboolean p11 = ctx.containsBeanDefinition("p1");//只能判断id,不能判断name值。System.out.println(p11);//false}
}
3:Bean标签的特殊写法
1.只配置class属性不配置id属性
<bean class = "..."/>这样是可以的,spring会默认分配一个默认的id值,格式一般是全限定类名+特殊符号+num
四:Spring工厂实现问答
为什么我们应用了Spring工厂实现类,写了类搞了配置之后,就可以通过工厂创建对象呢?
当我们定义好类,在applicationContext.xml配置文件中配置好Bean标签之后,创建工厂对象就可以获取相应的配置文件中的对象配置,Spring在Junit或者main方法的程序入口执行之后,创建工厂类对象的时候,Spring会读取applicationContext.xml配置文件,读取之后获取每个bean标签的id和class,根据class采用反射的方式获取对象,并将引用地址赋值给id属性,随后可以通过Spring工厂对象中重载的getBean的方法进行获取对应的对象引用
反射创建对象调用不调用这个类的构造方法呢?
一定会的,默认调用的是无参的构造方法。验证方法:在无参构造方法内部加入一个打印语句就可以了。虽然反射创建了对象,但是反射创建对象其实等效于new创建对象,底层也会调用new来创建对象。反射的底层调用的这个对象的无参构造方法
如果一个类的构造方法是私有的怎么办呢?
private修饰的内容只可以在本类中进行使用,如果构造器是private的,spring也能够创建对象,实际上底层通过反射调用私有的属性或者方法的,在反射中私有的内容也可以通过暴力反射的方式进行获取
在开发过程中,是不是所有的对象都会交由spring进行创建?
理论上来讲是这样的,但是有特例:实体对象(entity)这个对象中的属性是和数据库进行一一对应的,他的对象往往用于封装数据库中的数据,所以一般实体类对象都是交由Mybatis、hibernate等持久层框架进行创建。
😉😉 学习交流群:
✅✅1:这是孙哥suns给大家的福利!
✨✨2:我们免费分享Netty、Dubbo、k8s、Mybatis、Spring...应用和源码级别的视频资料
🥭🥭3:QQ群:583783824 📚📚 工作微信:BigTreeJava 拉你进微信群,免费领取!
🍎🍎4:本文章内容出自上述:Spring应用课程!💞💞
💞💞5:以上内容,进群免费领取呦~ 💞💞💞💞




)
003)






)

HTTPS协议(加密解密+中间人攻击+证书))




LinkedList的常见使用)