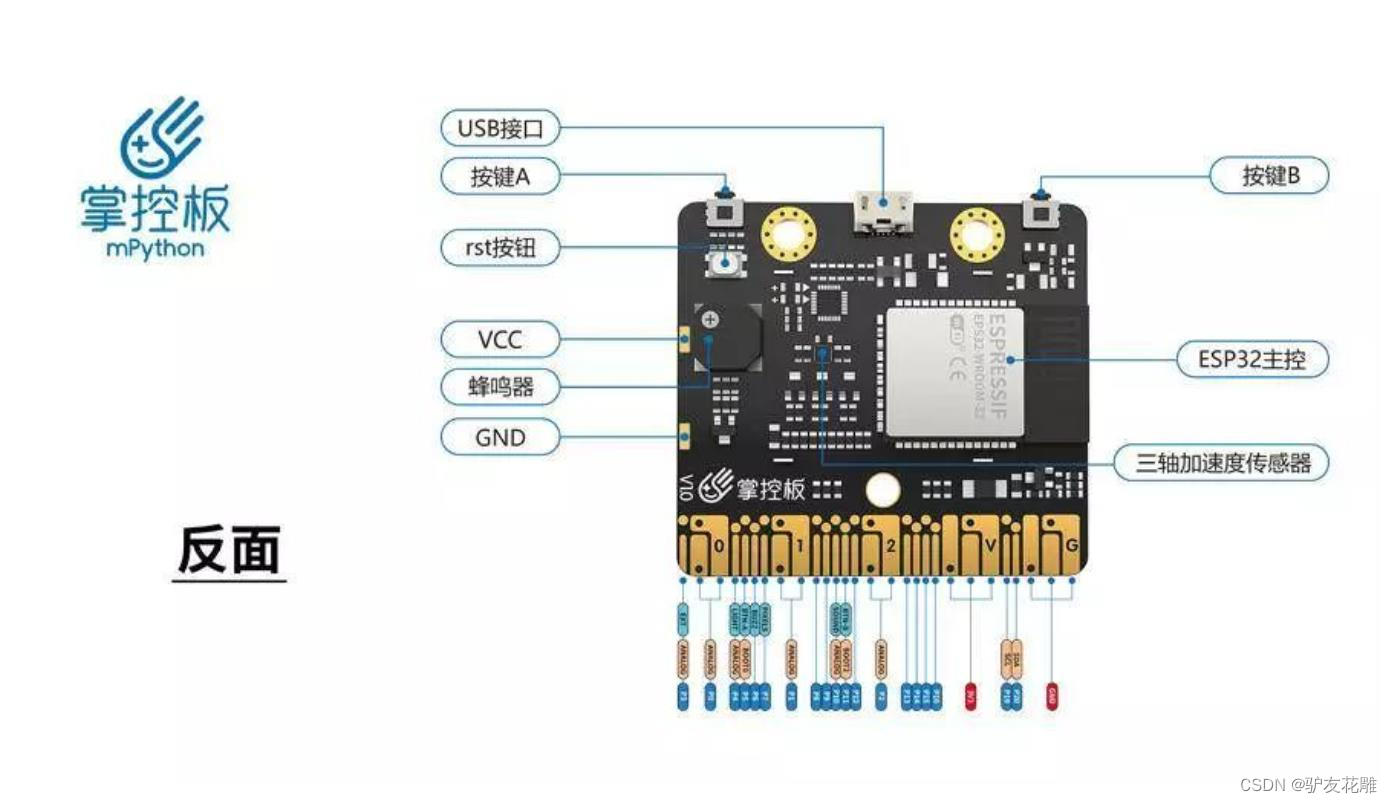
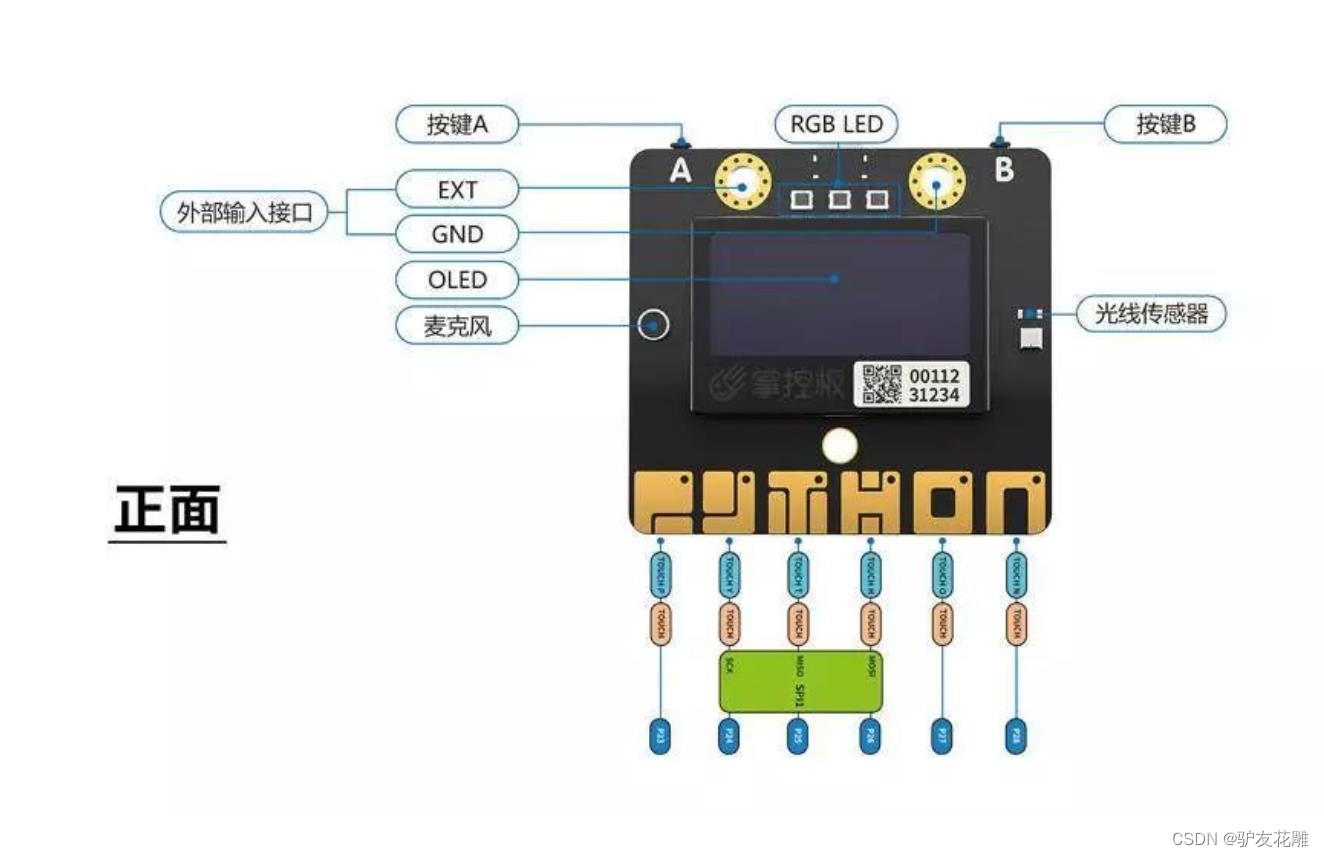
知识点:什么是掌控板?
掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED显示屏、RGB灯、加速度计、麦克风、光线传感器、蜂鸣器、按键开关、触摸开关、金手指外部拓展接口,支持图形化及MicroPython代码编程,可实现智能机器人、创客智造作品等智能控制类应用。

1、TTS(Text-To-Speech,文本到语音)
TTS是Text To Speech的缩写,即“从文本到语音”,是人机对话的一部分,将文本转化问文字,让机器能够说话。我们比较熟悉的ASR(Automatic Speech Recognition),是将声音转化为文字,可类比于人类的耳朵。而TTS是将文字转化为声音(朗读出来),类比于人类的嘴巴,是人机对话的一部分,让机器能够说话。
TTS是同时运用语言学和心理学的杰出之作,在内置芯片的支持之下,通过神经网络的设计,把文字智能地转化为自然语音流。TTS技术对文本文件进行实时转换,转换时间之短可以秒计算。在其特有智能语音控制器作用下,文本输出的语音音律流畅,使得听者在听取信息时感觉自然,毫无机器语音输出的冷漠与生涩感。TTS语音合成技术 [1] 即将覆盖国标一、二级汉字,具有英文接口,自动识别中、英文,支持中英文混读。所有声音采用真人普通话为标准发音,实现了120-150个汉字/分钟的快速语音合成,朗读速度达3-4个汉字/秒,使用户可以听到清晰悦耳的音质和连贯流畅的语调。有少部分MP3随身听具有了TTS功能。

附:什么是人工智能?
顾名思义就是由人创造的"智慧能力",具备听说看理解等能力。
听 ==语音识别
说 ==语音合成
看 ==图像视频文字识别
理解 ==语言(文字)图像视频理解等逻辑处理
思考 ==理解后的逻辑处理
2、语音合成(SpeechSynthesis)
语音合成,能将任意文字信息实时转化为标准流畅的语音朗读出来,相当于给机器装上了人工嘴巴。它涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术,解决的主要问题就是如何将文字信息转化为可听的声音信息,也即让机器像人一样开口说话。我们所说的“让机器像人一样开口说话”与传统的声音回放设备(系统)有着本质的区别。传统的声音回放设备(系统),如磁带录音机,是通过预先录制声音然后回放来实现“让机器说话”的。这种方式无论是在内容、存储、传输或者方便性、及时性等方面都存在很大的限制。而通过计算机语音合成则可以在任何时候将任意文本转换成具有高自然度的语音,从而真正实现让机器“像人一样开口说话”。
语音合成是通过机械的、电子的方法产生人造语音的技术。TTS技术(又称文语转换技术)隶属于语音合成,它是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术。TTS将储存于电脑中的文件,如帮助文件或者网页,转换成自然语音输出。TTS不仅能帮助有视觉障碍的人阅读计算机上的信息,更能增加文本文档的可读性。TTS应用包括语音驱动的邮件以及声音敏感系统,并常与声音识别程序一起使用。语音合成满足将文本转化成拟人化语音的需求,打通人机交互闭环。 提供多种音色选择,支持自定义音量、语速,让发音更自然、更专业、更符合场景需求。语音合成广泛应用于语音导航、有声读物、机器人、语音助手、自动新闻播报等场景,提升人机交互体验,提高语音类应用构建效率。

3、TTS一般分为两个步骤
(1) 文本处理。这一步做的事情是把文本转化成音素序列,并标出每个音素的起止时间、频率变化等信息。作为一个预处理步骤,它的重要性经常被忽视,但是它涉及到很多值得研究的问题,比如拼写相同但读音不同的词的区分、缩写的处理、停顿位置的确定,等等。
(2)语音合成。狭义上这一步专指根据音素序列(以及标注好的起止时间、频率变化等信息)生成语音,广义上它也可以包括文本处理的步骤。这一步主要有三类方法:
a、拼接法,即从事先录制的大量语音中,选择所需的基本单位拼接而成。这样的单位可以是音节、音素等等;为了追求合成语音的连贯性,也常常用使用双音子(从一个音素的中央到下一个音素的中央)作为单位。拼接法合成的语音质量较高,但它需要录制大量语音以保证覆盖率。
b、参数法,即根据统计模型来产生每时每刻的语音参数(包括基频、共振峰频率等),然后把这些参数转化为波形。参数法也需要事先录制语音进行训练,但它并不需要100%的覆盖率。参数法合成出的语音质量比拼接法差一些。
c、声道模拟法。参数法利用的参数是语音信号的性质,它并不关注语音的产生过程。与此相反,声道模拟法则是建立声道的物理模型,通过这个物理模型产生波形。这种方法的理论看起来很优美,但由于语音的产生过程实在是太复杂,所以实用价值并不高。

4、在讯飞开放平台注册
TTS是Text To Speech的缩写,即“从文本到语音”,是人机对话的一部分,将文本转化问文字,让机器能够说话。
掌控拓展板的在线语音合成功能是使用 讯飞在线语音合成API(https://www.xfyun.cn/services/online_tts) ,用户在使用该功能前,需要在讯飞开放平台注册并做相应的配置。
步骤1.在讯飞 https://www.xfyun.cn 注册账号。

步骤2.创建新应用,应用平台选择"WebAPI"

步骤3.添加"在线语音合成"服务,且在程序中传入APPID、APIKey实例 TTS ,获取自己的公网IP(http://www.ip138.com)并添加到IP白名单。
注意
在调用该业务接口时,授权认证通过后,服务端会检查调用方IP是否在讯飞开放平台配置的IP白名单中,对于没有配置到白名单中的IP发来的请求,服务端会拒绝服务。
IP白名单,在 控制台-我的应用-相应服务的应用管理卡片上 编辑,保存后五分钟左右生效。
每个IP白名单最多可设置5个IP,IP为外网IP,请勿设置局域网IP。

5、文字转语音
#MicroPython动手做(25)——语音合成与语音识别
#测试文字转语音
注意
TTS功能依赖网络,使用是注意先连接网络并保持网络通畅!
首先使用 ntptime.settime() 校准RTC时钟。
然后 player_init() 初始化。
用 xunfei_tts_config(api_key, appid ) , appid , api_key 为必选参数,在讯飞平台的应用的APPID、API_KET 。
然后使用 xunfei_tts(text) 将文本转为语音并播放。
TTS支持中英文的文本转换。你可以将你想要说话的内容,通过文本的形式转化为语音。这样你就可以给你掌控板添上“人嘴”,模拟人机对话场景。

#MicroPython动手做(25)——语音合成与语音识别
#测试文字转语音from mpython import *
import network
import ntptime
from xunfei import *
import audiomy_wifi = wifi()my_wifi.connectWiFi("zh", "zy1567")while True:try:ntptime.settime(8, "time.windows.com")breakexcept:pass
Text = "掌控板TTS文字转语音以及语音识别"
Audio = "tts.pcm"
speech_tts = Xunfei_speech("5ec66b", "5d32b259f15b2902d81b9efd22926", "3aace39c0ecea76ef46a200300826", mode=MODE_TTS, AudioFile=Audio, Text=Text)
print("Processing, please wait....")
speech_tts.tts()
audio.player_init()
audio.set_volume(100)
audio.play(Audio)运行程序后,一直出错,换成2.0版掌控板,又重刷固件,仍是不行。后来偶然发现,讯飞开发平台有个IP白名单,需要保持更新(每次打开电脑的IP地址是随机分配的),否则无法使用WebAPI调用方式。
核查IP https://www.ip138.com/

mPython X 图形编程

MicroPython动手做(25)——语音合成与语音识别
#测试文字转语音(视频)
https://v.youku.com/v_show/id_XNDY4MjQyODY0MA==.html?spm=a2h0c.8166622.PhoneSokuUgc_1.dtitle

6、AB按键切换语言合成项目
#MicroPython动手做(25)——语音合成与语音识别
#AB按键切换语言合成项目from mpython import *
import network
import time
import ntptime
from xunfei import *
import audiomy_wifi = wifi()my_wifi.connectWiFi("zh", "zy1567")def on_button_a_down(_):global Audio, Texttime.sleep_ms(10)if button_a.value() == 1: returnrgb[0] = (int(102), int(0), int(0))rgb.write()time.sleep_ms(1)Text = "A键被按下"Audio = "tts.pcm"speech_tts = Xunfei_speech("5ec66b", "5d32b259f15b2902d81b9efd22926", "3aace39c0ecea76ef46a200300826", mode=MODE_TTS, AudioFile=Audio, Text=Text)print("Processing, please wait....")speech_tts.tts()oled.fill(0)oled.DispChar(" A键被按下", 0, 16, 1)oled.show()audio.player_init()audio.set_volume(120)audio.play(Audio)time.sleep(2)oled.fill(0)rgb[0] = (0, 0, 0)rgb.write()time.sleep_ms(1)oled.show()def on_button_b_down(_):global Audio, Texttime.sleep_ms(10)if button_b.value() == 1: returnrgb[2] = (int(102), int(0), int(0))rgb.write()time.sleep_ms(1)Text = "B键被按下"Audio = "tts.pcm"speech_tts = Xunfei_speech("5ec66b", "5d32b259f15b2902d81b9efd22926", "3aace39c0ecea76ef46a200300826", mode=MODE_TTS, AudioFile=Audio, Text=Text)print("Processing, please wait....")speech_tts.tts()oled.fill(0)oled.DispChar(" B键被按下", 0, 16, 1)oled.show()audio.player_init()audio.set_volume(120)audio.play(Audio)time.sleep(2)oled.fill(0)rgb[2] = (0, 0, 0)rgb.write()time.sleep_ms(1)oled.show()button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down)button_b.irq(trigger=Pin.IRQ_FALLING, handler=on_button_b_down)rgb[1] = (int(0), int(51), int(0))
rgb.write()
time.sleep_ms(1)
while True:try:ntptime.settime(8, "time.windows.com")breakexcept:pass
mPython X 图形编程









(视频讲解A——D))










