👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

Python将100个PDF文件对应的json文件存储到MySql数据库(源码)
目录
- Python将100个PDF文件对应的json文件存储到MySql数据库(源码)
- 1. 需求描述
- 2. 结果展示
- 3. 代码分析
- 3. 1 导入模块
- 3.2 数据库配置
- 3.3 数据库连接
- 3.4 创建数据库表
- 3.5 数据插入函数
- 3.6 加载和处理JSON数据
- 3.7数据检索函数
- 1.8 示例检索和清理
- 部分代码
1. 需求描述
给100篇PDF文件与其一一对应的json文件,假定这一百篇PDF文件存储于D盘的名为100PDF的文件夹中,json文件存储在D盘名为100JSON的文件夹中。
要求:
1.利用python对接数据库,将这100篇PDF和对应的JSON文件存储在名为Mypdf的数据库中。
2.写一段python代码,能够调用这100篇 PDF和其对应的JSON文件。
100_PDF_MetaData.json 部分内容如下:
{"elsevier_05cbcb9ef5629bc25e84df43572f9d1eddb9a35f": {"date": "1981-12-01T00:00:00","ref_paper": [],"conference": "","keywords": [],"year": 1981,"author": {"affiliation": ["Chemistry Department, B-017, University of California at San Diego, La Jolla, CA 92093 U.S.A.","Chemistry Department, B-017, University of California at San Diego, La Jolla, CA 92093 U.S.A."],"name": ["R.W. Carlson","G.W. Lugmair"]},"last_page": 8,"link": "https://www.sciencedirect.com/science/article/abs/pii/0012821X81901126","abstract": "Pristine samples from the lunar highlands potentially offer important information bearing on the nature of early crustal development on all the terrestrial planets. One apparently unique sample of this group of lunar crustal rocks, the feldspathic lherzolite 67667, was studied utilizing the Sm-Nd radiometric system in an attempt to define its age and the implications of that age for the evolution of the lunar highlands. Data for 67667 precisely define an isochron corresponding to an age of 4.18\u00b10.07 AE. The observed lack of disturbance of the Sm-Nd system of this sample may suggest that this time marks its crystallization at shallow depth in the lunar crust. However, the possibility that this age, as well as those of other highland rocks, indicate the time of their impact-induced excavation from regions deep enough in the lunar crust to allow subsolidus isotopic equilibrium to be produced or maintained between their constituent minerals is also considered. Taken together, bulk rock Sm-Nd data for four \u201chigh-Mg\u201d rocks, including 67667, indicate that the chemical characteristics of all their source materials were established 4.33\u00b10.08 AE ago and were intimately associated with the parent materials of KREEP. This finding provides more support for the concept of a large-scale differentiation episode early in lunar history. The possible roles of the crystallization of a global magma ocean, endogenous igneous activity, and of planetesimal impact, in producing the observed geochemical and chronological aspects of lunar highland rocks are discussed.","title": "Sm-Nd age of lherzolite 67667: implications for the processes involved in lunar crustal formation","paper_id": "elsevier_05cbcb9ef5629bc25e84df43572f9d1eddb9a35f","volume": 56,"update_time": "2022-07-16T14:06:08.117141","journal": "Earth and Planetary Science Letters","issn": "0012-821X","first_page": 1,"publisher": "elsevier","doi": "10.1016/0012-821X(81)90112-6"},....略...}
pdf文档内容如下:
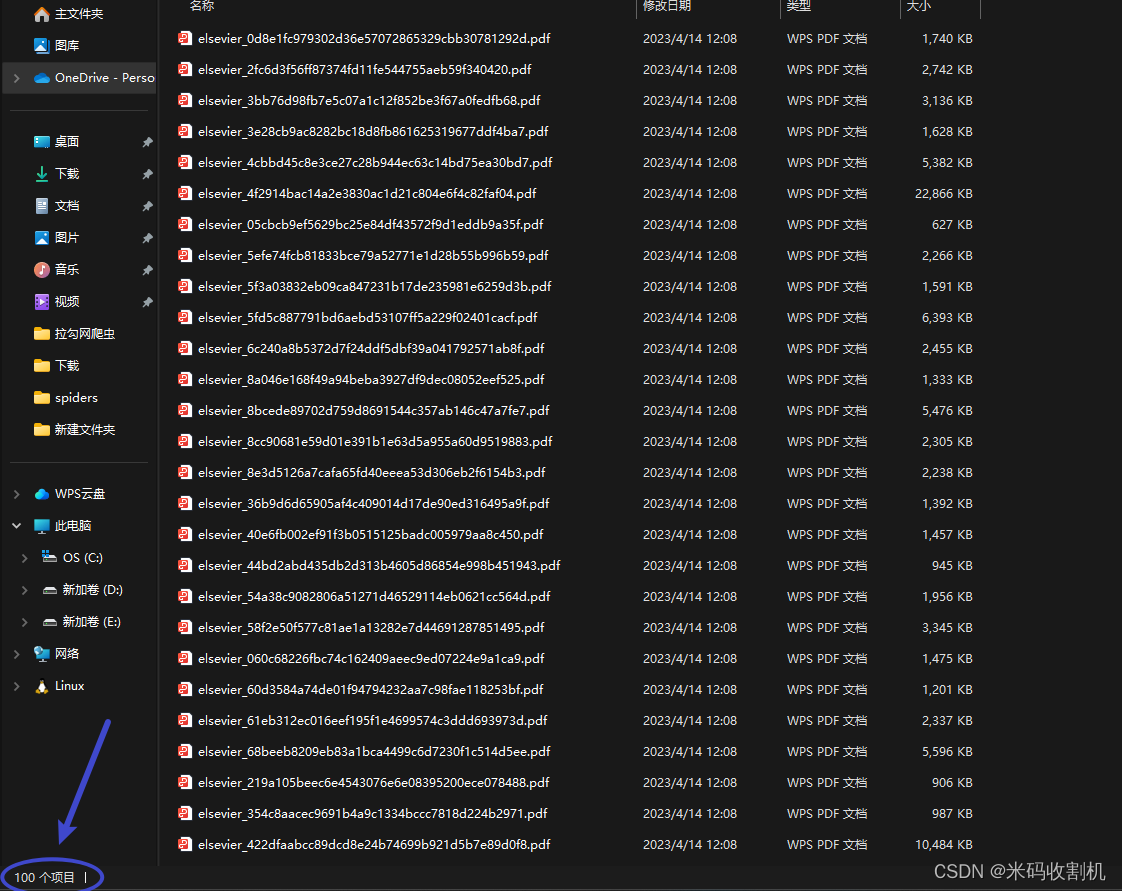
2. 结果展示
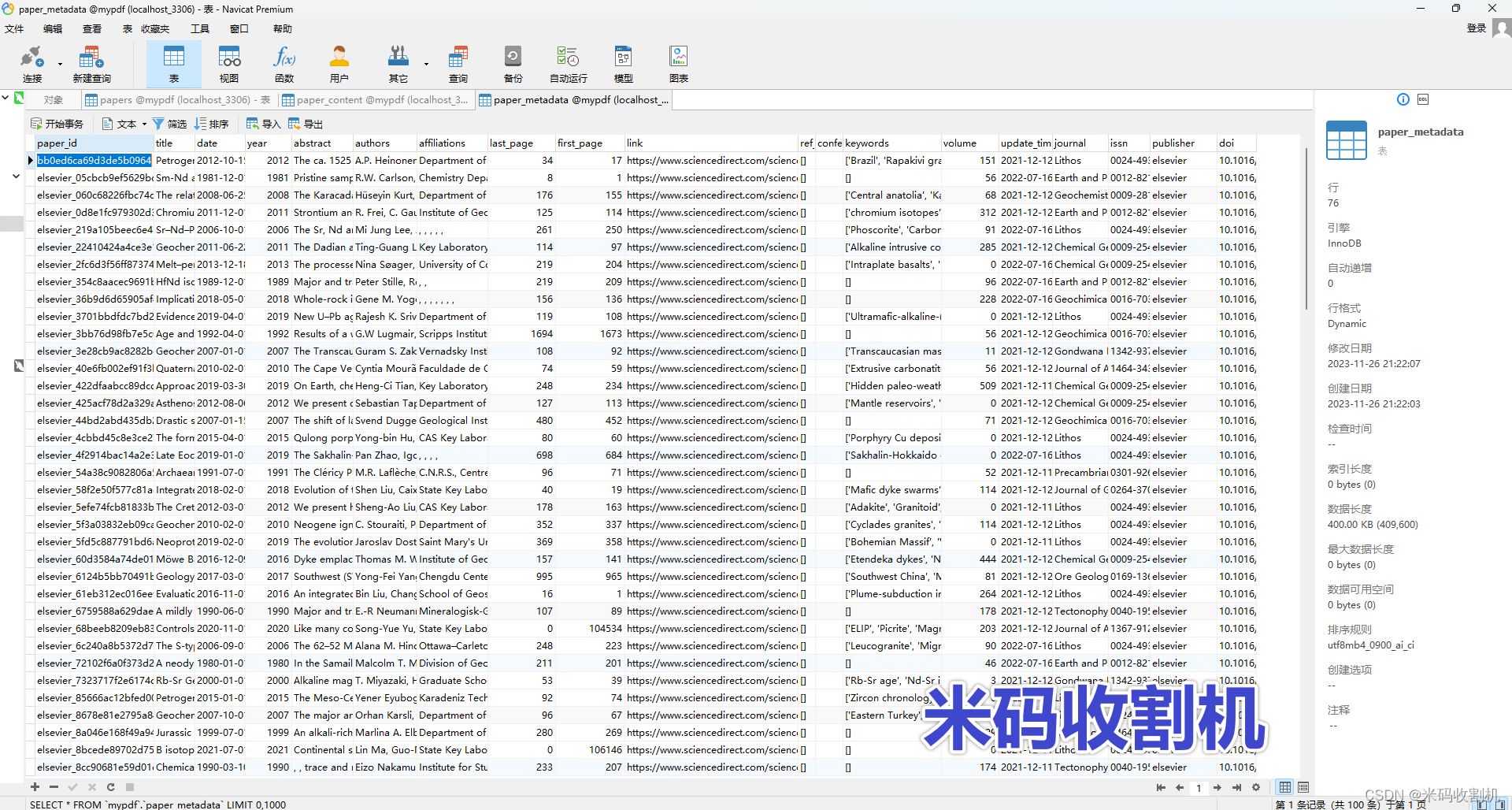
json数据表:
关注公众号,回复 “PDF数据库存储” 获取源码👇👇👇
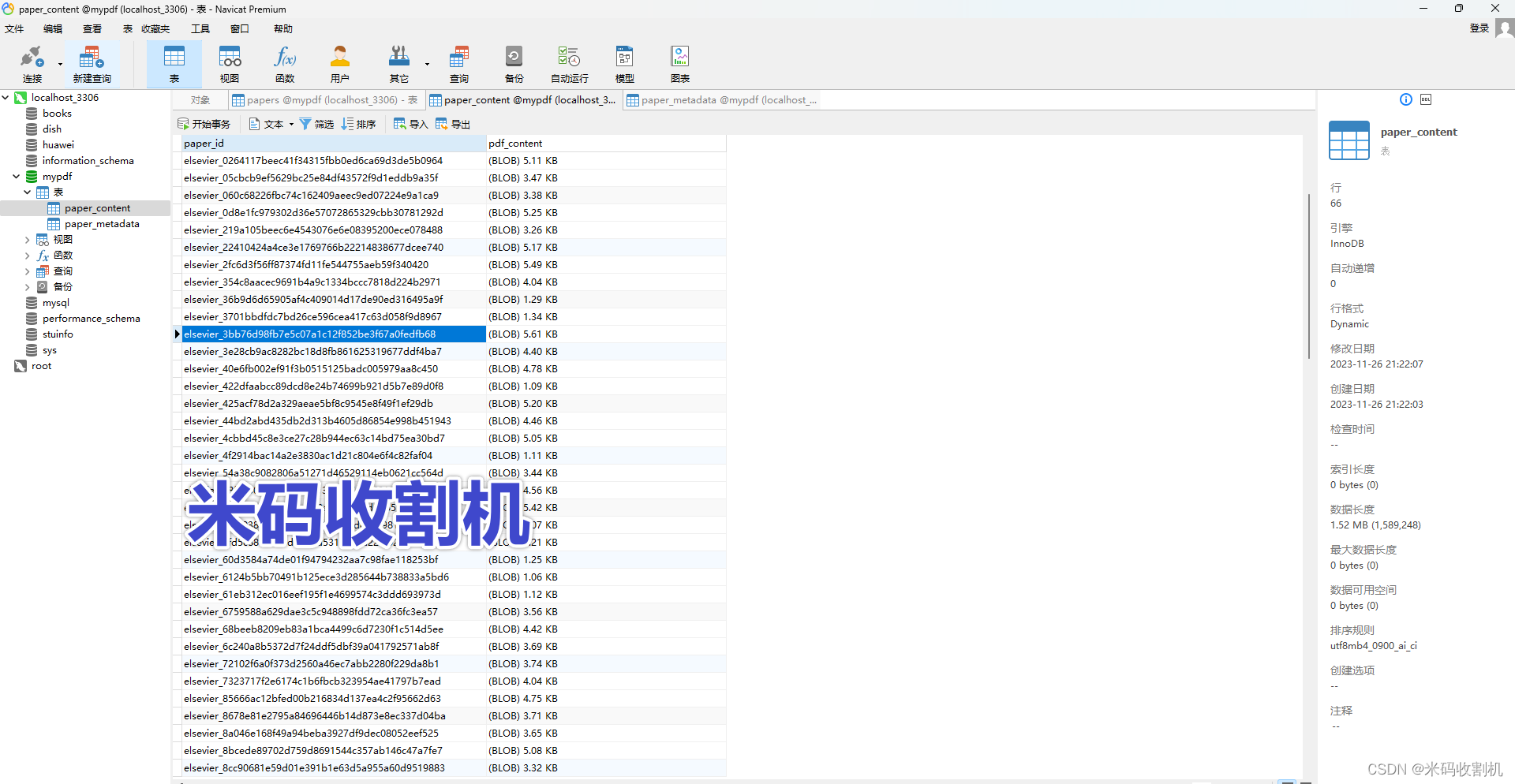
论文内容数据表:
关注公众号,回复 “PDF数据库存储” 获取源码👇👇👇
3. 代码分析
当然,让我们更详细地分析这段代码的每个部分:
3. 1 导入模块
os:用于文件和目录操作,如遍历目录和打开文件。pymysql:一个Python库,用于连接和操作MySQL数据库。PyPDF2:Python库,用于读取PDF文件。json:内置库,用于处理JSON数据,这里主要用于读取JSON文件。
3.2 数据库配置
db_config:一个字典,包含连接MySQL数据库所需的信息(如主机、用户、密码、数据库名)。
3.3 数据库连接
- 使用
pymysql.connect建立到MySQL的连接。 cursor对象用于执行SQL命令。
3.4 创建数据库表
CREATE TABLESQL语句被用来创建两个表:paper_metadata(存储论文的元数据)和paper_content(存储论文的PDF内容)。IF NOT EXISTS确保如果表已存在,不会重复创建。
3.5 数据插入函数
insert_metadata:将JSON中的元数据插入paper_metadata表。这里处理了如作者、出版日期等多种字段。insert_content:将PDF文件的内容插入paper_content表。这里只提取了PDF的第一页内容。- 使用
cursor.execute来执行SQL插入命令,并且在每次插入后调用connection.commit来提交事务。
3.6 加载和处理JSON数据
- 从指定路径加载JSON文件,其中包含与PDF文件相关联的元数据。
- 遍历一个特定目录中的PDF文件,使用
PyPDF2读取每个文件,提取第一页内容。 - 对于每个PDF,如果它的ID在JSON元数据中,它的内容和元数据将被插入到数据库中。
3.7数据检索函数
retrieve_data:根据paper_id从paper_metadata和paper_content表中检索信息。- 使用
cursor.execute执行查询,并通过cursor.fetchone获取结果。
1.8 示例检索和清理
- 使用
retrieve_data函数来检索特定paper_id的数据。 - 如果找到数据,它将被打印出来;如果没有,会打印一条消息表示没有找到数据。
- 最后,代码清理部分关闭了数据库游标和连接。
部分代码
部分代码如下:
import os
import pymysql
from PyPDF2 import PdfReader
import json# 数据库配置
db_config = {'host': '127.0.0.1','user': 'root','password': 'root','database': 'Mypdf'
}# 连接数据库
connection = pymysql.connect(**db_config)
cursor = connection.cursor()# 创建表格 - paper_metadata
cursor.execute("""CREATE TABLE IF NOT EXISTS paper_metadata (paper_id VARCHAR(255) PRIMARY KEY,# ...略....)
""")# 创建表格 - paper_content
cursor.execute("""...略(源码关注公众号:测试开发自动化, 回复 “PDF数据库存储” 获取)
""")# 插入数据的函数 - paper_metadata
def insert_metadata(paper_id, json_data):query = """INSERT INTO paper_metadata (paper_id, title, date, year, abstract, authors, affiliations, last_page, first_page, link, ref_paper, conference, keywords, volume, update_time, journal, issn, publisher, doi)VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""authors = ', '.join(json_data['author']['name'])affiliations = ', '.join(json_data['author']['affiliation'])cursor.execute(query, (paper_id, json_data['title'], json_data['date'], json_data['year'], json_data['abstract'], authors, affiliations, json_data['last_page'], json_data['first_page'], json_data['link'], str(json_data['ref_paper']), json_data['conference'], str(json_data['keywords']), json_data['volume'], json_data['update_time'], json_data['journal'], json_data['issn'], json_data['publisher'], json_data['doi']))connection.commit()...略# 检索数据的函数
def retrieve_data(paper_id):# 查询metadata表query_metadata = "SELECT * FROM paper_metadata WHERE paper_id = %s"# ...略# 查询content表query_content = "SELECT pdf_content FROM paper_content WHERE paper_id = %s"# ...略# 检索数据的示例
result = retrieve_data("elsevier_05cbcb9ef5629bc25e84df43572f9d1eddb9a35f")
if result:print(result)
else:print("No data found for this paper ID.")# 关闭连接
cursor.close()
connection.close()
关注公众号,回复 “PDF数据库存储” 获取源码👇👇👇








![[leetCode]257. 二叉树的所有路径(两种方法)](http://pic.xiahunao.cn/[leetCode]257. 二叉树的所有路径(两种方法))






在WSL单机搭建Kafka伪集群)
 文本结构和事件)


