1.什么是内存池
内存池·动态内存分配与管理技术,对于程序员来说,通常情况下,动态申请内存需要使用new,delete,malloc,free这些API来申请,这样导致的后果是,当程序长时间运行之后,由于程序运行时所申请的内存大小不定,频繁使用将会导致大量的内存碎片,进而降低程序的运行效率问题,减少程序和操作系统的性能。所以,我们引入了内存池的概念,内存池则是在真正使用内存之前,就向操作系统申请一大块内存留住备用,当程序员动态申请的时候,就向内存池申请内存,当释放内存的时候,就将释放的内存放到内存池里面,再次申请池可以 再取出来使用,并尽量与周边的空闲内存块合并。若内存池不够时,则自动扩大内存池,从操作系统中申请更大的内存池。直到程序结束,将所用内存还给操作系统。
2.内存池的作用
为什么需要内存池
1.解决内存碎片问题:
内存碎片分为外碎片和内碎片,外碎片是频繁地向操作系统申请内存,释放内存,导致内存不连续,内存不连续导致我们虽然有内存但是由于内存小于我们需要的,而导致我们无法使用,内碎片由于我们在动态申请内存的时候,由于内存对齐的原因,导致我们实际申请的内存大于等于我们实际需要的内存,这样就会导致多出来的内存无法使用,造成资源的浪费。为了解决内存碎片问题,就需要用到内存池来解决;
2.解决效率问题:
由于频繁的申请和释放内存,将会导致程序运行下降和操作系统性能下降,这样会减少效率,所以使用池化技术以提高程序的运行效率问题。
3.内存池的设计
1.教科书上的内存分配器:
做一个链表指向空闲内存,分配时就取出一块内存,释放时就还回去一块内存,并做还归并,做好标记好保护,避免二次释放,减小内存碎片。
优点:简单易实现
缺点:分配时搜索合适的内存块效率低,释放回归内存后归并消耗大,实际中不实用
2.定长内存池
即实现一个 FreeList,每个 FreeList 用于分配固定大小的内存块,比如用于分配 32字节对象的固定内存分配器,之类的。每个固定内存分配器里面有两个链表,OpenList 用于存储未分配的空闲对象,CloseList用于存储已分配的内存对象,那么所谓的分配就是从 OpenList 中取出一个对象放到 CloseList 里并且返回给用户,释放又是从 CloseList 移回到 OpenList。分配时如果不够,那么就需要增长 OpenList:申请一个大一点的内存块,切割成比如 64 个相同大小的对象添加到OpenList中。这个固定内存分配器回收的时候,统一把先前向系统申请的内存块全部还给系统。
优点:简单粗暴,分配和释放效率高,解决实际场景下的问题有效。缺点:应有场景单一,只能解决定长内存问题,另外占着内存没有释放。
比如:
代码实现:http://t.csdnimg.cn/I9qae 定长内存池问题
3.我们的重点目标:实现并发内存池concurrent memory pool
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。所以这次我们实现的内存池需要考虑以下几方面的问题:
- 内存碎片为题
- 性能问题
- 多线程下锁竞争问题
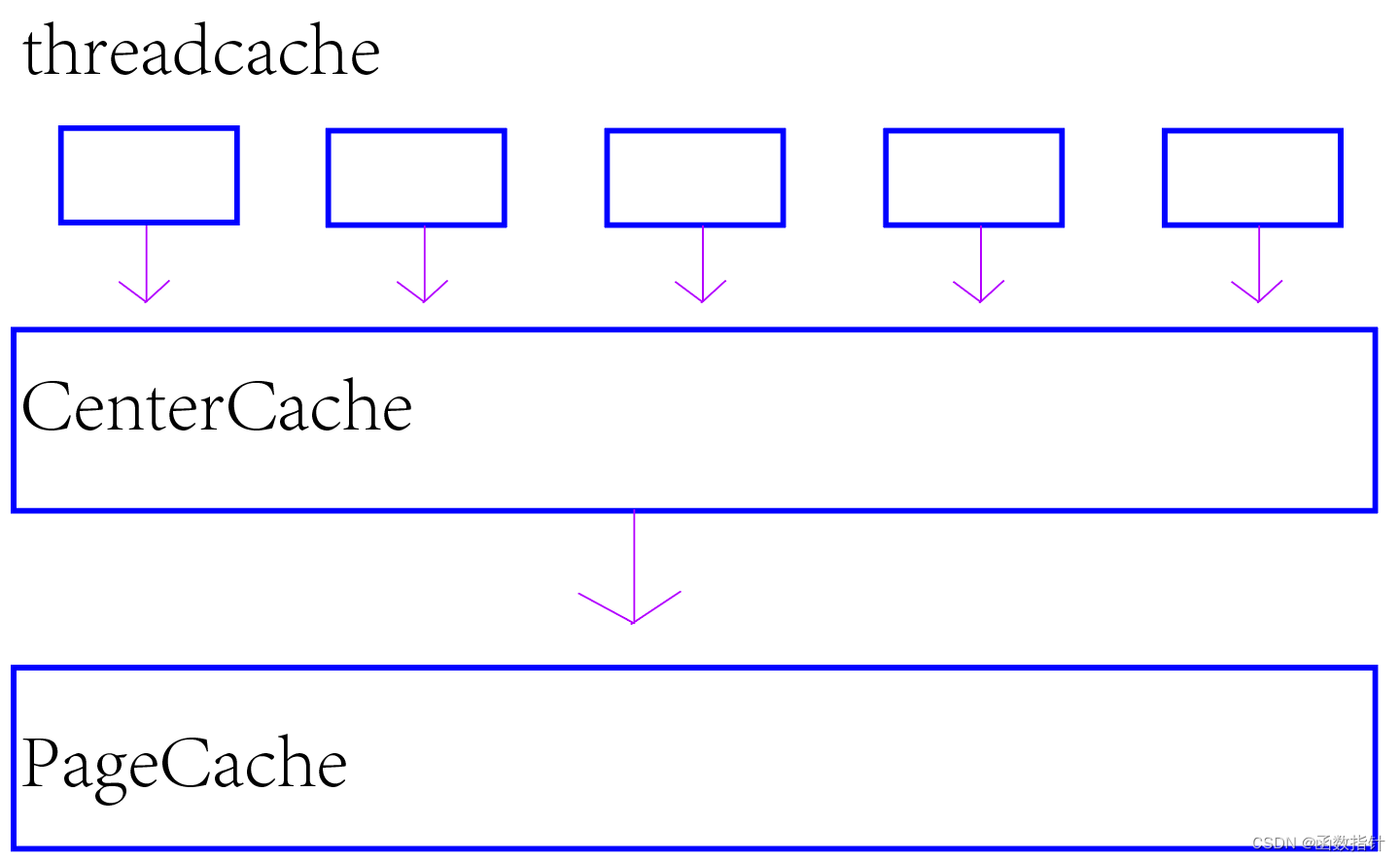
concurrent memory pool主要由以下3个部分构成:
1.ThreadCache:线程缓存是每个线程独有的,用于小于64k的内存的分配,所以不用加锁,每个线程独享一个ThreadCache,这是并发线程池高效的地方,本质是由哈希映射的链表实现。
2.CentralCache:中心缓存是所有线程所共享的,所以需要加锁,ThreadCache是按需从CentralCache中获取的对象。CentralCache周期性的回收ThreadCache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧。达到内存分配在多个线程中更均衡的按需调度的目的。CentralCache是存在竞争的,所以从这里取内存对象是需要加锁,不过一般情况下在这里取内存对象的效率非常高,所以这里竞争不会很激烈。
3.PageCache:页缓存是在CentralCache缓存上面的一层缓存,存储的内存是以页为单位存
储及分配的,CentralCache没有内存对象时,从PageCache分配出一定数量的page,并切
割成定长大小的小块内存,分配给CentralCache。PageCache会回收CentralCache满足条
件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题.
比如这样:
这就是内存池的简单模型。
具体细节请看代码实现。

4.内存池的实现
ThreadCache的实现
由于ThreadCache是一个有哈希映射的链表,所以可以将其设计为一个命名为ThreadCache的类:
class ThreadCache { public: private: };由于ThreadCacheTjreadCache的设计需要实现一个链表,可以可以放在一个公共头文件中,使其它部分也可以访问。
这个类存放的是ThreadCache单个对象,设计为:
static void*& NextObj(void* obj)//保证在其他文件不可见 {return *(void**)obj; }class FreeList { public: void Push(void* obj) {//void* _FreeList=NextObj(obj);NextObj(obj) = _FreeList;_FreeList = obj;_size++; } void* Pop() {void* obj = _FreeList;_FreeList = NextObj(obj);_size--;return obj; } private:void* _FreeList = nullptr; }FreeList先放入插入函数和删除函数,以后的内容到后面实现。由于需要访问下一个元素,所以直接实现一个函数,实现访问下一个元素。
对于每个单个小对象先来说,初始化为空。
对于ThreadCache来说,需要实现的函数接口为,申请内存,释放内存,当ThreadCache内存不够使,向CentralCache中申请。由于ThreadCache是没有锁的,且为了保证效率,我们使用thread local storage保存每个线程本地的ThreadCache的指针,这样大
部分情况下申请释放内存是不需要锁的。为了防止出现在多个文件中出现重定义现象,我们采取定义和声明分离来实现。class ThreadCache { public:void* Alloc(size_t size);//申请内存void Deallocate(void* ptr, size_t size);//释放内存void* FetchFromCentralCache(size_t bytes, size_t align);//向CentralCache申请private:FreeList _freeLists[NFREE_LIST];//哪个桶 };static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;//每个ThreadCache都有一个线程,没//申请内存 void* ThreadCache::Alloc(size_t size) {assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);//有效字节数size_t index = SizeClass::Index(size);//哪个桶//assert(alignSize <= MAX_BYTES);assert(index <= NFREE_LIST);if (!_freeLists[index].Empty())return _freeLists[index].Pop();//有内存elsereturn ThreadCache::FetchFromCentralCache(index, alignSize);//从cettercache获取 } //释放内存 void ThreadCache::Deallocate(void* ptr, size_t size) {assert(ptr);assert(size <= MAX_BYTES);size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//size<最大sizeif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);} }申请内存:
首先需要确定申请的内存需要小于256Kb的大小,大于256KB,我们后续解决。
申请内存需惊醒内存对齐,保证申请的内存达到最大利用率。
//static size_t _RoundUp(size_t bytes, size_t alignNum)//简单计算 //{ // size_t _size = bytes; // if (bytes % alignNum == 0) // { // return _size; // } // else // { // _size = (bytes / alignNum + 1) * 8; // } //} static size_t _RoundUp(size_t bytes, size_t alignNum)//高级计算 {return ((bytes + alignNum - 1) & ~(alignNum - 1)); } //计算最小对齐数 static size_t RoundUp(size_t size) {if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8 * 1024);}else if(size> MAX_BYTES){return _RoundUp(size, 1 << PAGE_SHIFT);}else{assert(false);return -1;} }对于这部分的代码,我们根据申请的不同字节数来确定,不同的对齐数,是资源利用率最大化。计算字节对齐数,可以有普通的方法和利用位运算的方法,位运算的方法分析:
对于上述位运算,我们以10字节按8字节对齐为例进行分析:
8 − 1 = 7 8-1=7 8−1=7,7就是一个低三位为1其余位为0的二进制序列,我们将10与7相加,相当于将10字节当中不够8字节的剩余字节数补上了。然后我们再将该值与7按位取反后的值进行与运算,而7按位取反后是一个低三位为0其余位为1的二进制序列,该操作进行后相当于屏蔽了该值的低三位而该值的其余位保持不变,此时得到的值就是10字节按8字节对齐后的值,即16字节。
然后我们需要确定在那个桶里面,因为ThreadCache是基于哈希映射来实现的,就像这样,
所以我们确定在那个桶里面,具体实现如下:
static size_t _Index(size_t bytes, size_t align_shift) {return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1; } //在哪个桶里面 static size_t Index(size_t bytes) {assert(bytes <= MAX_BYTES);static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128){return _Index(bytes, 3);}else if (bytes <= 1024){return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024){return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024){return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024){return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else{assert(false);return -1;}}这个思路和上面的差不多,同学们可以自行探索下。确定在哪个桶之后,可以申请内存,保证这个桶里面不是空的,如果没有内存,则需要的下一层中申请,也就是CentralCache中。
如果内存不够,则需要去CentralCache中去申请,也即FetchFromCentralCache()函数,
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size) {//慢增长调节算法size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (batchNum == _freeLists[index].MaxSize()){batchNum += 1;}void* start = nullptr;void* end = nullptr;//实际大小size_t actually = CentreCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actually > 0);if (actually == 1)//直接返回{assert(start == end);return start;}else//一段范围{_freeLists[index].PushRange(NextObj(start), end,actually);return start;} }对于FetchFromCentralCache()函数来说,需要确定申请的大小,所以为了减小内存的浪费,我们采用慢增长调节算法,当thread cache向central cache申请内存时,如果central cache给的太少,那么thread cache在短时间内用完了又会来申请;但如果一次性给的太多了,可能thread cache用不完也就浪费了。但如果给少了不够用,需要频繁得去向CenTRALCache中申请内存,降低性能,所以我们需要再次写一个函数,确定申请的大小。
通过确定对齐数的大小,用来申请,需要的内存,最小为2,最大为512,然后计算实际大小,以为CentralCache可能没有那么大的内存,需要我们进行处理,如果申请额的内存正好为1,即start等于end,直接返回start,如果大于一,则需要将剩余的同挂到相同的桶的下面。方便下次申请。这样就需要再确定一个函数,即插入一段范围的区间:PushRange函数:
n为实际申请的大小数。_size为当前有多少内存,方便以后统计使用。
到CenterCache中获取新内存,就需要再设计出一个类,用以保存类成员及类的成员函数,由于CentralCache是每个线程都共享的,所以我们把它设计为单列模式,即每次只允许创建一个对象,具体看代码
// 单例模式 class CentreCache { public:static CentreCache* GetInstance(){return &_sInst;}// 获取一个非空的spanspan* GetOneSpan(spanlist& list, size_t byte_size);// 从中心缓存获取一定数量的对象给thread cachesize_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);//释放内存void ReleaseListToSpans(void*& start, size_t size); private:spanlist _spanLists[NFREE_LIST]; private:CentreCache(){}CentreCache(const CentreCache&) = delete;static CentreCache _sInst; };
CenteralCache也是一个由哈希映射的一个链表结构,所以我们把设计为带头双向循环链表,我们就需要再设计出一个类,用来存储;链表结构:
struct span {PAGE_ID _pageId = 0;//起始页号size_t _num = 0;//页得数量span* _prev = nullptr;//头span* _next = nullptr;//尾size_t _objSize = 0;//切好的小对象的大小size_t _useCount = 0; // 切好小块内存,被分配给thread cache的计数void* _freeList = nullptr;// 切好的小块内存的自由链表bool _isUse = false;//是否正在使用 }; class spanlist { public:spanlist(){_head = new span;_head->_next = _head;_head->_prev = _head;}/*~spanlist(){while (_head){_head = _head->_next;delete _head;}}*/span* Begin(){return _head->_next;}span* End(){return _head;}bool Empty(){return _head->_next == _head;}void pushFront(span* newpos){assert(newpos);Insert(Begin(), newpos);}span* popFront(){assert(_head->_next);span* it = Begin();Erase(Begin());return it;}//插入void Insert(span* pos, span* newpos)//newpos插入节点{assert(pos);assert(newpos);//判断span* prev = pos->_prev;//插入prev->_next = newpos;newpos->_prev = prev;newpos->_next = pos;pos->_prev = newpos;}//删除void Erase(span* pos){assert(pos);assert(pos != _head);span* prev = pos->_prev;span* next = pos->_next;prev->_next = next;next->_prev = prev;}private:span* _head; public:std::mutex _mtx; // 桶锁 };由于CentrealCache只能有一个线程来访问,所以需要带一把桶锁,防止锁竞争问题。
下面是得到一段范围的内存:
size_t CentreCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size) {size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();span* sspan = GetOneSpan(_spanLists[index], size);assert(sspan);assert(sspan->_freeList);// 从span中获取batchNum个对象// 如果不够batchNum个,有多少拿多少start = sspan->_freeList;end = start;size_t i = 0;size_t actualNum = 1;while (i < batchNum - 1 && NextObj(end) != nullptr){end = NextObj(end);++i;++actualNum;}sspan->_freeList = NextObj(end);NextObj(end) = nullptr;sspan->_useCount += actualNum;_spanLists[index]._mtx.unlock();return actualNum; }得到一段范围的内存,就需要GetOneSpan()函数来执行这段代码,我们先来分析FetchRangeObj()函数接口,得到一块span之后,确定是否为空,如果为空,则申请失败,然后确定开始位置和结束为止,确定其申请的个数,方便下次操作,然后返回其实际数值。
span* CentreCache::GetOneSpan(spanlist& list, size_t size) {span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}else it = it->_next;}//说明没有span,到PageCache申请list._mtx.unlock();//解锁PageCache::GetInstance()->_pageMtx.lock();span* sspan = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));sspan->_isUse = true;sspan->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();// 对获取span进行切分,不需要加锁,因为这会其他线程访问不到这个span// 计算span的大块内存的起始地址和大块内存的大小(字节数)// 计算span的大块内存的起始地址和大块内存的大小(字节数)char* start = (char*)(sspan->_pageId << PAGE_SHIFT);size_t bytes = sspan->_num << PAGE_SHIFT;char* end = start + bytes;// 把大块内存切成自由链表链接起来// 1、先切一块下来去做头,方便尾插sspan->_freeList = start;start += size;void* tail = sspan->_freeList;int i = 1;while (start < end){++i;NextObj(tail) = start;tail = NextObj(tail); // tail = start;start += size;}// 切好span以后,需要把span挂到桶里面去的时候,再加锁list._mtx.lock();list.pushFront(sspan);return sspan; }GetOneSpan得到一块新span,CenteralCache中可能没有span,所以我们需要去判断是否有足够的内存去使用,如果没有,就需要到PageCacheh中申请,如果足够,则直接返回span.到PageCache中申请足够的内存之后,需要 计算span的大块内存的起始地址和大块内存的大小(字节数),start为开始时的起始地址,页的起始地址左移13位计算出页的起始地址,页的个数左移13位计算出页的个数,结束位置为开始的地址加上页得个数。
然后把大块内存切成自由链表连接起来,先切头结点,方便尾插,然后再挂到桶里面去,再加锁,防止锁竞争。
PageCache申请:PageCache的结构和CentralCache的结构是一样的,在次不做多余解释
class PageCache { public:static PageCache* GetInstance(){return &_sInst;}//得到一个spanspan* NewSpan(size_t k);//找到对应的spanspan* MapObjectToSpan(void* start);void ReleaseSpanToPageCache(span* span);//合并大页std::mutex _pageMtx; private:spanlist _spanLists[NPAGES];ObjectPool<span> _spanPool;PageCache(){}PageCache(const PageCache&) = delete;//记录页号所对应的spanstd::unordered_map<PAGE_ID, span*> _idspanMap;static PageCache _sInst; };得到一个NewSpan():
span* PageCache::NewSpan(size_t k) {assert(k > 0 );// 先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){return _spanLists->popFront();}// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分for (size_t i = k + 1; i < NPAGES; ++i){if (!_spanLists[i].Empty()){span* nSpan = _spanLists[i].popFront();span* kSpan = new span;// 在nSpan的头部切一个k页下来// k页span返回// nSpan再挂到对应映射的位置kSpan->_pageId = nSpan->_pageId;kSpan->_num = k;nSpan->_pageId += k;nSpan->_num -= k;_spanLists[nSpan->_num].pushFront(nSpan);for (PAGE_ID i = 0; i < kSpan->_num; ++i){_idspanMap[kSpan->_pageId + i] = kSpan;}return kSpan;}}// 走到这个位置就说明后面没有大页的span了// 这时就去找堆要一个128页的spanspan* bigSpan = new span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_num = NPAGES - 1;_spanLists[bigSpan->_num].pushFront(bigSpan);return NewSpan(k); }对于NewSpan()函数来说,如果PageCache当前的第K个桶里面有内存,则直接使用第K个桶里面的内存,如果没有,则一个一个遍历,直到找到不是空的那个桶里面,然后通过new来new一个空间,找到k个空间,拿去使用,然后多余的内存挂到第n-k号桶里面,然后返回找到的span,如果没有,则直接去堆上申请。
申请内存完成之后需要释放内存,先说ThreadCache的内存释放,如果ThreadCache所释放的空间小于最大内存数量,则直接释放到ThreadCache中,如果多于最大数量,则调用下一层CentrealCache,通过CentralCache释放,
void ThreadCache::Deallocate(void* ptr, size_t size) {assert(ptr);assert(size <= MAX_BYTES);size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//size<最大sizeif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);} } void ThreadCache::ListTooLong(FreeList& list, size_t size) {void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());CentreCache::GetInstance()->ReleaseListToSpans(start, size);}释放内存,ThreadCache和CenteralCache释放
void CentreCache::ReleaseListToSpans(void*& start, size_t size) {size_t index = SizeClass::Index(size);//哪个桶_spanLists[index]._mtx.lock();//加锁//还内存while (start){void* next = NextObj(start);span* sspan=PageCache::GetInstance()->MapObjectToSpan(start);//找页号NextObj(start) = sspan->_freeList;sspan->_freeList = start;sspan->_useCount--;if (sspan->_useCount == 0)//还回来完了{_spanLists[index].Erase(sspan);sspan->_freeList = nullptr;sspan->_next = nullptr;sspan->_prev = nullptr;// 释放span给pagecache时,使用page cache的锁就可以了// 这时把桶锁解掉_spanLists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(sspan);PageCache::GetInstance()->_pageMtx.unlock();}start = next;}_spanLists[index]._mtx.unlock(); }最后就是如果CenterCache中所使用的内存减到0为止,就需要向PageCache中释放,PageCache的内存释放需要合并,通过向前和向后合并,完成内存的释放。
void PageCache::ReleaseSpanToPageCache(span* span) {if (span->_num > NPAGES - 1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);//delete span;_spanPool.Delete(span);return;}//对span前后页进行合并while (true){PAGE_ID previd = span->_pageId - 1;auto pret = _idspanMap.find(previd);//是否存在if (pret == _idspanMap.end()) break;// 前面相邻页的span在使用,不合并了auto prevspan=pret->second;if (prevspan->_isUse) break;if (prevspan->_num + span->_num > NPAGES - 1) break;span->_pageId = prevspan->_pageId;//前合并span->_num += prevspan->_num;_spanLists[prevspan->_num].Erase(prevspan);//删除_spanPool.Delete(prevspan);}//后合并while (true){PAGE_ID nextId = span->_pageId + span->_num;auto ret = _idspanMap.find(nextId);if (ret == _idspanMap.end()) break;auto nextspan = ret->second;if (nextspan->_isUse == true) break;if (nextspan->_num + span->_num > NPAGES - 1) break;//合并//span->_pageId = nextspan->_pageId;span->_num += nextspan->_num;_spanLists[nextspan->_num].Erase(nextspan);//delete nextspan;_spanPool.Delete(nextspan);}_spanLists[span->_num].pushFront(span);span->_isUse = false;//恢复_idspanMap[span->_pageId] = span;_idspanMap[span->_pageId + span->_num - 1] = span;}






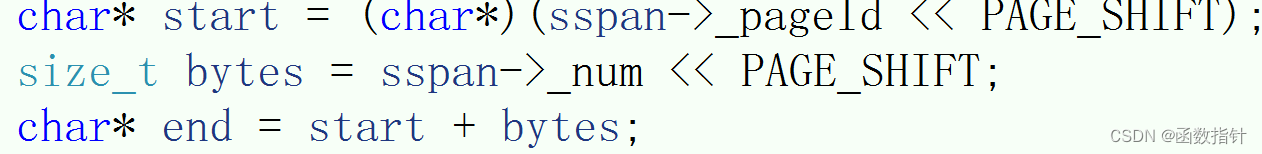
4.结尾
对于大块内存来说,如果申请的内存大于256kb,则需要直接去堆上申请,但是如果直接去堆上申请,则依然会导致内存碎片的产生,所以我们采用定长内存池的方法去向堆中申请,这样就可以直接避免直接new和delete而产生的内存碎片问题,减少外内存问题的产生,另外,内碎片是无法解决的,只能去减小内碎片的问题,不能直接去解决·。当然了·,如果释放内存大于256KB,也是通过定长内存池去释放的,提高程序的性能问题。
另外在不同平台下,需要有不同的解决方案,这就需要条件编译来解决问题,本次项目主要在windows下的32位平台下解决问题,完整代码请查看该网址:Text .MemoryPool/Text .MemoryPool · 一页纸鸢/C-C++项目 - 码云 - 开源中国 (gitee.com)

)





`)

)




)

二位数 如何让加减乘除题目从小到大排序(以1-20之间加法为例,做正序排列用))


