目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 爬虫
- 1.安装Anaconda
- 2.安装Python3.6
- 3.更换pip源
- 4.安装Python包
- 5.下载phantomjs
- 模型训练
- 1.安装依赖
- 2.安装lmageAl
- 实际应用
- 1.前端
- 2.安装Flask
- 3.安装Nginx
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目通过爬虫技术获取图片,利用OpenCV库对图像进行处理,识别并切割出人物脸部,形成了一个用于训练的数据集。通过ImageAI进行训练,最终实现了对动漫人物的识别模型。同时,本项目还开发了一个线上Web应用,使得用户可以方便地体验和使用该模型。
首先,项目使用爬虫技术从网络上获取图片。这些图片包含各种动漫人物,其中我们只对人物脸部进行训练,所以我们会对图像进行处理,并最终将这些图像将作为训练数据的来源。
其次,利用OpenCV库对这些图像进行处理,包括人脸检测、图像增强等步骤,以便准确识别并切割出人物脸部。这一步是为了构建一个清晰而准确的数据集,用于模型的训练。
接下来,通过ImageAI进行训练。ImageAI是一个简化图像识别任务的库,它可以方便地用于训练模型,这里用于训练动漫人物的识别模型。
最终,通过项目开发的线上Web应用,用户可以上传动漫图像,系统将使用训练好的模型识别图像中的动漫人物,并返回相应的结果。
总的来说,本项目结合了爬虫、图像处理、深度学习和Web开发技术,旨在提供一个便捷的动漫人物识别服务。这对于动漫爱好者、社交媒体平台等有着广泛的应用前景。
总体设计
本部分包括系统整体结构图和系统流程图。
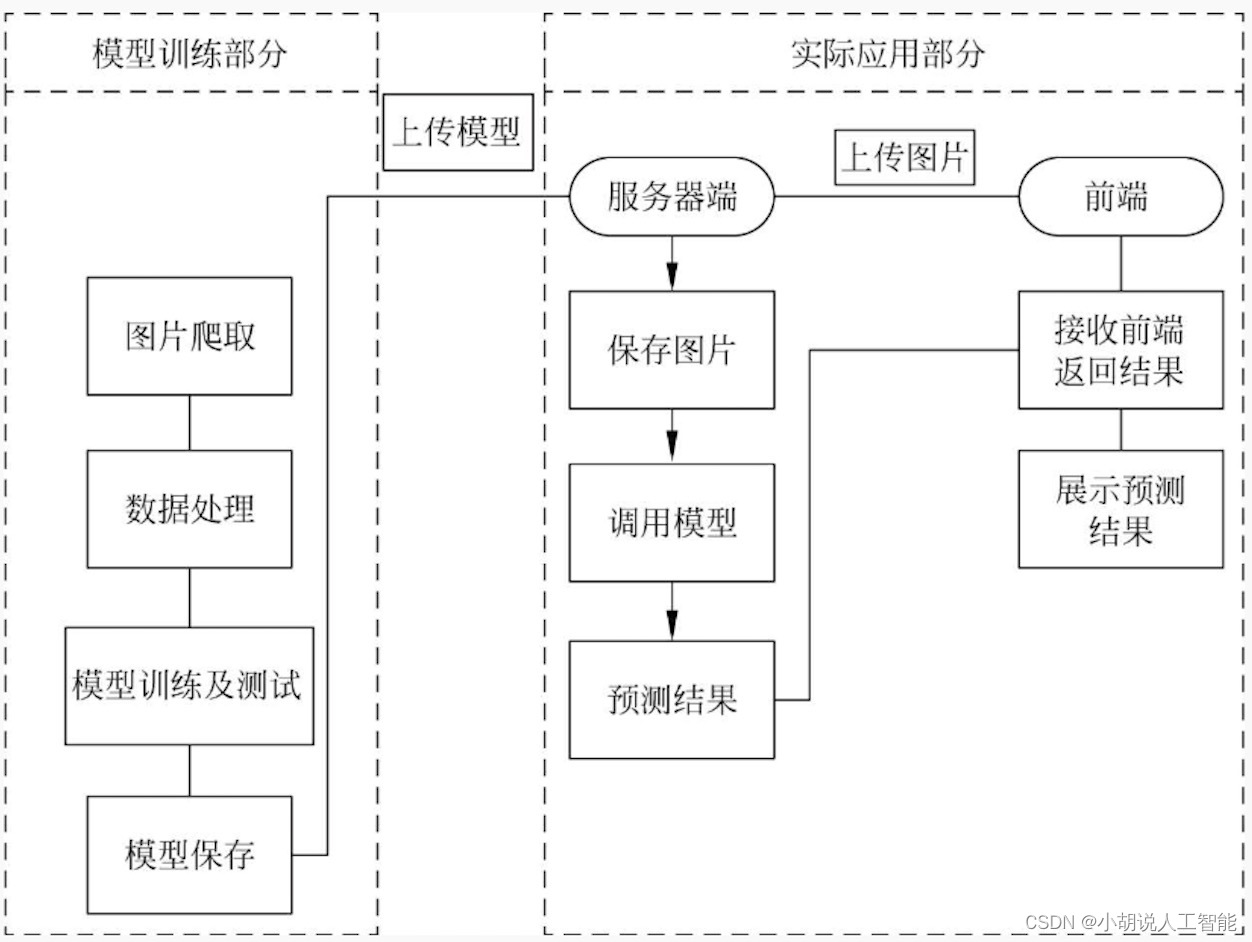
系统整体结构图
系统整体结构如图所示。
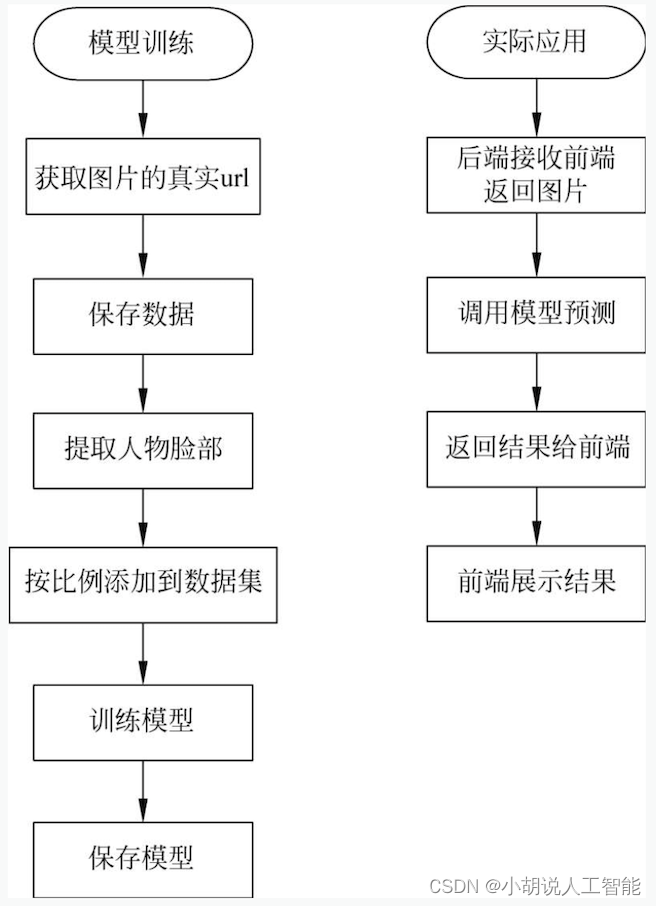
系统流程图
系统流程如图所示。
运行环境
本部分包括爬虫、模型训练及实际应用运行环境。
爬虫
安装Python3.6以上及Selenium3.0.2版本。
1.安装Anaconda
使用Anaconda管理Python环境。在Windows环境下载Anaconda完成安装,下载地址为https://www.anaconda.com/。
验证安装。单击菜单【开始】→Anaconda3(64-bit)→Anaconda Navigator,若可以成功启动Anaconda Navigator则说明安装成功。
2.安装Python3.6
打开计算机的cmd命令行窗口,新建Python3.6环境,名称为TensorFlow:
conda create --name tensorflow python=3.6
激活环境:
conda activate tensorflow
3.更换pip源
由于网络问题,需要更换Python包管理工具pip的下载源来提高下载速度。按Win+R组合键打开用户目录%HOMEPATH%,在此目录下创建pip文件夹以及pip.ini文件,成功更换pip的源为清华镜像。内容如下:
[global]
timeout = 60000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
4.安装Python包
新建一个.txt文件并命名为crawler_requirements.txt,写入如下内容:
future==0.16.0
futures==3.0.5
requests==2.12.1
selenium==3.0.2
在启动的Python环境cmd窗口输入:
pip install -r crawler_requirements.txt
即可安装爬虫所需要的包。
5.下载phantomjs
Selenium是用于Web应用程序测试的工具,其测试直接在浏览器中运行,需要使用phantomjs。在Linux环境下的phantomjs是完整的,可以直接使用pip安装使用,但是在Windows环境下需要下载phantomjs.exe文件来引用。新建bin文件夹用于存储phantomjs.exe可执行文件。
官网下载地址:https://phantomjs.org/download.html
模型训练
本部分包括安装依赖、安装ImageAI。
1.安装依赖
TensorFlow 1.4.0(及更高版本)安装或通过pip安装:
pip3 install -- upgrade tensorflow
Numpy1.13.1(及更高版本)安装或通过pip安装:
pip3 install numpy
SciPy0.19.1(及更高版本)安装或通过pip安装:
pip3 install scipy
OpenCV安装或通过pip安装:
pip3 install opencv - python
pillow安装或通过pip安装:
pip3 install pillow
Matplotlib安装或通过pip安装:
pip3 install matplotlib
h5py安装或通过pip安装:
pip3 install h5py
Keras2.x安装或通过pip安装:
pip3 install keras
2.安装lmageAl
可以直接通过下面命令安装ImageAI:
pip3 install imageai
也可以先下载imageai-2.0.1-py3-none-any.whl。
下载地址为https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
然后在下载目录下,运行如下命令安装ImageAI:
pip3 install imageai-2.0.1-py3-none-any.whl
实际应用
实际应用包括前端开发环境和后端环境的搭建。
1.前端
实际应用过程中需要在官网下载Jquery3.5.0.js、bootstrap 4.4.1.js和template.js0.8.0.js等3个文件。
2.安装Flask
通过ask1.1.2接收和发送用户请求,使用pip直接安装:
pip install -y Flask
3.安装Nginx
本地开发完成后,需要在服务器端运行。配置服务器端的环境为Nginx,Nginx(enginex),是高性能的HTTP和运行代理Web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx负责接收和转发用户请求,同时保证服务器端的负载均衡。
安装Nginx。选择稳定版本:服务器端的Linux环境为CentOS 6.2x86_64。使用Linux下包管理工具yum安装缺少的依赖包:
# yum -y install gcc gcc-c++make libtoolzlib zlib zlib-devel openssl openssl-devel pcre pcre-devel
如果yum上没有这些软件包,可以下载源码编译安装,编译时默认安装的目录,确保在安装Nginx时找到动态库文件。从网站http://nginx.org/en/download.html下载稳定版nginx-1.6.3.tar.gz到/usr/local/src下解压。
另外下载2个插件模块——nginx_upstream_check_module-0.3.0.tar.gz 和 nginx-goodies-nginx-sticky-module-ng-bd312d586752.tar.gz(建议在/usr/local/src下解压后将目录重命名为nginx-sticky-module-ng-1.2.5),前者用于检查后端服务器的状态,后者用于后端做负载均衡解决报错(sessions ticky问题)。注意插件与Nginx的版本兼容问题,一般插件越新越好,Nginx则无须追求最新的版本。
启动Nginx服务,命令如下:
systemctl start nginx
修改Nginx的配置文件。
打开/etc/nginx/nginx.conf文件,修改server部分。相关代码如下:
server {#监听端口listen 80;#访问城名server_name localhost;#编码格式,若网页格式与此不同,将被自动转码#charset koi8#虚拟主机访问日志定义#access_log logs/host.access.log main;#对URL进行匹配location / {#访问路径,可以是相对路径也可以是绝对路径root html;#首页文件,以下按顺序匹配index l index.htm;}
}
本项目在阿里云的控制台开放服务器端口才能被用户访问,Nginx服务器默认为80端口。
相关其它博客
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(二)
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(三)
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。













上创建、修改报表(下))
之build构建系统基础(一))




