上一节我们安装了机器学习mlagents的开发环境,本节我们创建第一个例子,了解什么是机器学习。
我们的例子很简单,就是让机器人自主移动到目标位置,不能移动到地板范围外。
首先我们来简单的了解以下机器学习的过程。
机器学习的过程
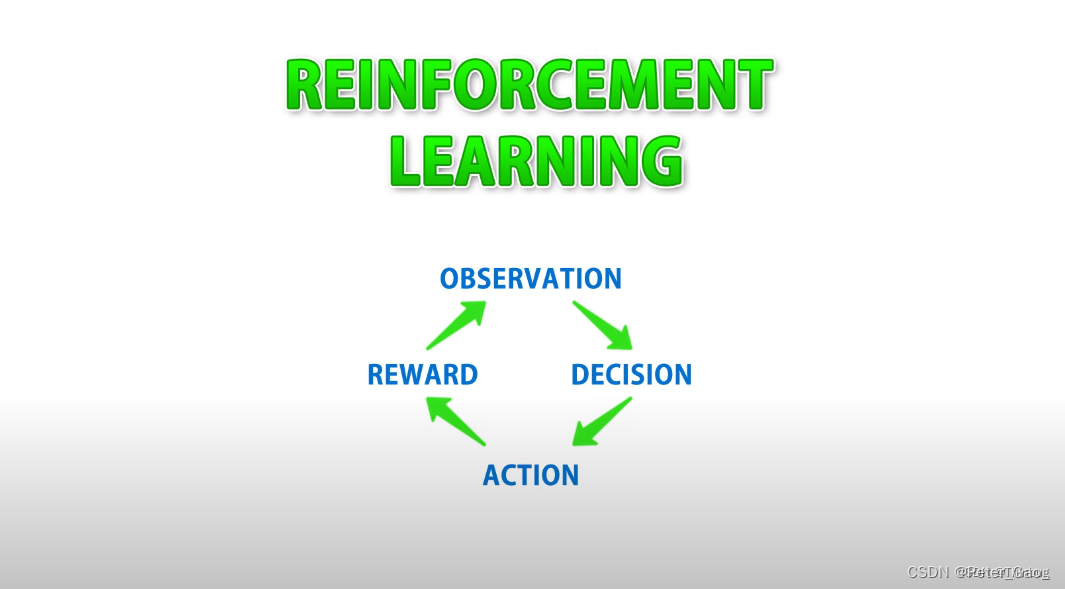
MLAgents机器强化学习的过程(reinforcement learning)
observation - 监视,观察
decision - 决策
action - 行动
reward - 奖罚
这4个步骤的翻译可能不是很准确,大概就是先观察,后决策,然后行动,最后奖罚。
脚本开始
我们首先创建一个新脚本,我这里创建了MoveToTarget.cs
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;public class MoveToTarget : Agent
{}机器学习的类都要要继承Agent基类。
Observation、Action(监视和行动)
我们首先通过覆写CollectObservations函数,它负责观察或者监视数据,本例是让代理(agent)观察目标target的方位。
然后覆写OnActionReceived函数,通过接受到的缓冲区的数据进行行动,这里我们要注意机器学习的算法只适用于数字,这意味着机器不知道什么是对象(object),也不知道什么是左右移动,它只负责处理数字,例如float,int类型数据。
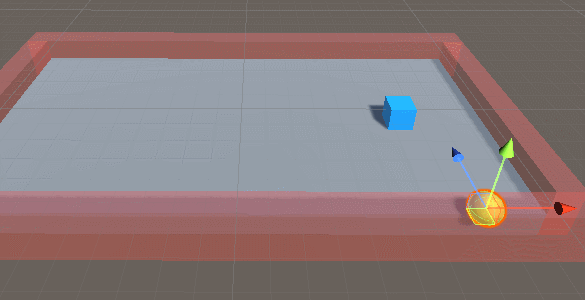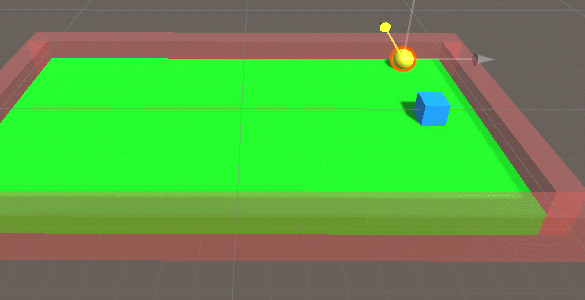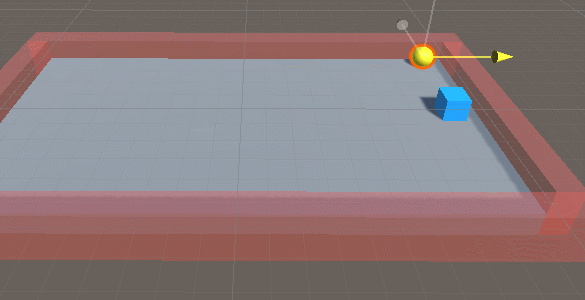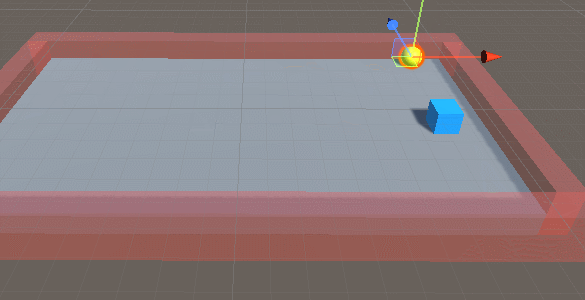
接下来,我们在Unity中创建一个agent(代理-盒子,蓝色),target(目标-球形,黄色),还有地板plane(盒子,灰色)。如下图:

理解重要参数
在agent上添加我们的脚本MoveToTarget,这时会自动添加一个BehaviorParameters的行为参数脚本。
离散的意义
我们先来理解下离散的意义:
假如我们离散输入1,分支0输入5。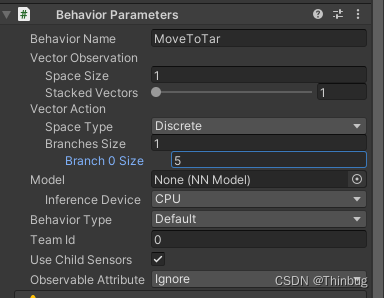
代码中覆写Action接收。 我们看下log,因为只有一个离散分支,所以是DiscreteActions[0]
public class MoveToTarget : Agent
{public override void OnActionReceived(ActionBuffers actions){Debug.Log(actions.DiscreteActions[0]);}
}
因为我们覆写了行动Action,我们还需要一个请求决策。我们在agent对象上添加DecisionRequester(决策请求),参数DecisonPeriod是请求的周期。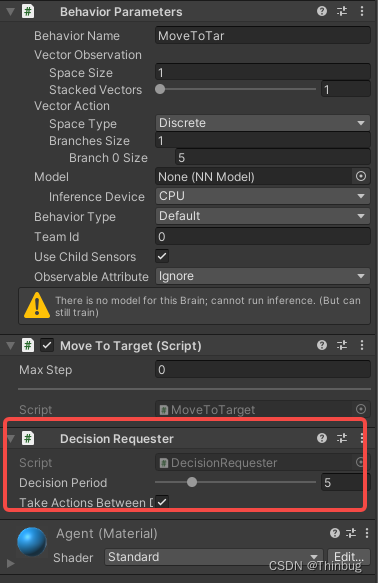
接下来我们就可以执行,看输出了什么。
调试和查看输出
首先开打cmd,让我们进入vent虚拟环境中。上一篇文章我们讲过了,就是那个MLApp\venv\Scripts\activate.bat批处理文件,确保正常是这样的。
然后我们输入
mlagents-learn
然后会出现一个漂亮的Unity Logo,并且告诉我们,可以开始Unity运行了。如下图:
Unity运行后,我们看到cmd窗口和Unity的输出已经开始了。
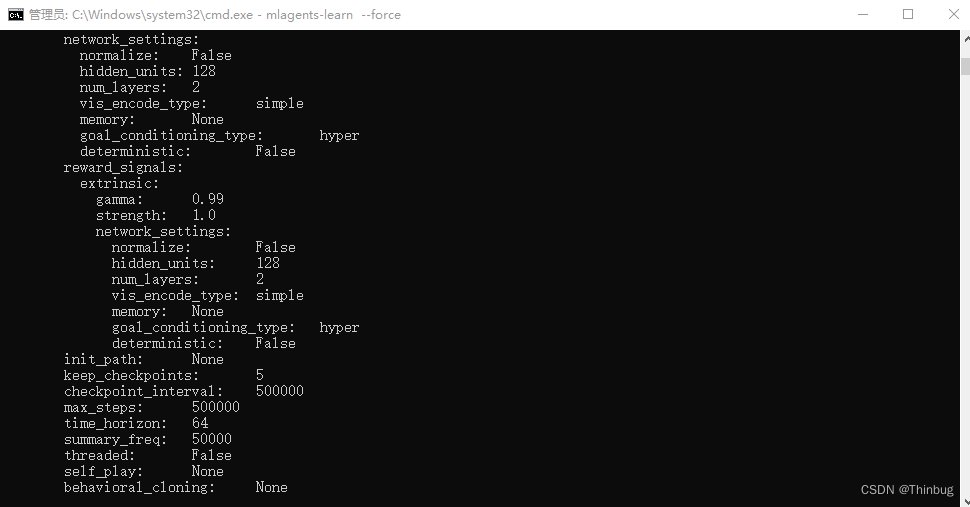

我们可以看到离散的输出,因为设置了5,这里也只有0-4。
连续类型
接下来我们测试连续型
在Unity中我们把SpaceType改为continuous。并且设置Size为1。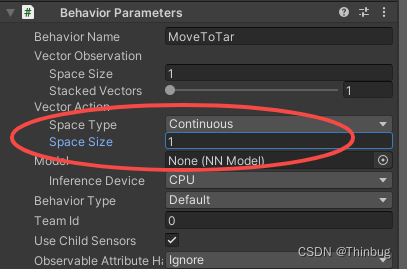
脚本也需要改为接收连续型
public class MoveToTarget : Agent
{public override void OnActionReceived(ActionBuffers actions){Debug.Log(actions.ContinuousActions[0]);}
}
我们继续开始运行,在cmd中输入mlagents-learn
这时我们会得到一个报错: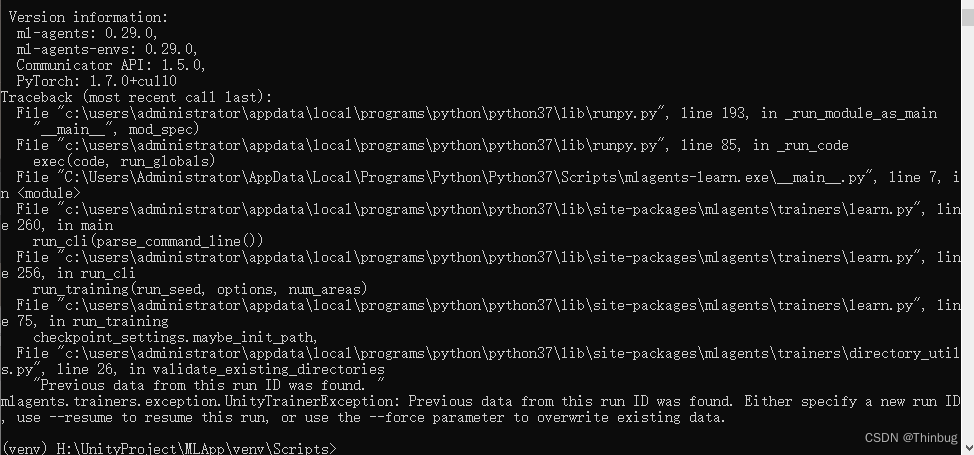
是因为我们重试使用了相同的默认ID进行再次训练,这里我们要么使用mlagents-learn --force来强制覆盖学习,要么更换ID,mlagents-learn --run-id=test2。
那么虚拟环境开启后,我们运行Unity。
运行后,我们得到的log如下: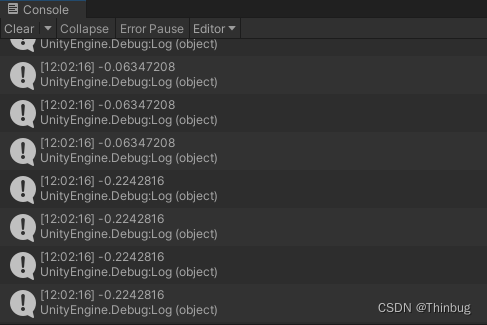
我们看到了,连续的就是-1到1的浮点数。到这里我们就了解了离散和连续的区别了。
监视和行动代码
下面我们将继续完善脚本,收集监视信息。
我们需要覆写CollectObservations(VectorSensor sensor)函数。这个函数你可以理解成AI,就是人工智能需要哪些数据才能解决你的问题。在本例中,我们希望盒子(agent)对象移动到球(target)对象的位置。我们思考以下,我们需要知道的数据有哪些?
如果你想agent能够移动到目标,是不是需要知道agent在哪,target在哪,所以要知道两个目标的位置,所以我们通过传感器把坐标传入监视。所以代码里我们把两个物体的坐标位置传递给观察器。
[SerializeField] Transform targetTfm; public override void CollectObservations(VectorSensor sensor){sensor.AddObservation(transform.position);sensor.AddObservation(targetTfm.transform.position);}
行动里,actions就是(decision - 决策)的结果,我们根据决策数据进行行动。
//行动float moveSpd = 10f;public override void OnActionReceived(ActionBuffers actions){float moveX = actions.ContinuousActions[0];float moveZ = actions.ContinuousActions[1];transform.position += new Vector3(moveX, 0f, moveZ) * Time.deltaTime * moveSpd;}
因为我们给观察函数的信息是两个坐标,相当于6个float类型,所以Vector Observations 的 SpaceSize需要填写6。而行动,我们只需要移动agent的x和z轴,所以Vector Action的SpaceSize填写2。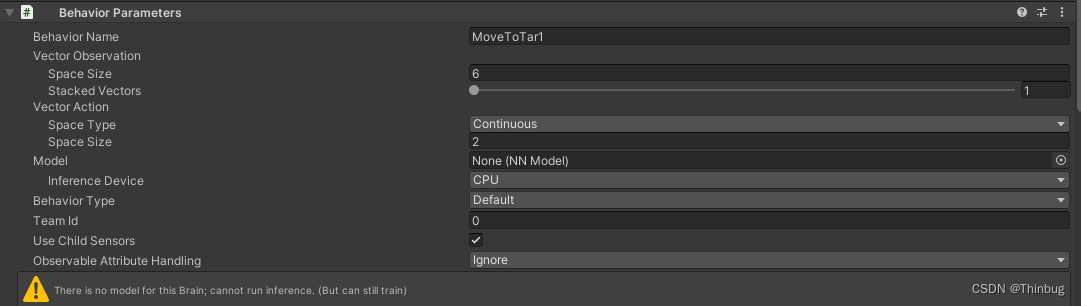
如何让机器学习
你可以把机器学习看成是训练小狗,如果小狗完成了指定动作,你可以给它骨头。反之,给予惩罚。
在本例中,我们在地板周围围上4面墙体。我们判断如果它移动到墙就扣分,如果移动都目标就加分,我们在Unity里给Plane围上4个wall。我们添加墙体,并勾选墙体和target 的Collider的IsTrigger,方面我们进行一个触发处理。

添加奖励模块脚本
private void OnTriggerEnter(Collider other){Debug.Log("OnTriggerEnter:"+other.name);if (other.name.Equals("target")){ AddReward(+1f); //奖励EndEpisode(); //结束经历plane.material.color = Color.green;Debug.Log("奖励");}else if (other.name.Equals("wall")){AddReward(-1f); //惩罚EndEpisode(); //结束plane.material.color = Color.grey;Debug.Log("惩罚");}}
上面的代码中,如果碰到了target,我们调用AddReward +1,并结束本段AI,让plane的颜色变为绿色,反之如果碰到了wall,那么就AddReward -1,plane变成灰色。
回合结束处理
每当得到奖励或者惩罚,会调用EndEpisode。当本段落结束后我们希望它继续训练,我们需要把agent对象重新复位,我们要覆写函数OnEpisodeBegin。
//当一段经历开始public override void OnEpisodeBegin(){transform.position = Vector3.zero;Debug.Log("经历开始");}
运行mlagent虚拟机后我们运行unity,可以看到机器已经开始学习如何跑到target的位置了,刚开始很艰难,常常碰到墙壁,慢慢的碰到target的概率会越来越大。
效果如下:
运行过程中,可能开始agent对象很笨,基本原地打转,经过长周期的运行会越来越快的找寻到target。
几个参数
这里有几个点要说明
MaxStep(最大步)

这里的MaxStep是一段(Episode)最大步数,如果我们不想每次运行尝试步数太长,可以给一个数值,你可以尝试1000,10000这样的数字,到达这个后,会重新进入OnEpisodeBegin。设置的目的是如果代理一直运行都没有碰到过target,只是躲避了wall,那么可能达不到我们训练的目的。
Heuristic (启发)
这个我的理解是通过你的控制来测试你的运行逻辑是否正确。属于一个调试功能。
//启发public override void Heuristic(in ActionBuffers actionsOut){ActionSegment<float> continuousActions = actionsOut.ContinuousActions;continuousActions[0] = Input.GetAxisRaw("Horizontal");continuousActions[1] = Input.GetAxisRaw("Vertical");}
我们可以修改agent的BehaviorParameters的BehaviorType为Heuristic(启发),然后运行Unity就可以控制agent。模拟机器是否遇到target和wall会复位,进行调试。
机器学习加快的办法
还有一个机器学习加速的办法,那就是把当前的训练场景复制很多个,让他们同时运行来达到机器训练加速的目的,我们可以把场景和脚本稍加修改。如下:

我们需要修改脚本,把原来的position改为localPosition。因为这样很容易复用我们的代码,并且只用复制几个图中的ground就可以了。
全代码如下:
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;public class MoveToTarget : Agent
{[SerializeField] Transform targetTfm;[SerializeField] Renderer plane;float moveSpd = 30f;//通过传感器把坐标传入监视public override void CollectObservations(VectorSensor sensor){sensor.AddObservation(transform.localPosition);sensor.AddObservation(targetTfm.transform.localPosition);}//行动接收public override void OnActionReceived(ActionBuffers actions){float moveX = actions.ContinuousActions[0];float moveZ = actions.ContinuousActions[1];transform.localPosition += new Vector3(moveX, 0f, moveZ) * Time.deltaTime * moveSpd;}//当一段经历开始public override void OnEpisodeBegin(){transform.localPosition = Vector3.zero;Debug.Log("经历开始");}//启发public override void Heuristic(in ActionBuffers actionsOut){ActionSegment<float> continuousActions = actionsOut.ContinuousActions;continuousActions[0] = Input.GetAxisRaw("Horizontal") * Time.deltaTime * moveSpd;continuousActions[1] = Input.GetAxisRaw("Vertical") * Time.deltaTime * moveSpd;}private void OnTriggerEnter(Collider other){//Debug.Log("OnTriggerEnter:"+other.name);if (other.name.Equals("target")){ AddReward(+1f); //奖励EndEpisode(); //结束经历plane.material.color = Color.green;//Debug.Log("奖励");}else if (other.name.Equals("wall")){AddReward(-1f); //惩罚EndEpisode(); //结束plane.material.color = Color.grey;//Debug.Log("惩罚");}}}我们修改完毕后,然后运行mlagents环境并运行Unity,明显批量的速度更快了。如下图:
从GIF中能看到,亮起绿色的频率越来越快了。在我的机器上到最后就只有绿色的亮起了。
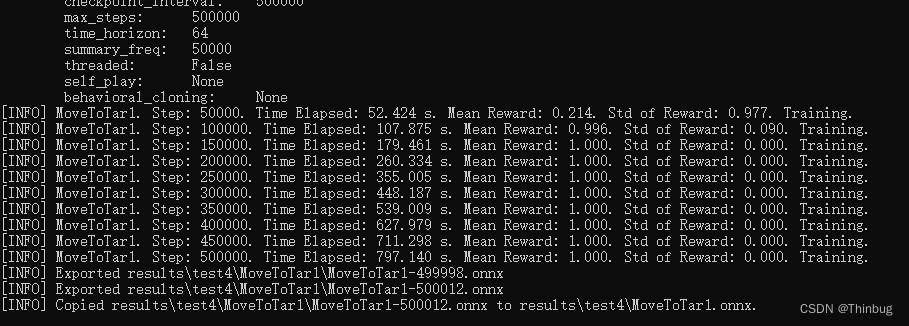
等机器运算完毕后会生成MovetoTart1.onnx文件。
然后在
H:\UnityProject\MLApp\venv\Scripts\results\就能看到我们所有的mlagents测试数据,包含我们需要的训练后的MoveToTar.onnx文件,我们把它复制到Unity/Assets中。这个onnx就是经过AI训练的大脑的神经网络。
我们把这个文件拖动到Model里。
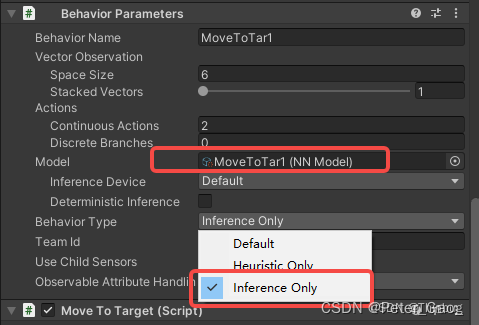
BehaviorType选择InferenceOnly,点击Unity运行,这样这个agent就拥有找寻target的AI了。
环境设置
机器学习的环境是可以自定义配置的,可以参考这里。
创建一个movetarget.yaml文件,放到Unity/config文件夹(建立一个)
behaviors:MoveToTar1:trainer_type: ppohyperparameters:batch_size: 10buffer_size: 100learning_rate: 3.0e-4beta: 5.0e-4epsilon: 0.2lambd: 0.99num_epoch: 3learning_rate_schedule: linearbeta_schedule: constantepsilon_schedule: linearnetwork_settings:normalize: falsehidden_units: 128num_layers: 2reward_signals:extrinsic:gamma: 0.99strength: 1.0max_steps: 500000time_horizon: 64summary_freq: 10000
通过下面的指令进行,就是按照自定的参数来执行了。具体参数意义有机会我们后面再聊。
使用这个配置文件开启机器学习,输入下面的指令:
mlagents-learn config/movetarget.yaml --run-id=test5
进一步优化机器
我们继续上一个测试。当运行的时候,把target的位置改变,我们发现agent可能就找不到目标了,可以思考下为什么?如下面的动画:
对的,因为在机器学习的时候我们的target的位置一直没有发生变化,所以AI可能觉得目标是死物,所以我们可以通过修改脚本,让target每段运算完毕后改变位置,发生变化,机器就会变得聪明些。
我们修改代码如下:
public override void OnEpisodeBegin(){transform.localPosition = new Vector3(Random.Range(-9f, 0f), 0f, Random.Range(-4f, 4f));targetTfm.localPosition = new Vector3(Random.Range(1f, 9f), 0f, Random.Range(-4f, 4f));//Debug.Log("经历开始");}
我们每次开始都随机以下target和agent的位置,但是不会重合。然后再进行机器学习。
我们输入下面指令,在上一次运行的test5的基础上进行test8运算
mlagents-learn config/movetarget.yaml --initialize-from=test5 --run-id=test8
运算后我们覆盖onnx文件,继续运行,结果如下: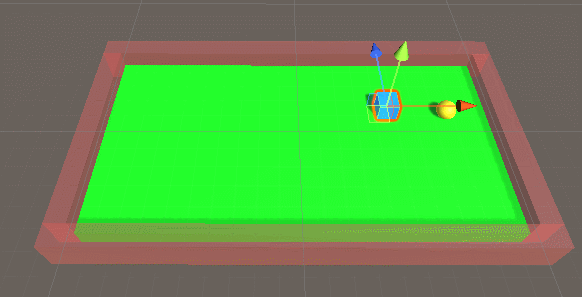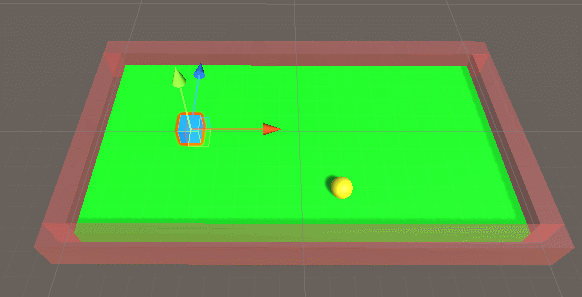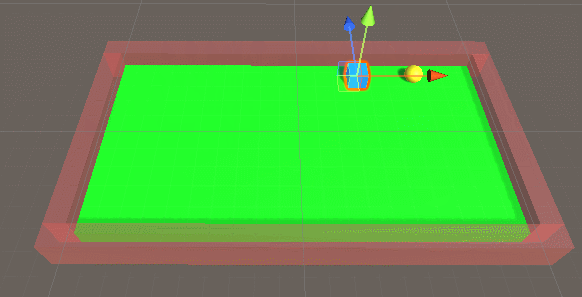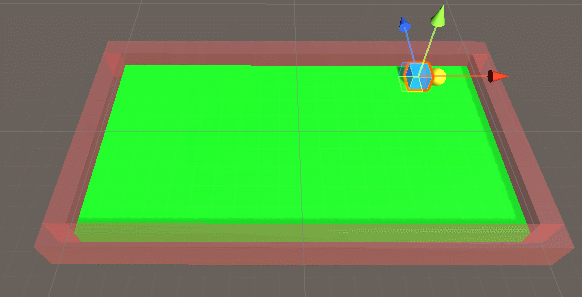
Web监控
要在训练期间监控代理性能的统计信息,请使用 TensorBoard指令。
可以开另外一个cmd,进入虚拟环境(venv),输入下面指令:
tensorboard --logdir results

然后再浏览器输入地址就可以了
http://localhost:6006/

根据图表,你可以看到各种曲线,来修改你的机器训练。
本章内容就到这里了,官方还有很多种机器学习的例子,如果有兴趣可以自行学习。有机会下一篇文章我们进一步扩展,或者做另外一个有意思的Demo。
本章源码
GitHub - thinbug/MLApp
引用:
https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Learning-Environment-Create-New.md
Unity机器学习2 ML-Agents第一个例子_ml-agents小狗-CSDN博客
Unity中训练一个ML-Agents项目—解决torch和mlagents配置问题_mlagents训练_LLLQQQismmmmme的博客-CSDN博客
Unity 对接 ML-Agents 初探_艾沃尼斯的博客-CSDN博客
GitHub - thinbug/MLApp
Unity之ml-agents(一):环境配置及初步使用_mlagents-CSDN博客
)








)
)



)




)