在生产环境中我们会遇到一些问题,此文主要记录并复盘一下当时项目中的实际问题及解决过程。
背景简述
最初系统上线后都比较正常风平浪静的。在系统运行了一段时间后,业务量上升后,生产上发现java应用内存占用过高,服务器总共64G,发现每个SpringBoot占用近12G的内存,我们项目采用微服务架构,有多个springboot应用。一下子内存就不够用了,springboot出现假死了。
由于当时生产没有截图,我用本机模拟类似的情况。

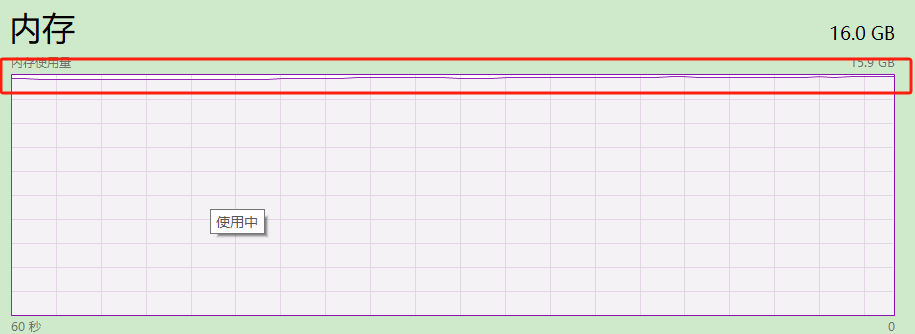
可以看到内存基本被使用完了,为什么Java程序会占用这么大内存呢?
解决步骤
step1:jps查看进程ID或通过top
step2:jmap -heap 进程ID
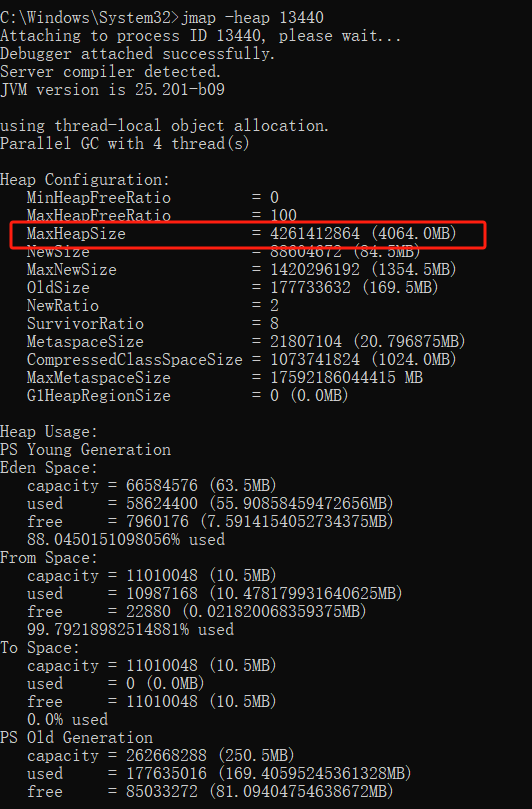
可以看到Java应用的最大堆内存是4G,当时我们生产是64G的物理内存,生产Java应用的最大堆内存是12G。
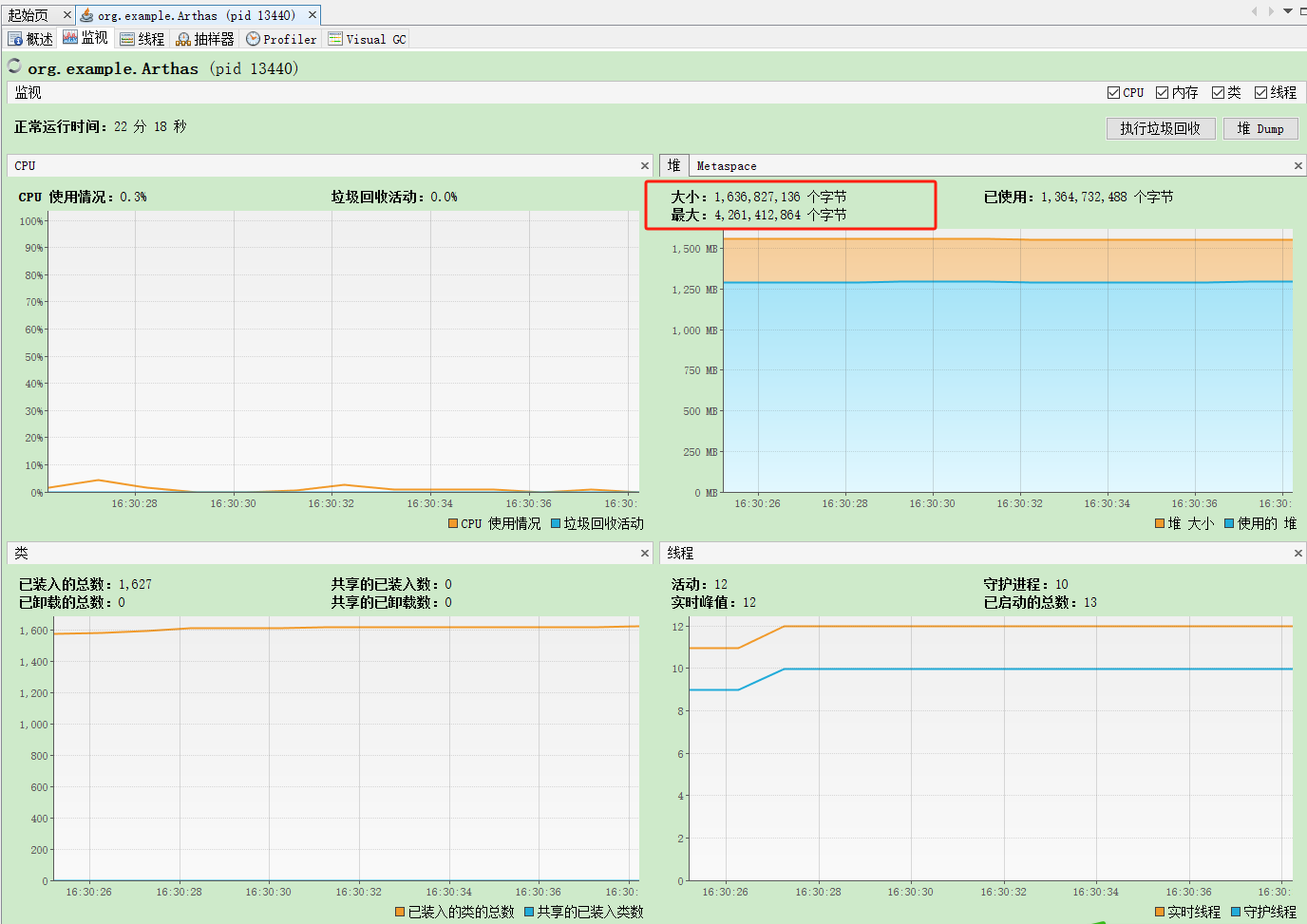
- 最大堆大小(-Xmx):通常为物理内存的1/4。
- 初始堆大小(-Xms):通常为物理内存的1/64。
以下是Oracle官方对JVM默认参数的详细说明:
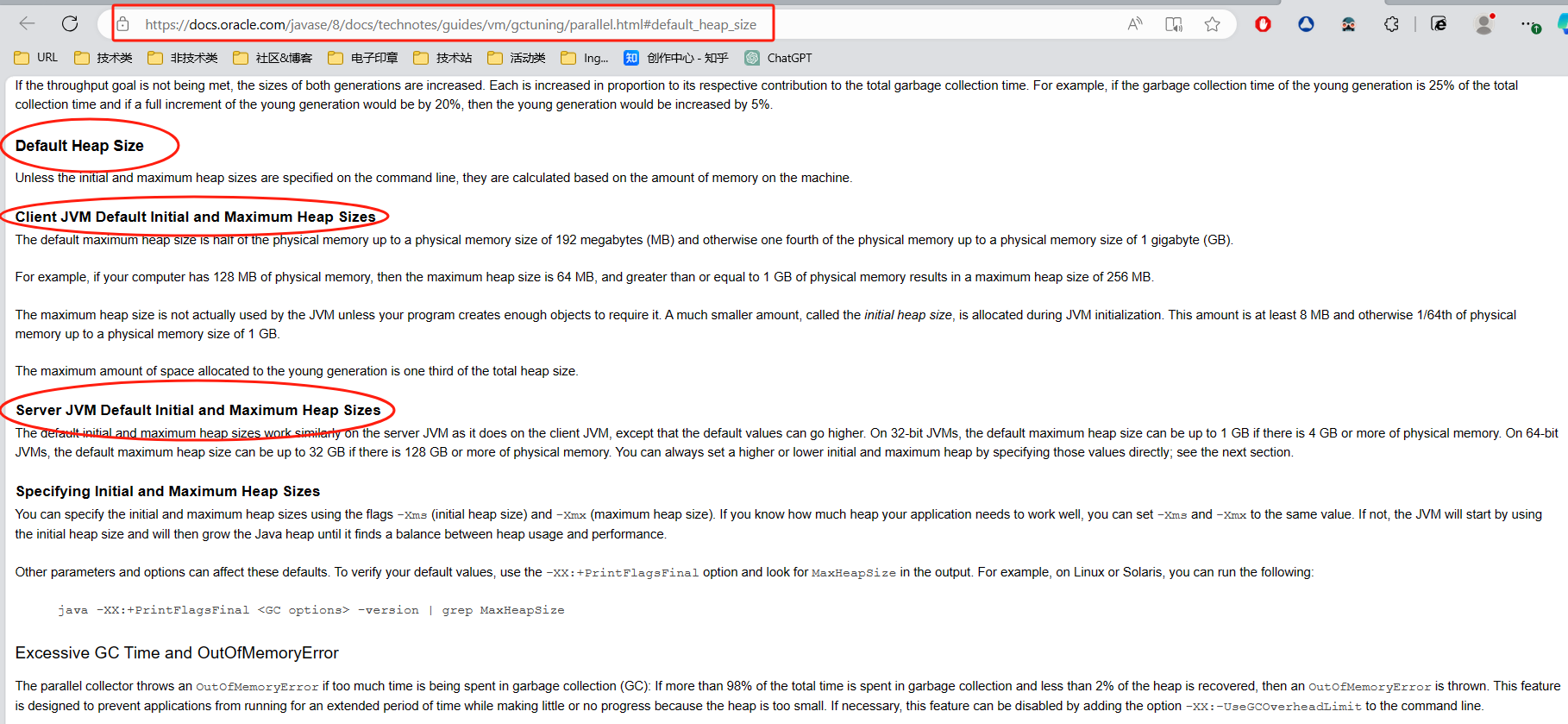
以下是对应的译文:
默认堆大小
除非在命令行中指定了初始堆大小和最大堆大小,否则它们是根据计算机上的内存量计算的。
客户端 JVM 默认初始和最大堆大小
默认最大堆大小是物理内存的一半(物理内存大小不超过 192 兆字节 (MB)),否则为物理内存的四分之一(物理内存大小不超过 1 千兆字节 (GB))。
例如,如果您的计算机有 128 MB 物理内存,则最大堆大小为 64 MB,大于或等于 1 GB 物理内存会导致最大堆大小为 256 MB。
JVM 实际上不会使用最大堆大小,除非您的程序创建了足够的对象来需要它。在 JVM 初始化期间分配的量要小得多,称为初始堆大小。此量至少为 8 MB,否则为物理内存的 1/64,最大物理内存大小为 1 GB。
分配给年轻代的最大空间量是总堆大小的三分之一。
服务器 JVM 默认初始和最大堆大小
默认初始堆大小和最大堆大小在服务器 JVM 上的工作方式与在客户端 JVM 上的工作方式类似,只是默认值可以更高。在 32 位 JVM 上,如果有 4 GB 或更多物理内存,则默认最大堆大小可达 1 GB。在 64 位 JVM 上,如果有 128 GB 或更多物理内存,则默认最大堆大小可达 32 GB。
到这里基本上可以看出是运维人员发布Java应用时并没有设置JVM参数,而是使用默认JVM参数。导致每个Java应用占用过高。虽然是小问题,但生产上每个Java占用12G内存还是比较吓人的。
复盘
一般内存占用过大的排查思路:
在排查内存占用过大的问题时,一般可以采取以下思路:
- 检查JVM参数: 如果在生产环境中启动Spring Boot没有设置JVM参数,使用默认的JVM配置,可能会导致性能问题和资源浪费。优化JVM参数,根据应用程序的需求和服务器配置进行调整。
- 观察内存使用情况: 使用监控工具或者操作系统提供的工具,观察Java应用的内存使用情况,包括堆内存、非堆内存、垃圾回收等。
- 分析GC: 如果发现内存问题,可以分析GC日志以了解垃圾回收的情况,包括频率、时间等。
- 合理设置堆内存大小: 根据应用程序的需求和服务器的物理内存,合理设置堆内存的大小,避免过大或过小导致性能问题。
- 考虑使用内存分析工具: 使用工具如VisualVM、MAT等,对应用程序进行内存分析,找出可能存在的内存泄漏或者大对象。

如果在生产环境中启动springboot没有设置jvm参数,使用默认的JVM配置,可能会有以下几个危害:
- 默认的JVM配置可能不适合你的应用程序的性能需求和资源限制,导致内存溢出、垃圾回收频繁、性能下降等问题。
- 默认的JVM配置可能会浪费服务器的内存资源,因为JVM会根据物理内存的大小来分配堆内存的大小,而不是根据应用程序的实际需求。
因此,建议在生产环境中启动springboot时,根据应用程序的特点和服务器的配置,合理地设置JVM参数,以提高应用程序的性能和稳定性,节省服务器的资源。





)

 计算两点云之间的最小距离)

函数)




![2023年中国高压驱动芯片分类、市场规模及发展趋势分析[图]](http://pic.xiahunao.cn/2023年中国高压驱动芯片分类、市场规模及发展趋势分析[图])
)



)