| 51.文献阅读笔记(KNN) | ||
| 简介 | 题目 | Exploring Nearest Neighbor Approaches for Image Captioning |
| 作者 | Jacob Devlin, Saurabh Gupta, Ross Girshick, Margaret Mitchell, C. Lawrence Zitnick, arXiv:1505.04467 | |
| 原文链接 | http://arxiv.org/pdf/1505.04467.pdf | |
| 关键词 | KNN、image caption | |
| 研究问题 | image captioning | |
| 研究方法 | explore a variety of nearest neighbor baseline approaches for image captioning。 首先查找相似图像,然后复制其标题来生成图像标题的方法 泛化到训练集以外的图像:测量每张测试图像与训练集中图像的相似度。然后,我们就可以检查各种方法在不寻常或更多样化的图像上的表现。 | |
| 研究结论 | 更灵活、更受喜爱 | |
| 创新不足 | 对于图片描述的评分有一定问题,对机器生成的文字评分更高,但是实际人类生成的文字更受喜爱。 | |
| 额外知识 | GIST | |
| 52.文献阅读笔记 | ||
| 简介 | 题目 | Language Models for Image Captioning: The Quirks and What Works |
| 作者 | Jacob Devlin, Hao Cheng, Hao Fang, Saurabh Gupta, Li Deng, Xiaodong He, Geoffrey Zweig, Margaret Mitchell, arXiv:1505.01809 | |
| 原文链接 | http://arxiv.org/pdf/1505.01809.pdf | |
| 关键词 | 现有方法性能比较 | |
| 研究问题 | image captioning | |
| 研究方法 | 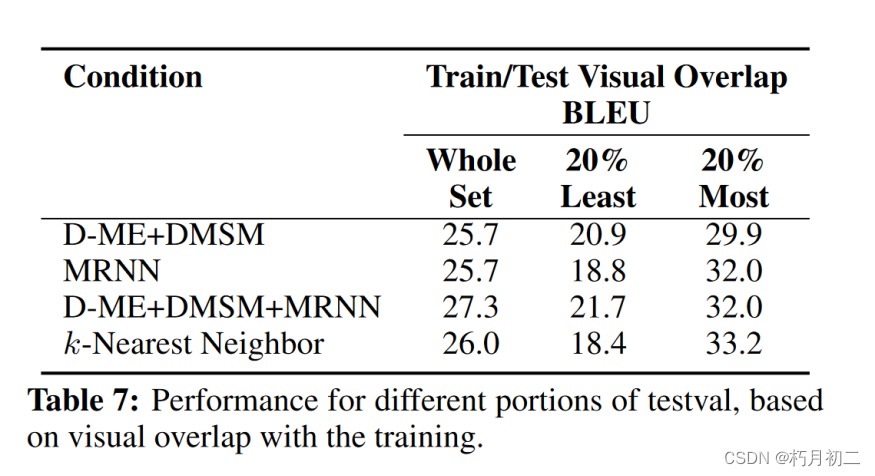 | |
| 研究结论 | 懒得看了 | |
| 创新不足 | ||
| 额外知识 | maximum entropy (ME) language model:最大熵( ME )语言模型 Cnn生成一组候选词,然后使用最大熵( ME )语言模型将这些词排列成一个连贯的句子。 第二种是将卷积神经网络的倒数第二个激活层作为循环神经网络( RNN )的输入,然后生成字幕序列。 BLUE评分: Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型 - Determined22 - 博客园 (cnblogs.com) | |
| 53.文献阅读笔记 | ||
| 简介 | 题目 | What Value Do Explicit High Level Concepts Have in Vision to Language Problems? |
| 作者 | Qi Wu, Chunhua Shen, Anton van den Hengel, Lingqiao Liu, Anthony Dick, arXiv:1506.01144 | |
| 原文链接 | arXiv:1506.01144 | |
| 关键词 | ||
| 研究问题 | 从视觉到语言(V2L)问题的最新进展主要是通过卷积神经网络(CNN)和循环神经网络(RNN)的结合实现的。这种方法并不明确表示高级语义概念,而是寻求从图像特征直接转化为文本。在本文中,我们将研究这种直接方法是否因其避免明确表示高级信息而取得成功。 | |
| 研究方法 | 提出了一种将高级概念纳入成功的 CNN-RNN 方法的方法。 我们的视觉属性作为图像内容的高级语义表征,被输入到一个 LSTM 中,该 LSTM 会根据更大的词汇量生成目标句子。 在主要的 CNN-LSTM 框架中引入中间属性预测层的效果。
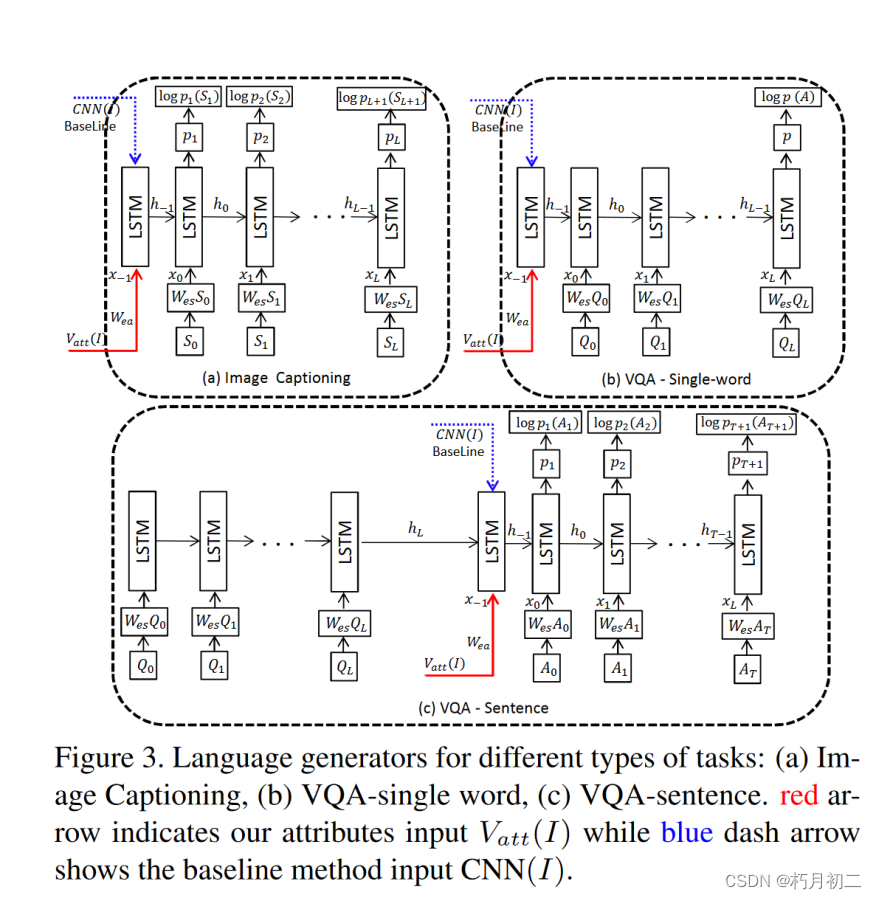 | |
| 研究结论 | 证明这种方法在图像字幕和视觉问题解答方面都比最先进的方法有显著提高。我们还证明,同样的机制可用于引入外部语义信息,并能进一步提高性能。 | |
| 创新不足 | ||
| 额外知识 | CNN 作为图像 "编码器",生成固定长度的向量表示,然后将其输入 "解码器 "RNN 以生成字幕。 | |

| 54.文献阅读笔记(有点注意力机制的意思) | ||
| 简介 | 题目 | Learning language through pictures |
| 作者 | Grzegorz Chrupala, Akos Kadar, Afra Alishahi, | |
| 原文链接 | arXiv:1506.03694 | |
| 关键词 | ||
| 研究问题 | ||
| 研究方法 | 提出了IMAGINET,一个从耦合的文本和视觉输入中学习基于视觉的语言表示的模型。该模型由两个具有共享词嵌入的门控循环单元网络组成,通过接收场景的文本描述并试图同时预测其视觉表征和句子中的下一个单词来使用多任务目标。
| |
| 研究结论 | 它从对视觉场景的描述中获得单个单词的意义表征。而且,它学会了在多词短语的语义解释中有效地使用序列结构。 | |
| 创新不足 | ||
| 额外知识 | ||

| 55.文献阅读笔记(对注意力机制的理解) | ||
| 简介 | 题目 | Describing Multimedia Content using Attention-based Encoder-Decoder Networks |
| 作者 | Kyunghyun Cho, Aaron Courville, Yoshua Bengio, | |
| 原文链接 | arXiv:1507.01053 | |
| 关键词 | ||
| 研究问题 | 基于注意力的编码器-解码器模型,四个最新应用:机器翻译、图像标题生成、视频描述生成和语音识别 | |
| 研究方法 | 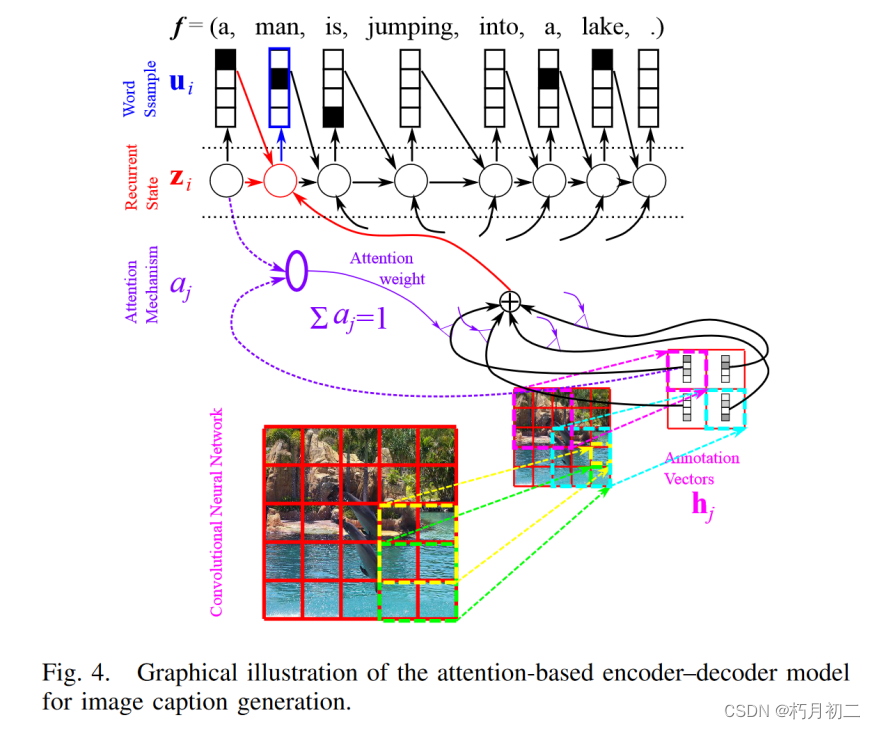 | |
| 研究结论 | ||
| 创新不足 | 这意味着注意力机制的最终目标是帮助编码器-解码器模型进行多媒体内容描述。然而,这不应被视为注意力机制唯一可能的应用。注意力机制除了能带来卓越的性能外,还能用于提取两种完全不同的模式之间的底层映射,而无需对映射进行明确的监督。基于注意力的模型能够以一种无监督的方式推断出不同模态(多媒体及其文本描述)之间的对齐方式,在没有太多先验知识/领域知识的情况下,这种基于注意力的模型完全可以用来从一对模态中提取这些潜在的、往往是复杂的映射。 | |
| 额外知识 | ||
| 56.文献阅读笔记 | ||
| 简介 | 题目 | Image Representations and New Domains in Neural Image Captioning |
| 作者 | Jack Hessel, Nicolas Savva, Michael J. Wilber, | |
| 原文链接 | arXiv:1508.02091 | |
| 关键词 | ||
| 研究问题 | 即使在图像表示质量很差的情况下,最先进的神经描述算法也能够产生高质量的描述。我们将这一结果复制到一个新的、细粒度的、迁移学习的字幕域中 | |
| 研究方法 | ||
| 研究结论 | 展示了 CNN 分类准确性与最先进的神经字幕算法生成的字幕质量之间的关系。训练越来越精确的图像分类器在达到一定程度后并不会带来更好的字幕。字幕质量的这种早期饱和现象表明,神经字幕生成算法的性能很可能无法通过生成更精确的 CNN 而直接提高。 此外,NIC 等模型输出的许多明显具有高度特异性的生成字幕很可能是由于语言模型捕获了粗粒度信息并生成了相应的可信自然语言序列。 图像特征过度拟合的作用很难量化。 一方面,图像表征中包含了额外的信息,而 NIC 等模型并没有利用这些信息,甚至通常会过度拟合图像表征。但是,目前还不清楚这些额外的、细粒度的信息是否值得考虑。基于离散图像表征生成语言的模型(例如(Young 等人,2014 年))所取得的成功表明,不考虑丰富的实值向量特征,算法也能达到最先进的性能。这些类型的模型很可能也不容易过度拟合。 | |
| 创新不足 | ||
| 额外知识 | ||
| 57.文献阅读笔记(RCCA)(图像查询) | ||
| 简介 | 题目 | Learning Query and Image Similarities with Ranking Canonical Correlation Analysis |
| 作者 | Ting Yao, Tao Mei, and Chong-Wah Ngo, ICCV, 2015 | |
| 原文链接 | ||
| 关键词 | ||
| 研究问题 | 图像搜索的基本问题之一是学习排名函数,即查询和图像之间的相似性。关于这一主题的研究已经发展出两种范式:基于特征的向量模型和图像排序器学习。前者依赖于图像周围的文本,而后者则根据人类标记的查询-图像对学习排序器。 | |
| 研究方法 | 向量模型对文本描述的质量很敏感,而学习范式则很难扩展,因为获得人工标注总是过于昂贵。我们在本文中证明,通过共同探索子空间学习和使用点击数据,可以很好地缓解上述两个局限性。具体来说,我们提出了一种用于学习查询和图像相似性的新颖的排序典型相关分析法(RCCA)。 RCCA 最初通过最大化查询和图像视图之间的相关性来找到它们之间的共同子空间,并进一步同时学习双线性查询图像相似性函数和调整子空间以保留点击数据中隐含的偏好关系。一旦子空间最终确定,查询-图像相似度就可以通过双线性相似度函数计算出它们在该子空间中的映射关系。 | |
| 研究结论 | ||
| 创新不足 | ||
| 额外知识 | ||










)
更新程序烧录刷机)


)




