背景
这篇论文是截至目前为数不多的介绍大模型训练配套环境比对的论文,对于想要入门大模型训练同学是个不错的入门资料。比较了不同尺寸模型(比较常用的7、13、70b),在不同型号gpu、训练框架、推理框架数据。
结合自己实际工作需要和论文给出的运行时数据分析,总结了下面几条:
1.二次预训练最低硬件配置,如果想要自己做简单二次预训练(7、13、70B参数)最小8卡80g显存A100
2.对于小规模sft对考虑PEFT做训练就可以,freezen fintune方法需要硬件还是较大
3.FlashAttention对向量并行化计算对训练起到加速作用,使用时候需要增大内存量
4.vLLM是一个在个硬件表现都不错的推理库,可持续关注
5.高性能卡(比如A800、A100)对于f全float优化做了很多优化,适合高性能高精度预训练
6.消费卡(RTX开头)对于低精度计算做了较多优化,比特化训练推理性价比高
大模型分布式系统
摘要
大型语言模型(LLMs)在学术界和工业界都取得了巨大的进步,它们的流行导致了许多开源框架和技术用于加速LLM的预训练、微调和推理。训练和部署LLMs需要大量的计算资源和内存,因此开发了许多高效的方法来改进系统管道以及操作符。然而,运行时性能在不同的硬件和软件堆栈之间可能会有显著的差异,这使得选择最佳配置变得困难。在这项工作中,我们旨在从宏观和微观的角度对性能进行基准测试。首先,我们对预训练、微调和服务不同大小的LLMs进行端到端的性能基准测试,即7、13和70亿参数(7B、13B和70B)在三个8-GPU平台上,包括和不包括个别的优化技术,包括ZeRO、量化、重计算、FlashAttention。然后,我们深入研究,提供了LLMs中子模块(包括计算和通信操作符)的详细运行时分析。对于终端用户,我们的基准测试和发现有助于更好地理解不同的优化技术、训练和推理框架,以及硬件平台,以选择部署LLMs的配置。对于研究人员,我们的深入模块分析发现了未来工作进一步优化LLMs运行时性能的潜在机会。
索引词 - 大型语言模型,性能评估,基准测试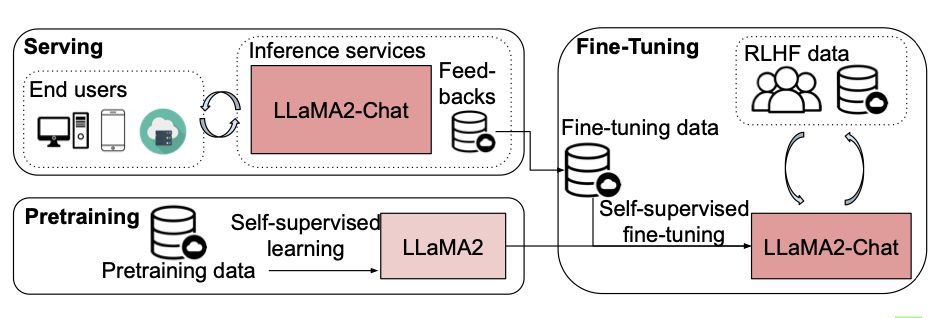
图1:使用Llama2 [9] 和Llama2-Chat作为例子部署LLM的流程,包含三个主要阶段:预训练、微调和服务。
I. 引言
近年来,大型语言模型(LLMs)在AI应用中变得非常流行,。随着LLMs的规模增大,它们在各种任务中展示出更好的泛化能力–。然而,最近的工作中模型的规模变得非常大,例如,GPT-3有1750亿个参数,PaLM有5400亿个参数。因此,训练和部署LLMs变得复杂且昂贵。
具体来说,LLMs的流程(如图1所示)有三个主要阶段,预训练、微调和服务,用于部署一个真实世界应用的LLM。首先,模型(例如,Llama2)在应用于下游任务之前,使用自监督学习进行预训练,这是LLM流程中最耗时的阶段。例如,预训练一个PaLM模型需要大约2.5 × 10^24次浮点运算(FLOPs),并且在6144个Google TPUv4芯片上执行时需要64天。其次,预训练的模型在下游任务或指令数据集上进行进一步的微调,以提高其在实际应用中的性能,例如,Llama2-Chat使用Llama2进行微调,并使用RLHF数据。第三,模型经过微调后(例如,Llama2-Chat),它被部署为一个网络(或API)服务,为给定的输入查询提供推理结果。
为了减少LLMs流程中的计算成本,已经提出了专用框架,用于有效的预训练(例如,DeepSpeed和Megatron-LM)、微调(例如,PEFT)和推理(例如,vLLM,LightLLM和TGI)。在每个框架内部,都应用了优化技术来提高内存和计算效率。具体来说,在预训练中,通常采用内存效率方法(ZeRO,激活重计算–,和量化)来使具有有限内存的GPU能够训练大型模型。在微调中,使用了参数高效微调(PEFT)方法,如LoRA,,通过调整适配器的参数而不是模型的全部参数来微调LLMs,以便具有有限内存的GPU能够微调LLMs。在LLM服务中,为了最大限度地利用部署中的GPU资源,对训练好的模型进行了量化和内核级优化。
然而,由于各种LLM框架和相关优化技术在不同类型的硬件上运行(例如,高端GPU如Nvidia A800和消费级GPU,例如Nvidia Geforce RTX4090和RTX3090),存在两个对最终用户和研究人员至关重要的未被充分探索的问题。首先,为了平衡效率和成本,特定应用的预训练、微调和部署LLMs需要什么配置?例如,8x A800 80GB GPU是否足以预训练一个7B模型,需要多长时间,以及应该启用哪种优化技术来加速训练?其次,现有的最先进的系统是否充分利用了GPU资源,性能瓶颈在哪里?特别是,在不同配置下,现代GPU服务器的计算和带宽资源的峰值利用率是多少?
为了解答这些问题,我们对LLM流程中现有系统在各种类型的GPU服务器上的运行时和内存性能进行了基准测试。具体来说,我们提供了以下详细的基准测试,以理解不同软硬件系统的时间和内存效率。
(1) 在框架级别,我们选择DeepSpeed和Megatron-LM来研究他们在三种类型的硬件(A800,RTX4090和RTX3090服务器)上对Llama2的训练性能,有三个规模(7B,13B和70B)。
** (2) 我们研究了整合ZeRO,量化,激活重计算和FlashAttention对内存和计算效率的影响。
(3) 我们评估了包括LoRA和QLoRA在内的流行PEFT框架,以理解他们的微调效率。
(4) 我们使用高度优化的推理库(包括vLLM,LightLLM和TGI)研究了端到端的推理性能。
(5) 为了深入理解性能,我们对最耗时的关键内核进行了微观基准测试。
通过全面的基准测试和分析,我们得出了以下重要的发现。
(1) DeepSpeed在所有配置中都比Megatron-LM实现了更高的吞吐量。
(2) ZeRO在不牺牲训练效率的情况下节省了大量的内存,或者当GPU的数量少于4时,它可能会遭受OOM。
(3) 内存卸载进一步减少了内存使用,但显著减慢了训练过程。
(4) 激活重计算只有在与其他优化技术结合使用时才能工作良好,否则它不能减少太多的内存消耗。
(5) 量化提高了训练速度,在所有硬件平台上实现了最大的吞吐量,与其他方法相比。然而,它可能导致收敛失败。
(6) FlashAttention在各种硬件平台上加速了训练过程,峰值内存消耗略高,可以与其他内存高效的方法迁移。 (7) PEFT方法使各种设备能够训练LLMs。
(8) 在A800平台上,LightLLM表现出优越的吞吐量。 相反,在24G GPU平台上,TGI展示了增强的吞吐量,而vLLM和LightLLM显示出相当的吞吐量水平。**
背景和初步研究
A. 仅解码器
基于Transformer的LLMs 预训练、微调、服务 软件 DeepSpeed (Q)LoRA vLLM TGI 解码器 RMSNorm 线性 传统的Transformer [24]由编码器和解码器组成,解码器已被广泛用于现代文本生成LLMs(例如,GPT-3 [25],Llama [26],Llama2GPU [9],BLOOM [27]等)。解码器的结构如图2所示。输入数据首先通过嵌入层进行编码,其输出被馈送到多个注意力块中。每个注意力块由一个多头注意力和一个前馈网络组成,前馈网络有几个线性层。然后,多个块的输出被连接作为下一个线性层的输入,称为生成或分类头,然后通过softmax层计算下一个标记的概率。
图2:仅解码器LLMs的解码器结构。
B. 预训练框架
DeepSpeed.
DeepSpeed [10]是一个用于大规模训练和推理的尖端深度学习(DL)优化软件套件。它采用了ZeRO,内存卸载,以及DeepSpeed-Inference 和其他技术。该软件被封装在一个开源库中,允许无缝地集成到训练和推理中。它已经在DL社区中被广泛采用,并且是微软AI at Scale倡议的基石。
Megatron-LM.
Megatron-LM ,解决了有效训练昂贵的Transformer模型的挑战。Megatron-LM对支持3D并行和激活重计算 进行了很好的优化。它还引入了序列并行,以与张量并行结合,因此它大大减少了激活重计算的需要。由于Megatron-LM具有很高的可扩展性,因此它已经成为一个常用的LLM训练系统。
C. 微调框架
微调LLM用于下游任务的直接方法是微调所有参数(即,Full-FT),但这非常消耗内存和时间。在实际应用中,参数高效微调(PEFT)[12]方法更受欢迎,因为它们比Full-FT需要更少的内存资源来微调模型。在PEFT中,LoRA [21](或QLoRA [22],LoRA的量化版本)和Prompt Tuning [32]是两种被广泛采用的方法。
LoRA.
低秩适应(LoRA)方法 [21]基于这样的观察,即超参数化模型通常在低内在维度内操作。对于预训练的权重矩阵W0 ∈ Rd×k,其更新受到低秩分解的约束:W0 + ∆W = W0 + BA,其中B ∈ Rd×r,A ∈ Rr×k,且秩r ≪ min(d,k)。在训练过程中,W0保持静态,不进行梯度更新,而A和B是可训练的。修改后的前向传递表示为h = W0x+∆Wx = W0x+BAx。因此,LoRA通过将LoRA秩r设置为预训练的权重矩阵来训练低秩矩阵,近似于Full-FT,并在推理过程中产生很小的额外开销。
QLoRA.
QLoRA [22] 是 LoRA 的量化版本。它将预训练的模型转换为特定的4位数据类型(NormalFloat 或 NF4),从而大大减少了内存使用量,并在保持量化过程中的数据完整性的同时提高了计算效率。
Prompt Tuning. Prompt tuning [32] 是一种专为将冻结的语言模型适应到特定下游任务而定制的新技术。具体来说,prompt-tuning 强调通过反向传播学习“软提示”,使它们可以使用标记示例的信号进行微调。
D. 推理框架
TGI.
文本生成推理(TGI)[15] 是一个专为部署和服务LLMs而设计的工具包。它迎合了一系列著名的开源LLMs,包括Llama系列 [,BLOOM 。它采用张量并行(或模型并行 )来加速多个GPU上的推理,并采用服务器发送事件(SSE)[34]进行令牌流。值得注意的是,TGI的连续批处理优化了对传入请求的处理,最大化了吞吐量。该工具包进一步通过优化的Transformer代码优化了推理,利用了诸如FlashAttention 和PagedAttention 等先进技术。
vLLM.
受操作系统中的虚拟内存和分页机制的启发,PagedAttention算法将动态变化的键值缓存(KV缓存)内存划分为较小的块,这些块可以放置在非连续的区域。这种方法解决了诸如碎片化等问题,为优化内存利用率铺平了道路。在PagedAttention的基础上,vLLM2是一个高吞吐量的LLM服务引擎。
LightLLM.
LightLLM 以其轻量级的架构、可扩展性和快速的性能,成为了一种尖端的、基于Python的LLM推理和服务框架。LightLLM采用了三进程异步协作方案,允许标记化、模型推理和去标记化同时进行,从而最大化GPU的利用率。此外,它引入了“Nopad”特性,以熟练地管理具有不同长度的请求,并引入了动态批处理调度机制,以简化请求处理。LightLLM的独特的基于令牌的KV缓存内存管理,被称为“Token Attention”,在推理过程中显著减少了内存使用。另一个特性是Int8KV Cache,它有效地将令牌容量增加了一倍。
E. 优化技术
ZeRO.
ZeRO串行技术(即,ZoRO-1/2/3 [16],ZeRO-Offload [28],和ZeRO-Infinity [29])优化了训练LLMs的内存效率。ZeRO-1将模型的优化器状态分布在各个GPU上,减少了这些状态所使用的内存。ZeRO-2在ZeRO-1的基础上增加了在各个GPU上对梯度的划分,进一步减少了梯度所需的内存。然而,ZeRO-2在反向过程中引入了额外的Reduce集合通信原语。基于ZeRO-1和ZeRO-2,ZeRO-3进一步增加了模型参数划分和激活的模型并行,最大化了内存节省,并允许以减少的通信开销训练更大的模型,但它需要额外的Reduce-Scatter来划分模型参数。有了ZeRO-Offload,作者们的目标是使十亿规模的模型训练更容易获得,弥合了计算需求和可用资源之间的差距。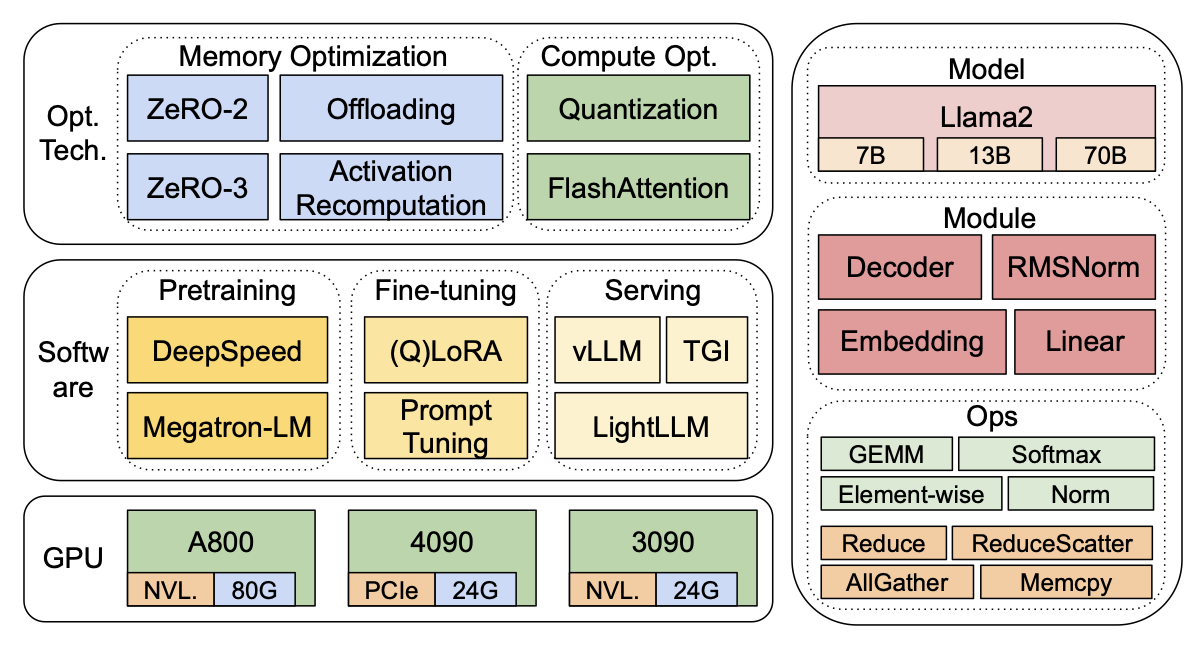
图3:我们的基准测试概览,涵盖了硬件、软件(包括有优化技术和无优化技术的情况)以及模型。
表I:GPU平台规格。每个平台都有8个GPU。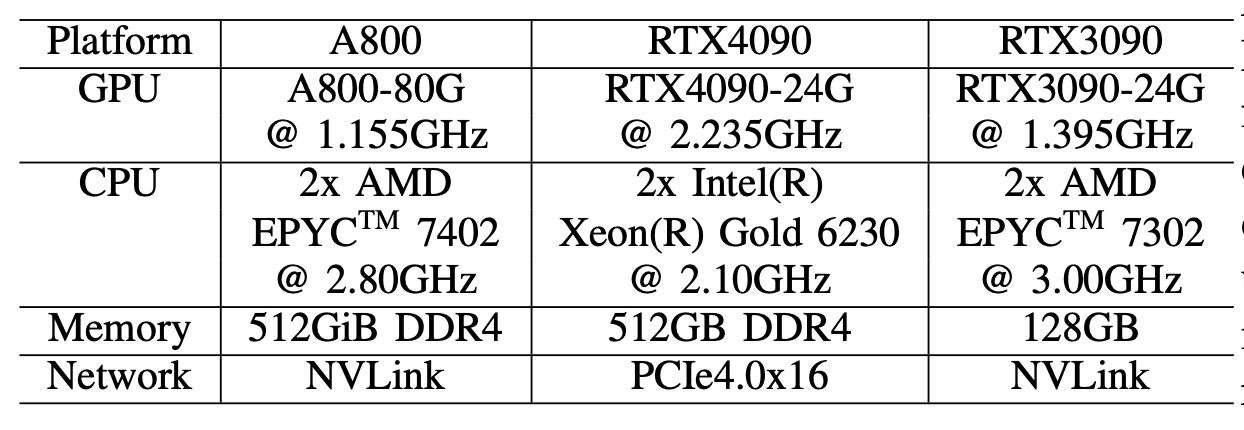
激活卸载.
激活卸载 是一种旨在有效管理训练和部署LLMs所固有的大量计算和GPU内存需求的技术。通过在神经网络的前向传递过程中选择性地将激活(中间神经元输出)从GPU内存转移到CPU内存或磁盘存储,并在反向传递过程中重新加载它们进行梯度计算,激活卸载有助于内存和计算资源的优化。此外,可以采用两种主要方法,优化器卸载和模型参数卸载,来显著减轻GPU内存的压力。然而,这引入了额外的数据传输开销。
激活重计算. 它涉及到在训练的反向传递过程中重新计算中间激活,而不是从前向传递中保留它们,以便优化内存使用。通过避免为模型的每一层存储激活,它可以显著减少内存消耗。然而,这种方法引入了额外的计算开销。虽然内存的好处是实质性的,但重计算过程需要对传统的反向传播算法进行修改,增加了训练范式的复杂性。
量化.
量化是一种重要的技术,用于使用低位格式表示权重或激活,以减少内存大小和计算时间。ZeroQuant 是一种流行的系统,它引入了一种新颖的后训练量化方法,并开发了一种对权重和激活都友好的硬件量化方案,一个独特的逐层知识蒸馏算法,以及一个高度优化的量化系统后端。它已经展示了将BERT和GPT-3等模型的权重和激活的精度降低到INT8的能力,同时几乎不降低精度。
FlashAttention.
FlashAttention ,是专门为解决Transformer在处理大量序列时所面临的固有挑战而定制的。这种算法是IO感知的,它优化了GPU内存级别之间的相互作用。它利用切片技术减少了GPU的高带宽内存(HBM)和片上静态随机存取内存(SRAM)之间的内存读/写,以提高注意力效率。
III. 方法论
我们的基准测试使用自上而下的方法,涵盖了在图3所示的三个8-GPU硬件平台上Llama2 [9] 的端到端步骤时间性能、模块级时间性能和操作符时间性能。
GPU.
在硬件评估方面,我们涵盖了三款8-GPU平台,其中的配置显示在表I中。在这些平台上,我们使用不同的软件(例如,DeepSpeed和Megatron-LM)测量LLMs在预训练、微调和服务中的时间性能。
软件.
在软件评估方面,我们比较了DeepSpeed和Megatron-LM在预训练和微调中的端到端步骤时间。为了评估优化技术,我们使用DeepSpeed一一启用这些优化(即,ZeRO-2,ZeRO-3,卸载,激活重计算,量化和FlashAttention)来测量时间和内存消耗的性能改进和降级。在LLM服务上,有三个高度优化的系统,vLLM [13],LightLLM [14],和TGI [15]。我们在三个测试平台上比较他们的性能(延迟和吞吐量)。为了深入理解端到端性能,我们提供了模型模块和操作符性能的微观基准测试,这些是预训练、微调和推理服务流程中的基本组件。
A. 测量端到端性能
我们通过使用步骤时间、吞吐量和内存消耗的指标,在四个测试平台上测量预训练、微调和服务三种大小的Llama2模型(Llama2-7B,Llama2-13B和Llama2-70B)的端到端性能。
预训练(§IV)。
我们首先比较DeepSpeed和Magetron-LM之间的性能(吞吐量、时间和内存)差异。然后,我们使用DeepSpeed来评估优化技术ZeRO-2,ZeRO-3,卸载,激活重计算,量化和FlashAttention对我们的测试平台上的时间和内存效率的影响。为了理解导致测量性能的根本原因,我们进一步测量了模块和操作符的性能。
微调(§V)
我们比较了两种流行的微调技术,LoRA和QLoRA,以及基线(全参数调整,或Full-FT)在四个测试平台上的吞吐量和内存消耗的指标。
推理服务(§VI)
我们使用三个测试平台评估三个广为认可的推理服务系统:vLLM [13],LightLLM [14],和TGI [15],重点关注延迟、吞吐量和内存消耗等指标。最初,我们为这些框架的每一个部署了API服务器。随后,我们使用一个基准测试脚本,利用asyncio,向模型服务器发送HTTP请求。为了全面利用计算资源并评估框架的鲁棒性和效率,所有的请求都以突发模式发送。实验数据集由1000个合成句子组成,每个句子包含512个输入令牌,确保了一致的评估环境。我们在同一GPU平台上的所有实验中一致地维护了“最大生成令牌长度”参数,以保证结果的一致性和可比性。由于RTX40X0 GPU系列存在一个公认的bug3,为了纠正这个问题并确保推理框架在RTX4090上正常工作,我们应用了配置NCCL_P2P_DISABLE=1。然而,这种配置可能会影响最终的性能,使RTX4090相对于其他平台处于不利地位。
表II:在8-GPU A800-80GB平台上预训练Llama2-7B时,Megatron和Deep-Speed的性能比较。 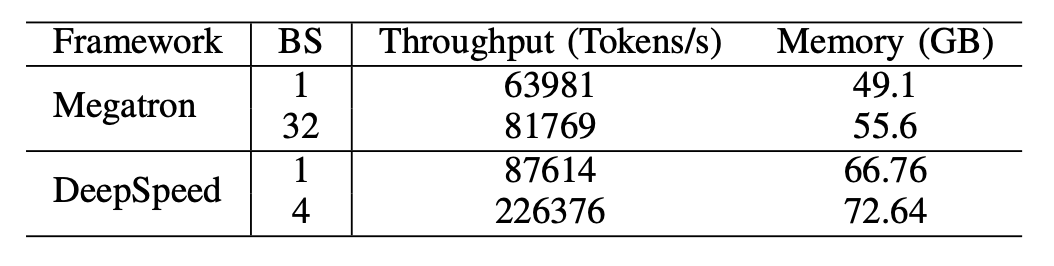
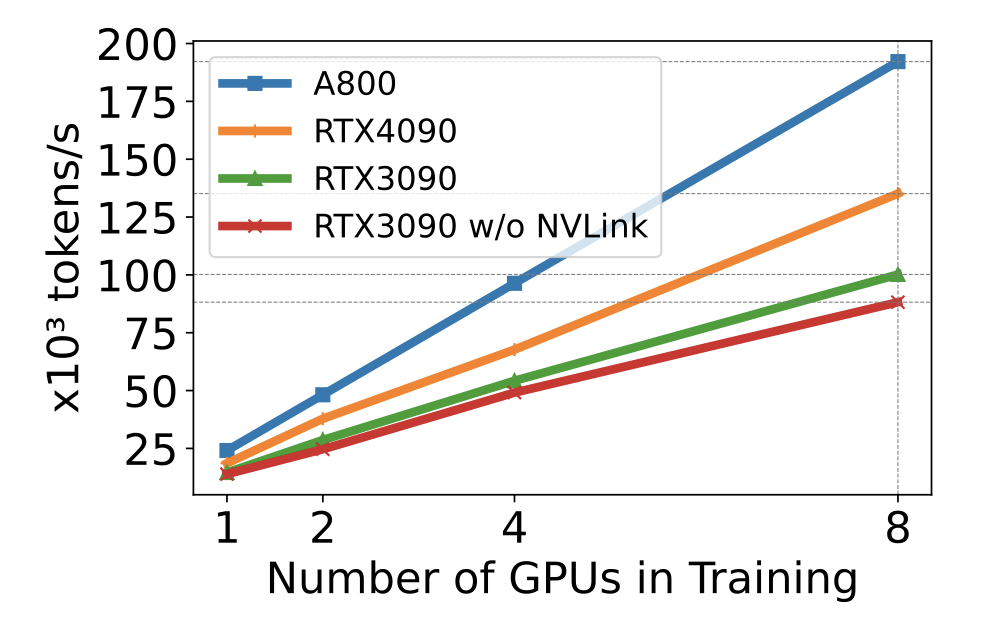
图4:在不同规模的GPU下训练Llama2-7B时的数据并行训练效率。
B. 测量模块级性能
LLM通常由一系列模块(或层)组成。以Llama2模型为例。顶级类LlamaForCausalLM由一个LlamaModel模块和一个用于下游任务的线性层组成。每个模块都有自己的子模块,这些子模块可能具有独特的计算和通信特性。具体来说,LlamaModel由一个嵌入层和多个解码器层(LlamaDecoderLayer)组成,LlamaDecoderLayer的数量是可配置的。LlamaAttention是自注意力层,由四个线性层组成,用于计算Q、K、V和O投影,以及一个嵌入层(LlamaRotaryEmbedding)。LlamaMLP由三个大小可配置的线性层和一个SiLU激活层(SiLUActivation)组成。LlamaRMSNorm是RMS规范化层。总的来说,构成Llama2模型的关键模块是嵌入(原生嵌入和LlamaRotaryEmbedding)、LlamaDecoderLayer、线性、SiLUActivation和LlamaRMSNorm。
在微调中,不同的方法引入了额外的模块来更新模型参数或适配器参数。特别地,LoRA需要额外的线性层,即低秩适配器。QLoRA与LoRA有相似的训练范式,但其计算使用低位表示,导致低精度的线性层,如8位或4位的线性层。
IV. 预训练结果
在本节中,我们首先分析了在四个测试平台上不同模型大小(7B,13B,70B)的预训练性能(迭代时间或吞吐量和内存消耗)(§IV-A),然后进行了模块级和操作级的微观基准测试(§VII)。除非另有说明,每个任务的每个指标(迭代时间或吞吐量和内存消耗)都测量三次,报告平均值。
A. 端到端性能
- Megatron-LM vs. DeepSpeed:
我们首先进行了一个实验,比较了Megatron-LM和DeepSpeed在A800-80GB服务器上预训练Llama2-7B的性能,这两者都没有使用任何内存优化技术,例如ZeRO。我们使用1024的序列长度,以及两组批量大小(BS)对于Megatron-LM和DeepSpeed,从1到最大批量大小。我们报告了训练吞吐量(每秒令牌数,或tokens/s)和消耗的GPU内存(以GB为单位)作为基准。结果显示在表II中。结果显示,当批量大小等于1时,DeepSpeed的性能略优于Megatron-LM,当它们达到最大吞吐量时,差距扩大。由于DeepSpeed的数据并行训练,它在训练速度方面领先。然而,在相同的批量大小下,DeepSpeed消耗的GPU内存比基于张量并行的Megatron-LM更多。即使批量大小很小,这两个系统也占用了大量的GPU内存,导致在RTX4090或RTX3090 GPU服务器上出现内存溢出(OOM)。
- GPU缩放效率:
我们使用DeepSpeed和量化来研究不同硬件平台上训练Llama2-7B(序列长度为1024,批量大小为2)的缩放效率(从1个GPU到8个GPU)。结果显示在图4中,其中斜率表示缩放效率。该图显示,A800几乎是线性缩放,而RTX4090和RTX3090的缩放效率略低(分别为90.8%和85.9%)。RTX4090的缩放效率比RTX3090高4.9%。在RTX3090平台上,NVLINK连接有助于提高缩放效率,比没有NVLINK高10%。
- 硬件和优化技术:
我们使用DeepSpeed来评估在不同的内存和计算效率方法下的训练性能。我们在所有的评估中使用1024的序列长度和1的批量大小,以进行公平的比较,并默认将模型权重加载到bf16中进行所有的实验。对于ZeRO-2和ZeRO-3与卸载,我们分别将优化器状态和优化器状态+模型权重卸载到CPU RAM。对于量化,我们使用4位的双重量化配置,如前一项研究[22]所建议。我们还报告了在禁用NVLink时RTX3090的性能,即所有数据都通过PCIe总线传输,结果显示在表III中。
硬件影响。
(1) A800的吞吐量超过RTX4090和RTX3090 GPUs的50倍,在所有评估的情况下,除了量化。在使用量化的情况下,RTX GPUs可以达到A800性能的一半。
(2) RTX4090比RTX3090好50%,并且RTX3090中的NVLink有助于提高性能约10%。
(3) 由于A800有80GB的内存,而RTX4090和RTX3090每个只有24GB,所以一些情况,例如,Naive和ZeRO-2不能在RTX4090和RTX3090 GPUs上运行。
优化技术。
在预训练Llama2-7B时,ZeRO-2的GPU内存消耗约为Naive的57%,而不牺牲模型性能和训练效率。同时,ZeRO-3的性能略低于ZeRO-2,但内存消耗较少。然而,当预训练Llama2-13B时,ZeRO-3的性能超过了ZeRO-2。这种差异是因为分片全模型状态有助于进一步减少通信,特别是在训练更大的模型时。卸载显著地减慢了训练过程,因为它将一些分片和计算卸载到RAM和CPU,并减少了GPU内存的消耗。量化在所有硬件平台上都实现了最高的吞吐量,但可能影响收敛。FlashAttention也加速了训练,可以与诸如ZeRO之类的内存效率方法一起使用。激活重计算进一步减少了GPU内存使用,但降低了吞吐量。注意,当批量大小=1时,激活内存很小,激活重计算可以在更高的批量大小下节省更多的内存。在表III中,当使用ZeRO或卸载时,同一方法的内存消耗在各个平台上有所不同,具体来说,它在A800上占用的内存比其他平台多。这种差异是因为在分片和卸载中,内存被固定在CPU上,句柄根据可用的物理内存动态加载到GPU内存中,而A800的物理内存比其他平台大。这个表也证明,训练Llama2-13B达到了Llama2-7B训练的吞吐量的一半,对于Llama2-7B和Llama2-13B之间的这种模型性能,训练一个有13B参数的模型可能比一个7B模型更好。我们进一步利用不同GPU服务器的计算能力,通过最大化每种方法的批量大小来获得最大的吞吐量。结果显示在表IV中。这个表显示,增大批量大小容易提高训练过程,这也使通信和GPU计算重叠。因此,具有高带宽和大GPU内存的GPU服务器更适合进行全参数混合精度预训练,而不是消费级GPU服务器。
表III:在四种类型的8-GPU平台上,对基线设置(Naive)、ZeRO-2(Z2)和3(Z3)、卸载(O)、量化(Q)、激活重计算(R)和FlashAttention(F)进行预训练性能比较。我们以103 tokens/s(T/s)为单位报告吞吐量,平均值为三次独立运行的平均值,每个吞吐量值的右下角显示标准偏差,以及峰值GPU内存使用量(M)以GB为单位。在每次运行中,吞吐量是在30个预热步骤后的100个步骤的平均值。"-"表示OOM。 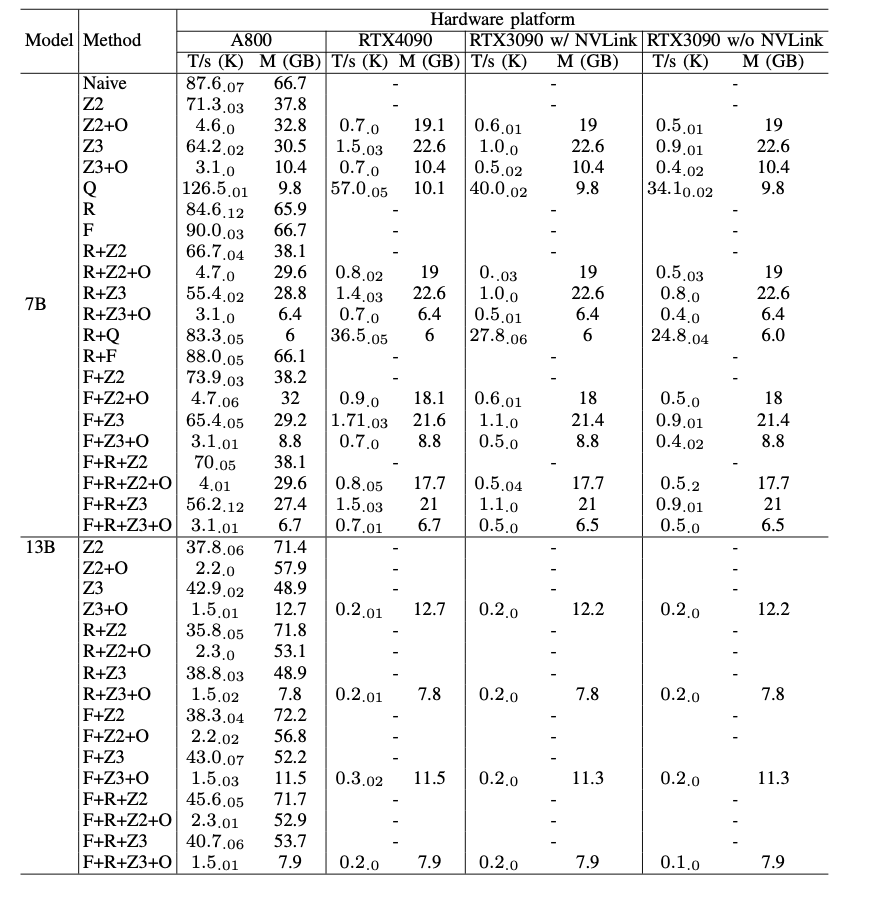
表IV:在最大化批量大小以获得最大吞吐量时,6种方法的预训练性能比较。我们使用与表III相同的配置。 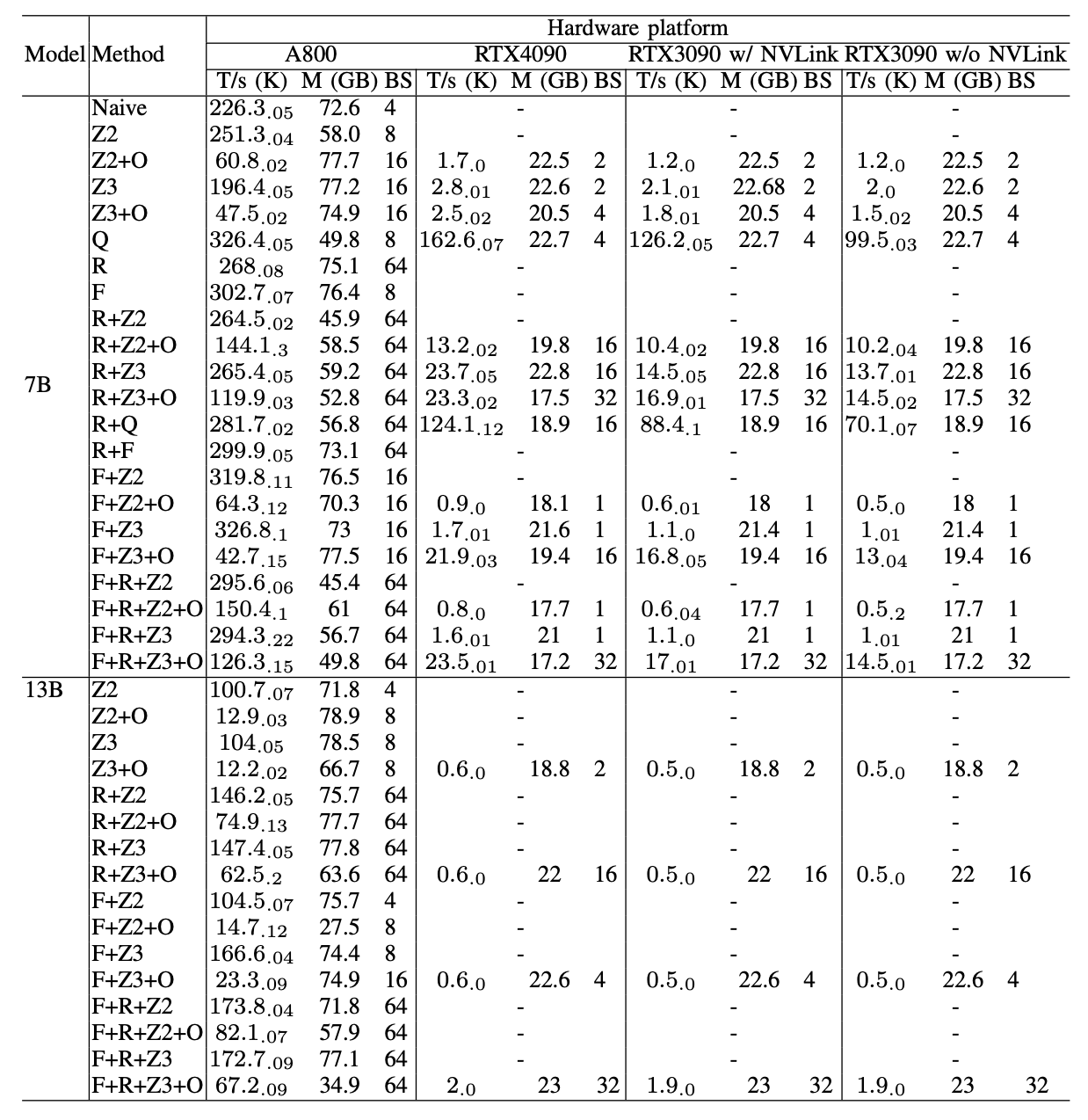
表V:预训练Llama2-7B模型的一步中,前向、反向和优化器的总体和计算内核时间成本。
*对于反向阶段,由于总体时间包括非重叠时间,所以计算内核时间的百分比明显低于前向阶段和优化器。如果从反向阶段中去除非重叠时间,这个值变为94.8%。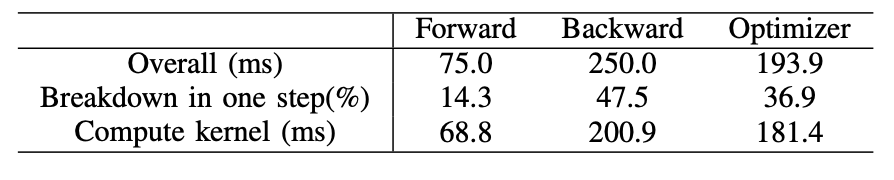
B. 模块级分析
为了更好地了解预训练性能,我们对预训练过程进行了详细的模块级分析。具体来说,我们选择了在A800平台上的Llama2-7B模型,以确保所有的案例都可以进行性能分析。为了确保结果的准确性和可重复性,我们计算了LLM常用数据集alpaca的指令、输入和输出的平均长度,并随机生成了固定长度的字符串作为我们性能分析的输入。我们使用“torch.profiler”生成了追踪,本节中呈现的所有性能数字都是十步的平均值。实验设置与第IV-A节中描述的一致。
考虑到A800的内存容量,我们将批量大小设置为2。在一个预训练步骤中,前向、反向和优化器阶段所消耗的时间详见表V。值得注意的是,大约37%的时间被用于优化器,这与预期不符,因为优化器只有元素级操作。我们在第IV-C节中分析了这种现象,重点关注了重计算的影响。
我们对前向和反向阶段进行了模块级时间分析,结果显示在表V中。在Llama2中,基于Transformer-decoder架构构建的解码器层占据了大部分的计算时间。具体来说,多层感知器(MLP)和查询、键和值(QKV)投影,这些都依赖于通用矩阵乘法(GEMM)操作,是最耗时的组件。此外,由于元素级操作的数量众多,RMSNorm和RoPE模块也需要大量的时间。与前向阶段相比,反向阶段需要额外的通信开销来进行GPU之间的梯度同步。
C. 重计算和FlashAttention的影响
加速预训练的技术大致可以分为两类:节省内存以增加批量大小和加速计算内核。如表5所示,GPU在前向、反向和优化器阶段的空闲时间为5-10%。我们认为这个空闲时间是由于批量大小较小。我们测试了可以使用所有可用技术的最大批量大小,并发现重计算可以将批量大小从2增加到最大的32。因此,我们选择重计算来增加批量大小,选择flashattention来加速计算内核分析。
重计算。
随着批量大小的增加,前向和反向阶段的时间显著增加,GPU的空闲时间很少(表VII)。优化器根据优化器状态更新模型参数,因此这个过程将有很多元素级操作,尽管批量大小增加,时间消耗将保持不变。相反,前向和反向阶段有很多批量操作,这将随着批量大小的增加而增加时间消耗。因此,当批量大小相对较小时,优化器所占用的时间比例会相对较大;当使用重计算技术进行大批量大小的预训练时,优化器所占用的时间比例会非常小。
表VI:Llama2-7B的前向和反向阶段的模块级时间消耗和百分比。解码器层中模块的时间消耗是32次迭代的累积时间。 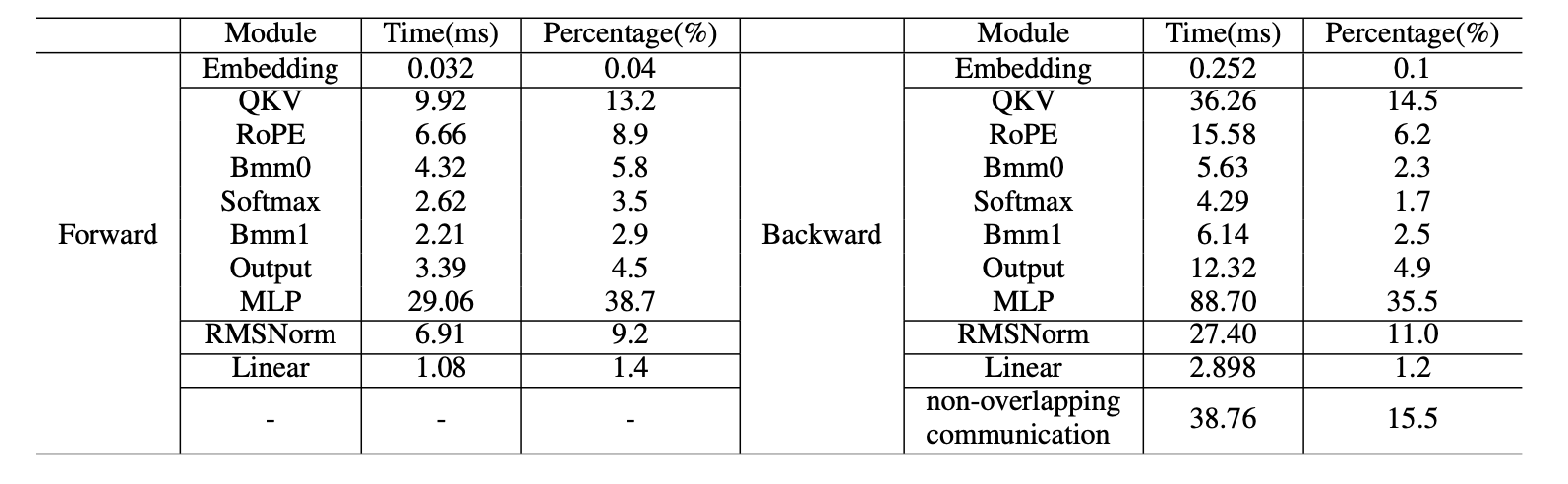
表VII:预训练Llama2-7B模型的一步中,前向、反向和优化器的总体和计算内核时间消耗。 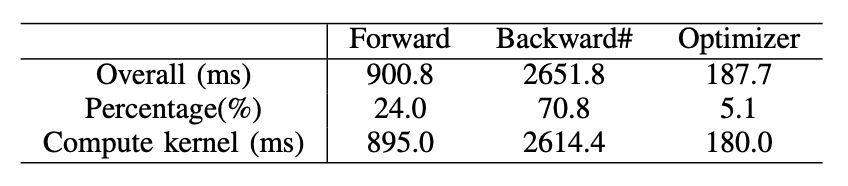
图5:没有(批量大小2)和有(批量大小32)重计算的解码器层模块的时间分解。 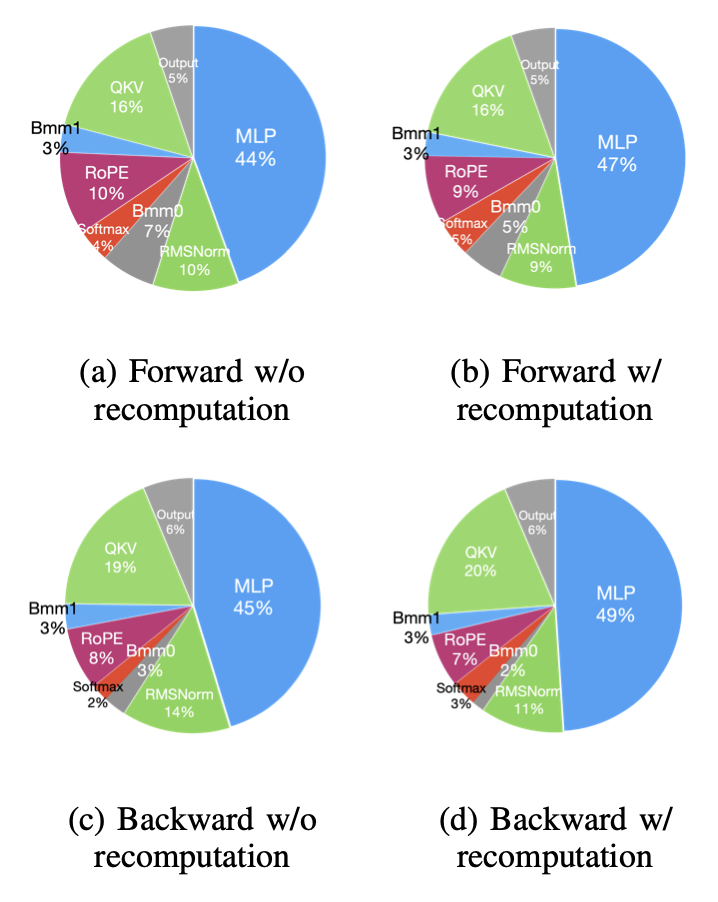
表VIII:在朴素和FlashAttention方法中,注意力模块时间消耗的比较。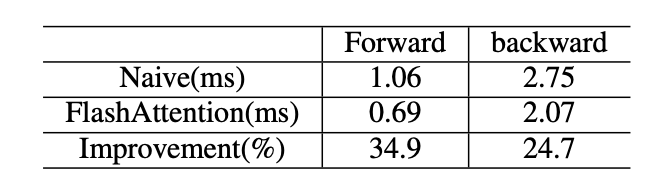
为了进一步探索更大批量大小对预训练性能的影响,我们比较了在前向和反向(在反向中去除重计算部分)阶段使用和不使用重计算(即,比较批量大小=32和批量大小=2)的解码器层模块所占用的时间百分比。因为反向阶段的重计算部分实质上是重新运行前向阶段,所以我们在分析时分别对前向和反向阶段进行分析。图5显示,当批量大小从2增加到32时,前向和反向阶段的模块在时间分解中的变化不大。这是因为,元素级操作是内存受限的,它们的运行时间大致与批量大小线性缩放。相比之下,解码器层中的GEMM操作是计算受限的,改变批量大小通常只影响M、N或K中的一个,所以运行时间也随着批量大小线性增长。
FlashAttention将KTQ、softmax、PV(P=softmax( K T Q ))和一些元素级操作融合到一个内核中,使用更多的访问低延迟高带宽的GPU SRAM,并减少访问高延迟低带宽的GPU DRAM。表VIII显示,这种技术可以分别提高注意力模块的34.9%和24.7%的速度。
在微调中,我们主要关注参数有效的微调方法,即PEFT方法,因为全参数训练已经在第IV-A节中讨论过。我们报告了LoRA和QLoRA在各种模型大小和硬件设置下的微调性能。我们使用1024的序列长度,1的批量大小,64的LoRA等级,并默认将模型权重加载到bf16中。对于QLoRA,我们采用4位双重量化的配置[22]。我们还将LoRA和QLoRA与其他技术结合,其配置与第IV-A节中描述的一致。Llama2-7B的微调结果显示在表IX中。
表IX显示,使用LoRA和QLoRA微调Llama2-13B的性能趋势与微调Llama2-7B的性能趋势保持一致,即,在所有的评估中,LoRA的吞吐量大约是QLoRA的2倍,这主要是由于量化和反量化操作的开销。然而,QLoRA的内存消耗是LoRA的一半。FlashAttention和ZeRO-2可以与LoRA在微调中结合,分别在所有硬件平台上获得比LoRA高20%和10%的吞吐量。ZeRO-3或卸载在LoRA微调中表现不佳,因为LoRA只更新一小组参数,即低秩适配器。由于优化器状态只处理LoRA参数更新,这不是计算受限的,卸载或分片这样一小部分状态,将引入与计算时间相比的通信开销,同时它不能减少太多的内存。
微调Llama2-13B的吞吐量比微调Llama2-7B减少了大约30%。当所有的优化技术都结合在一起时,甚至RTX4090和RTX3090都可以微调Llama2-70B,总吞吐量约为每秒200个令牌。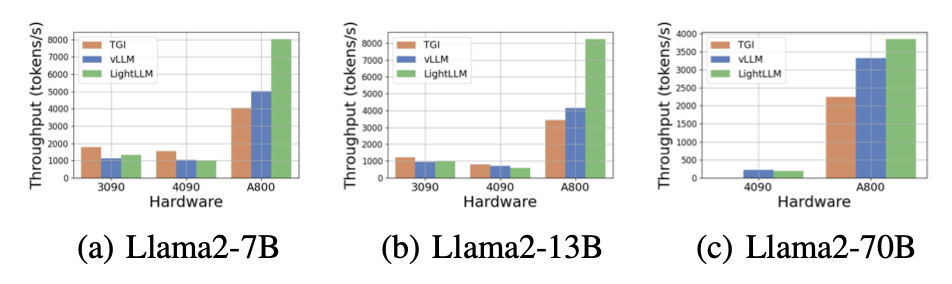
图6:在不同的GPU平台上,随着LLM大小的变化,吞吐量性能的比较。
VI. 推理结果
A. 端到端性能
吞吐量。
我们在图6中展示了各种硬件平台和推理框架的吞吐量比较分析。由于Llama2-70B模型在RTX3090和RTX4090上使用TGI框架会引发OOM错误,因此在图6中省略了与Llama2-70B相关的数据推理。TGI框架表现出优越的吞吐量,特别是在具有24GB内存的GPU上,如RTX3090和RTX4090。相比之下,LightLLM在A800 GPU平台上的性能显著优于TGI和vLLM,吞吐量几乎翻倍。这些实验表明,TGI推理框架在24GB GPU平台上表现出优越的性能,而LightLLM推理框架在A800 80GB GPU平台上表现出最高的吞吐量。这个发现表明,LightLLM专门针对高性能GPU进行了优化,如A800/A1000系列。
延迟。
我们在图7、图8、图9和图10中展示了各种硬件平台和推理框架的延迟比较分析。我们使用累积分布函数(CDF)来绘制不同推理框架的延迟。CDF表示一个变量取小于或等于样本空间中特定点的值的概率。例如,在图7a中,LightLLM需要大约20秒的时间来响应60%的请求,需要大约80秒的时间来响应100%的请求。
在图7中,我们比较了同一GPU平台上三个推理框架的延迟。RTX3090和A800平台上的性能表现出类似的趋势,TGI显示出最低的延迟,其次是LightLLM,vLLM的延迟最高。在图9中展示了更多的实验。
图9是图7的扩展,包含了同一GPU平台上的推理基准的额外延迟实验。RTX4090平台上的性能结果与其他两个平台不同。这种差异可能是由于NCCL_P2P_DISABLE=1的设置。在RTX4090平台上,LightLLM显示出最高的延迟,而TGI对于Llama2-7B模型有最低的延迟。从延迟实验中得到的另一个明显的发现是,在消费级GPU平台上,随着模型参数大小的增加,总推理时间会增加。具体来说,在RTX4090平台上,Llama2-7B和Llama2-70B之间的推理时间差可以达到13倍,从120秒增加到1600秒。然而,这种现象在A800 GPU平台上并未观察到,在这个平台上,对于较大模型的推理时间保持在一个较窄的范围内。这表明,对于目前流行的LLM大小,A800平台可以处理推理,而不会产生任何延迟影响,而且70B模型还没有达到A800平台推理的性能极限。
在图8中,我们比较了不同GPU平台上每个推理框架的延迟。在几乎所有的实验中,A800始终表现出最低的延迟。此外,RTX3090 GPU平台在大多数实验中的延迟比RTX4090低,这种情况也可能是由于NCCL_P2P_DISABLE=1的设置。这些实验表明,如果一个人的目标是一个具有最小延迟的推理服务,A800 GPU平台是最好的选择,它在各种模型和推理框架组合中都提供了显著的性能优势。在图10中展示了更多的实验。
表IX:在4种类型的8-GPU服务器上,使用LoRA(L)、QLoRA(QL)以及不同的优化方法(包括ZeRO阶段2和3(Z2,Z3)、FlashAttention(F)、卸载(O)、激活重计算(R))进行微调性能比较:A800,RTX4090,RTX3090 w/ NVLink和RTX3090 w/o NVLink。批量大小固定为1。我们报告了三次独立运行的平均吞吐量103 tokens/s(T/s)及其标准偏差,以及峰值GPU内存使用量(M)以GB为单位。在每次运行中,吞吐量是在30个预热步骤后的100个步骤的平均值。 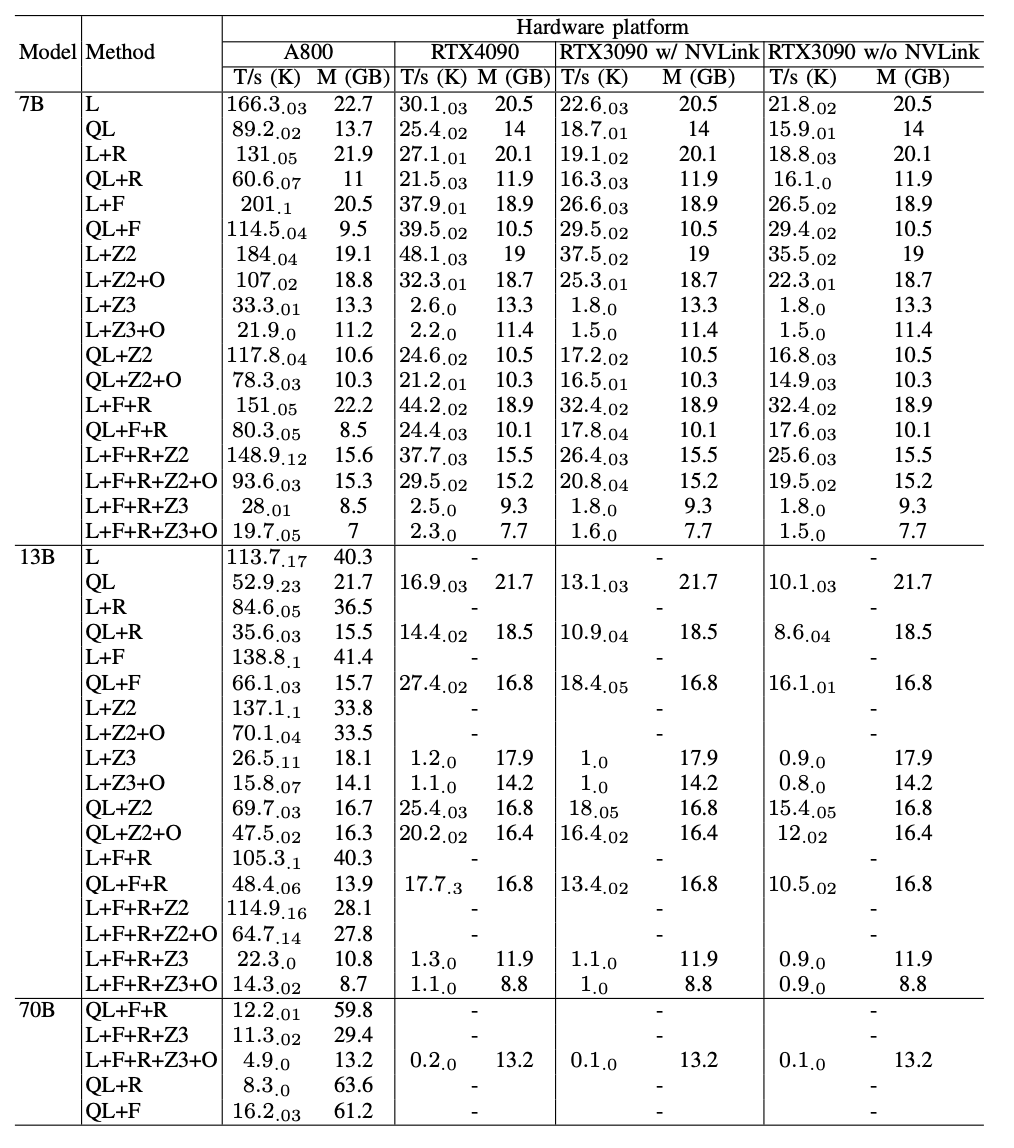
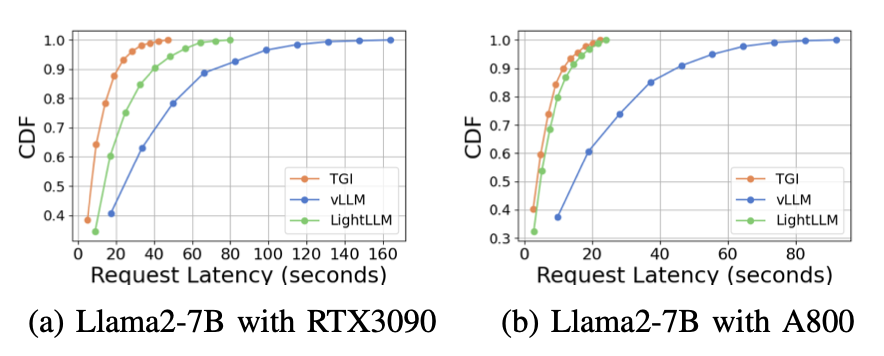
图7:在同一GPU平台上,使用不同推理框架的延迟比较。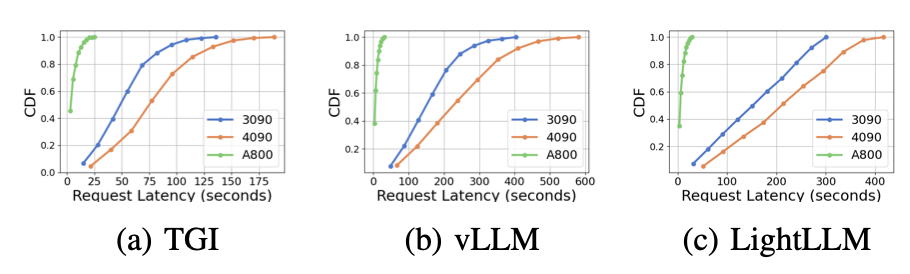
图8:在不同GPU平台上,使用Llama2-13B的延迟性能比较。
图10是图8的扩展,包含了对同一推理框架进行推理基准测试的额外延迟实验。 总的来说,A800平台在吞吐量和延迟方面明显优于其他两个消费级平台。在这两个消费级平台中,RTX3090比RTX4090有轻微的优势。在消费级平台上运行时,三个推理框架在吞吐量方面没有显著差异。相比之下,TGI框架在延迟方面始终优于其他框架。在A800 GPU平台上,LightLLM在吞吐量上表现最好,其延迟也非常接近TGI框架。
B. 模块级分析
在这个小节中,我们以LightLLM为例,讨论了模块级时间成本。我们将批量大小设置为1024,以模拟大量用户使用服务的场景,输出长度为64,提示长度为512,在A800 GPU服务器上。表X和表XI显示了结果。我们发现GPU泡沫卡在了推理框架中。在表X的“其他”行中显示了泡沫,占了7.55%。这表明我们可以进一步融合GPU内核,以减少泡沫的总时间。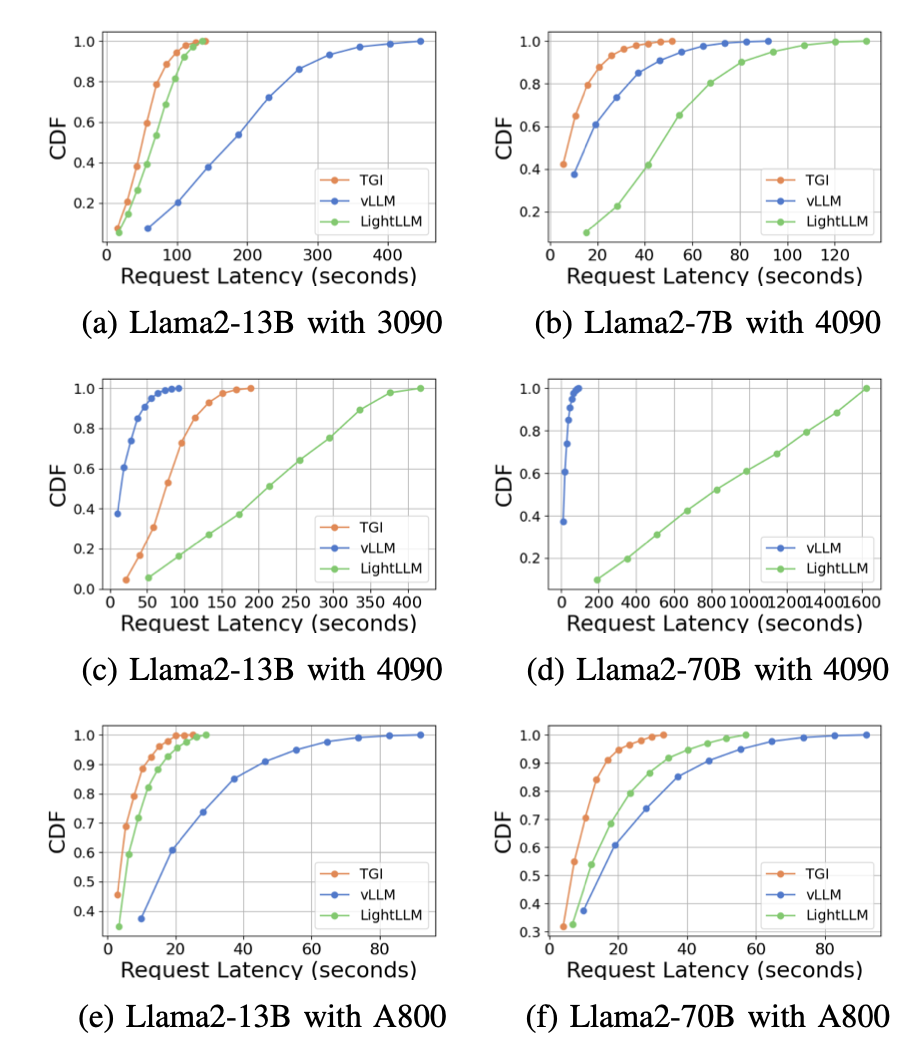
图9:在同一GPU平台上,使用不同推理框架的延迟性能比较。
表X:在A800上运行LightLLM的Llama2-7B的模块级时间成本。 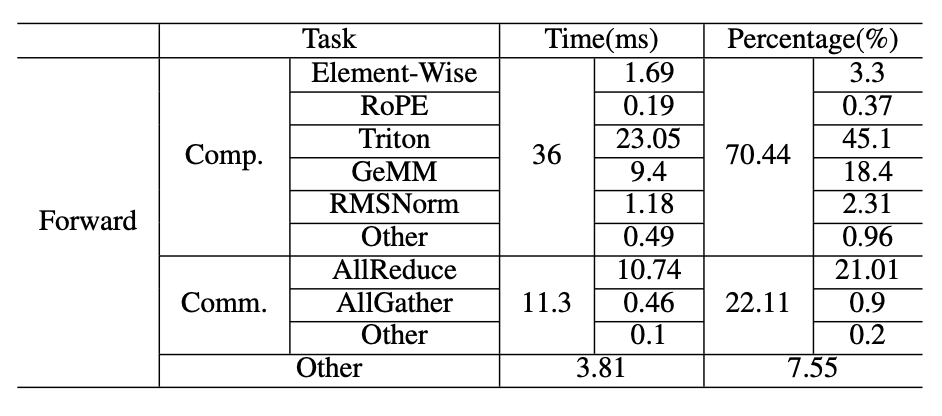
表XI:在A800上使用LightLLM的Llama2-7B的时间线。 
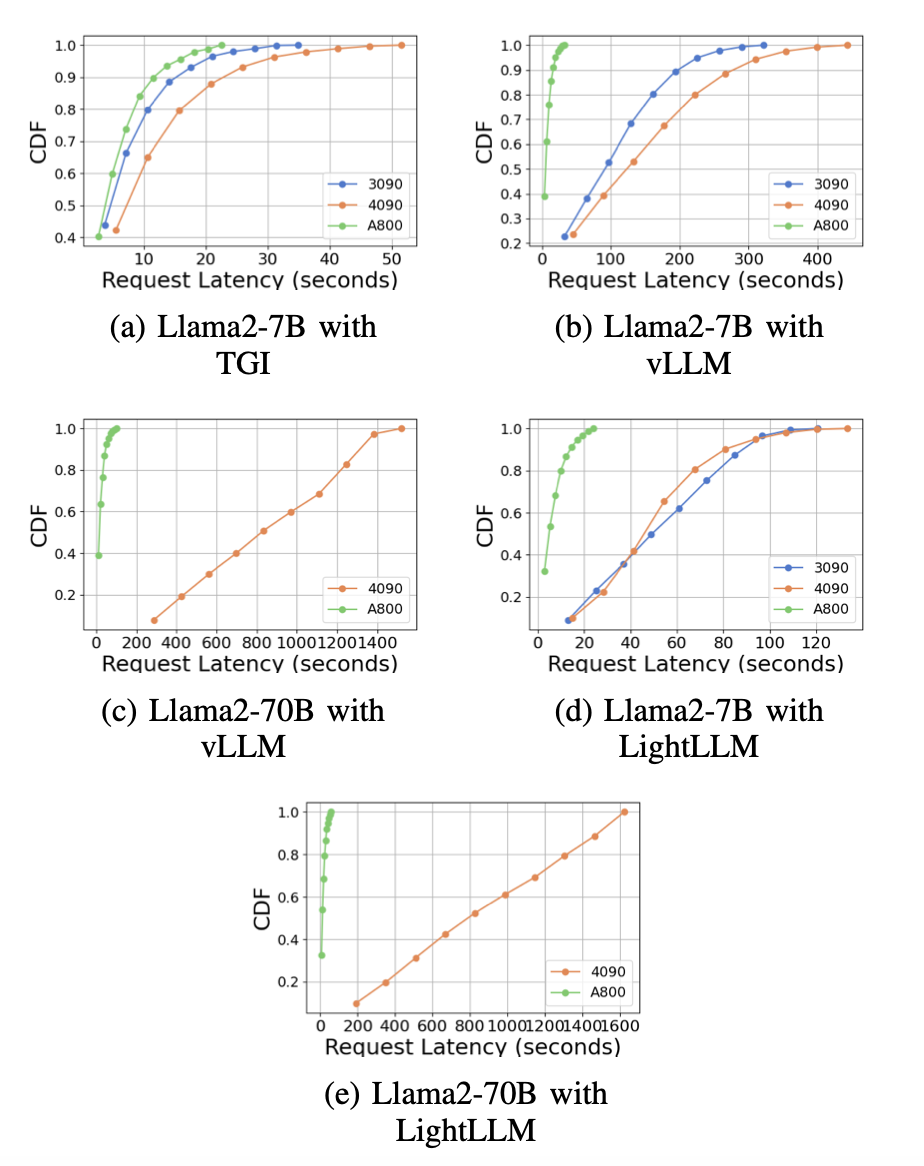
图10:在不同GPU平台上,使用相同推理框架的延迟性能比较。CDF代表累积分布函数。
表XII:使用朴素和重计算方法的MLP中第一个GEMM的性能比较。数据来自320次测量的平均值。 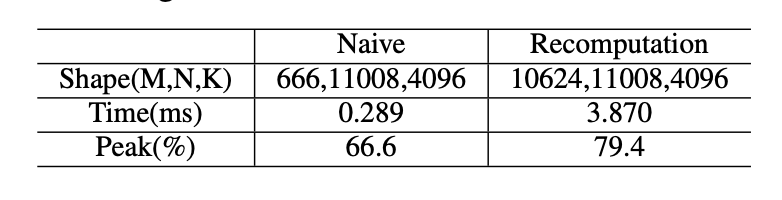
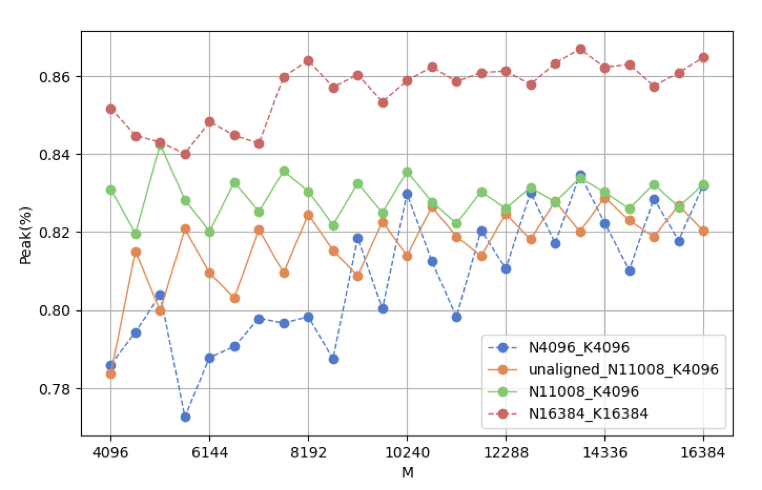
图11:随着矩阵大小的变化,GEMM的性能。
表XIII:使用朴素和重计算方法的前向和反向阶段的GEMM内核的时间分解。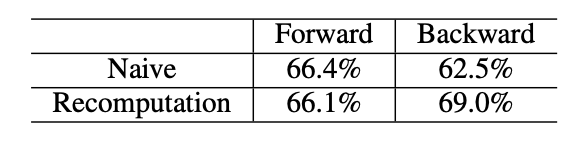
VII. 微基准测试
为了更深入地理解实验结果,我们进行了涵盖计算和通信的微基准分析。
A. GEMM分析
在第IV-B节中,我们观察到包含GEMM操作的模块的时间消耗相对较高。我们分别使用朴素方法和重计算来计算前向和反向阶段的GEMM操作的时间分解。表XIII显示,GEMM内核在前向和反向阶段都占用了超过60%的时间。因此,GEMM的性能对LLM的性能至关重要。为了更好地理解GEMM的性能,我们在MLP中执行了第一个GEMM(表XIII)。选择这个GEMM操作的原因是,MLP是最耗时的模块,它包含3个大小相似的GEMM。导致朴素方法的峰值低于重计算的主要原因是,矩阵大小太小,无法充分利用硬件。使用重计算将大小增加32倍后,峰值仍然低于理想值的90%。我们在我们的实验平台(A800)上测试了不同的矩阵大小,结果显示在图11中。在这个GEMM操作中,批量大小影响M。由于我们在相同的K和N下逐渐增加M,所以有两种选择M的情况。对于N4096 K4096,N11008 K4096(由Llama2-7B模型确定的形状)和N16384 K16384,M从4096逐渐增加到16384,步长为512,这确保了大小是TensorCore计算规模的整数倍。通过比较这三条曲线,我们可以看到,盲目增加批量大小并不总是能提高峰值性能。当批量大小足够大时,我们可以通过增加K和N进一步提高GEMM峰值。对于未对齐的N11008 K4096情况,我们的M从4096+13开始(魔数13是一个奇数,选择它不会显著影响M的大小),并以512的步长增加到16384+13。我们通过这个案例分析了M作为TencoreCore计算规模的整数倍和非整数倍的性能差异。结果清楚地显示,当M是TensorCore计算规模的整数倍时,峰值高于非整数倍。
B. 内存复制
卸载和上传是由内存复制内核实现的。表XIV提供了在A800上每次迭代中内存复制的绝对时间成本和百分比的总结。如表XIV所示,ZeRO-3比ZeRO-2产生更大的上传和卸载时间。然而,在这种情况下,内存复制的影响相对较小。图12描绘了上传操作(表示为H到D)和卸载操作(表示为D到H)内核的性能。在这个图中,上传和卸载操作的吞吐量和延迟都是相似的。对于较小的数据大小,启动时间往往占主导地位,而对于较大的数据大小,带宽变得更为重要。
表XIV:我们使用DeepSpeed框架,设置(bf16)和批量大小为32。在A800中,每次迭代的绝对时间和内存复制的百分比。在这种设置下,内存复制的影响相对较小。 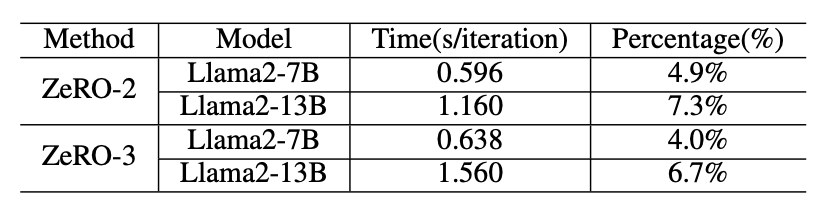
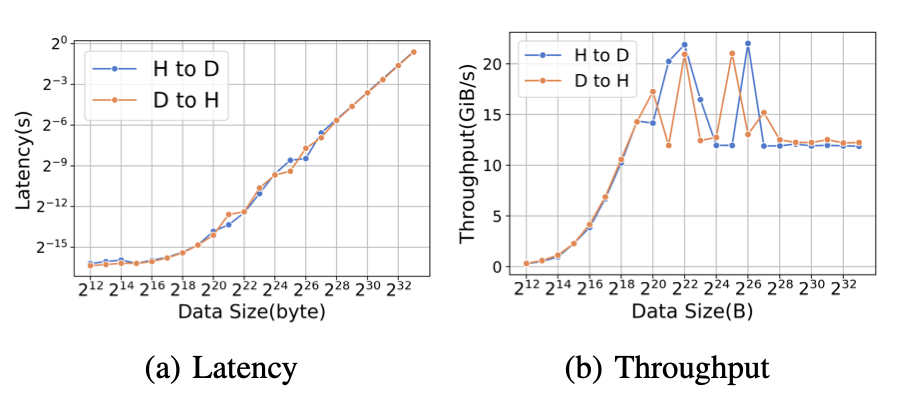
图12:在A800上,不同数据大小的卸载和上传比较的延迟和吞吐性能。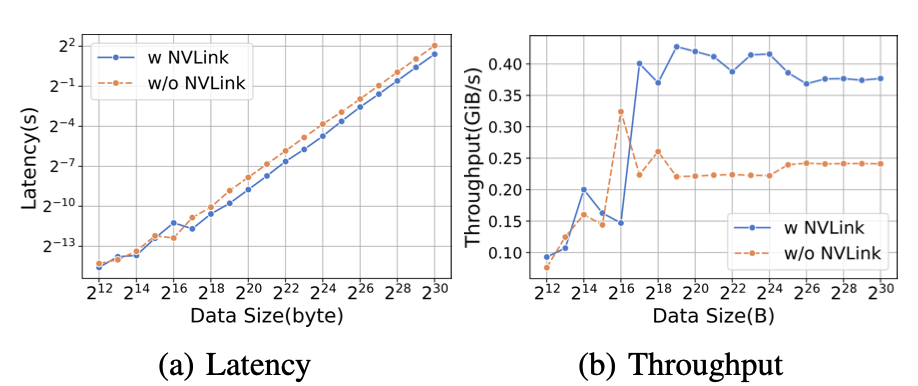
图13:在RTX3090上,使用和不使用NVLink的AllGather的延迟和吞吐量,数据大小不同。 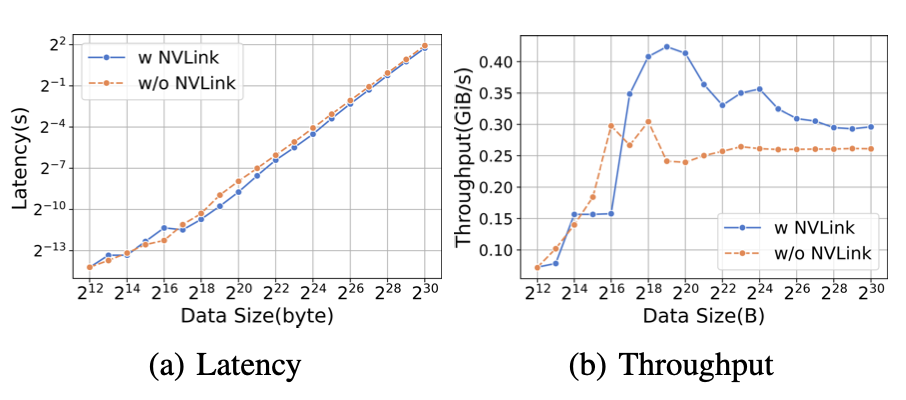
图14:在RTX3090上,使用和不使用NVLink的ReduceScatter的延迟和吞吐量,数据大小不同。
C. 集体通信
我们首先强调NVLink提供的高通信速度。当进行具有不同数据规模的AllGather时,我们观察到,带有NVLink的RTX3090优于没有NVLink的对应设备,如图13所示。 不同的训练范式涉及到不同的集体通信操作。对于数据并行范式,我们在反向阶段使用AllReduce来同步权重,如表XV所示。 当进行具有不同数据大小的ReduceScatter时,我们观察到,带有NVLink的RTX3090优于没有NVLink的对应设备,如图14所示。
表XV:AllReduce百分比。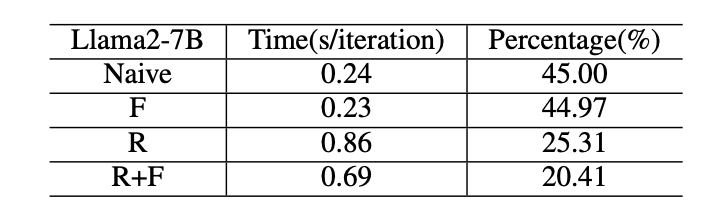
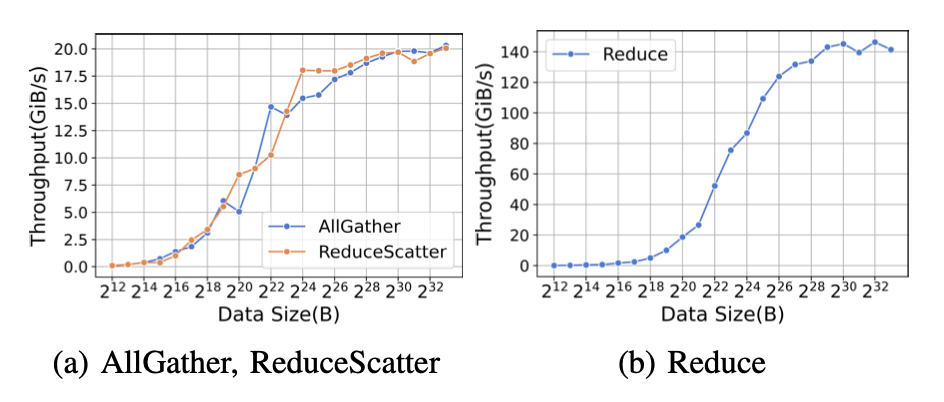
图15:在A800上,随着数据大小的变化,AllGather、ReduceScatter和Reduce的吞吐量。
表XVI:我们使用DeepSpeed框架,设置(bf16)和批量大小为32。在A800中,每次迭代的绝对时间和通信内核的百分比。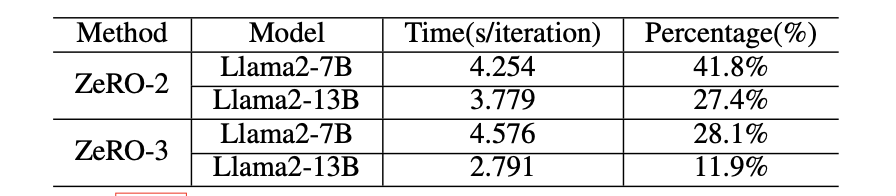
C. 集体通信
ZeRO-2在反向阶段需要Reduce集体通信原语。图15b显示了reduce内核的性能。与内存复制类似,Reduce内核的小数据大小导致启动时间占主导地位,而大数据大小部分的性能取决于带宽。ZeRO-3在反向阶段使用ReduceScatter代替Reduce集体通信原语。图15a显示了ReduceScatter内核的性能。ZeRO-2和ZeRO-3都使用AllGather来更新参数。图15a还显示了AllGather内核的性能。 表XVI总结了在A800中每次迭代的内存复制的绝对时间和百分比。如表XVI所示,我们可以看到ZeRO-3的通信时间比ZeRO-2多,而且在预训练小模型时,通信时间更为重要。
VIII. 相关工作
有大量的研究对模型性能进行了基准测试,包括泛化能力和在下游任务中的准确性。然而,只有少数研究关注硬件和软件,效率的评估和时间分析,甚至更少的研究关注训练、微调和服务LLMs。Xu等人提供了一项调查,比较了在模型微调和推理中特别有用的模型压缩技术。Cao等人也对诸如ELECTRA,Prompt Tuning等算法方面的高效LLMs进行了概述。Liang等人提出了HELM,一种全面的性能评估,用于比较模型泛化能力和时间效率。然而,他们的时间效率结果主要关注在给定软件的特定硬件平台上的推理。MLCommons4是另一个用于比较深度学习(也包括LLMs)训练和推理的时间性能的前沿基准,不受硬件平台的限制。在LLM时代之前,一些基准被提出来比较不同模型(包括CNNs、LSTMs和/或Transformers)的软件和硬件性能。 据我们所知,我们提供了第一项在各种硬件平台上分析LLMs管道中所有三个关键阶段(预训练、微调和服务)的运行时性能的研究。
IX. 结论 在这项工作中,我们在三个8-GPU硬件平台(Nvidia A800-80G,RTX4090和RTX3090)上对预训练、微调和服务LLMs的运行时性能进行了基准测试。基于基准测试结果,我们分析了对总体时间贡献最大的关键模块和操作符。实验结果和分析为最终用户选择硬件、软件和优化技术配置进行预训练、微调和服务LLMs提供了更多的信息。此外,对性能的深入理解提供了进一步的优化机会,以提高系统性能。
:理解、实现与运用)


)






)








