PyTorch 从 1.2.0 版本开始,正式自带内置的 Tensorboard 支持了,我们可以不再依赖第三方工具来进行可视化。
tensorboard官方教程地址:https://github.com/tensorflow/tensorboard/blob/master/README.md
1、tensorboard 下载
step 1
此次tensorboard在pycharm的终端里下载。点击pycharm的终端(红圈处),并且输入activate pytorch激活之前安装了pytorch的环境。
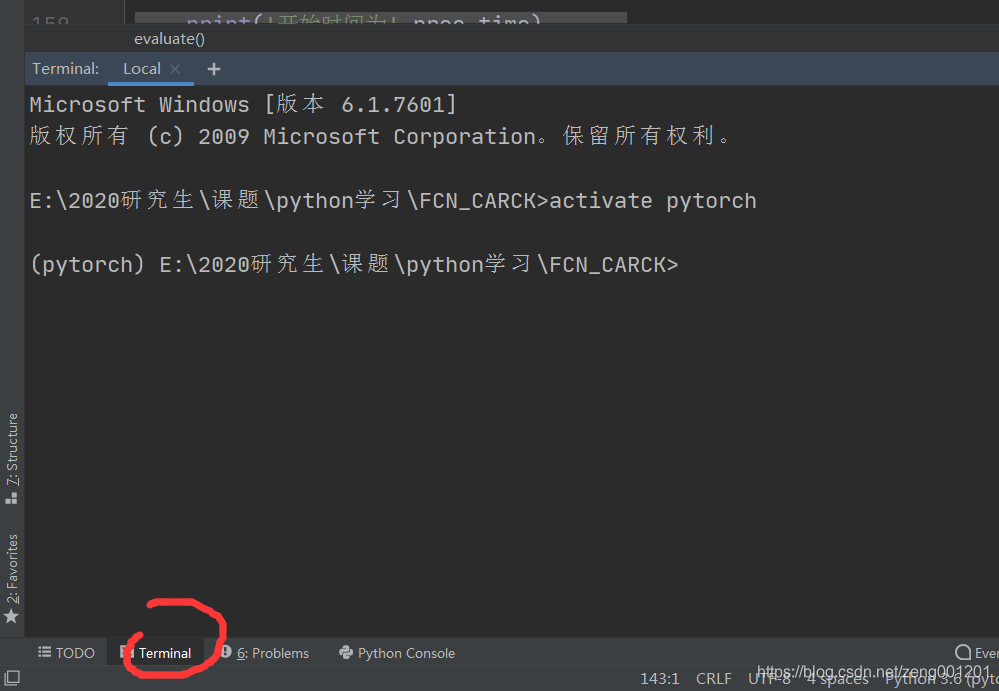
step 2
这里使用pip安装tensorboard,输入 pip install tensorboard
等待安装完后,再安装另外一个他需要依赖的库。
输入 pip install future.
安装完毕后,输入pip list查看是否安装成功。
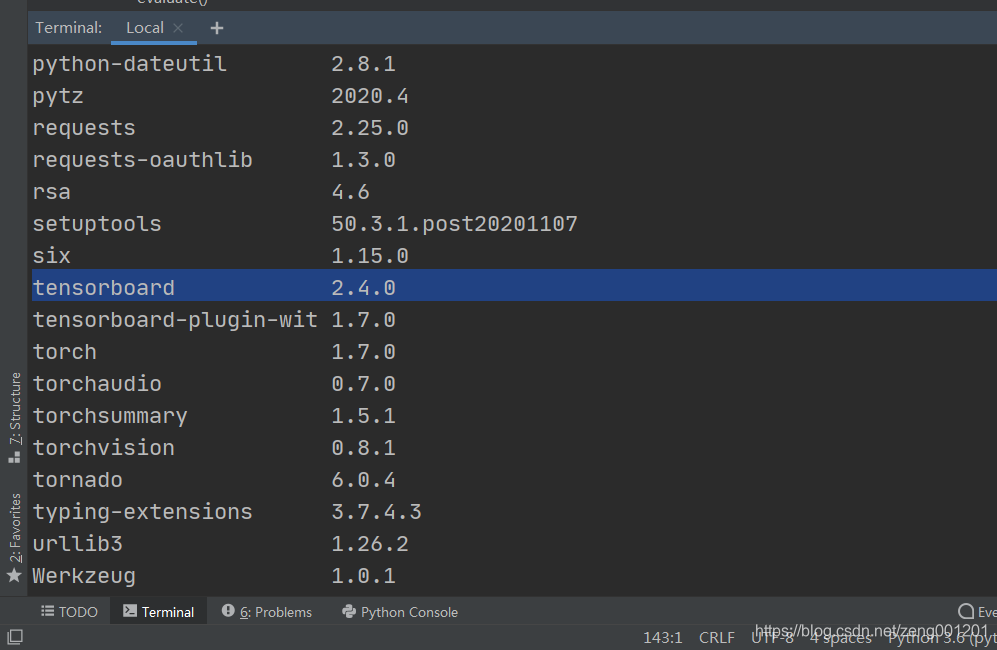
下载成功后可用下述代码进行测试:
import numpy as np
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter(comment='test_tensorboard')for x in range(100):writer.add_scalar('y=2x', x * 2, x)writer.add_scalar('y=pow(2, x)', 2 ** x, x)writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),"xcosx": x * np.cos(x),"arctanx": np.arctan(x)}, x)
writer.close()
2、tensorboard 的使用
2.1 tensorboard 的打开
这里也在pycharm的终端中打开tensorboard工具去读取event file。
step 1
打开pycharm的终端
step 2
在终端中输入 dir查看项目当前文件夹里的文件
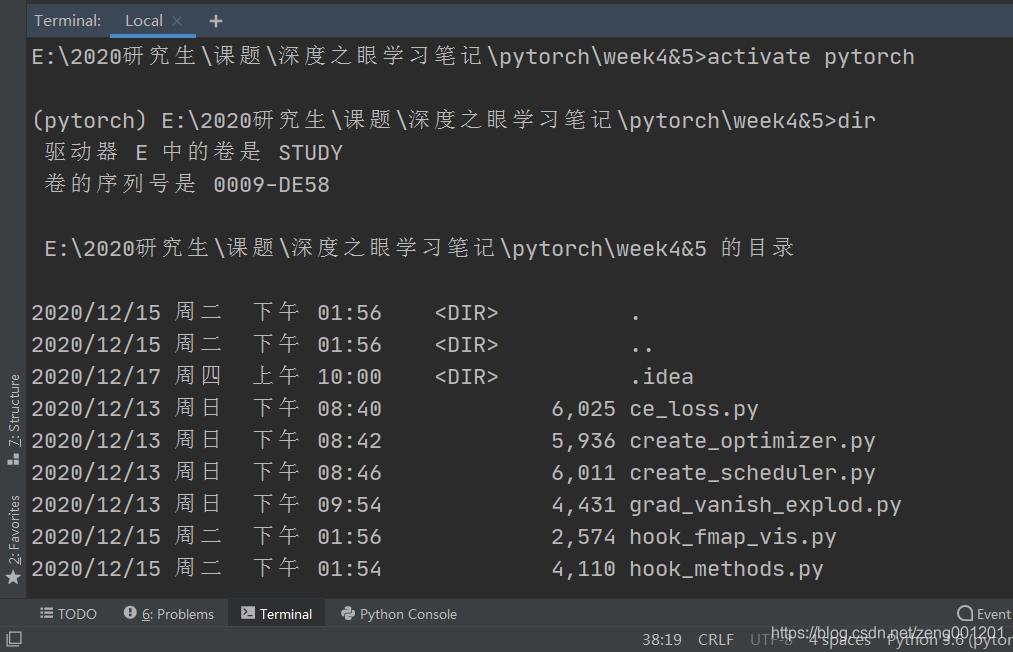
step 3
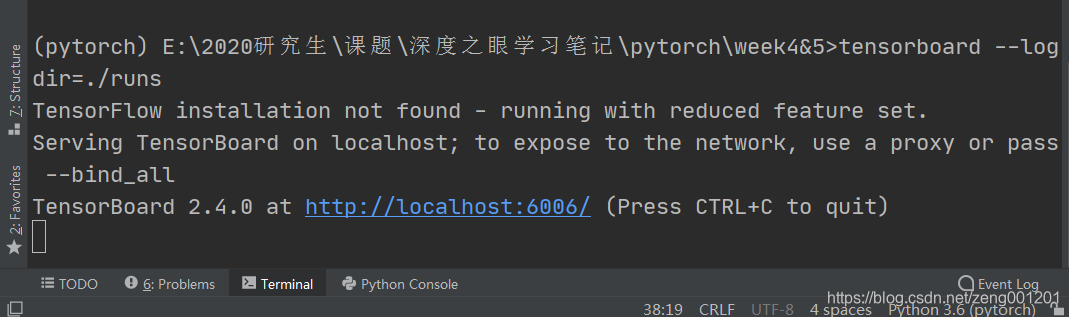
设置路径,输入tensorboard --logdir=./runs
./runs为想要可视化数据所在的文件夹路径
step 4
点击网址,打开tensorboard页面

2.2 tensorboard 的用法
SummaryWriter类
tensorboard 的SummaryWriter类:提供创建event file的高级接口,主要属性为:
主要的方法有:
add_scalar()和add_scalars()

add_scalars()用于创建多条曲线,用字典来记录数据与数据名。
add_histogram()

add_image()

add_graph()

3、tensorboard 的实战演练
3.1 创建SummaryWriter对象
一般在train.py中,在开始迭代计算前,创建SummaryWriter对象:
# 生成tensorboard可视化文件
ut = cfg.use_tensorboard
if ut:from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter(log_dir='./tensorboard event file', filename_suffix=str(cfg.EPOCH_NUMBER),flush_secs = 180)# log_dir 里为可视化文件所在位置路径,可用绝对路径,默认在runs# filename_suffix 设置event file文件名后缀# flush_secs 设置每隔多久将数据写入可视化文件中,默认120
3.2 计算图的可视化
在定义完网络后,在网络的.py文件中:
if __name__ == "__main__":rgb = torch.randn(1,3,360, 640)net = FCN_8s(2)out = net(rgb)print(out.shape)# ________________________查看模型计算图# 生成tensorboard可视化文件ut = cfg.use_tensorboardif ut:from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter(log_dir='./tensorboard event file',filename_suffix=str(cfg.EPOCH_NUMBER),flush_secs=180)writer.add_graph(net, rgb)writer.close()
运行后,点开pycharm的终端:

点击网址:

另外一种用于debug检查模型的方法:
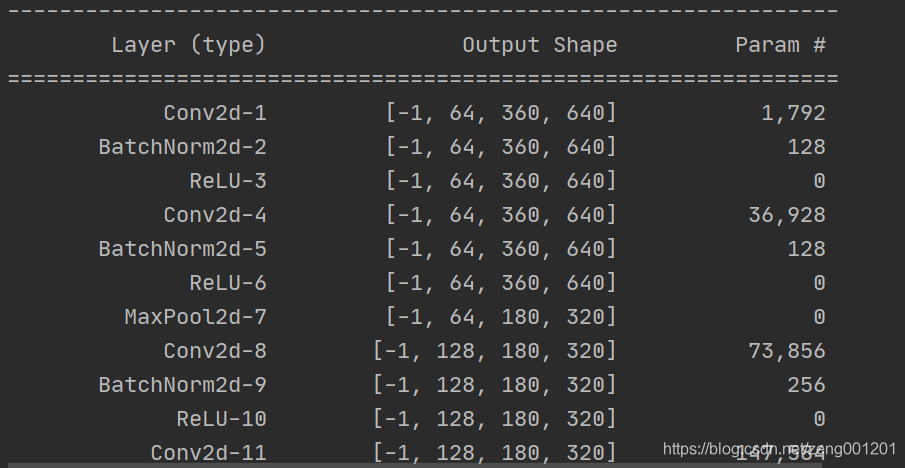
summary()可输出模型每层输入输出的shape以及模型总量。使用前需要在终端pip install torchsummary。

from torchsummary import summary
print(summary(net, (3, 360, 640), device="cpu"))
运行得到:

3.3 训练过程loss的可视化
在训练train.py文件中的,每次计算完loss后输出:
print(metric_description)# 用tensorboard可视化Train Lossif ut:writer.add_scalar('Train Loss', train_loss / num_mini_batch, epoch)writer.flush()
验证同理
3.4 训练过程卷积核以及输入输出图像的可视化
查看输出图像以及卷积核图像对语义分割具有重要作用。
1、对输入图片进行可视化:
import cfg
import data
from torch.utils.data import DataLoader
import torchvision
import kk_toolstrain_img_path = cfg.TRAIN_ROOT
train_label_path = cfg.TRAIN_LABEL
transform_img = torchvision.transforms.Compose(
[torchvision.transforms.Resize(32),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])traindata_path = data.CRACKdataset_path([train_img_path,train_label_path],cfg.crop_size,transform_img)
train_loader = DataLoader(traindata_path,batch_size=cfg.BATCH_SIZE,shuffle=True,num_workers=0)# del_file(log_dir) # 删除原来存在的数据,删除文件夹
from torch.utils.tensorboard import SummaryWriter
logdir = 'checkphoto'
kk_tools.del_file(logdir)
writer = SummaryWriter(log_dir = logdir,filename_suffix=str(cfg.EPOCH_NUMBER),flush_secs=cfg.refresh_time)i, sample = next(enumerate(train_loader))
img = sample['img'] # torch.Size([4, 3, 240, 360])
import torchvision.utils
img_grid = torchvision.utils.make_grid(img,nrow = 2,normalize= False,scale_each=False)
# nrow = 2 设置有2行
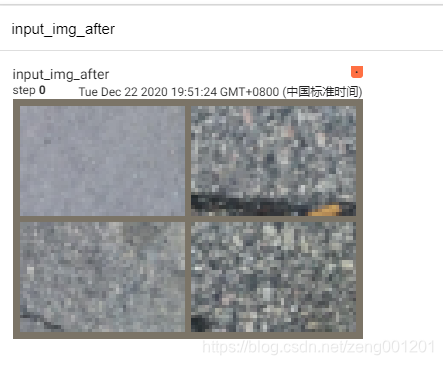
writer.add_image('input_img',img_grid,str(i))_ = kk_tools.transform_invert(img_grid, transform_img ) # 处理normolize
kk_tools.dshow_picture(img_grid)
writer.add_image('input_img_after', img_grid, str(i))
writer.close()

2、对卷积核可视化:这里使用 torchvision.utils.make_grid()会有bug,详情看网址:https://github.com/pytorch/vision/issues/3025
要使用pytorch1.5版本的就不报错。
然后问了一个大神,改成酱就行了。改的方法看上面网址。下面是对第一个卷积进行是可视化,但是需要输入通道数是3的才可以,其他通道数不行,除非改成3通道数的。
from FCN_8s import FCN_8s
import torch
from torch import nn
import torchvision.utils
from torch.utils.tensorboard import SummaryWriter
net = FCN_8s(2)
net.load_state_dict(torch.load('best.pth'))
print(net.parameters())
kernel_num = -1 # 当前可视化层
vis_max = 1 # 最大可视化层
log_dir = 'kernelphoto'
del_file(log_dir)
writer = SummaryWriter(log_dir=log_dir)for sub_module in net.modules():if isinstance(sub_module,nn.Conv2d):kernel_num += 1if kernel_num > vis_max:breakkernels = sub_module.weight # torch.Size([64, 3, 3, 3])c_out,c_int,k_w,k_h = tuple(kernels.shape)for o_idx in range(c_out):kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度with torch.no_grad():kernel_grid = torchvision.utils.make_grid(kernel_idx,nrow=c_int,normalize=True,scale_each=True,)writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)kernel_all = kernels.view(-1, 3, k_h, k_w) # 3, h, wwith torch.no_grad():kernel_grid = torchvision.utils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, wwriter.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=322)print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))writer.close()

3、对输出图像进行可视化:
需要借助hook函数来提取特征图进行可视化,在前向传播或者反向传播时,通过hook函数机制挂上额外的函数,获取或者改变特征图梯度。感觉这个对后续特征图的可视化不靠谱,因为这里的输出往往不是3通道的,酱如何可视化???

针对tensor张量的hook函数:

针对module网络模型的hook函数:



flag = 0
flag = 1
if flag:import cfgimport datafrom torch.utils.data import DataLoaderimport torchvisionfrom FCN_8s import FCN_8sfrom torch import nnimport torchvision.utilsimport numpy as nptrain_img_path = cfg.TRAIN_ROOTtrain_label_path = cfg.TRAIN_LABELtransform_img = torchvision.transforms.Compose([torchvision.transforms.Resize(32),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])traindata_path = data.CRACKdataset_path([train_img_path,train_label_path],cfg.crop_size,transform_img)test_loader = DataLoader(traindata_path,batch_size=cfg.BATCH_SIZE,shuffle=True,num_workers=0)from torch.utils.tensorboard import SummaryWriterlogdir = 'checkphoto'kk_tools.del_file(logdir)writer = SummaryWriter(log_dir=logdir)net = FCN_8s(2)net.eval()net.load_state_dict(torch.load('best.pth'))fmap_dict = dict()for name, sub_module in net.named_modules():print(name)if isinstance(sub_module, nn.Conv2d) or isinstance(sub_module, nn.ConvTranspose2d):key_name = str(sub_module.weight.shape)fmap_dict.setdefault(key_name, list())def hook_func(m, inputd, outputd):key_name = str(m.weight.shape)fmap_dict[key_name].append(outputd)if '.' in name:n1, n2 = name.split(".")net._modules[n1]._modules[n2].register_forward_hook(hook_func)else:net._modules[name].register_forward_hook(hook_func)i, sample = next(enumerate(test_loader))out = net(sample['img'])# add imagefor layer_name, fmap_list in fmap_dict.items():fmap = fmap_list[0]nrow = int(np.sqrt(fmap.shape[0]))with torch.no_grad():fmap_grid = torchvision.utils.make_grid(fmap,normalize=True,scale_each=True,nrow=nrow)writer.add_image('feature map in {}'.format(layer_name), fmap_grid, global_step=322)# 需要特征图输出通道数为3才可以可视化writer.close()print('完成')
3.5 训练过程输出值的可视化
为避免出现梯度消失或者梯度爆炸,需要保持方差一致性原则,尽量使输出层的方差为1,这里可用直方图直观的查看输出值的分布情况。
在训练train.py文件中的,每次输出完loss的可视化文件后:
if ut_w:for name, param in net.named_parameters():writer.add_histogram(name + '_grad', param.grad, epoch)writer.add_histogram(name + '_data', param, epoch)
得到多分位数折线图:观察方差情况
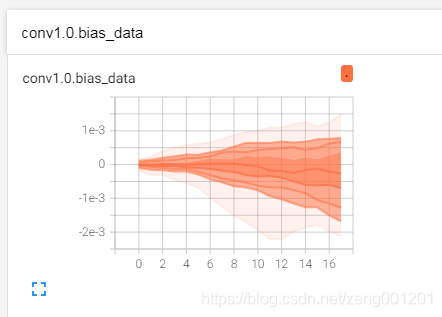
得到直方图:

更多示例一
# tensorboard --logdir=e:\Desktop\tensor# 初始化了一个SummaryWriter,这是将信息写入TensorBoard的主要工具。 # 使用add_graph方法添加了模型的计算图。 # 在训练过程中的每个 epoch,它都会计算损失和准确率,并使用add_scalar方法将它们添加到TensorBoard # 使用add_histogram方法记录了模型权重的分布 # 使用add_image方法记录了模型产生的示例图像from torch.utils.tensorboard import SummaryWriter # 初始化 TensorBoard 写入器 writer = SummaryWriter() # 假设有一个名为 SimpleCNN 的模型 model = SimpleCNN() # 记录模型的计算图 dummy_input = torch.randn(1, 3, 8, 8) writer.add_graph(model, dummy_input) for epoch in range(epochs): # 训练和验证逻辑的占位符 train_loss = compute_train_loss() # 计算损失 validation_accuracy = compute_validation_accuracy() # 计算准确率 # 记录标量值 writer.add_scalar('Loss/train', train_loss, epoch) # 训练中的损失 writer.add_scalar('Accuracy/validation', validation_accuracy, epoch) # 验证中的准确率 # 记录张量值的分布 for name, param in model.named_parameters(): writer.add_histogram(name, param.clone().cpu().data.numpy(), epoch) # 假设模型有一个方法来生成示例图片 generated_images = model.generate_sample_images() # 记录图像数据 for i, img in enumerate(generated_images): writer.add_image(f'Generated/Image_{i}', img, epoch) writer.close()from torch.utils.tensorboard import SummaryWriter from torchvision.utils import make_grid writer = SummaryWriter() model = ComplexModel() # 假设存在的 PyTorch 模型,含有 modelA 和 modelB 子模型 optimizer = ... # 某种优化器,例如 torch.optim.Adam # 1. add_graph: 记录计算图 # 对于有条件分支的模型,你可以为每个分支分别添加计算图。 dummy_input = torch.randn(1, 3, 8, 8) writer.add_graph(model.modelA, dummy_input) # modelA的计算图 writer.add_graph(model.modelB, dummy_input) # modelB的计算图 for epoch in range(epochs): # 2. add_scalar: 跟踪学习率 lr = optimizer.param_groups[0]['lr'] writer.add_scalar('Learning Rate', lr, epoch) # ... 训练逻辑 ... # 3. add_histogram: 检测梯度爆炸/消失 for name, param in model.named_parameters(): if param.requires_grad: writer.add_histogram(f"{name}.grad", param.grad, epoch) # 4. add_image # 使用 Grid:一次显示多张图像。 images = ... # 假设有一组图像 grid = make_grid(images) writer.add_image('images', grid, epoch) # 可视化特征映射 def forward_hook(module, input, output): grid = make_grid(output[0, :16]) # 前16个特征图 writer.add_image(f'features/{module.name}', grid, epoch) # 添加到你想观察的层,这里只是一个例子 layer = model.some_layer # 假设模型有一个名为some_layer的层 hook = layer.register_forward_hook(forward_hook) # ... 额外的训练逻辑 ... # 在完成特定层的观察后,取消挂钩以避免额外的开销 hook.remove() writer.close()
更多示例二
在之前分享中,我们向你展示了如何加载数据,继承 nn.Module 创建子类,在子类中实现前向传播方法完成模型的搭建,然后在训练数据上训练这个模型,并在测试数据上对其进行测试。对于每个环节为了更清楚地了解发生了什么,在模型训练时使用 print 语句输出一些我们想要了解的信息,例如统计数据,以了解训练是否有进展。然而,其实我们还可以做得比这更好,其实 PyTorch 已经集成了 TensorBoard ,所以 TensorBoard 这样好用可视化工具,我们在 PyTorch 中也是能够使用的。TensorBoard 是一个专门用于可视化神经网络训练结果的工具。本分享使用 Fashion-MNIST 数据集来训练一个模型,在训练过程中引入 TensorBoard ,从来说明 TensorBoard 的一些功能以及应该如何使用这些功能,该数据集可以通过 torchvision.datasets 读入PyTorch 。
将会了解到
- 读取数据并进行适当的转换,例如转换为 Tensor、缩放和翻转等
- 设置 TensorBoard
- 如何要 TensorBoard
- 使用 TensorBoard 查看模型结构
- 使用 TensorBoard 来创建的可视化的交互式
TensorBoard 有哪些用途
- 检查训练数据的几种方法
- 如何在训练过程中跟踪模型的性能
- 模型训练完成时,如何评估模型的性能
准备数据集
# imports
import matplotlib.pyplot as plt
import numpy as npimport torch
import torchvision
import torchvision.transforms as transformsimport torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim# transforms
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])# 数据集
trainset = torchvision.datasets.FashionMNIST('./data',download=True,train=True,transform=transform)
testset = torchvision.datasets.FashionMNIST('./data',download=True,train=False,transform=transform)# 定义数据加载器
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)# 数据类
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot')# 函数用于展示图片
def matplotlib_imshow(img, one_channel=False):if one_channel:img = img.mean(dim=0)img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()if one_channel:plt.imshow(npimg, cmap="Greys")else:plt.imshow(np.transpose(npimg, (1, 2, 0)))
定义网络
数据集中的图像只有 1 通道,数据尺寸是 28x28 而不是 32x32
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 4 * 4, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 4 * 4)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()
定义损失函数和选择优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
TensorBoard 设置
现在开始设置 TensorBoard,从 torch.utils 导入 tensorboard,并定义一个 SummaryWriter,这是用于向 TensorBoard 写信息的对象。
from torch.utils.tensorboard import SummaryWriter# 在没有指定要写入文件默认写入到 `log_dir` 是 "runs"
writer = SummaryWriter('runs/fashion_mnist_experiment_1')
如何向 TensorBoard 中写信息
# 从训练集中图片中随机抽取一些图片
dataiter = iter(trainloader)
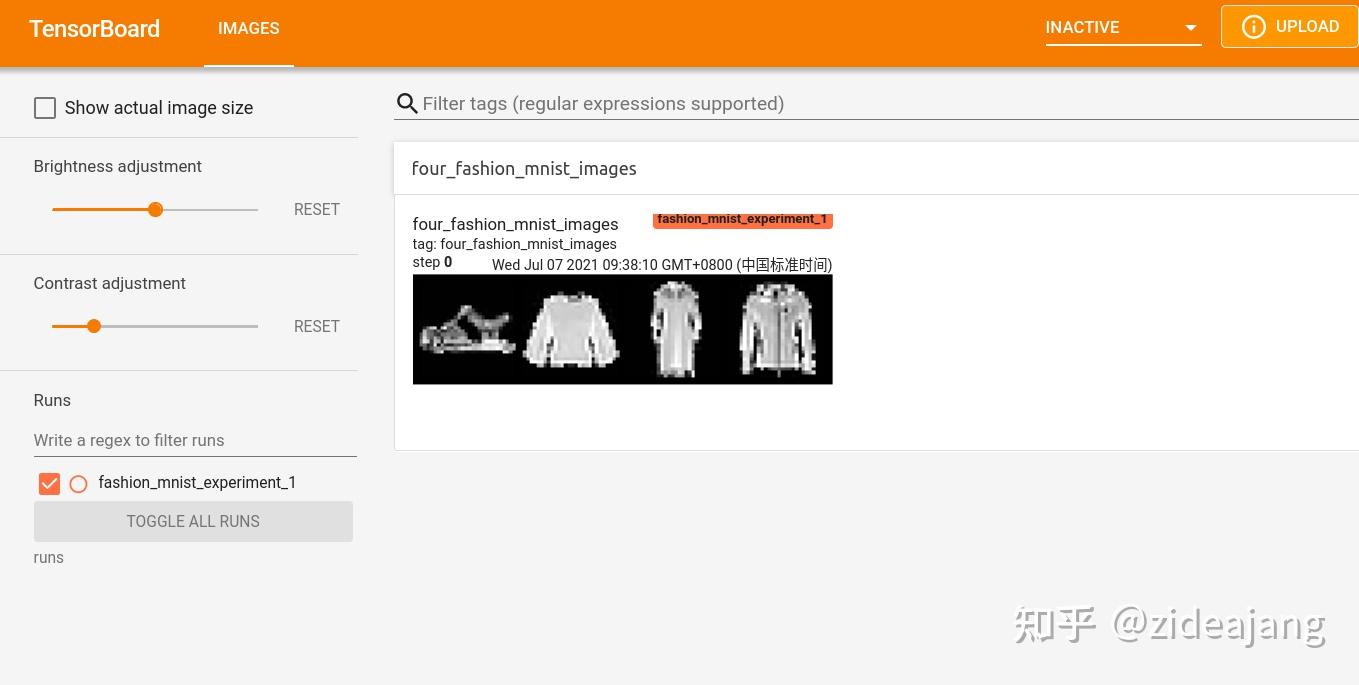
images, labels = dataiter.next()# 创建图片显示为grid,类似将选择到图片一表格形式显示出来
img_grid = torchvision.utils.make_grid(images)# 显示图片
matplotlib_imshow(img_grid, one_channel=True)# 写入到 tensorboard
writer.add_image('four_fashion_mnist_images', img_grid)
- 现运行代码
- 然后运行
tensorboard --logdir=runs
成功启动了 TensorBoard 服务之后,可以在浏览器上,访问控制台 http://localhost:6006, 生成网页,这个布局也比较传统,导航栏,左侧为控制,最大区域是是一个可视化的内容区域。
writer 是让我们开发者将要查看或则在,通过调用 add_image 为我们就可以在导航栏创建一个标签(tab) 一些数据相关都可以写入到该页面展示出来。处理 Image 之外,TensorBoard 提供了 distributions、projector、text 、PR_curve 和 profile 等栏目,虽有还会这些栏目中选取一两个给大家详细介绍。
现在知道如何使用 TensorBoard 了,然而,这个例子可以在 Jupyter 笔记本中完成–TensorBoard 真正擅长的地方是创建交互式的可视化。
使用 TensorBoard 来检测模型结构
TensorBoard 的优势之一,能够将复杂的模型结构可视化。现在我们就来创建的模型结构可视化。
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 4 * 4, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 4 * 4)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()
这会使用 add_graph 命令将图像添加到导航栏,刷新导航栏后就可以在导航栏上看到 GRAPH 标签页,
# 写入到 tensorboard
writer.add_graph(net, images)
writer.close()
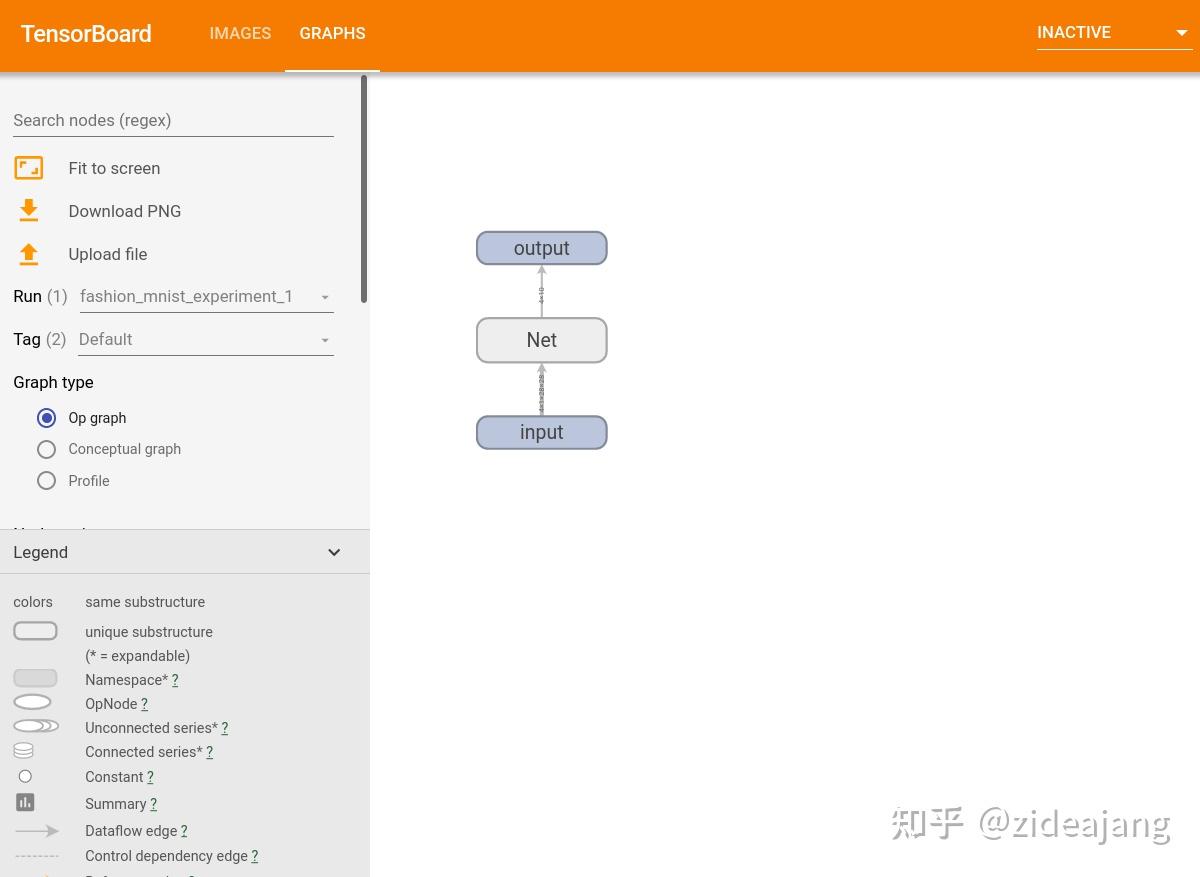
上面图展示 net 模型结构,TensorBoard 除了可以展示整体的计算图结构之外,还展示很丰富细节信息,如节点基本信息、运行的时间、运行时消耗的内存。
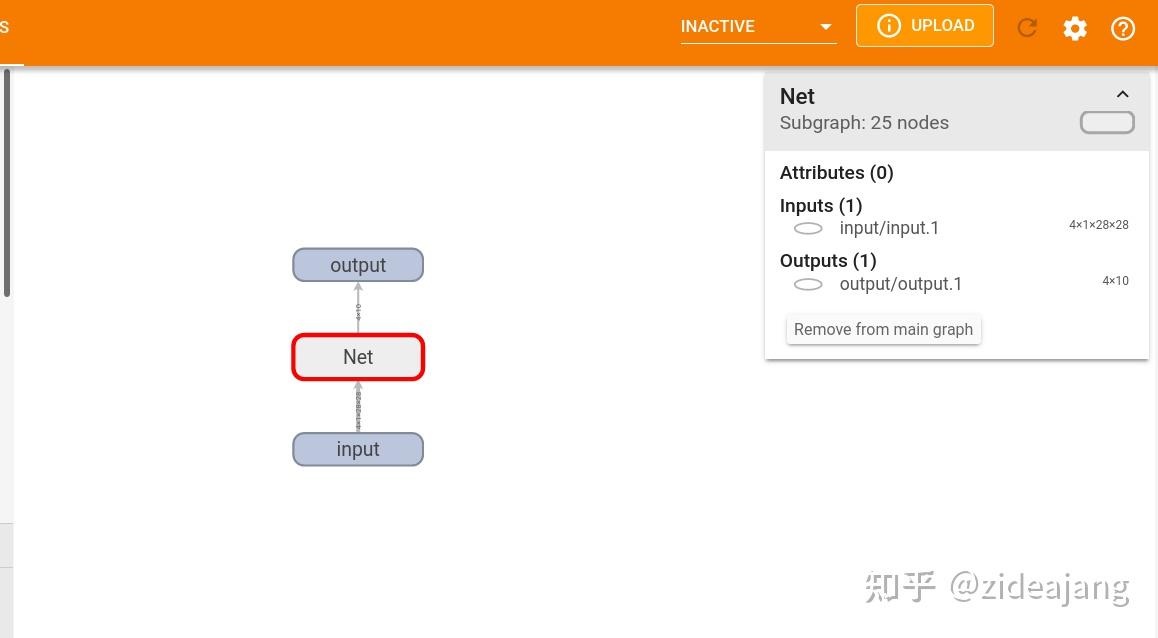
看这张图对照上面网络结构定义的代码对比来看,输入经过 2 层卷积层然后紧接是 3 个全连接层,双击 Net 节点就可以清除地看到 Net 中结构。大家可能已经注意到了,在节点连接边上有 tensor 的形状。
选中一个节点后可以观察到该节点的详细信息,例如输入和输出以及属性等信息。
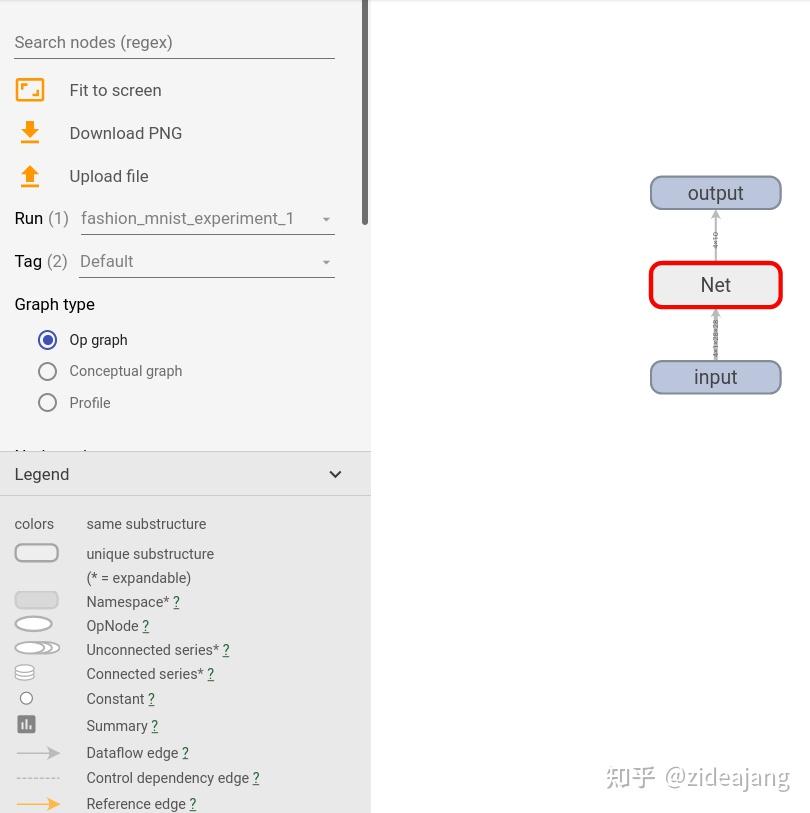
有关图说明可以在界面左下中图例(Legend)查看
- Namespace(表示命名空间)
- OpNode (操作节点)
- Constant (常量)
- Dataflow edge (数据流向边)
- Control dependency edge (控制依赖边)
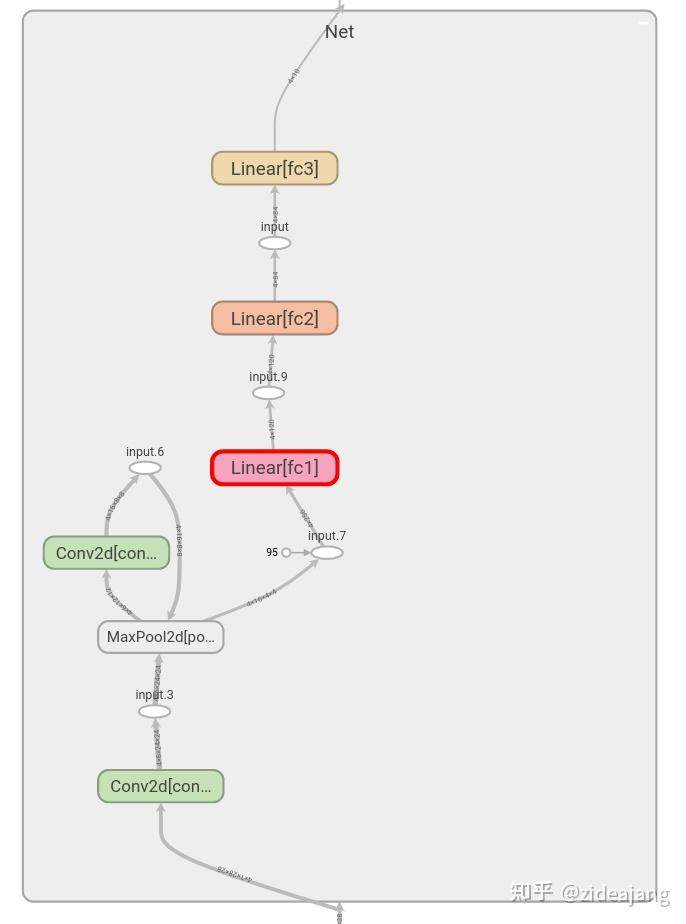
继续前进,双击 Net 以看到的展开,看到构成模型的各个操作的详细视图
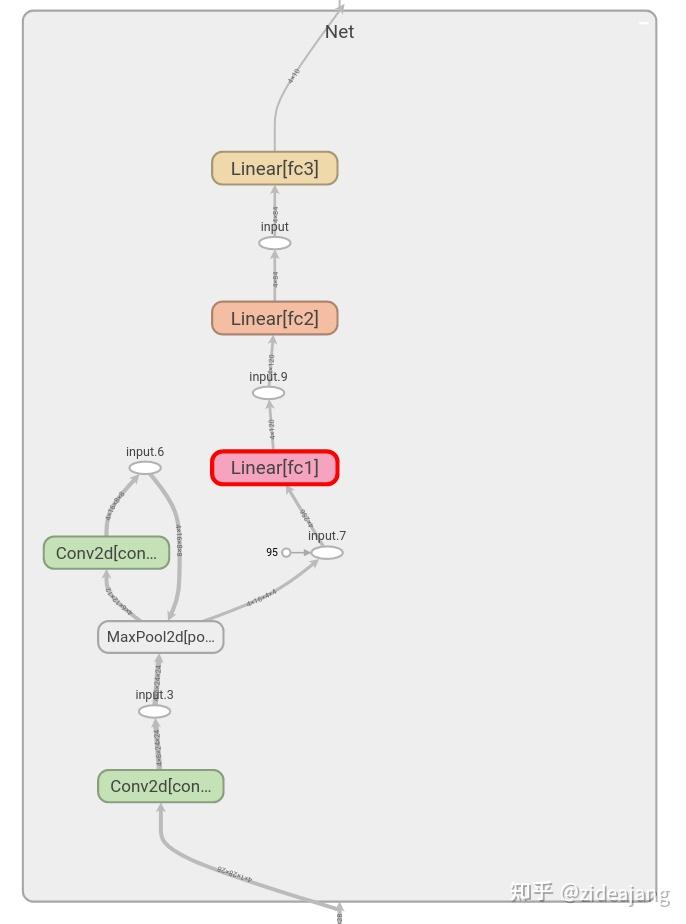
其实还可以更进一步,继续点击某一层卷积层,可以查看其中内部结构
TensorBoard 有一个非常方便的功能,用于可视化高维数据,如低维空间中的图像数据,我们接下来会介绍这个。
添加投影仪到 TensorBoard
# helper function
def select_n_random(data, labels, n=100):'''Selects n random datapoints and their corresponding labels from a dataset'''assert len(data) == len(labels)perm = torch.randperm(len(data))return data[perm][:n], labels[perm][:n]# 在训练集中随机抽取图片
images, labels = select_n_random(trainset.data, trainset.targets)# 获取每张图片的 label
class_labels = [classes[lab] for lab in labels]# 查看图片
features = images.view(-1, 28 * 28)
writer.add_embedding(features,metadata=class_labels,label_img=images.unsqueeze(1))
writer.close()
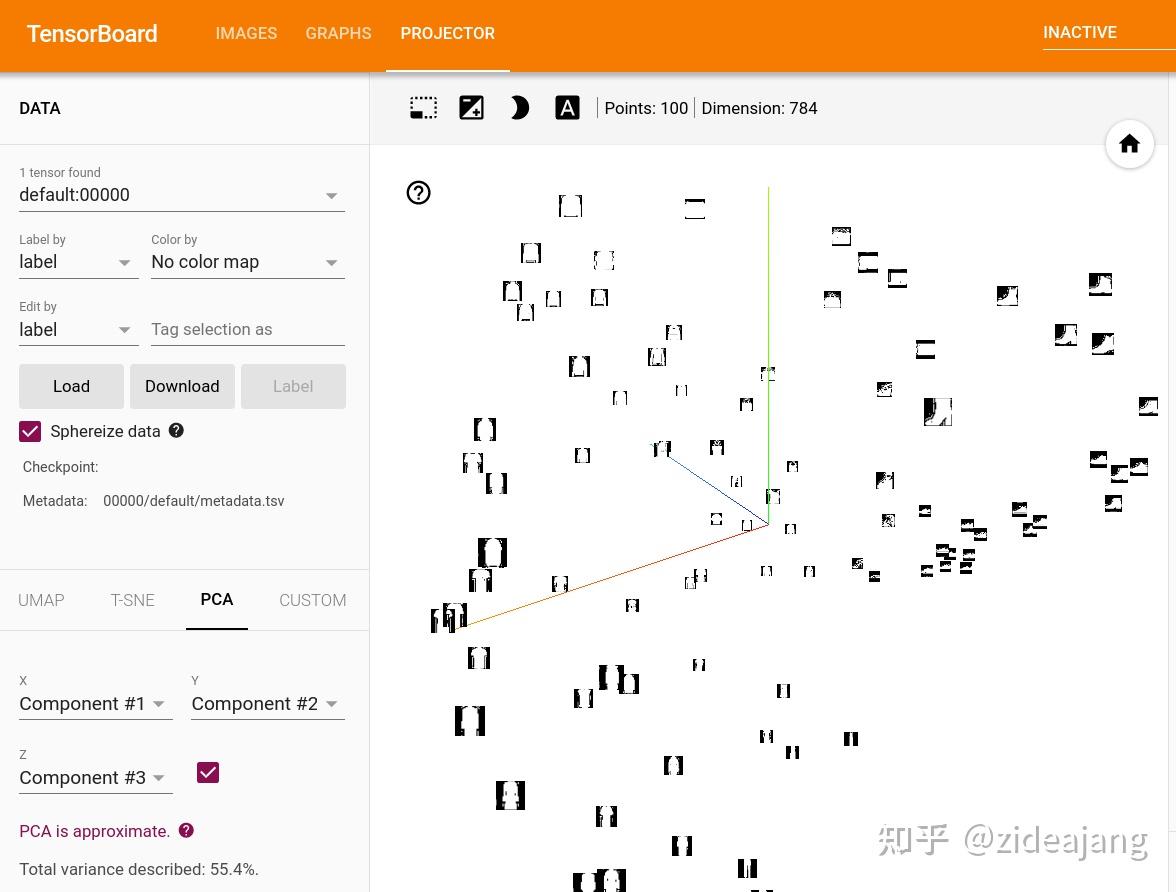
现在来创建一个 TensorBoard 的投影仪(Projector)选项卡,这是一个交互式可视化工具,通过数据可视化来分析高维数据,将100 张图片(每张都是 784 维)投射到三维空间。接下来看一看良好的互动的体验,可以点击和拖动来旋转三维投影。这里读取图像后将其形状转换(784,)向量用于
通过可以在左上方选择 "颜色:标签"来启用 “夜间模式”,这将使图像更容易看到清楚,默认的背景颜色是白色的。
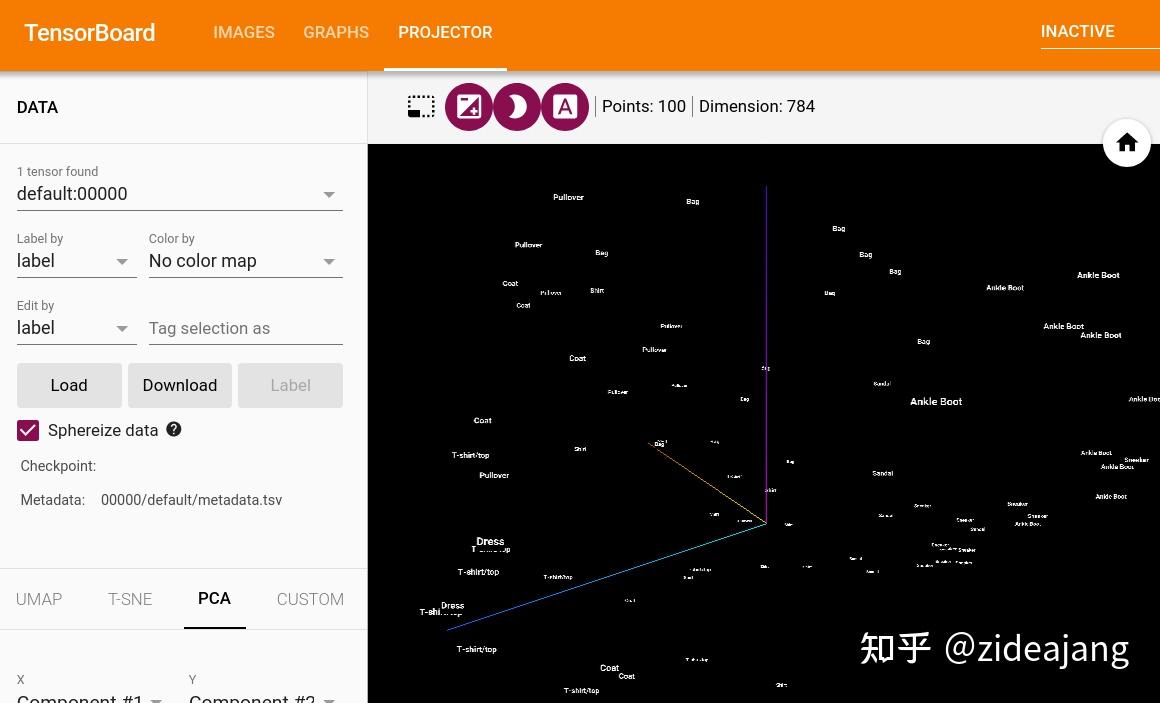
TensorBoard 跟踪模型训练的整个过程
在前面的例子中,通过添加标量标签(SCALARS) 来代替简单地打印了模型的训练过程中,每 2000 次迭代的损失值。现在,训练时损失记录在 TensorBoard 上,同时通过 plot_classes_preds 函数查看模型的预测结果。
def images_to_probs(net, images):'''从训练好的网络和图像列表中生成预测和相应的概率'''output = net(images)# 将输出的概率分布数据转换预测类别,网络输出一个按类别的概率分布,取最大概率对应位置标签就是我们要预测的结果_, preds_tensor = torch.max(output, 1)preds = np.squeeze(preds_tensor.numpy())return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)]def plot_classes_preds(net, images, labels):'''使用训练好的网络以及抽取一批图像和标签生成 matplotlib 图来显示网络训练效果,包括预测结果及其概率值,通过标签文字颜色来反映预测结果的正确性'''preds, probs = images_to_probs(net, images)# 将预测的结果和标签连同图一起显示出来fig = plt.figure(figsize=(12, 48))for idx in np.arange(4):ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[])matplotlib_imshow(images[idx], one_channel=True)ax.set_title("{0}, {1:.1f}%\n(label: {2})".format(classes[preds[idx]],probs[idx] * 100.0,classes[labels[idx]]),color=("green" if preds[idx]==labels[idx].item() else "red"))return fig
模型训练过程记录下来以便于分析,这些图形数据可以让我们分析出训练过程中一些问题,以及在下一步应该如何调整模型超参数,每 1000个 批次将结果写入 TensorBoard,而不是打印到控制台,这是用 add_scalar 函数完成的在 TensorBoard 输出。
此外,当我们训练时,我们将生成一张图片,显示模型的预测与该批中包括的 4 张图片的实际结果。
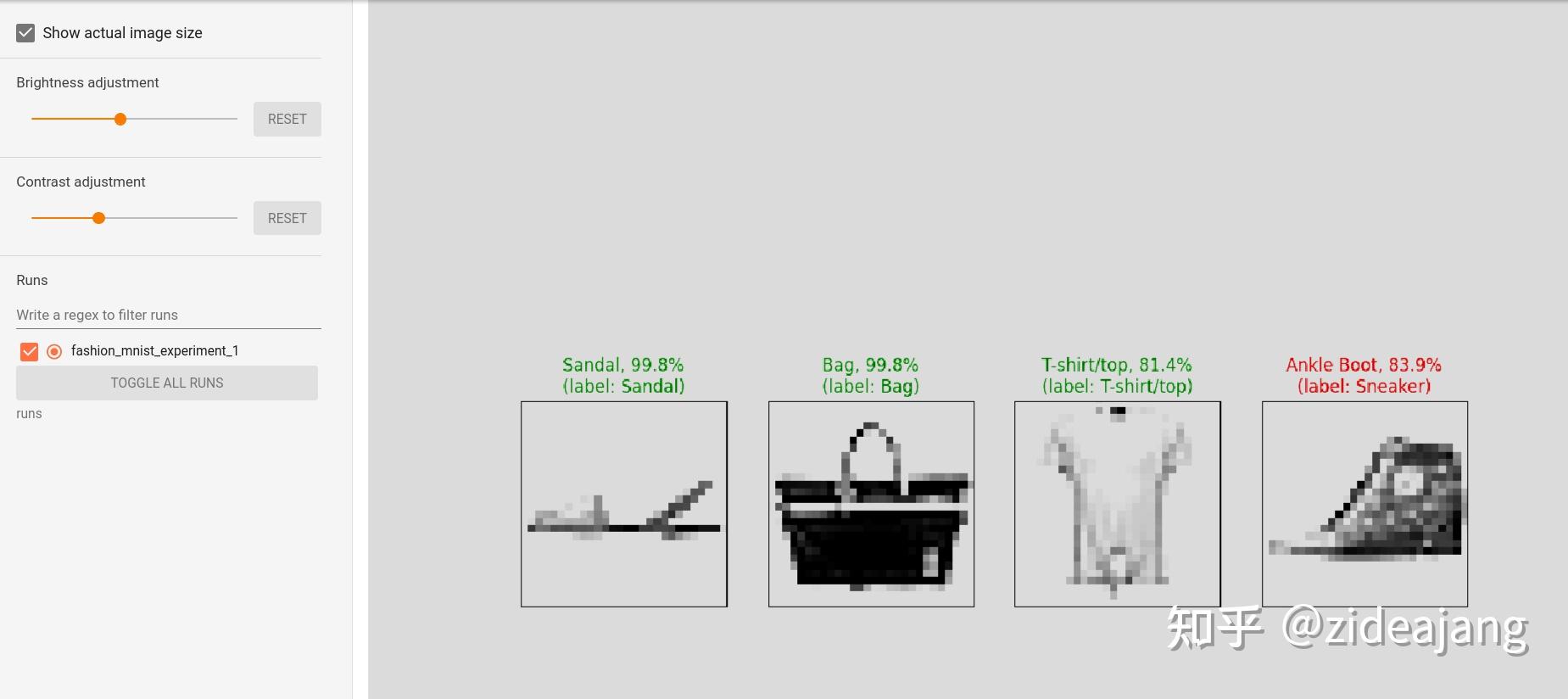
此外,可以看一下模型在整个学习过程中对任意批次的预测情况。请看"图像(Images)"选项卡,在"predictions vs. actuals"可视化下往下看,可以看到一下图
更多示例三
本章代码:
这篇文章主要介绍了 PyTorch 中的优化器,包括 3 个部分:优化器的概念、optimizer 的属性、optimizer 的方法。
TensorBoard 是 TensorFlow 中强大的可视化工具,支持标量、文本、图像、音频、视频和 Embedding 等多种数据可视化。
在 PyTorch 中也可以使用 TensorBoard,具体是使用 TensorboardX 来调用 TensorBoard。除了安装 TensorboardX,还要安装 TensorFlow 和 TensorBoard,其中 TensorFlow 和 TensorBoard 需要一致。
TensorBoardX 可视化的流程需要首先编写 Python 代码把需要可视化的数据保存到 event file 文件中,然后再使用 TensorBoardX 读取 event file 展示到网页中。
下面的代码是一个保存 event file 的例子:
import numpy as npimport matplotlib.pyplot as pltfrom tensorboardX import SummaryWriterfrom common_tools import set_seedmax_epoch = 100writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")for x in range(max_epoch):writer.add_scalar('y=2x', x * 2, x)writer.add_scalar('y=pow_2_x', 2 ** x, x)writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),"xcosx": x * np.cos(x)}, x)writer.close()
上面具体保存的数据,我们先不关注,主要关注的是保存 event file 需要用到 SummaryWriter 类,这个类是用于保存数据的最重要的类,执行完后,会在当前文件夹生成一个runs的文件夹,里面保存的就是数据的 event file。
然后在命令行中输入tensorboard --logdir=lesson5/runs启动 tensorboard 服务,其中lesson5/runs是runs文件夹的路径。然后命令行会显示 tensorboard 的访问地址:
TensorBoard 1.9.0 at http://LAPTOP-DPDNNJSU:6006 (Press CTRL+C to quit)
在浏览器中打开,显示如下:
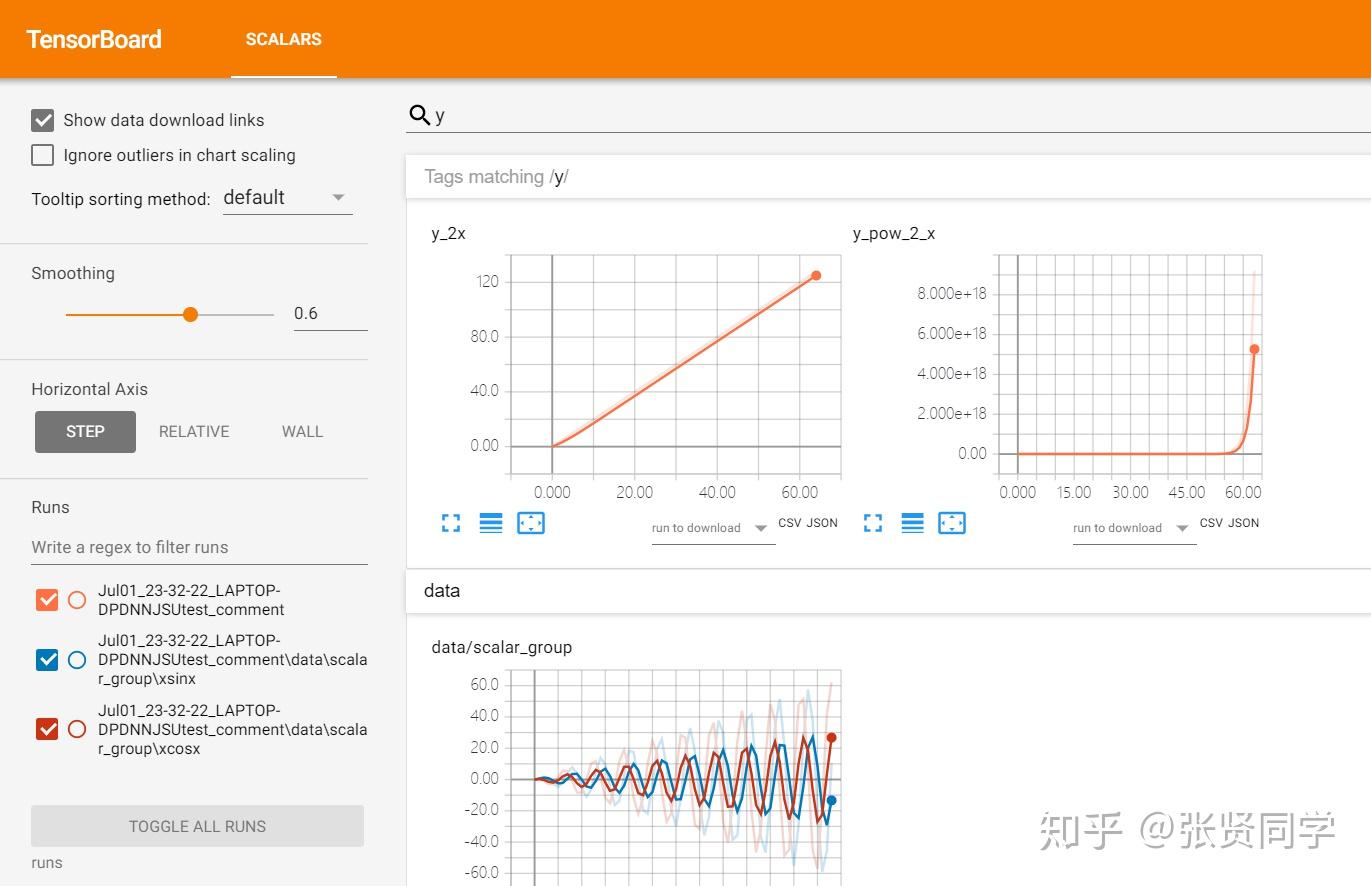
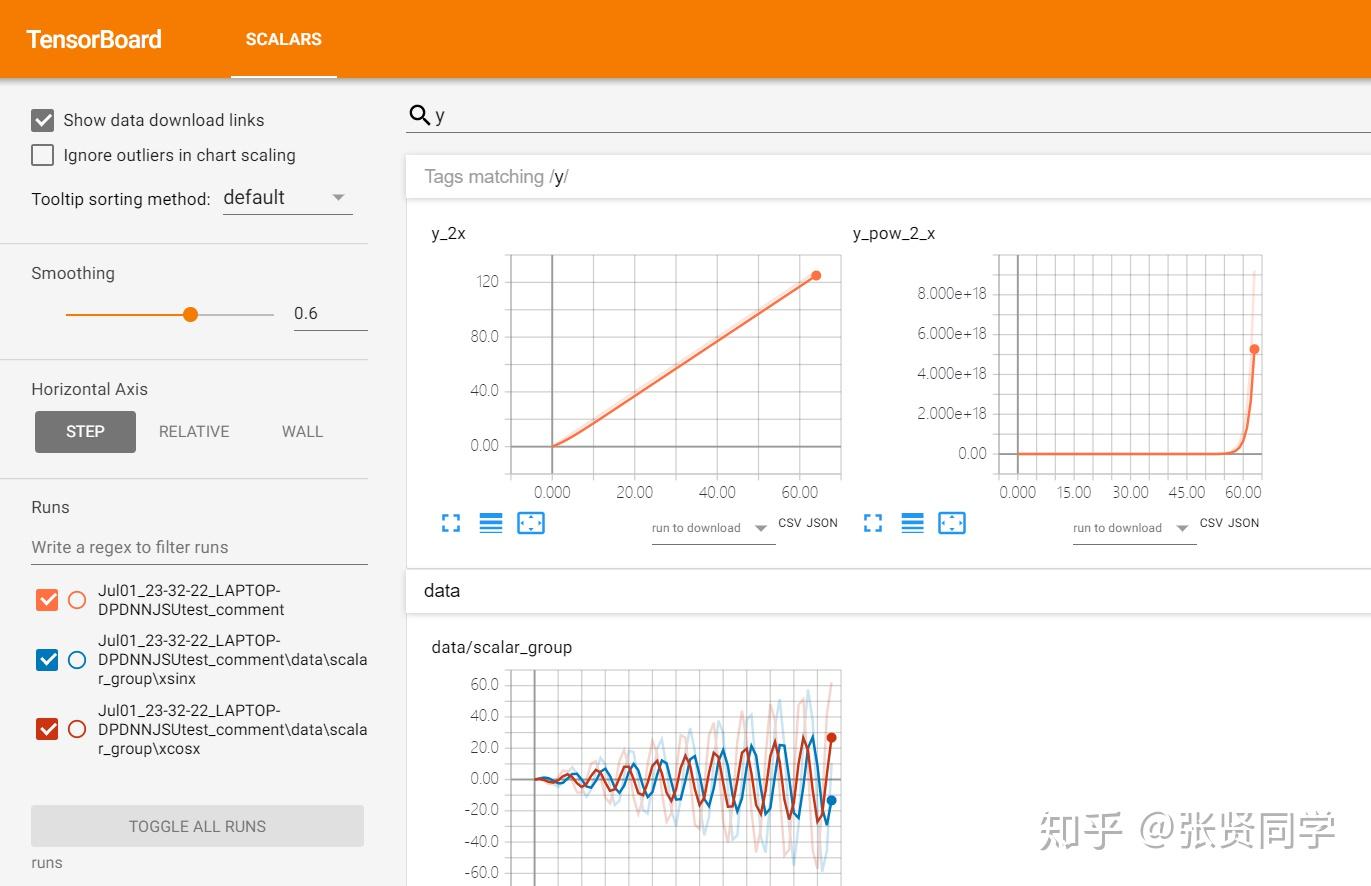
最上面的一栏显示的是数据类型,由于我们在代码中只记录了 scalar 类型的数据,因此只显示SCALARS。
右上角有一些功能设置

点击INACTIVE显示我们没有记录的数据类型。设置里可以设置刷新 tensorboard 的间隔,在模型训练时可以实时监控数据的变化。
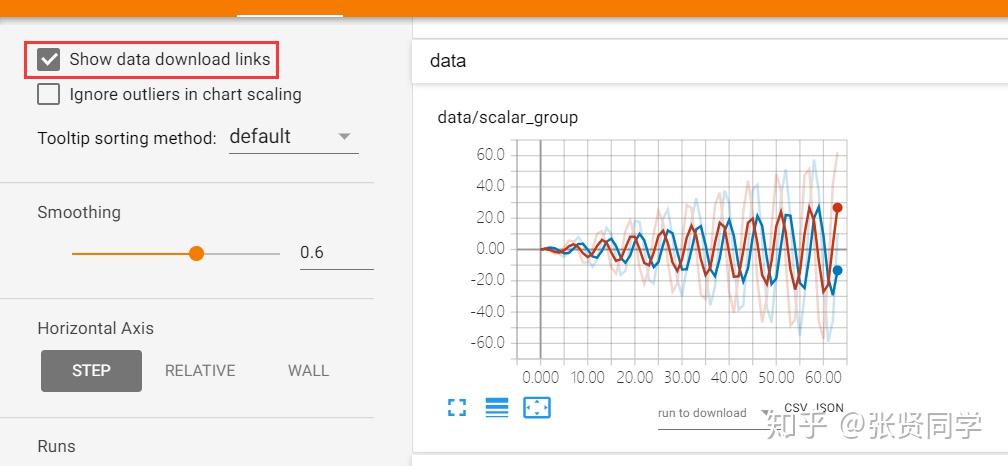
左边的菜单栏如下,点击Show data download links可以展示每个图的下载按钮,如果一个图中有多个数据,需要选中需要下载的曲线,然后下载,格式有 csv和json可选。
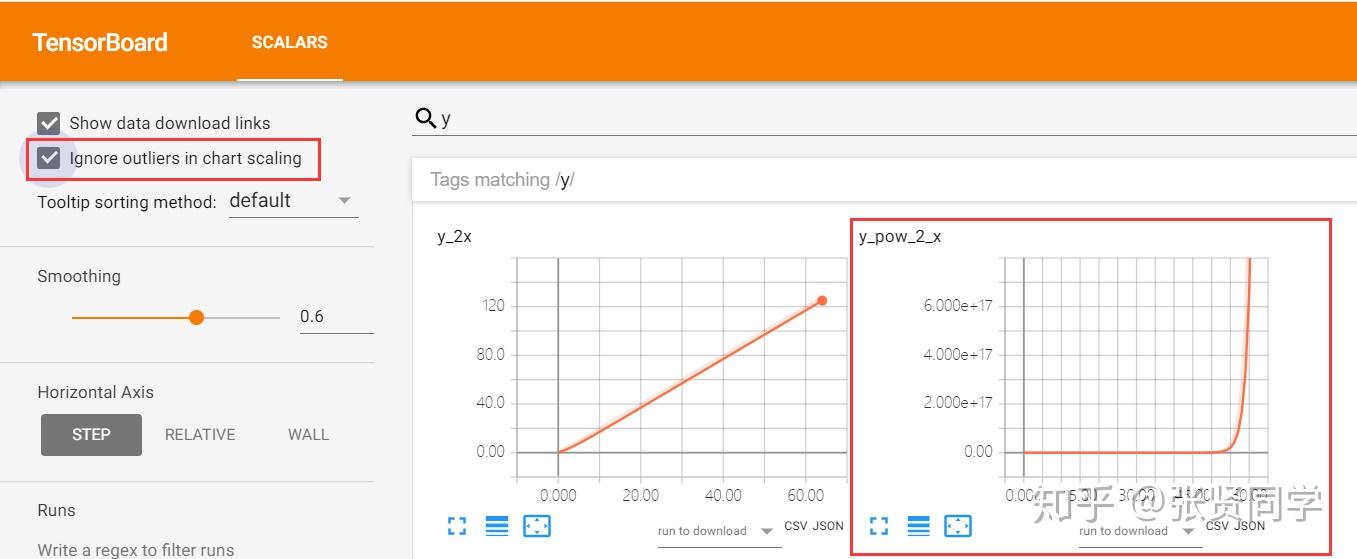
第二个选项Ignore outliers in chart scaling可以设置是否忽略离群点,在y_pow_2_x中,数据的尺度达到了 10^{18},勾选Ignore outliers in chart scaling后 y 轴的尺度下降到 10^{17}。
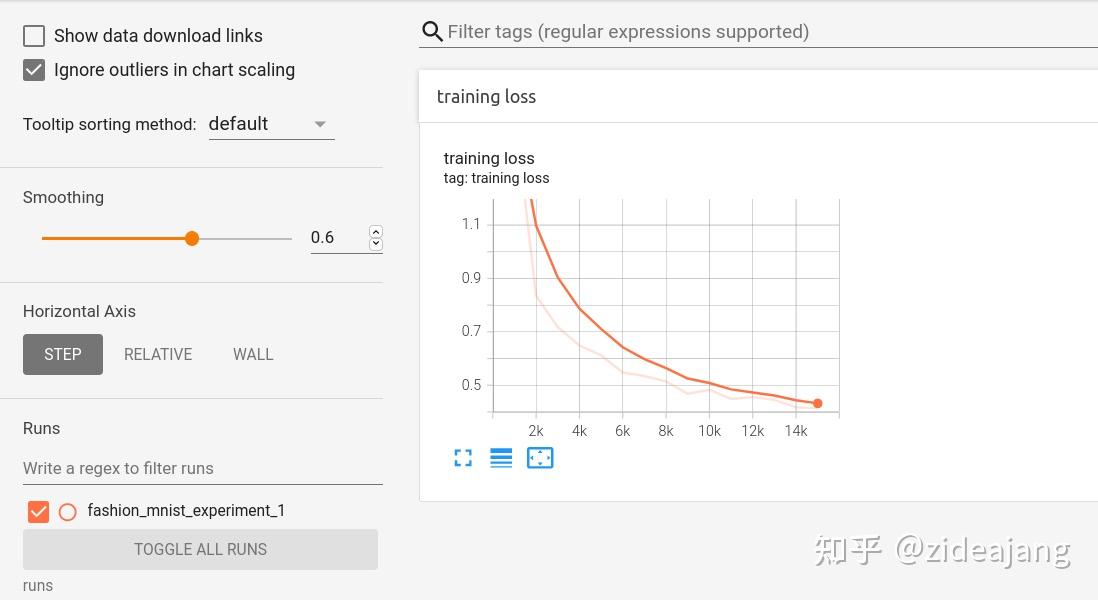
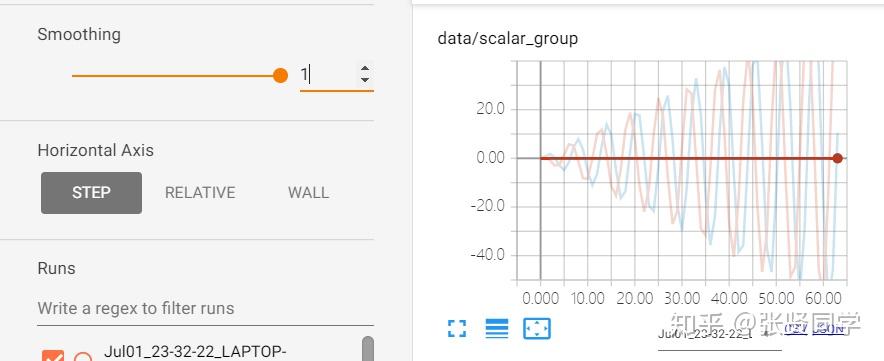
Soothing 是对图像进行平滑,下图中,颜色较淡的阴影部分才是真正的曲线数据,Smoothing 设置为了 0.6,进行了平滑才展示为颜色较深的线。
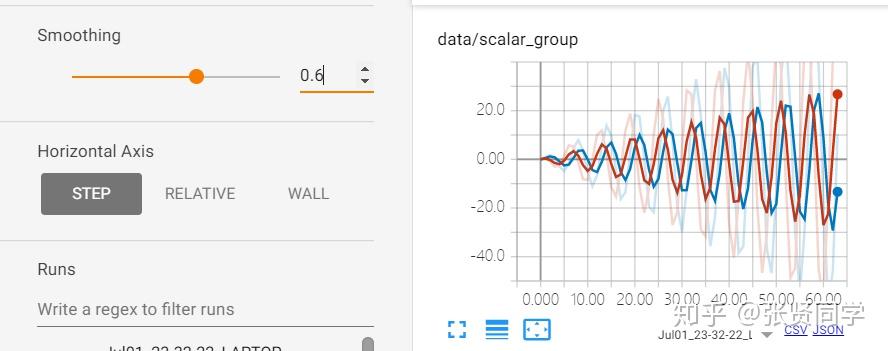
Smoothing 设置为 0,没有进行平滑,显示如下:
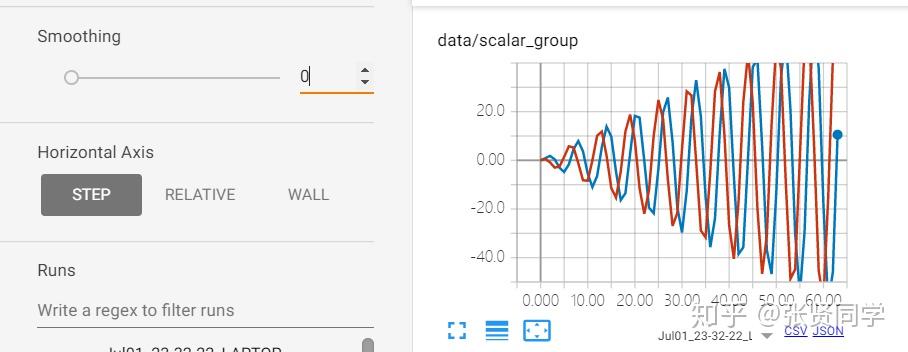
Smoothing 设置为 1,则平滑后的线和 x 轴重合,显示如下:
Horizontal Axis表示横轴:STEP表示原始数据作为横轴,RELATIVE和WALL都是以时间作为横轴,单位是小时,RELATIVE是相对时间,WALL是绝对时间。
runs显示所有的 event file,可以选择展示某些 event file 的图像,其中正方形按钮是多选,圆形按钮是单选。

上面的搜索框可以根据 tags 来搜索数据对应的图像

# optimizer 的属性
PyTorch 中提供了 Optimizer 类,定义如下:
class Optimizer(object):def __init__(self, params, defaults):self.defaults = defaultsself.state = defaultdict(dict)self.param_groups = []
主要有 3 个属性
- defaults:优化器的超参数,如 weight_decay,momentum
- state:参数的缓存,如 momentum 中需要用到前几次的梯度,就缓存在这个变量中
- param_groups:管理的参数组,是一个 list,其中每个元素是字典,包括 momentum、lr、weight_decay、params 等。
- _step_count:记录更新 次数,在学习率调整中使用
SummaryWriter
torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
功能:提供创建 event file 的高级接口
主要功能:
- log_dir:event file 输出文件夹,默认为
runs文件夹 - comment:不指定 log_dir 时,
runs文件夹里的子文件夹后缀 - filename_suffix:event_file 文件名后缀
代码如下:
log_dir = "./train_log/test_log_dir"writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")# writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")for x in range(100):writer.add_scalar('y=pow_2_x', 2 ** x, x)writer.close()
运行后会生成train_log/test_log_dir文件夹,里面的 event file 文件名后缀是12345678。

但是我们指定了log_dir,comment参数没有生效。如果想要comment参数生效,把SummaryWriter的初始化改为writer = SummaryWriter(comment='_scalars', filename_suffix="12345678"),生成的文件夹如下,runs里的子文件夹后缀是_scalars。

# add_scalar
add_scalar(tag, scalar_value, global_step=None, walltime=None)
功能:记录标量
- tag:图像的标签名,图的唯一标识
- scalar_value:要记录的标量,y 轴的数据
- global_step:x 轴的数据
add_scalars
上面的add_scalar()只能记录一条曲线的数据。但是我们在实际中可能需要在一张图中同时展示多条曲线,比如在训练模型时,经常需要同时查看训练集和测试集的 loss。这时我们可以使用add_scalars()方法
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
- main_tag:该图的标签
- tag_scalar_dict:用字典的形式记录多个曲线。key 是变量的 tag,value 是变量的值
代码如下:
max_epoch = 100writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")for x in range(max_epoch):writer.add_scalar('y=2x', x * 2, x)writer.add_scalar('y=pow_2_x', 2 ** x, x)writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),"xcosx": x * np.cos(x)}, x)writer.close()
运行后生成 event file,然后使用 TensorBoard 来查看如下:
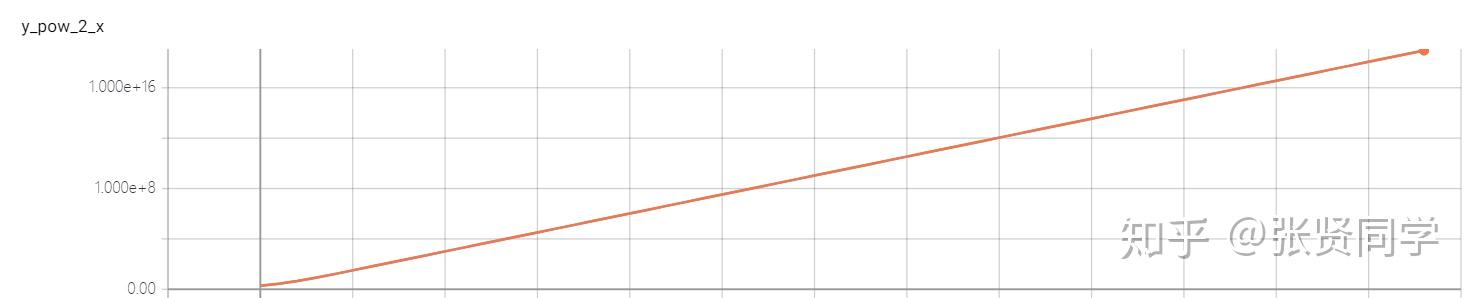
每个图像下面都有 3 个按钮,中间的按钮是以对数形式展示 y 轴。如对y=pow_2_x曲线的 y 轴取对数展示如下,变成了直线。
# add_histogram
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
功能:统计直方图与多分位折线图
- tag:图像的标签名,图的唯一标识
- values:要统计的参数,通常统计权值、偏置或者梯度
- global_step:第几个子图
- bins:取直方图的 bins
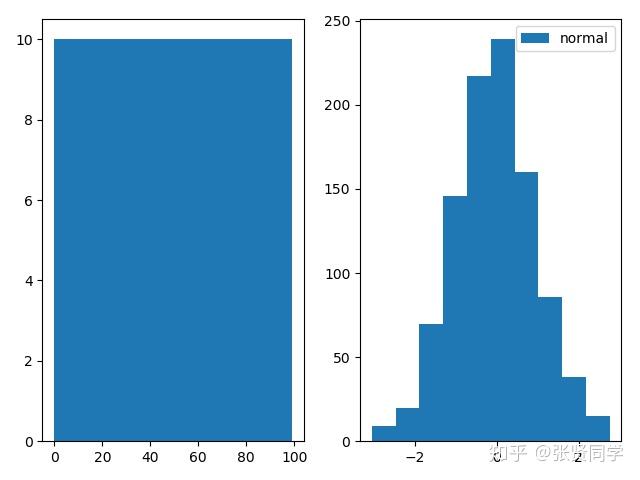
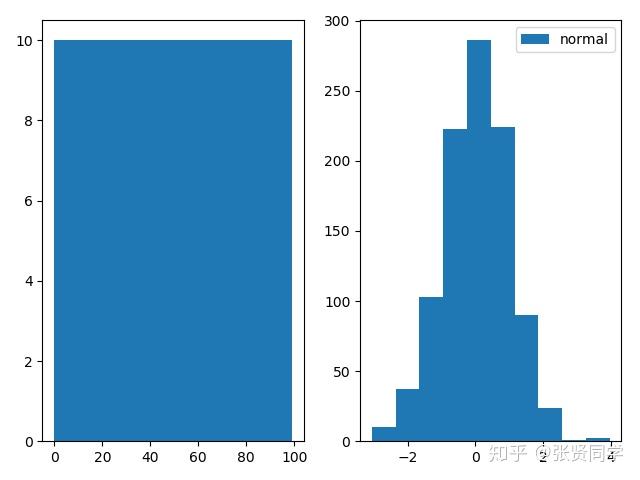
下面的代码构造了均匀分布和正态分布,循环生成了 2 次,分别用matplotlib和 TensorBoard 进行画图。
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")for x in range(2):np.random.seed(x)data_union = np.arange(100)data_normal = np.random.normal(size=1000)writer.add_histogram('distribution union', data_union, x)writer.add_histogram('distribution normal', data_normal, x)plt.subplot(121).hist(data_union, label="union")plt.subplot(122).hist(data_normal, label="normal")plt.legend()plt.show()writer.close()
matplotlib画图显示如下:
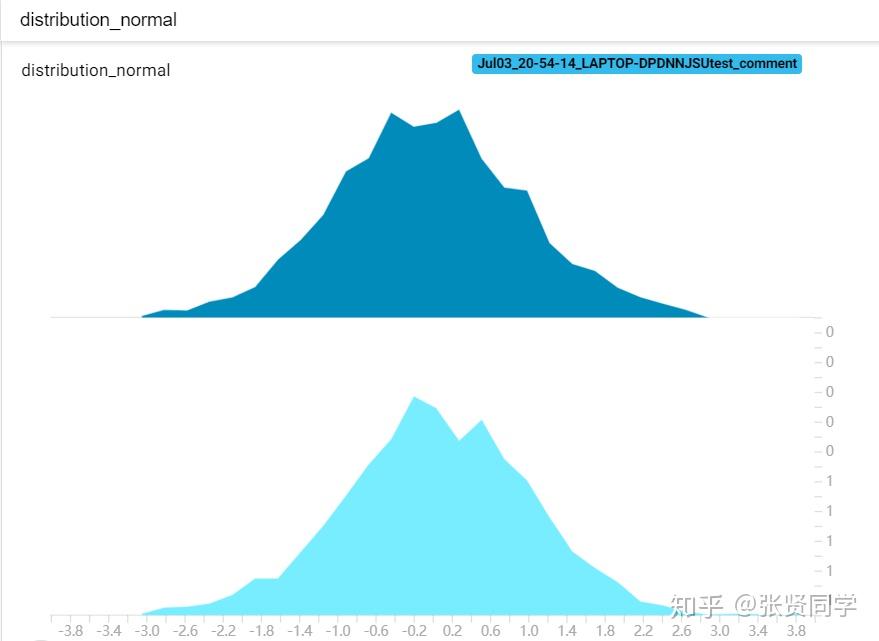
TensorBoard 显示结果如下。
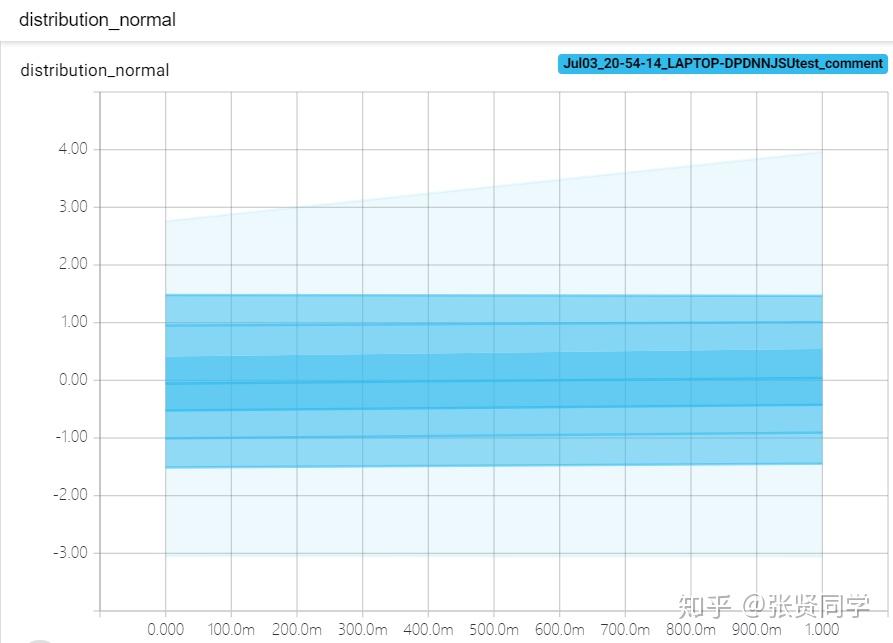
正态分布显示如下,每个子图分别对应一个 global_step:
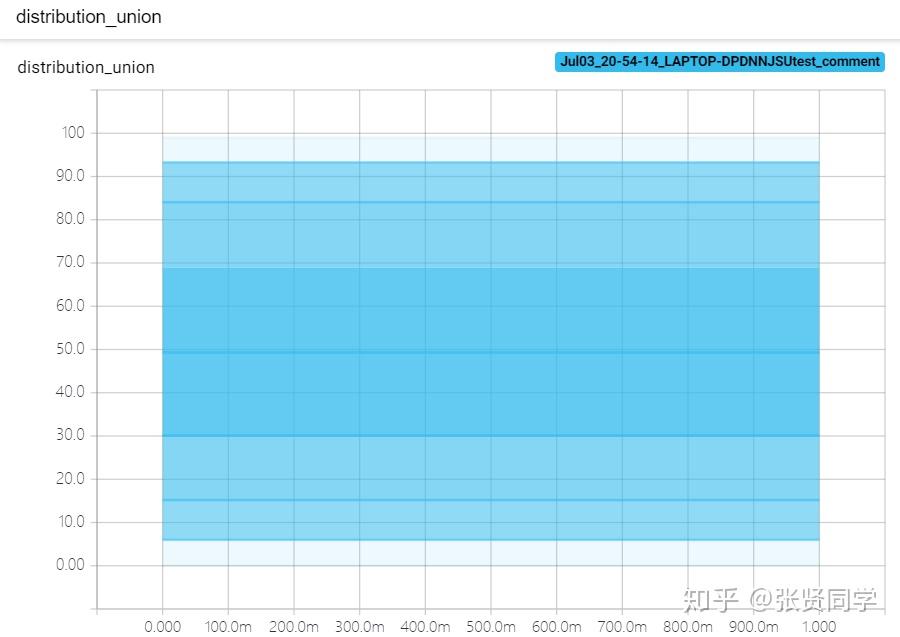
均匀分布显示如下,显示曲线的原因和bins参数设置有关,默认是tensorflow:
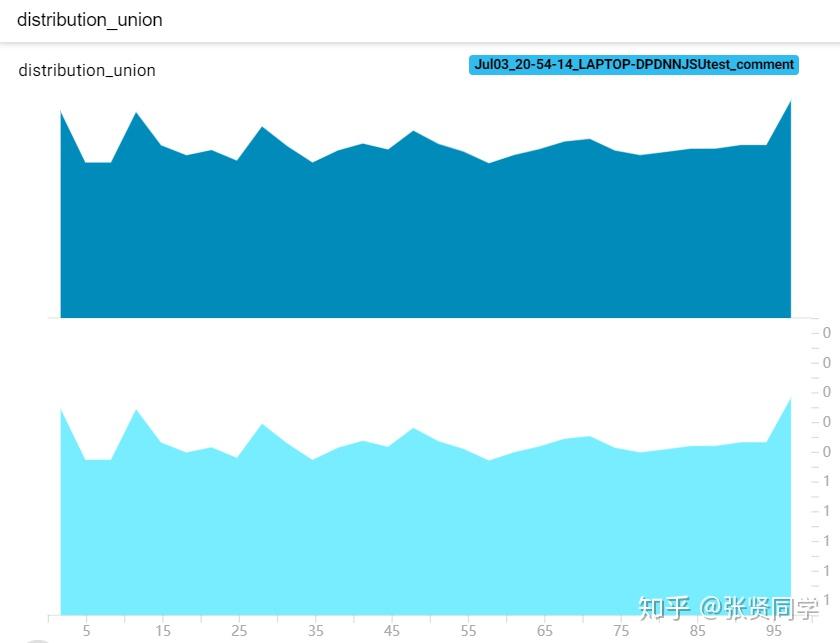
除此之外,还会得到DISTRIBUTIONS,这是多分位折线图,纵轴有 9 个折线,表示数据的分布区间,某个区间的颜色越深,表示这个区间的数所占比例越大。横轴是 global_step。这个图的作用是观察数方差的变化情况。显示如下:
# 模型指标监控
下面使用 TensorBoard 来监控人民币二分类实验训练过程中的 loss、accuracy、weights 和 gradients 的变化情况。
首先定义一个SummaryWriter。
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
然后在每次训练中记录 loss 和 accuracy 的值
# 记录数据,保存于event file
writer.add_scalars("Loss", {"Train": loss.item()}, iter_count)
writer.add_scalars("Accuracy", {"Train": correct / total}, iter_count)
并且在验证时记录所有验证集样本的 loss 和 accuracy 的均值
# 记录数据,保存于event file
writer.add_scalars("Loss", {"Valid": np.mean(valid_curve)}, iter_count)
writer.add_scalars("Accuracy", {"Valid": correct / total}, iter_count)
并且在每个 epoch 中记录每一层权值以及权值的梯度。
# 每个epoch,记录梯度,权值for name, param in net.named_parameters():writer.add_histogram(name + '_grad', param.grad, epoch)writer.add_histogram(name + '_data', param, epoch)
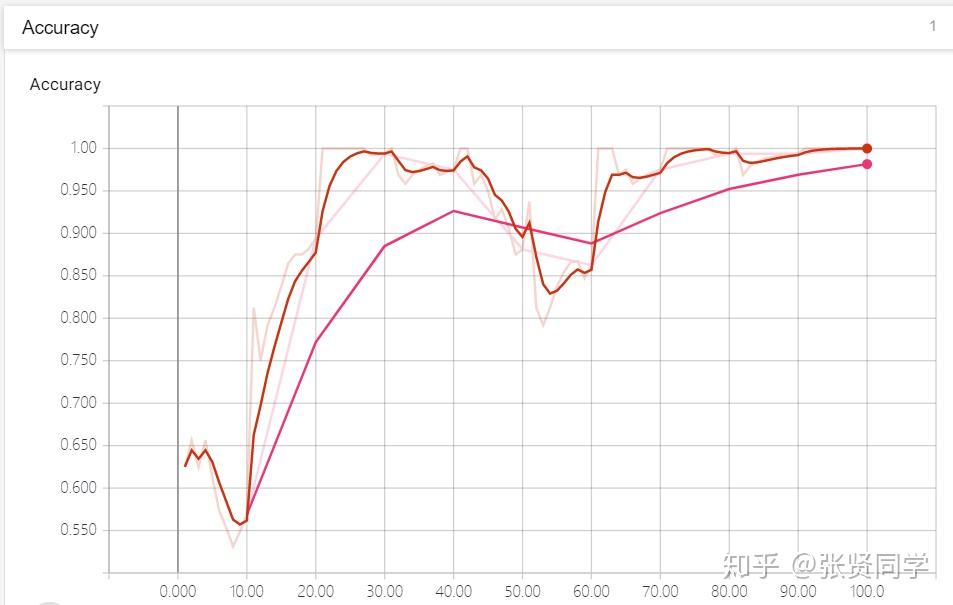
在训练还没结束时,就可以启动 TensorBoard 可视化,Accuracy 的可视化如下,颜色较深的是训练集的 Accuracy,颜色较浅的是 验证集的样本:
Loss 的可视化如下,其中验证集的 Loss 是从第 10 个 epoch 才开始记录的,并且 验证集的 Loss 是所有验证集样本的 Loss 均值,所以曲线更加平滑;而训练集的 Loss 是 batch size 的数据,因此震荡幅度较大:
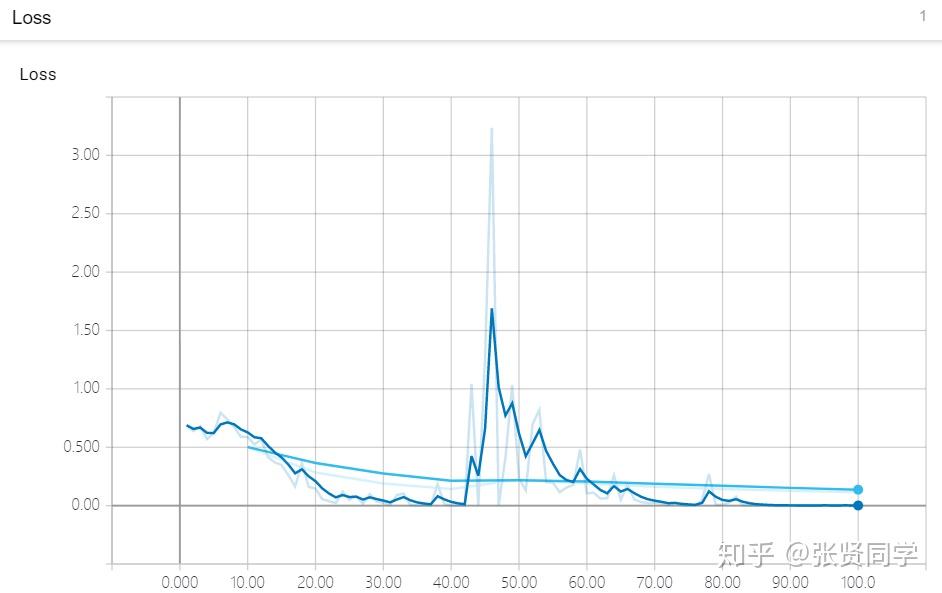
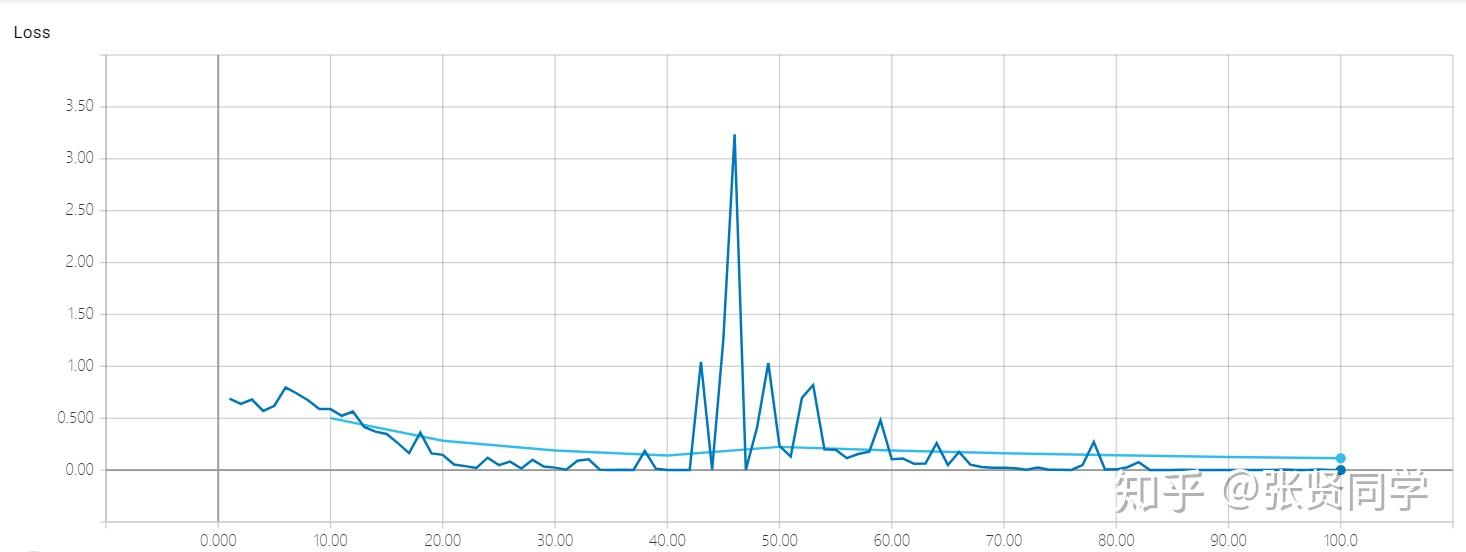
上面的 Loss 曲线图与使用matplotlib画的图不太一样,因为 TensorBoard 默认会进行 Smoothing,我们把 Smoothing 系数设置为 0 后,显示如下:
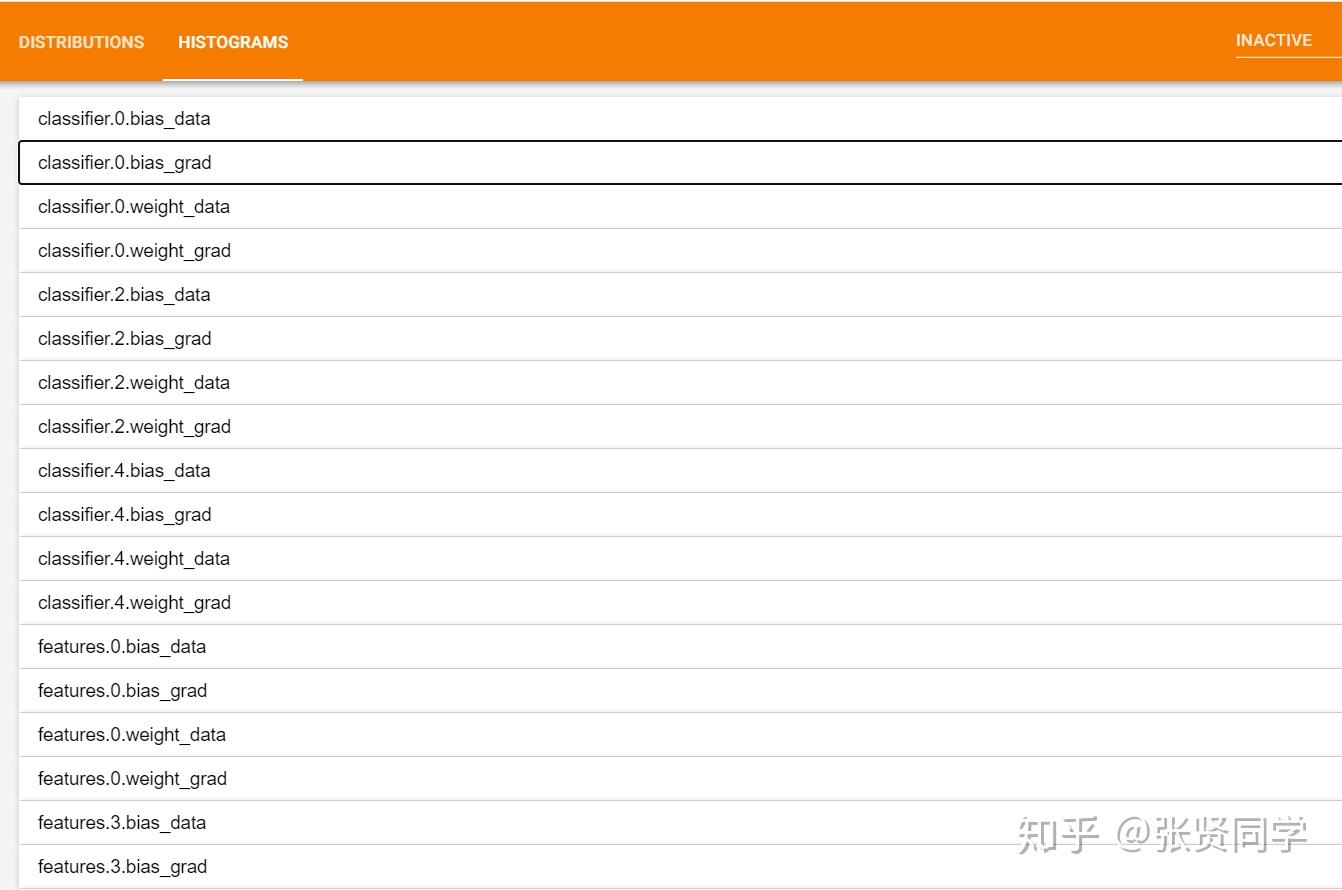
而记录权值以及权值梯度的 HISTOGRAMS 显示如下,记录了每一层的数据:
展开查看第一层的权值和梯度。
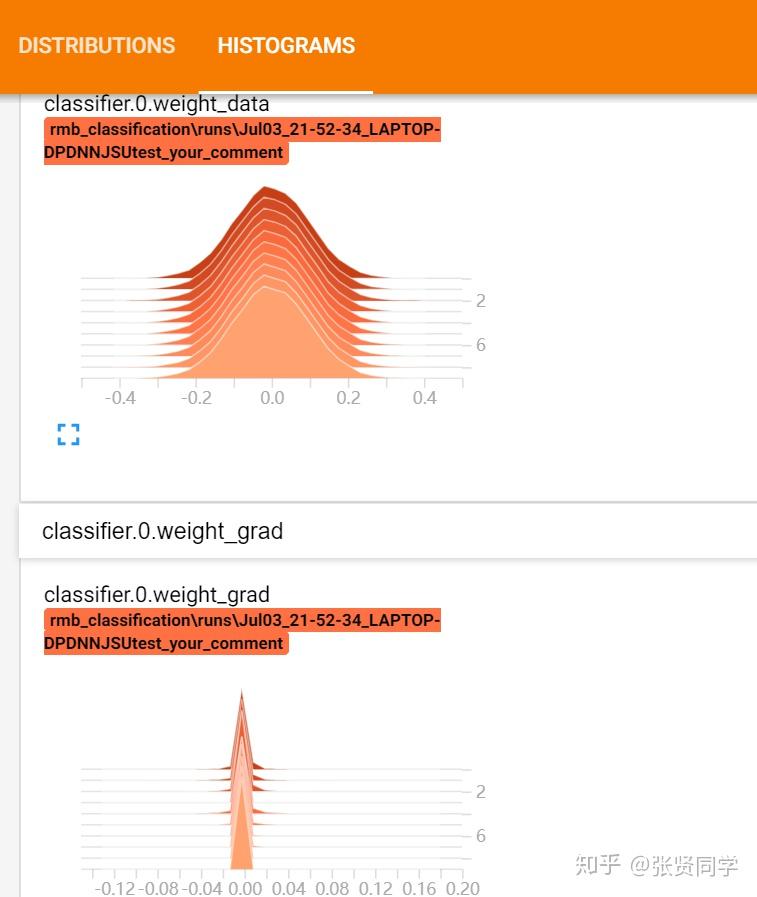
可以看到每一个 epoch 的梯度都是呈正态分布,说明权值分布比较好;梯度都是接近于 0,说明模型很快就收敛了。通常我们使用 TensorBoard 查看我们的网络参数在训练时的分布变化情况,如果分布很奇怪,并且 Loss 没有下降,这时需要考虑是什么原因改变了数据的分布较大的。如果前面网络层的梯度很小,后面网络层的梯度比较大,那么可能是梯度消失,因为后面网络层的较大梯度反向传播到前面网络层时已经变小了。如果前后网络层的梯度都很小,那么说明不是梯度消失,而是因为 Loss 很小,模型已经接近收敛。
add_image
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
功能:记录图像
- tag:图像的标签名,图像的唯一标识
- img_tensor:图像数据,需要注意尺度
- global_step:记录这是第几个子图
- dataformats:数据形式,取值有’CHW’,‘HWC’,‘HW’。如果像素值在 [0, 1] 之间,那么默认会乘以 255,放大到 [0, 255] 范围之间。如果有大于 1 的像素值,认为已经是 [0, 255] 范围,那么就不会放大。
代码如下:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")# img 1 random
# 随机噪声的图片
fake_img = torch.randn(3, 512, 512)
writer.add_image("fake_img", fake_img, 1)
time.sleep(1)# img 2 ones
# 像素值全为 1 的图片,会乘以 255,所以是白色的图片
fake_img = torch.ones(3, 512, 512)
time.sleep(1)
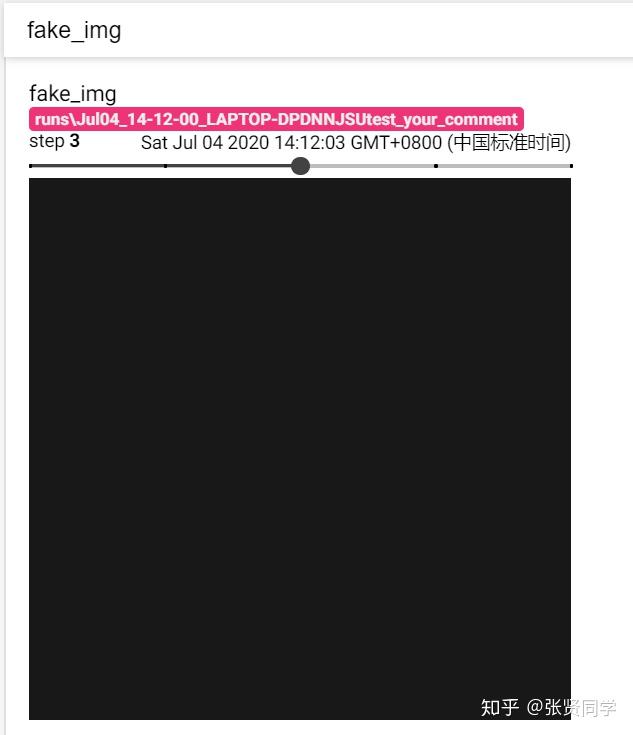
writer.add_image("fake_img", fake_img, 2)# img 3 1.1
# 像素值全为 1.1 的图片,不会乘以 255,所以是黑色的图片
fake_img = torch.ones(3, 512, 512) * 1.1
time.sleep(1)
writer.add_image("fake_img", fake_img, 3)# img 4 HW
fake_img = torch.rand(512, 512)
writer.add_image("fake_img", fake_img, 4, dataformats="HW")# img 5 HWC
fake_img = torch.rand(512, 512, 3)
writer.add_image("fake_img", fake_img, 5, dataformats="HWC")writer.close()
使用 TensorBoard 可视化如下:
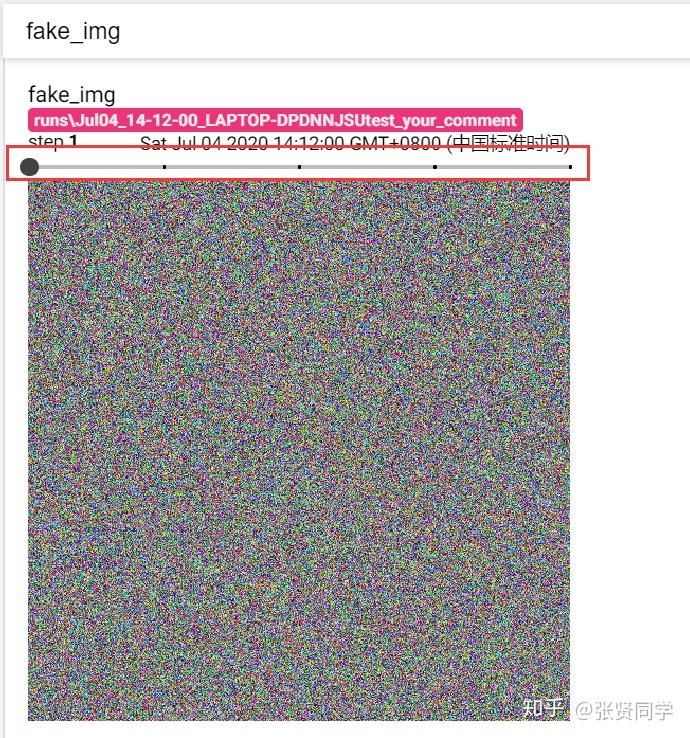
图片上面的step可以选择第几张图片,如选择第 3 张图片,显示如下:
# torchvision.utils.make_grid
上面虽然可以通过拖动显示每张图片,但实际中我们希望在网格中同时展示多张图片,可以用到make_grid()函数。
torchvision.utils.make_grid(tensor: Union[torch.Tensor, List[torch.Tensor]], nrow: int = 8, padding: int = 2, normalize: bool = False, range: Optional[Tuple[int, int]] = None, scale_each: bool = False, pad_value: int = 0)
功能:制作网格图像
- tensor:图像数据,B \times C \times H \times W 的形状
- nrow:行数(列数是自动计算的,为:\frac{B}{nrow})
- padding:图像间距,单位是像素,默认为 2
- normalize:是否将像素值标准化到 [0, 255] 之间
- range:标准化范围,例如原图的像素值范围是 [-1000, 2000],设置 range 为 [-600, 500],那么会把小于 -600 的像素值变为 -600,那么会把大于 500 的像素值变为 500,然后标准化到 [0, 255] 之间
- scale_each:是否单张图维度标准化
- pad_value:间隔的像素值
下面的代码是人民币图片的网络可视化,batch_size 设置为 16,nrow 设置为 4,得到 4 行 4 列的网络图像
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")split_dir = os.path.join(enviroments.project_dir, "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
# train_dir = "path to your training data"
# 先把宽高缩放到 [32, 64] 之间,然后使用 toTensor 把 Image 转化为 tensor,并把像素值缩放到 [0, 1] 之间
transform_compose = transforms.Compose([transforms.Resize((32, 64)), transforms.ToTensor()])
train_data = RMBDataset(data_dir=train_dir, transform=transform_compose)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data_batch, label_batch = next(iter(train_loader))img_grid = vutils.make_grid(data_batch, nrow=4, normalize=True, scale_each=True)
# img_grid = vutils.make_grid(data_batch, nrow=4, normalize=False, scale_each=False)
writer.add_image("input img", img_grid, 0)writer.close()
TensorBoard 显示如下:

# AlexNet 卷积核与特征图可视化
使用 TensorBoard 可视化 AlexNet 网络的前两层卷积核。其中每一层的卷积核都把输出的维度作为 global_step,包括两种可视化方式:一种是每个 (w, h) 维度作为灰度图,添加一个 c 的维度,形成 (b, c, h, w),其中 b 是 输入的维度;另一种是把整个卷积核 reshape 到 c 是 3 的形状,再进行可视化。详细见如下代码:
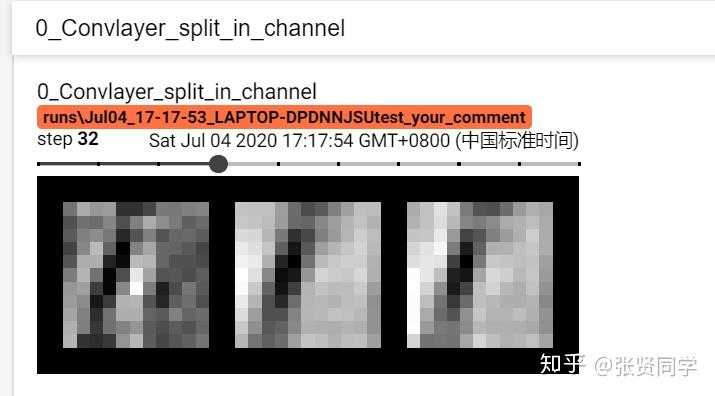
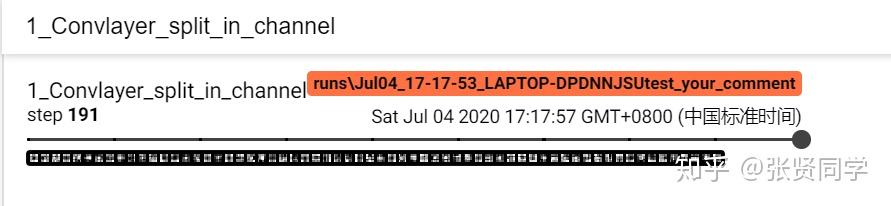
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")alexnet = models.alexnet(pretrained=True)# 当前遍历到第几层网络的卷积核了kernel_num = -1# 最多显示两层网络的卷积核:第 0 层和第 1 层vis_max = 1# 获取网络的每一层for sub_module in alexnet.modules():# 判断这一层是否为 2 维卷积层if isinstance(sub_module, nn.Conv2d):kernel_num += 1# 如果当前层大于1,则停止记录权值if kernel_num > vis_max:break# 获取这一层的权值kernels = sub_module.weight# 权值的形状是 [c_out, c_int, k_w, k_h]c_out, c_int, k_w, k_h = tuple(kernels.shape)# 根据输出的每个维度进行可视化for o_idx in range(c_out):# 取出的数据形状是 (c_int, k_w, k_h),对应 BHW; 需要扩展为 (c_int, 1, k_w, k_h),对应 BCHWkernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度# 注意 nrow 设置为 c_int,所以行数为 1。在 for 循环中每 添加一个,就会多一个 global_stepkernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)# 因为 channe 为 3 时才能进行可视化,所以这里 reshapekernel_all = kernels.view(-1, 3, k_h, k_w) #b, 3, h, wkernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, wwriter.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=kernel_num+1)print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))writer.close()
使用 TensorBoard 可视化如下。
这是根据输出的维度分批展示第一层卷积核的可视化
这是根据输出的维度分批展示第二层卷积核的可视化
这是整个第一层卷积核的可视化

这是整个第二层卷积核的可视化

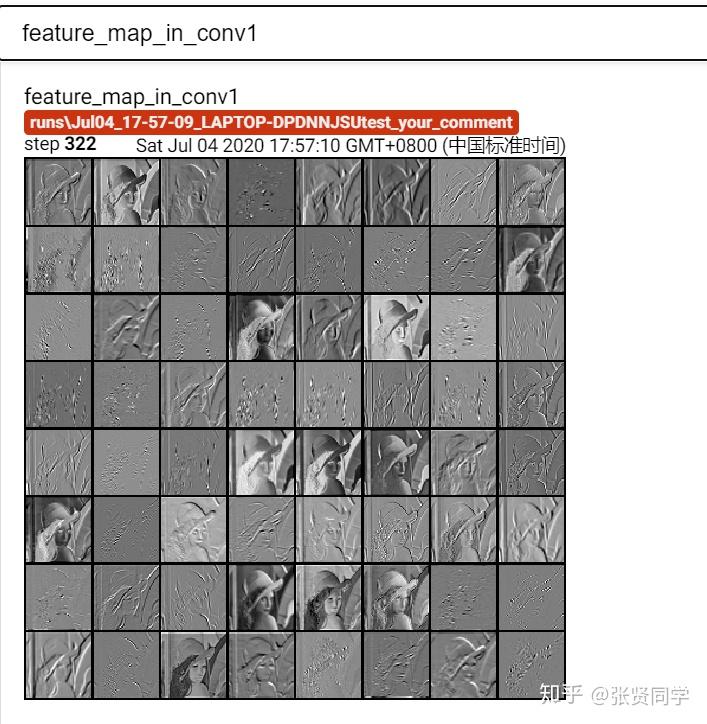
下面把 AlexNet 的第一个卷积层的输出进行可视化,首先对图片数据进行预处理(resize,标准化等操作)。由于在定义模型时,网络层通过nn.Sequential() 堆叠,保存在 features 变量中。因此通过 features 获取第一个卷积层。把图片输入卷积层得到输出,形状为 (1, 64, 55, 55),需要转换为 (64, 1, 55, 55),对应 (B, C, H, W),nrow 设置为 8,最后进行可视化,代码如下:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")# 数据path_img = "./lena.png" # your path to imagenormMean = [0.49139968, 0.48215827, 0.44653124]normStd = [0.24703233, 0.24348505, 0.26158768]norm_transform = transforms.Normalize(normMean, normStd)img_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),norm_transform])img_pil = Image.open(path_img).convert('RGB')if img_transforms is not None:img_tensor = img_transforms(img_pil)img_tensor.unsqueeze_(0) # chw --> bchw# 模型alexnet = models.alexnet(pretrained=True)# forward# 由于在定义模型时,网络层通过nn.Sequential() 堆叠,保存在 features 变量中。因此通过 features 获取第一个卷积层convlayer1 = alexnet.features[0]# 把图片输入第一个卷积层fmap_1 = convlayer1(img_tensor)# 预处理fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)writer.add_image('feature map in conv1', fmap_1_grid, global_step=322)writer.close()
使用 TensorBoard 可视化如下:
# add_graph
add_graph(model, input_to_model=None, verbose=False)
功能:可视化模型计算图
- model:模型,必须继承自 nn.Module
- input_to_model:输入给模型的数据,形状为 BCHW
- verbose:是否打印图结构信息
查看 LeNet 的计算图代码如下:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")# 模型fake_img = torch.randn(1, 3, 32, 32)lenet = LeNet(classes=2)writer.add_graph(lenet, fake_img)writer.close()
使用 TensorBoard 可视化如下:
torchsummary
模型计算图的可视化还是比较复杂,不够清晰。而torchsummary能够查看模型的输入和输出的形状,可以更加清楚地输出模型的结构。
torchsummary.summary(model, input_size, batch_size=-1, device="cuda")
功能:查看模型的信息,便于调试
- model:pytorch 模型,必须继承自 nn.Module
- input_size:模型输入 size,形状为 CHW
- batch_size:batch_size,默认为 -1,在展示模型每层输出的形状时显示的 batch_size
- device:“cuda"或者"cpu”
查看 LeNet 的模型信息代码如下:
# 模型lenet = LeNet(classes=2)print(summary(lenet, (3, 32, 32), device="cpu"))
输出如下:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 6, 28, 28] 456Conv2d-2 [-1, 16, 10, 10] 2,416Linear-3 [-1, 120] 48,120Linear-4 [-1, 84] 10,164Linear-5 [-1, 2] 170
================================================================
Total params: 61,326
Trainable params: 61,326
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.05
Params size (MB): 0.23
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
None
上述信息分别有模型每层的输出形状,每层的参数数量,总的参数数量,以及模型大小等信息。
我们以第一层为例,第一层卷积核大小是 (6, 3, 5, 5),每个卷积核还有一个偏置,因此 6 × 3 × 5 × 5 + 6 = 456 6 \times 3 \times 5 \times 5+6=456 6×3×5×5+6=456。
mary**
模型计算图的可视化还是比较复杂,不够清晰。而torchsummary能够查看模型的输入和输出的形状,可以更加清楚地输出模型的结构。
torchsummary.summary(model, input_size, batch_size=-1, device="cuda")
功能:查看模型的信息,便于调试
- model:pytorch 模型,必须继承自 nn.Module
- input_size:模型输入 size,形状为 CHW
- batch_size:batch_size,默认为 -1,在展示模型每层输出的形状时显示的 batch_size
- device:“cuda"或者"cpu”
查看 LeNet 的模型信息代码如下:
# 模型lenet = LeNet(classes=2)print(summary(lenet, (3, 32, 32), device="cpu"))
输出如下:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 6, 28, 28] 456Conv2d-2 [-1, 16, 10, 10] 2,416Linear-3 [-1, 120] 48,120Linear-4 [-1, 84] 10,164Linear-5 [-1, 2] 170
================================================================
Total params: 61,326
Trainable params: 61,326
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.05
Params size (MB): 0.23
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
None
上述信息分别有模型每层的输出形状,每层的参数数量,总的参数数量,以及模型大小等信息。
我们以第一层为例,第一层卷积核大小是 (6, 3, 5, 5),每个卷积核还有一个偏置,因此 6 × 3 × 5 × 5 + 6 = 456 6 \times 3 \times 5 \times 5+6=456 6×3×5×5+6=456。






 软件篇 中)







)


 软件篇 下)

