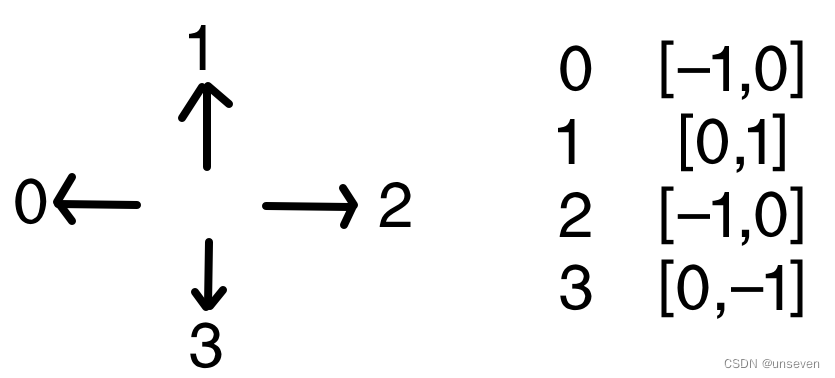摘要
Non-local patch based methods were until recently state-of-the-art for image denoising but are now outper formed by CNNs. Y et they are still the state-of-the-art for video denoising, as video redundancy is a key factor to attain high denoising performance. The problem is that CNN architectures are hardly compatible with the search for self-similarities. In this work we propose a new and efficient way to feed video self-similarities to a CNN. The non-locality is incorporated into the network via a first non-trainable layer which finds for each patch in the input image its most similar patches in a search region. The central values of these patches are then gathered in a feature vector which is assigned to each image pixel. This information is presented to a CNN which is trained to predict the clean image. We apply the proposed architecture to image and video denoising. For the latter patches are searched for in a 3D spatio-temporal volume. The proposed architecture achieves state-of-the-art results. To the best of our knowledge, this is the first successful application of a CNN to video denoising.
基于非局部补丁的方法直到最近才成为图像去噪的最先进技术,但现在被 CNN 超越。然而,它们仍然是视频去噪的最先进技术,因为视频冗余是获得高去噪性能的关键因素。问题在于 CNN 架构与搜索自相似性几乎不兼容。在这项工作中,我们提出了一种将视频自相似性提供给 CNN 的新的有效方法。非局部性通过第一个不可训练层合并到网络中,该层为输入图像中的每个补丁找到其在搜索区域中最相似的补丁。然后将这些补丁的中心值收集在分配给每个图像像素的特征向量中。该信息被呈现给经过训练以预测干净图像的 CNN。我们将所提出的架构应用于图像和视频去噪。对于后者,在 3D 时空体积中搜索补丁。所提出的架构实现了最先进的结果。据我们所知,这是 CNN 首次成功应用于视频去噪。
introduction
(1)曝光时间有限情况下低信噪比不可避免,且噪声很高
(2)通过将去噪算法迭代应用,因此,减少运行时间很重要
图像去噪相关文献
(1)CNNs are amenable to efficient parallelization on GPUs potentially enabling real-time performance.
(2) two types of CNN approaches: trainable inference networks and black box networks.(可训练推理的网络模型和无需训练的模型)
2.1 第一种通过模仿一些优化算法的迭代而执行得到结果,但是可能会导致一些不一样的架构、造成网络模型设计的限制
2.2 第二种将其视为标准的回归问题,虽然没有使用之前过多的研究,但是其技术名列前茅,比如CNN
2.3 引出Although these architectures produce very good results,
for textures formed by repetitive patterns, non-local patch-based methods still perform better
Although these architectures produce very good results, for textures formed by repetitive patterns, non-local patch-based methods still perform better
视频去噪相关文献
1、CNN应用于视频处理很多方面,但是在视频去噪中有限。
2、在输出质量方面,the state-of-the-art is achieved by patch-based methods [16、35、3、19、9、53]。他们极大地利用了自然图像和视频的自相似性,即大多数补丁周围都有几个相似的补丁(空间和时间)。每个补丁都使用这些相似的补丁进行去噪,这些补丁在其周围的区域中进行搜索。搜索区域通常是一个时空立方体,但也使用了涉及光流的更复杂的搜索策略。由于使用了如此广泛的搜索邻域,这些方法被称为non-local。
优点:perform very well 缺点: computation-ally costly( Because of their complexity)
不适用于: high resolution video processing.
3、Patch-based methods usually follow three steps that can
be iterated:(1)搜索相似的补丁,(2)对相似的补丁组进行去噪,(3)聚合去噪的补丁以形成去噪帧。
VBM3D [16] 改进了图像去噪算法 BM3D [17],通过使用“预测搜索”策略在相邻帧中搜索相似的补丁,加速搜索并提供一些时间一致性。 VBM4D [35] 将这个想法推广到 3D 补丁。在 VNLB [2] 中,未进行运动补偿的时空补丁用于提高时间一致性。在 [19] 中,一种通用搜索方法通过将补丁搜索扩展到整个视频,将每个基于补丁的去噪算法扩展为全局视频去噪算法。 SPTWO [9] 和 DDVD [8] 使用光流将相邻帧扭曲到每个目标帧。然后使用类似于 [29] 的贝叶斯策略,使用该卷中的类似块对目标帧的每个块进行去噪。最近,[53] 提出使用批量帧来学习自适应最优变换
4、基于补丁的方法也实现了帧递归方法中的最新技术[20, 4]。这些方法仅使用当前噪声帧和前一个去噪帧来计算当前帧。与非递归方法相比,它们获得的结果更低,但内存占用更少,并且(可能)计算成本更低。
Contributions
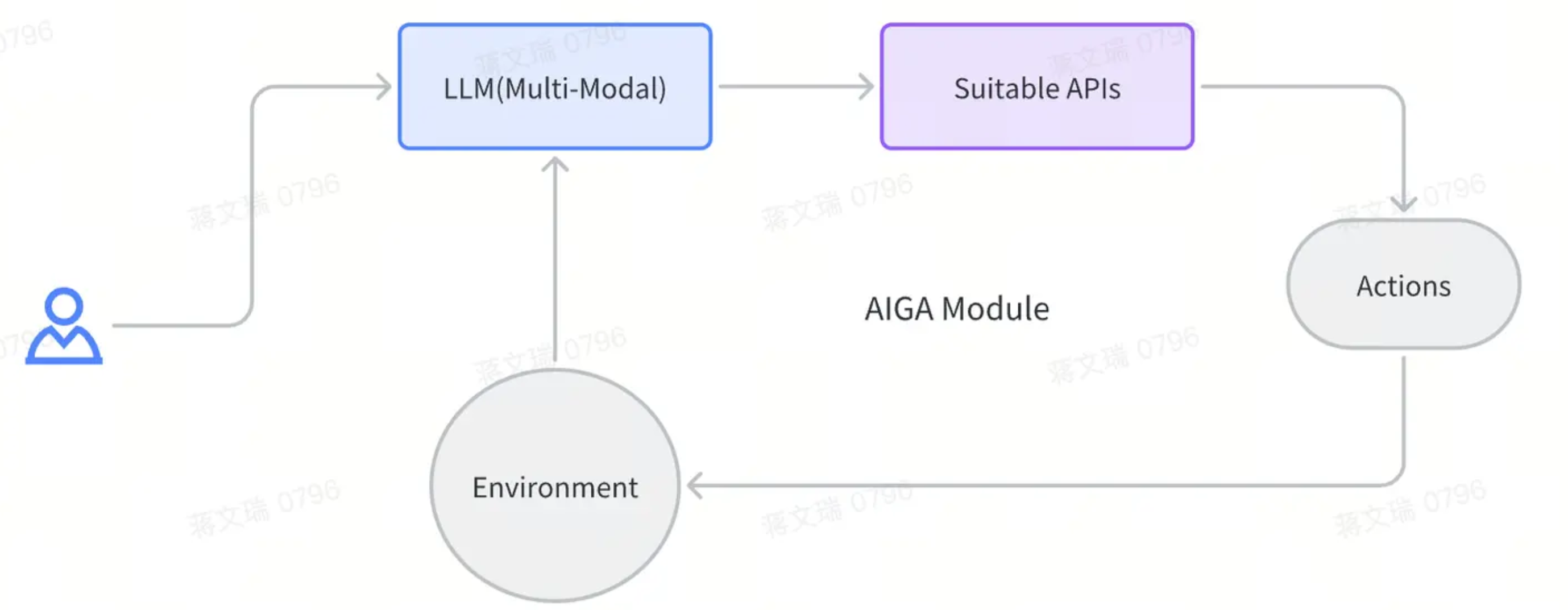
在这项工作中,我们提出了一种不受可训练推理网络限制的a non-local architecture for image and video denoising的非本地架构。
The method
first: computes for each image patch the most similar neighbors in a rectangular spatio-temporal search window and gathers the center pixel of each similar patch forming a feature vector which is assigned to each image location.
This results in an image with n channels, which is fed to a CNN trained to predict the clean image from this high dimensional vector.
首先,在矩形时空搜索窗口中 为每个图像块计算n个最相似的邻居,并收集每个相似块的中心像素,形成分配给每个图像位置的特征向量。
这会产生具有 n 个通道的图像,该图像被馈送到经过训练的 CNN,以从这个高维向量中预测干净的图像。
We trained our network
for gray scale and color video denoising.
我们训练我们的网络进行灰度和彩色视频去噪。实际训练这种架构是通过 GPU 实现的补丁搜索实现的,它允许有效地计算最近的邻居。视频中暂时存在的自相似性可以通过我们的建议实现强大的去噪效果。

所提出方法的架构。第一个模块在相邻帧上执行逐块最近邻搜索。然后,将当前帧和每个像素(最近邻的中心像素)的特征向量 fnl 输入到网络中。网络的前四层使用 32 个特征图执行 1×1 卷积。生成的特征图是具有 15 层的简化 DnCNN [55] 网络的输入。
Proposed method
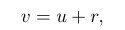
u代表视频,u(x,t)表示帧t中位置x处的值,假设观察的v是一个加入高斯白噪声u的版本。r(x, t) ∼ N (0, σ2).
Non-local features
设 Px,t 是在帧 t 中以像素 x 为中心的补丁。搜索模块计算块 Px,t 与以 (x,t)为中心、大小为 ws*ws*w t的 3D 矩形搜索区域 R 中的块之间的距离,其中 ws 和 wt 是空间和时间大小。这 n 个相似块的位置是 (xi, ti)(根据后面指定的标准排序)。注意 (x1, t1) = (x, t)。
这些位置的像素值被收集为 n 维非局部特征向量
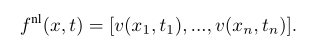
f具有 n 个通道的 3D 张量。这是网络的输入。请注意,特征图像的第一个通道对应于噪声图像 v。
Network
我们的网络可以分为两个阶段: a non-local stage and a local stage:
The non-local stage 由四个 1×1 卷积层和 32 个内核组成。这些层的基本原理是允许网络从输入的原始非局部特征 f nl 中计算像素级特征。
The second stage接收第一阶段计算的特征。它由 14 层和 64 个 3 × 3 卷积核组成,然后是批量归一化和 ReLU 激活。输出层是一个 3×3 的卷积。它的架构类似于 [55] 中介绍的 DnCNN 网络,尽管有 15 层而不是 17 层(如 [56] 中)。对于 DnCNN,网络输出残差图像,必须将其减去噪声图像才能得到去噪图像。训练损失是残差和噪声之间的平均均方误差。对于 RGB 视频,我们使用相同数量的层,但每层的特征数量增加三倍。
Training and dataset
省略
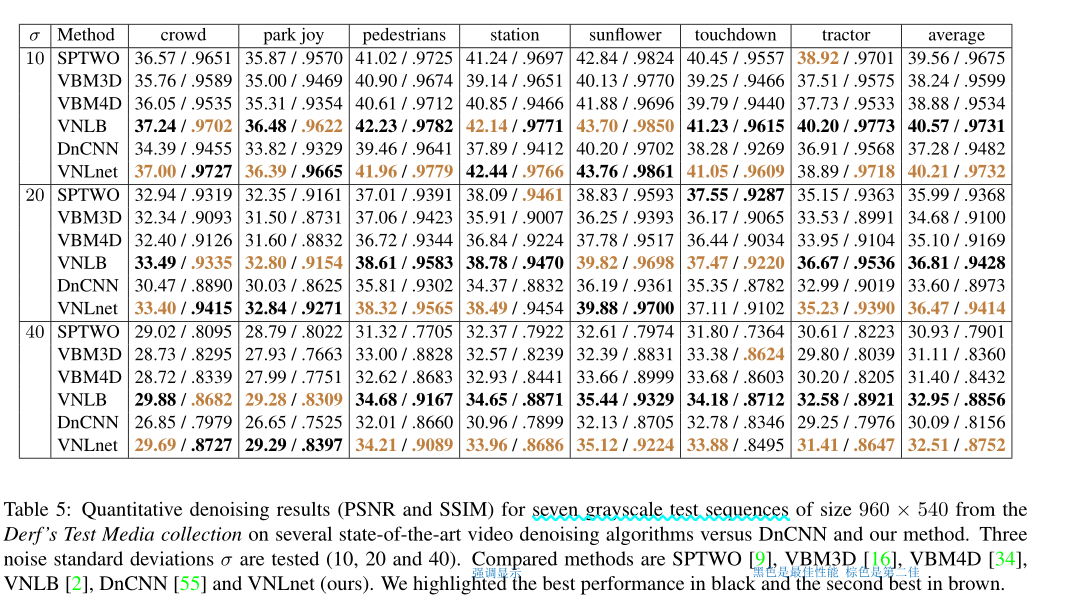
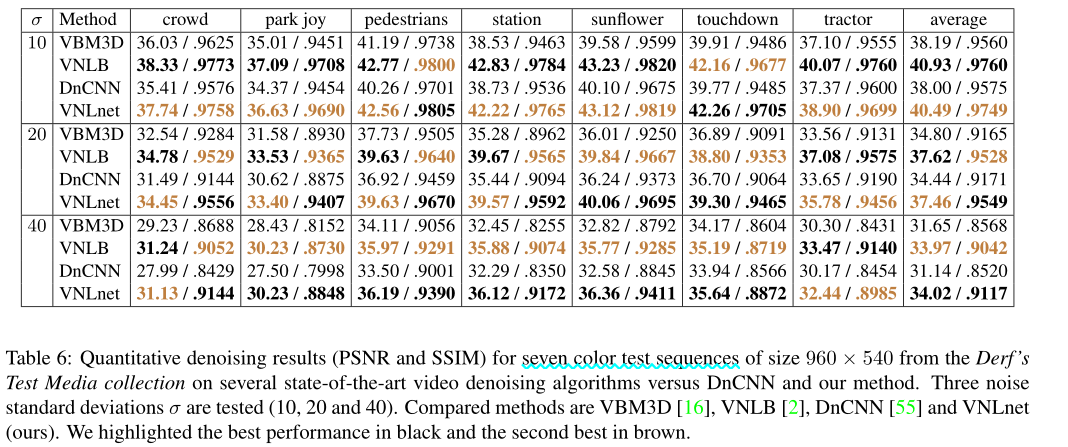
Experimental results
我们将首先展示一些实验来突出所提出方法的相关方面。
然后我们与最先进的进行比较
The untapped potential of non-locality.
非本地未被开发法的潜力
尽管这项工作的重点是视频去噪,但研究提出的非局部 CNN 在图像上的性能仍然很有趣。

图 2 显示了基线 CNN(DnCNN [55] 的 15 层版本,如在我们的网络中)和我们为静态图像去噪训练的方法版本(它通过比较 9 × 9 块收集 9 个邻居)的比较。有和没有非本地信息的结果非常相似,这在表 1 中得到证实。唯一的区别是在非常自相似的部分上可见,例如图 2 中详细显示的百叶窗。

非局部性在改善 CNN 的结果方面具有很大的潜力。 oracle 方法获得的平均 PSNR 为 31.85dB,比基线高 0.6dB。然而,这种改进受到在存在噪声的情况下难以找到准确匹配的阻碍。减少匹配错误的一种方法是使用更大的补丁。但在图像上,较大的补丁具有较少的相似补丁。相反,正如我们将在下面看到的,视频的时间冗余允许使用非常大的补丁。
Parameter tuning参数调优
Non-local search has three main parameters: The patch size,`` the number of retained matches and the number of frames in the search region
三个参数:补丁大小、保留匹配的数量和搜索区域中的帧数。

我们通过增加补丁的大小获得了越来越好的结果。主要原因是匹配精度提高了,因为噪声对补丁距离的影响缩小了

我们可以看到,前者使用大块显然更好地去噪,而后者在运动区域周围保持不受影响。这表明网络能够确定何时提供的非局部信息不准确,并在这种情况下回退到类似于 DnCNN 的结果(单图像去噪),[图6可以查看] 进一步增加补丁大小将导致更多区域被处理为单个图像。结果,我们看到从 31×31 到 41×41 的性能增益相当小。对于如此大的块,只有来自不同帧的相同对象的匹配才可能被视为邻居。因此,我们更进一步,强制匹配来自不同的帧,这略微提高了性能。这显示在图 5 和表 4 中。请注意,由于补丁分布受到影响,网络会被重新训练。事实上,当没有施加限制时,邻居是按增加距离排序的。而在此变体中,邻居按帧索引排序。
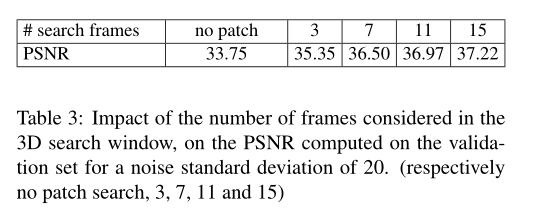


总结:在接下来的实验中,我们将使用 41 × 41 块和 15 帧。非局部搜索的另一个参数是搜索窗口的空间宽度,我们将其设置为 41 像素(测试块的中心像素必须位于该区域内)。我们为 σ 10、20 和 40 的 AGWN 训练了灰度和彩色网络。为了强调 CNN 方法可以适应多种噪声类型这一事实,与传统方法不同,我们还为通过 3 × 3 相关的高斯噪声训练了灰度网络盒核使得最终的标准偏差为 σ = 20,以及 25% 的均匀椒盐噪声(移除的像素被随机均匀噪声替换)。

训练结果
A note on running times:还比较CPU 的运行时间


表 11 的 GPU 运行时指出,在 CPU 上,我们的方法应该比 DnCNN 慢 10 倍。非局部搜索的成本特别高,因为我们在 15 帧上搜索以图像的每个像素为中心的补丁。通过使用其他论文中探索的技巧来减小 3D 窗口的大小,可以显着加快补丁搜索的速度。例如,VBM3D 将搜索集中在围绕在前一帧中找到的最佳匹配的小窗口上的每一帧上。一个相关的加速是使用基于 PatchMatch [6] 的搜索策略。
Implementation details
补丁搜索需要计算图像中每个补丁与搜索区域中的补丁之间的距离。成本很大
为了降低计算成本:一种常见的方法是只在图像的子网格中搜索最近的邻居。例如,BM3D 使用默认参数处理 1/9 的补丁。由于处理后的补丁重叠,去噪补丁的聚合覆盖了整个图像。
我们提出的方法没有任何聚合。我们计算所有图像块的邻居,这是昂贵的。在视频的情况下,使用大块和大搜索区域(时间和空间)获得最佳结果。因此,我们需要一种高效的补丁搜索算法
我们的实现使用了一个优化的 GPU 内核,它并行搜索位置。对于每个补丁,相对于搜索量中所有其他补丁的最佳距离都保存在一个表中。我们将距离的计算分为两个步骤:首先计算跨列的平方和
为了优化算法的速度,我们使用 GPU 共享内存作为内存访问的缓存,从而减少了带宽限制。此外,为了对距离进行排序,有序表存储到 GPU 寄存器中,并且仅在计算结束时写入内存。 L2 距离的计算和有序表的维护具有大约相同数量级的计算成本。有关实施的更多详细信息,请参见附录 A
结论
We described a simple yet effective way of incorporating non-local information into a CNN for video denoising. The
proposed method computes for each image patch the n most similar neighbors on a spatio-temporal window and gathers
the value of the central pixel of each similar patch to form a non-local feature vector which is given to a CNN. Our
method yields a significant gain compared to using the single frame baseline CNN on each video frame.
我们描述了一种将非本地信息合并到 CNN 中进行视频去噪的简单而有效的方法。所提出的方法为每个图像块计算时空窗口上的 n 个最相似的邻居,并收集每个相似块的中心像素的值,以形成一个非局部特征向量,该向量被提供给 CNN。与在每个视频帧上使用单帧基线 CNN 相比,我们的方法产生了显着的收益。
We have seen the importance of having reliable matches: On the validation set, the best performing method used
patches of size 41 × 41 for the patch search. We have alsonoticed that on regions with non-reliable matches (complex
motion), the network reverts to a result similar to single image denoising. Thus we believe future works should fo-
cus on improving this area, by possibly adapting the size of the patch and passing information about the quality of the matches to the network.
我们已经看到了可靠匹配的重要性:在验证集上,性能最佳的方法使用大小为 41 × 41 的补丁进行补丁搜索。我们还注意到,在具有不可靠匹配(复杂运动)的区域上,网络恢复到类似于单图像去噪的结果。因此,我们认为未来的工作应该集中在改善这一领域,可能会调整补丁的大小并将有关匹配质量的信息传递给网络。