前言
前段时间,产品经理在线上验证产品功能的时候,发现某个功能不符合需求预期,后来测试验证发现是服务端的一个接口大概率偶现超时,前端做了兜底处理,所以对线上用户么有太大影响。
问题排查过程
由于服务端的接口偶现超时,并且网关设置了30s超时熔断,所以前端请求就直接报错了,由于前端做了兜底,所以在页面上没有明显的报错提示。从grafana上看接口响应确实耗时较长。
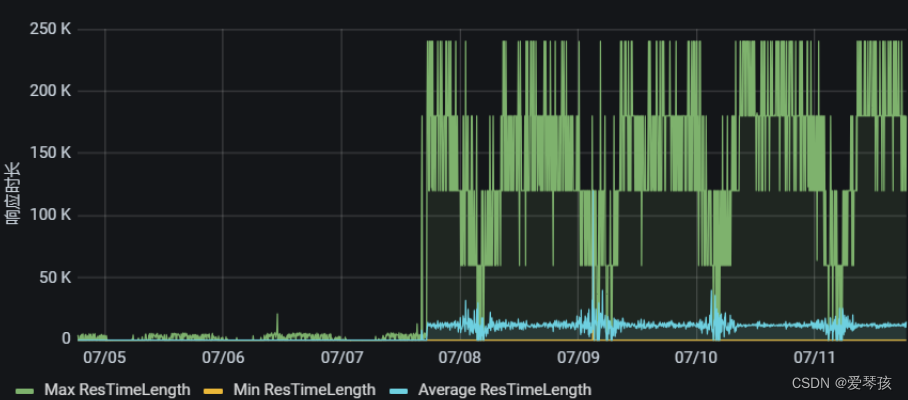
知道是服务端接口响应超时,那问题就好办了,排查去具体耗时原因即可。在kibana上找到一个响应耗时较长的请求,然后根据traceId来看下具体的链路日志。在日志中发现一个比较诡异的地方
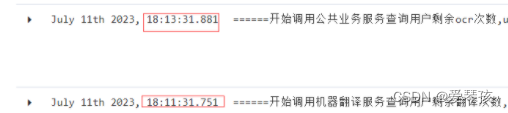
这两个日志位置,是分别调用翻译服务和公共业务服务的入口日志,单纯的两次RPC调用,两次调用之间没有其他的业务逻辑了。看到这里肯定猜想是翻译服务的接口响应超时了。我们来看下翻译对应接口响应耗时。
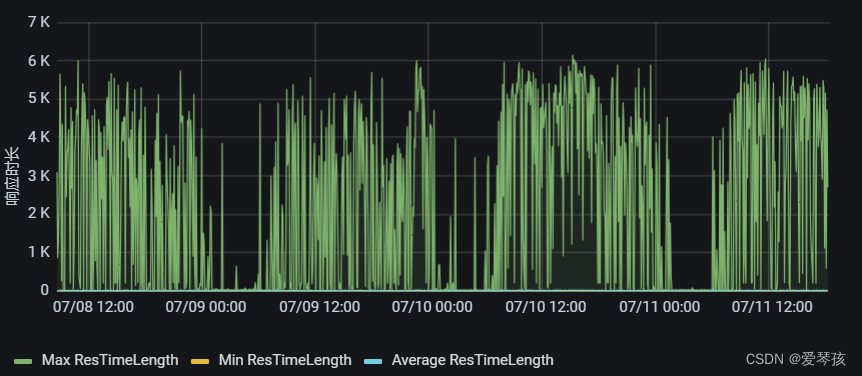
从上面的接口响应来看,接口最大耗时也就在6s左右,不至于会出现上面的2分钟的未响应。所以问题并不是由于底层接口的read timed out。既然不是read timed out那有么有可能是connaction timed out呢。我们一起看下上层适配服务配置的超时时间。
feign.client.config.default.connectTimeout=60000
feign.client.config.default.readTimeout=60000
feign.client.config.default.loggerLevel=FULL#ribbon
ribbon.MaxAutoRetries=0
ribbon.MaxAutoRetriesNextServer=3
ribbon.OkToRetryOnAllOperations=false
ribbon.ServerListRefreshInterval=3000
ribbon.ConnectTimeout=60000
ribbon.ReadTimeout=60000看到上面的ribbon.ConnectTimeout=60000,就验证了我们的猜想了,应该是适配服务和底层的翻译服务建立连接超时了,眼尖的小伙伴可能发现,不对啊,ribbon.ConnectTimeout=60000,连接超时时间是1分钟,但是上面的链路日志中,调用翻译服务应该超时了2分钟才对,这就引出了Ribbon的重试机制了
Ribbon的重试机制
我们看下Ribbon的这两个配置
ribbon.MaxAutoRetries=0
ribbon.MaxAutoRetriesNextServer=3这两个配置用于定义Ribbon在调用服务时的重试行为。
- ribbon.MaxAutoRetries=0: 这个配置定义了在调用服务失败时的最大重试次数。设置为0表示不进行重试,即仅尝试调用一次服务,如果失败则立即返回错误。
- ribbon.MaxAutoRetriesNextServer=3: 这个配置定义了在当前服务实例不可用时,尝试下一个服务实例的最大次数。设置为3表示如果当前服务实例无法访问,Ribbon将尝试最多3次切换到下一个可用的服务实例进行调用。
这就解释了上面的调用翻译服务为啥耗时了2分钟,由于第一次调用建立连接超时了1分钟之后,切换到下一个点进行了重试,但是建立连接依旧超时了1分钟,接着切换到下一个节点,这次调用成功了,所以从日志上看调用耗时了2分钟。由于现网问题,所以当时通知运维把翻译服务所有的点都重启了下,问题解决了,至于为啥翻译服务部分节点为啥建立连接超时,请听下回分解。







)






)

)


