Universal adversarial perturbations----《普遍对抗扰动》
通俗UAP算法步骤理解:对于 x i ∈ X {x_i} \in X xi∈X 的每个采样数据点,比较 k ^ ( x i + v ) \hat k({x_i} + v) k^(xi+v) 与 k ^ ( x i ) \hat k({x_i}) k^(xi) ,如果 k ^ ( x i + v ) = k ^ ( x i ) \hat k({x_i} + v) = \hat k({x_i}) k^(xi+v)=k^(xi) ,则说明 v v v 对 x i {x_i} xi 的扰动不足以让分类器 k ^ ( ⋅ ) \hat k( \cdot ) k^(⋅) 做出错误决定,因此需要找到一个 Δ v i \Delta {v_i} Δvi ,使得 k ^ ( x i + v + Δ v i ) ≠ k ^ ( x i ) \hat k({x_i} + v + \Delta {v_i}) \ne \hat k({x_i}) k^(xi+v+Δvi)=k^(xi) , Δ v i \Delta {v_i} Δvi 就是 x i + v {x_i} + v xi+v 到决策边界的最小扰动,当采样数据集 X v {X_v} Xv 的错误率大于 1 − δ 1 - \delta 1−δ 时,说明此时的 v v v (经过迭代更新)能够使 ( 1 − δ ) % (1 - \delta )\% (1−δ)% 的采样数据分类错误,满足预设的通用扰动阈值,算法终止。
摘要
给定最先进的深度神经网络分类器,我们证明了存在一个通用的(与图像无关的)且非常小的扰动向量,该向量会导致自然图像以高概率被错误分类。我们提出了一种用于计算普遍扰动的系统算法,并表明最先进的深度神经网络非常容易受到这种扰动的影响,尽管人眼几乎无法察觉。我们进一步对这些普遍的扰动进行了实证分析,并特别表明它们在神经网络中具有很好的泛化性。普遍扰动的存在揭示了分类器高维决策边界之间的重要几何相关性。它进一步概述了输入空间中存在单一方向的潜在安全漏洞,对手可能会利用这些方向来破坏大多数自然图像的分类器。
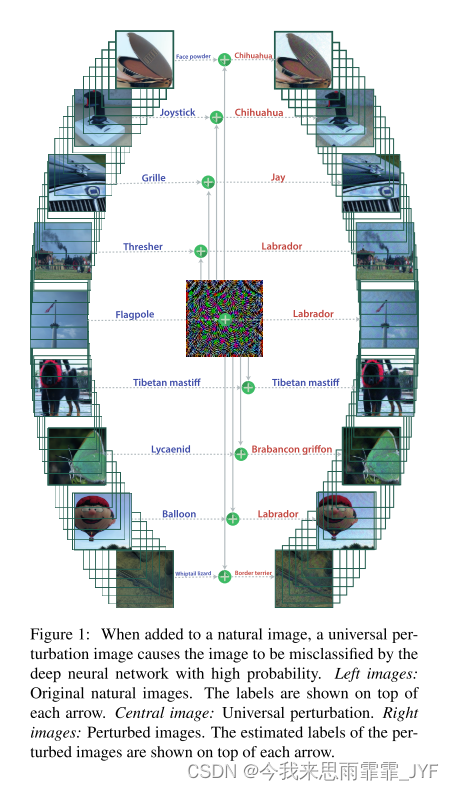
引言
我们能否找到一个小图像扰动来愚弄所有自然图像上最先进的深度神经网络分类器?我们在本文中证明了这种近似不可察觉的普遍扰动向量的存在,这些向量很可能导致自然图像的错误分类。具体来说,通过在自然图像中添加这种近似不可察觉的扰动,深度神经网络估计的标签会以很高的概率发生变化(见图1)。这种扰动被称为普遍的,因为它们与图像无关。当分类器部署在现实世界(并且可能是敌对的)环境中时,这些扰动的存在是有问题的,因为它们可以被对手利用来破坏分类器。事实上,扰动过程仅涉及向所有自然图像添加一个非常小的扰动,并且对手在现实世界环境中可以相对简单地实施,但相对难以检测,因为这种扰动非常小,因此不会显着影响数据分布。普遍扰动的惊人存在进一步揭示了对深度神经网络决策边界拓扑结构的新见解。我们将本文的主要贡献总结如下:
- 我们展示了最先进的深度神经网络普遍存在的与图像无关的扰动。
- 我们提出了一种寻找此类扰动的算法。该算法寻求一组训练点的通用扰动,并通过聚合原子扰动向量来进行,这些向量将连续的数据点发送到分类器的决策边界。
- 我们表明,通用扰动具有显着的泛化特性,因为针对相当小的训练点集计算的扰动能够以高概率欺骗新图像。
- 我们表明,这种扰动不仅在图像中(数据)普遍存在,而且在深度神经网络中(网络架构)也能很好地推广。因此,这种扰动对于数据和网络架构来说都是双重普遍的。
- 我们通过检查决策边界不同部分之间的几何相关性来解释和分析深度神经网络对普遍扰动的高度脆弱性。
图像分类器对结构化和非结构化扰动的鲁棒性最近引起了很多关注[19,16,20,3,4,12,13,14]。尽管深度神经网络架构在具有挑战性的视觉分类基准上表现出色[6,9,21,10],但这些分类器被证明非常容易受到扰动。在[19]中,这种网络被证明对于非常小的且通常难以察觉的附加对抗性扰动是不稳定的。这种精心设计的扰动要么是通过求解优化问题[19,11,1]来估计的,要么是通过一个梯度上升步骤[5]来估计的,并导致扰动欺骗特定的数据点。这些对抗性扰动的一个基本属性是它们对数据点的内在依赖性:扰动是专门为每个数据点独立设计的。 因此,计算新数据点的对抗性扰动需要从头开始解决数据相关的优化问题,该问题使用分类模型的全部知识。这与本文中考虑的通用扰动不同,因为我们寻求在大多数自然图像上欺骗网络的单个扰动向量。然后,扰动新数据点仅涉及向图像添加通用扰动(并且不需要解决优化问题/梯度计算)。最后,我们强调了普遍扰动的概念与[19]中研究的对抗性扰动的泛化不同,在[19]中,MNIST任务计算的扰动在不同模型中具有很好的泛化效果。相反,我们研究了存在于属于数据分布的大多数数据点的通用扰动。
普遍扰动
我们在本节中形式化了普遍扰动的概念,并提出了一种估计此类扰动的方法。令 μ \mu μ 表示 R d {R^d} Rd 中图像的分布, k ^ \hat k k^ 定义一个分类函数,为每个图像 x ∈ R d x \in {R^d} x∈Rd 输出估计标签 k ^ ( x ) \hat k(x) k^(x)。本文的主要关注点是寻找扰动向量 v ∈ R d v \in {R^d} v∈Rd 来愚弄几乎所有从 μ \mu μ 采样的数据点上的分类器 k ^ \hat k k^。也就是说,我们寻找一个向量 v v v 使得:
k ^ ( x + v ) ≠ k ^ ( x ) \hat k(x + v) \ne \hat k(x) k^(x+v)=k^(x) 对于几乎所有的 x ∼ μ x \sim \mu x∼μ
我们创造了这样一个通用的扰动,因为它代表了一种与图像无关的固定扰动,会导致从数据分布 μ \mu μ 中采样的大多数图像发生标签变化。我们在这里关注分布 μ \mu μ 代表自然图像集的情况,因此包含大量的可变性。在这种情况下,我们检查了对大多数图像进行错误分类的小普遍扰动(根据 p ∈ [ 1 , ∞ ) p \in [1,\infty ) p∈[1,∞) 的 l p {l_p} lp 范数)的存在。因此,目标是找到满足以下两个约束的 v v v:
∥ v ∥ p ≤ ξ {\left\| v \right\|_p} \le \xi ∥v∥p≤ξ
P x ∼ μ ( k ^ ( x + v ) ≠ k ^ ( x ) ) ≥ 1 − δ \mathop P\limits_{x \sim \mu } (\hat k(x + v) \ne \hat k(x)) \ge 1 - \delta x∼μP(k^(x+v)=k^(x))≥1−δ
其中,参数 ξ \xi ξ 控制扰动向量 v v v 的大小, δ \delta δ 量化从分布 μ \mu μ 采样的所有图像的所需愚弄率。
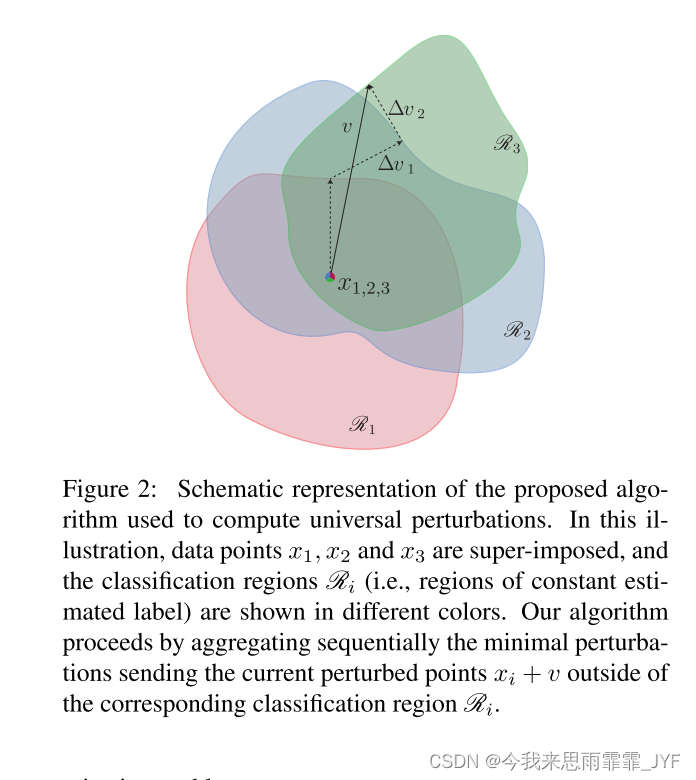
算法:令 X = { x 1 , . . . , x m } X = \{ {x_1},...,{x_m}\} X={x1,...,xm} 是从分布 μ \mu μ 中采样的一组图像。我们提出的算法是寻找一个通用扰动 v v v,使得 ∥ v ∥ p ≤ ξ {\left\| v \right\|_p} \le \xi ∥v∥p≤ξ,同时欺骗 X X X 中的大多数数据点。该算法对 X X X 中的数据点进行迭代,并逐渐构建通用扰动,如图 2 所示。在每次迭代中,计算将当前扰动点 x i + v {x_i} + v xi+v 发送到分类器决策边界的最小扰动 Δ v i \Delta {v_i} Δvi,并将其汇总到当前通用扰动的实例中。更详细地说,假设当前的通用扰动 v v v 不会欺骗数据点 x i x_i xi,我们通过解决以下优化问题来寻求具有最小范数的额外扰动 Δ v i \Delta {v_i} Δvi,从而允许欺骗数据点 x i x_i xi:
Δ v i ← arg min r ∥ r ∥ 2 \Delta {v_i} \leftarrow \mathop {\arg \min }\limits_r {\left\| r \right\|_2} Δvi←rargmin∥r∥2, 其中 k ^ ( x i + v + r ) ≠ k ^ ( x i ) \hat k({x_i} + v + r) \ne \hat k({x_i}) k^(xi+v+r)=k^(xi) (1)
为了确保满足约束 ∥ v ∥ p ≤ ξ {\left\| v \right\|_p} \le \xi ∥v∥p≤ξ ,更新后的通用扰动进一步投影到半径为 ξ \xi ξ 且以 0 为中心的 l p {l_p} lp 球上。也就是说,设 P p , ξ {P_{p,\xi }} Pp,ξ 为投影算子,定义如下:
P p , ξ ( v ) = arg min v ′ ∥ v − v ′ ∥ 2 {P_{p,\xi }}(v) = \mathop {\arg \min }\limits_{v'} {\left\| {v - v'} \right\|_2} Pp,ξ(v)=v′argmin∥v−v′∥2, ∥ v ′ ∥ p ≤ ξ {\left\| v' \right\|_p} \le \xi ∥v′∥p≤ξ
然后,我们的更新规则由 v ← P p , ξ ( v + Δ v i ) v \leftarrow {P_{p,\xi }}(v + \Delta {v_i}) v←Pp,ξ(v+Δvi) 给出。对数据集 X X X 执行多次迭代以提高通用扰动的质量。当扰动数据集 X v : = { x 1 + v , . . . , x m + v } {X_v}: = \{ {x_1} + v,...,{x_m} + v\} Xv:={x1+v,...,xm+v} 上的经验“愚弄率”超过 1 − δ 1 - \delta 1−δ 时算法终止。也就是说,我们停止算法迭代当:
E r r ( X v ) : = 1 m ∑ i = 1 m 1 k ^ ( x i + v ) ≠ k ^ ( x i ) ≥ 1 − δ Err({X_v}): = \frac{1}{m}\sum\limits_{i = 1}^m {{1_{\hat k({x_i} + v) \ne \hat k({x_i})}}} \ge 1 - \delta Err(Xv):=m1i=1∑m1k^(xi+v)=k^(xi)≥1−δ (详细算法见算法1)

有趣的是,实际上,计算对整个分布 μ \mu μ 有效的通用扰动,不需要很多 X X X 中的数据点 m m m。特别是,我们可以将 m m m 设置为远小于训练点的数量(参见第 3 节)。
所提出的算法在每次迭代中最多求解 m m m 个式(1)中的优化问题。虽然当 k ^ \hat k k^ 是标准分类器(例如深度神经网络)时,这个优化问题不是凸的,但已经设计了几种有效的近似方法来解决这个问题 [19,11,7]。为了提高效率,我们在下面使用[11]中的方法。还应该注意的是,算法 1 的目标不是找到能够欺骗从分布中采样的大多数数据点的最小通用扰动,而是找到一个具有足够小的范数的扰动。特别地,对集合 X X X 进行不同的随机变换,自然会产生满足所需约束的不同的普遍扰动集合 v v v。因此,提出的算法可以用来为深度神经网络生成多个普遍扰动(见下一节的可视化示例)。
深度网络的通用扰动
现在,我们使用算法 1 分析最先进的深度神经网络分类器对普遍扰动的鲁棒性。
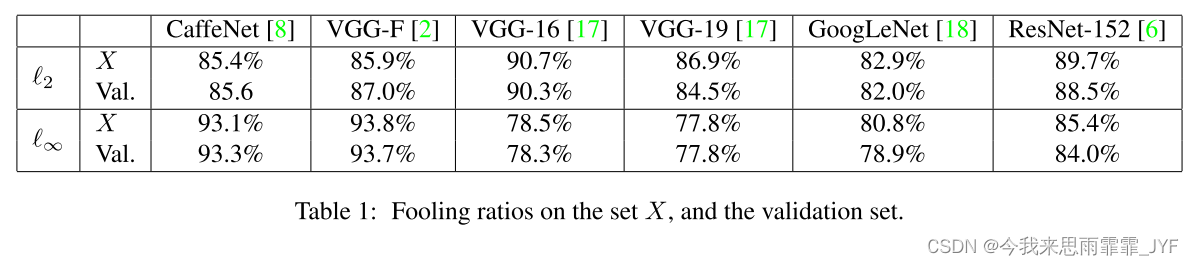
在第一个实验中,我们评估了 ILSVRC 2012 [15] 验证集(50,000 张图像)上最近不同深度神经网络的估计普遍扰动,并报告了愚弄率,即当受到我们的扰动时改变标签的图像比例。报告 p = 2 p = 2 p=2 和 p = ∞ p = \infty p=∞ 时的结果,其中我们分别设置 ξ = 2000 \xi = 2000 ξ=2000 和 ξ = 10 \xi = 10 ξ=10。选择这些数值,是为了得到一个扰动,其范数明显小于图像范数,这样当将扰动添加到自然图像中时,近似不可察觉。结果如表1所示。结果列在表1中。每个结果都在集合 X X X 上报告,该集合用于计算扰动,以及在验证集上报告,该集合用于验证扰动(该验证集在计算通用扰动的过程中未使用)。观察到,对于所有网络,通用扰动在验证集上实现了非常高的愚弄率。具体来说,为 CaffeNet 和 VGG-F 计算的通用扰动愚弄了超过 90% 的验证集(对于 p = ∞ p = \infty p=∞)。换句话说,对于验证集中的任何自然图像,仅仅添加我们的通用扰动就可以让分类器十次的预测被愚弄九次以上。此外,这个结果并不特定于此类架构,因为我们还可以找到导致 VGG、GoogLeNet 和 ResNet 分类器在自然图像上被愚弄的普遍扰动,概率接近 80%。这些结果令人惊讶,因为它们表明存在单一的通用扰动向量,这些向量会导致自然图像以高概率被错误分类,尽管人类几乎无法察觉。为了验证后一种说法,我们在图 3 中展示了扰动图像的视觉示例,其中使用了 GoogLeNet 架构。这些图像要么取自 ILSVRC 2012 验证集,要么使用手机摄像头拍摄。观察到,在大多数情况下,普遍扰动是近乎不可察觉的,并且这种强大的图像不可知扰动能够对最先进的分类器以高概率错误分类任何图像。我们参考辅助材料的原始(未扰动)图像以及其真实标签。我们还参考了补充材料中的视频,了解智能手机上的真实示例。我们在图 4 中可视化了不同网络对应的普遍扰动。应该注意的是,这种通用扰动不是唯一的,因为可以为同一网络生成许多不同的通用扰动(全部满足两个所需的约束)。在图 5 中,我们可视化了通过在 X X X 中使用不同的随机采样获得的五种不同的通用扰动。观察到这种普遍的扰动是不同的,尽管它们表现出相似的模式。此外,通过计算两对扰动图像之间的归一化内积也证实了这一点,因为归一化内积不超过0.1,这表明可以找到多种通用扰动。



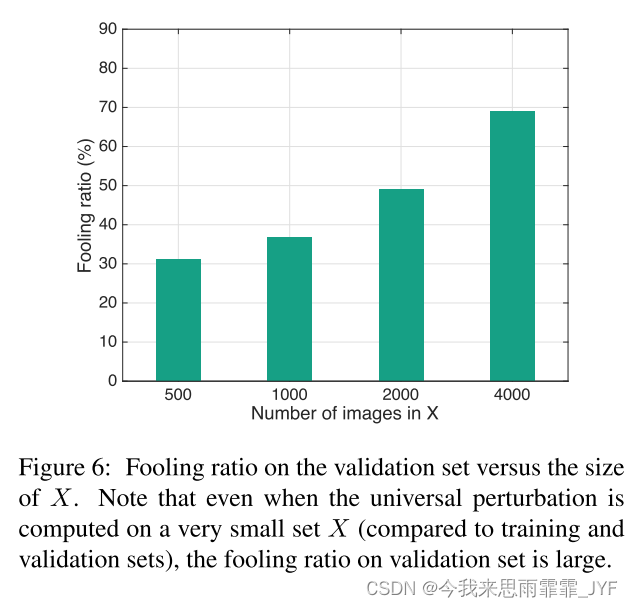
虽然上面的普遍摄动是针对一个集合 X X X 计算的,该集合 X X X 包含来自训练集的10,000幅图像(即,每个类平均10幅图像),我们现在检查 X X X 的大小对通用扰动质量的影响。我们在图 6 中展示了 GoogLeNet 在不同大小的 X 上生成的通用扰动在验证集上获得的愚弄率。请注意,例如,如果 X X X 集合仅包含 500 张图像,我们可以欺骗验证集上超过 30% 的图像。与 ImageNet 中的类数量(1000)相比,这个结果非常重要,因为它表明我们可以欺骗大量未见过的图像。因此,使用算法 1 计算的通用扰动对于未见过的数据点具有显着的泛化能力,并且可以在非常小的训练图像集上进行计算。
跨模型通用性
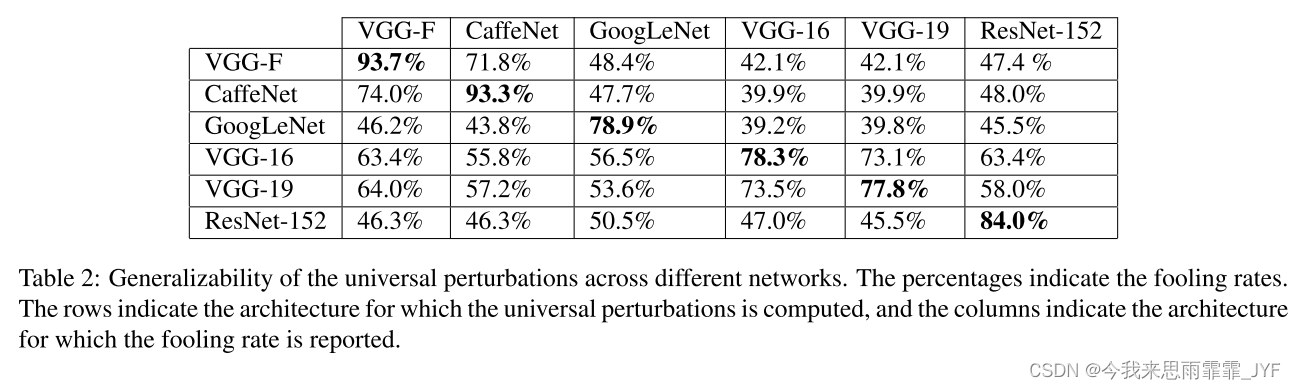
虽然计算出的扰动在看不见的数据点上是普遍存在的,但我们现在检查它们的跨模型普遍性。也就是说,我们研究针对特定架构(例如 VGG-19)计算的通用扰动在多大程度上对于另一种架构(例如 GoogLeNet)也有效。表 2 显示了一个矩阵,总结了六种不同架构中此类扰动的普遍性。对于每种架构,我们计算通用扰动并报告所有其他架构的愚弄率;我们在表 2 的行中报告了这些。观察到,对于某些架构,通用扰动在其他架构中很好地推广。例如,针对 VGG-19 网络计算的通用扰动对于所有其他测试架构的愚弄率均高于 53%。这一结果表明,我们的普遍扰动在某种程度上是双重普遍的,因为它们可以很好地泛化到数据点和非常不同的架构。应该指出的是,在[19]中,先前的研究表明,对抗性扰动在某种程度上可以很好地推广到 MNIST 问题上的不同神经网络。然而,我们的结果有所不同,因为我们展示了 ImageNet 数据集上不同架构的通用扰动的普遍性。该结果表明,此类扰动具有实际意义,因为它们可以很好地泛化到数据点和架构上。特别是,为了欺骗未知神经网络上的新图像,简单添加在 VGG-19 架构上计算的通用扰动可能会错误分类数据点。
普遍扰动影响的可视化
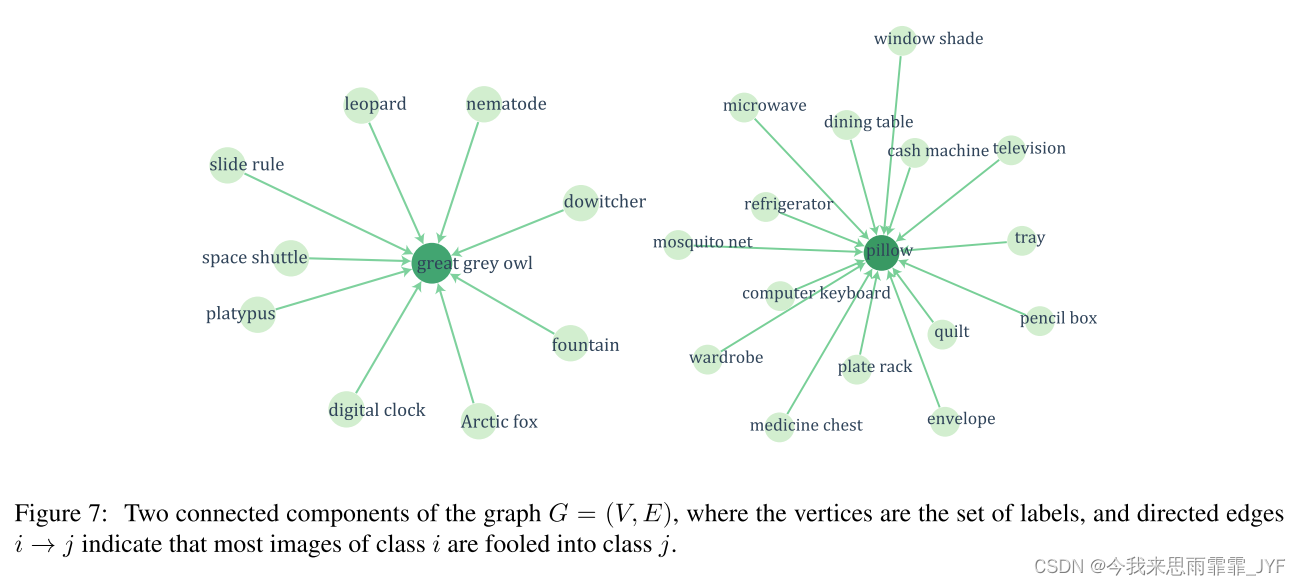
为了深入了解普遍扰动对自然图像的影响,我们现在可视化 ImageNet 验证集上标签的分布。具体来说,我们构建一个有向图 G = ( V , E ) G = (V,E) G=(V,E),其顶点表示标签,有向边 e = ( i → j ) e = (i \to j) e=(i→j) 表示在应用通用扰动时,大多数 i i i 类图像被愚弄到标签 j j j 。因此,边 i → j i \to j i→j 的存在表明, i i i 类图像的首选愚弄标签是 j j j。我们为 GoogLeNet 构建了这个图,并在补充材料中可视化完整的图。该图的可视化显示了一种非常奇特的拓扑结构。特别是,该图是不相交组件的并集,其中一个组件中的所有边大多连接到一个目标标签。有关两个连接组件的图示,请参见图 7。这种可视化清楚地显示了几个主要标签的存在,并且普遍的扰动大多使自然图像用这些标签进行分类。我们假设这些主导标签占据图像空间中的大部分区域,因此代表了欺骗大多数自然图像的候选标签。请注意,这些主要标签是由算法1自动找到的,而不是在计算扰动时强加的先验。
用普遍扰动进行微调(对抗训练)
我们现在检查使用扰动图像微调网络的效果。我们使用 VGG-F 架构,并根据修改后的训练集对网络进行微调,其中将通用扰动添加到一小部分(干净的)训练样本中:对于每个训练点,以0.5的概率添加通用扰动,并以0.5的概率保留原始样本。为了考虑通用扰动的多样性,我们预先计算了 10 个不同通用扰动,并将扰动随机添加到训练样本中。通过对修改后的训练集执行 5 个额外的训练周期来对网络进行微调。为了评估微调对网络鲁棒性的影响,我们计算微调网络的新通用扰动(使用算法 1,其中 p = ∞ p = \infty p=∞ 和 ξ = 10 \xi = 10 ξ=10),并报告网络的愚弄率。经过 5 个额外的 epoch 后,验证集上的愚弄率为 76.2%,相对于原始网络(93.7%,见表 1)有所改善。尽管取得了这一进步,但经过微调的网络在很大程度上仍然容易受到普遍的小扰动的影响。因此,我们重复上述过程(即,为微调网络计算 10 个通用扰动,根据修改后的训练集对新网络进行 5 个额外 epoch 的微调),我们获得了新的愚弄比 80.0 %。一般来说,重复这一过程固定次数并没有比一步微调后获得的 76.2% 的愚弄率产生任何改善。因此,虽然微调网络可以稍微提高鲁棒性,但我们观察到这种简单的解决方案并不能完全免受小的普遍扰动的影响。
解释模型对普遍扰动的脆弱性
本节的目标是分析和解释深度神经网络分类器对普遍扰动的高度脆弱性。为了理解普遍扰动的独特特征,我们首先将这种扰动与其他类型的扰动进行比较,即 i) 随机扰动,ii) 为随机选取的样本计算的对抗性扰动(分别使用 [11] 和 [5] 中的 DF 和 FGS 方法计算),iii) X X X 上的对抗性扰动之和,以及 iv) 平均值图像(或 ImageNet 偏差)。对于每个扰动,我们在图 8 中描绘了一个相变图,显示了验证集上相对于扰动的 l 2 {l_2} l2 范数的愚弄率。通过用乘法因子相应地缩放每个扰动以获得目标范数,可以实现不同的扰动范数。请注意,通用扰动是在 ξ = 2000 \xi = 2000 ξ=2000 时计算的,并且也进行了相应的缩放。
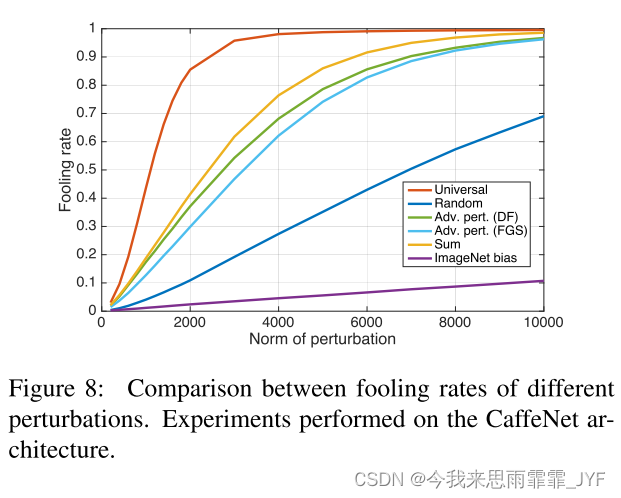
观察到,即使扰动被限制为小范数,所提出的通用扰动也会很快达到非常高的愚弄率。例如,当 l 2 {l_2} l2 范数限制为 ξ = 2000 \xi = 2000 ξ=2000 时,使用算法 1 计算的通用扰动达到了 85% 的愚弄率,而其他扰动在可比范数下实现的比率要小得多。特别是,从半径为 2000 的球体中均匀采样的随机向量只能欺骗 10% 的验证集。通用扰动和随机扰动之间的巨大差异表明通用扰动利用了分类器决策边界不同部分之间的一些几何相关性。事实上,如果不同数据点邻域中决策边界的方向完全不相关(并且与到决策边界的距离无关),则最佳通用扰动的范数将与随机扰动的范数相当。请注意,后一个量很好理解(参见[4]),因为欺骗特定数据点所需的随机扰动范数精确地表现为 Θ ( d ∥ r ∥ 2 ) \Theta (\sqrt d {\left\| r \right\|_2}) Θ(d∥r∥2),其中 d d d 是输入的维度空间, ∥ r ∥ 2 {\left\| r \right\|_2} ∥r∥2 是数据点和决策边界之间的距离(或等效地,最小对抗性扰动的范数)。对于所考虑的 ImageNet 分类任务,对于大多数数据点而言,该量等于 d ∥ r ∥ 2 ≈ 2 × 1 0 4 \sqrt d {\left\| r \right\|_2} \approx 2 \times {10^4} d∥r∥2≈2×104,这至少比通用扰动 ( ξ = 2000 \xi = 2000 ξ=2000) 大一个数量级。因此,随机扰动和普遍扰动之间的这种巨大差异表明我们现在探索的决策边界的几何结构存在冗余。
对于验证集中的每个图像 x x x,我们计算对抗性扰动向量 r ( x ) = a r g min r ∥ r ∥ 2 r(x) = \mathop {arg\min }\nolimits_r {\left\| r \right\|_2} r(x)=argminr∥r∥2, k ^ ( x + r ) ≠ k ^ ( x ) \hat k(x + r) \ne \hat k(x) k^(x+r)=k^(x)。很容易看出 r ( x ) r(x) r(x) 垂直于分类器的决策边界(在 x + r ( x ) x + r(x) x+r(x) 处)。因此,向量 r ( x ) r(x) r(x) 捕获数据点 x x x 周围区域中决策边界的局部几何形状。为了量化分类器决策边界不同区域之间的相关性,我们定义矩阵:
N = [ r ( x 1 ) ∥ r ( x 1 ) ∥ 2 . . . r ( x n ) ∥ r ( x n ) ∥ 2 ] N = \left[ {\frac{{r({x_1})}}{{{{\left\| {r({x_1})} \right\|}_2}}}...\frac{{r({x_n})}}{{{{\left\| {r({x_n})} \right\|}_2}}}} \right] N=[∥r(x1)∥2r(x1)...∥r(xn)∥2r(xn)]
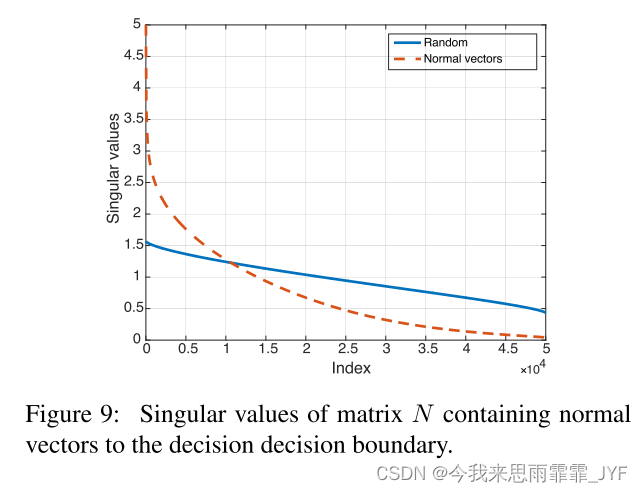
为验证集中 n n n 个数据点附近决策边界的法向向量。对于二元线性分类器,决策边界是一个超平面,并且 N N N 的秩为 1,因为所有法向量都是共线的。为了更普遍地捕获复杂分类器决策边界中的相关性,我们计算矩阵 N N N 的奇异值。针对 CaffeNet 架构计算的矩阵 N N N 的奇异值如图 9 所示。我们进一步在同一图中显示了当从单位球体中均匀随机采样 N N N 列时获得的奇异值。观察到,虽然后面的奇异值衰减缓慢,但 N N N 的奇异值衰减很快,这证实了深层网络决策边界中存在较大的相关性和冗余。更准确地说,这表明存在低维 d ′ d' d′( d ′ ≪ d d' \ll d d′≪d)的子空间 S S S,其中包含自然图像周围区域中决策边界的大多数法向量。我们假设,欺骗大多数自然图像的普遍扰动的存在部分是由于这种低维子空间的存在,它捕获了决策边界不同区域之间的相关性。事实上,这个子空间“收集”不同区域决策边界的法线,因此属于这个子空间的扰动可能会欺骗数据点。为了验证这个假设,我们选择一个属于由前 100 个奇异向量跨越的子空间 S S S 的范数 ξ = 2000 \xi = 2000 ξ=2000 的随机向量,并在不同的图像集(即一组尚未被处理过的图像)上计算其愚弄比。这样的扰动可以欺骗近 38% 的图像,从而表明这个精心寻找的子空间 S S S 中的随机方向显着优于随机扰动(我们记得这样的扰动只能欺骗 10% 的数据)。图 10 说明了捕获决策边界中相关性的子空间 S S S。还应该指出的是,这种低维子空间的存在解释了图 6 中获得的通用扰动的令人惊讶的泛化特性,其中人们可以用很少的图像构建相对通用的通用扰动。
与上述实验不同的是,该算法没有在该子空间中选择随机向量,而是选择特定方向以最大化整体愚弄率。这解释了 S S S 中随机向量策略与算法1所获得的愚弄率之间的差距。

结论
我们展示了小的普遍扰动的存在,这些扰动可以欺骗自然图像上最先进的分类器。我们提出了一种迭代算法来生成通用扰动,并强调了此类扰动的几个属性。特别是,我们表明普遍扰动在不同的分类模型中可以很好地泛化,从而产生双重普遍扰动(与图像无关、与网络无关)。我们通过决策边界不同区域之间的相关性进一步解释了这种扰动的存在。这提供了对深度神经网络决策边界几何形状的见解,并有助于更好地理解此类系统。决策边界不同部分之间的几何相关性的理论分析将是未来研究的主题。





)


)









)
