文章目录
- 整体概况
- 数据增强与前处理
- 自适应Anchor的计算
- Lettorbox
- 架构
- SiLU激活函数
- YOLOv5改进点
- SSPF 模块
- 正负样本匹配
- 损失函数
整体概况

YOLOv5 是一个基于 Anchor 的单阶段目标检测,其主要分为以下 5 个阶段:
1、输入端:Mosaic 数据增强、自适应Anchor计算、自适应图像缩放;
2、Backbone:提取出高中低层的特征,使用了 CSP 结构、SPPF、SiLU 等操作;
3、Neck:使用 FPN+PAN 结构,将各层次的特征进行融合,并提取出大中小的特征图;
4、Head:进行最终检测部分,在特征图上应用 Anchor Box,并生成带有类别概率、类别
得分以及目标框的最终输出向量;
5、损失函数:计算预测结果与 Ground Truth 之间的 Loss。
数据增强与前处理
自适应Anchor的计算
自适应 Anchor 计算
在 YOLOv3、YOLOv4 中,训练不同的数据集时,计算初始 Anchor 的值是通过单独的程序运行的。但 YOLOv5 中将此功能嵌入到代码中,每次训练时会自适应的计算不同训练集中的最佳 Anchor 值。
自适应计算 Anchor 的流程如下:
1、载入数据集,得到数据集中所有数据的 w、h;
2、将每张图像中 w、h 的最大值等比例缩放到指定大小,较小边也相应缩放;
3、将 bboxes 从相对坐标改成绝对坐标(乘以缩放后的 w、h);
4、筛选 bboxes,保留 w、h 都大于等于 2 像素的 bboxes;
5、使用 k-means 聚类得到 n 个 Anchors;
6、使用遗传算法随机对 Anchors 的 w、h 进行变异,如果变异后效果变得更好就将变异后的结果赋值给 Anchors,如果变异后效果变差就跳过。
Lettorbox
在常用的目标检测算法中,不同的图像长宽都不相同,因此常用的方式是将原始图像统一缩放到一个标准尺寸,再送入检测网络中。
前期 YOLO算法中常用 416×416、608×608 等尺寸,比如对 800×600 的图像进行缩放和填充。如图所示,YOLOv5 作者认为,在项目实际应用时,很多图像的长宽比不同,因此均直接进行缩放填充后,两端的灰边大小会不同,而如果填充的比较多,则存在信息的冗余,也可能会影响推理速度。
在 YOLOv5 中作者对 Letterbox 函数中进行了修改,对原始图像自适应的添加最少的灰边。


架构
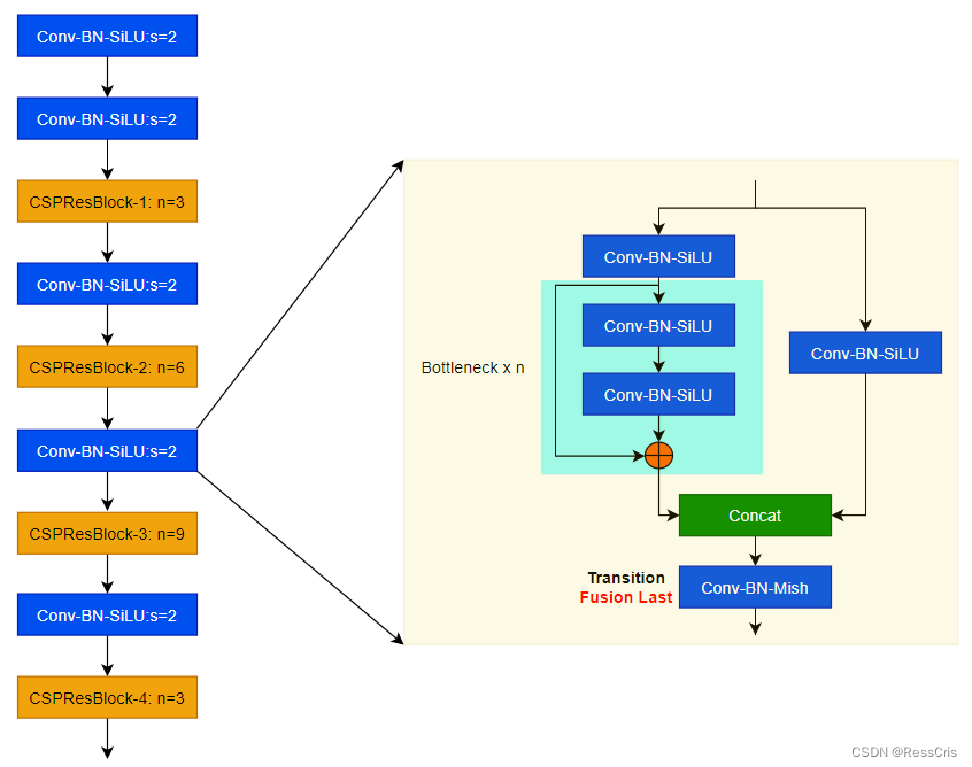
YOLOv5的Backbone和Neck模块和YOLOv4中大致一样,都采用CSPDarkNet和FPN+PAN的结构,但是网络中其他部分进行了调整,其中YOLOv5使用的激活函数是SiLU(YOLOv4为Mish激活函数),同时YOLOv5在CSP Block中没有使用Transition First卷积。
SiLU激活函数

Swish激活函数具备无上界有下届、平滑、非单调的特性,Swish在深层模型上效果优于ReLU,表达式如下:

β是个常数或者可训练的参数,当β=1时,也称作SiLU激活函数。
YOLOv5改进点
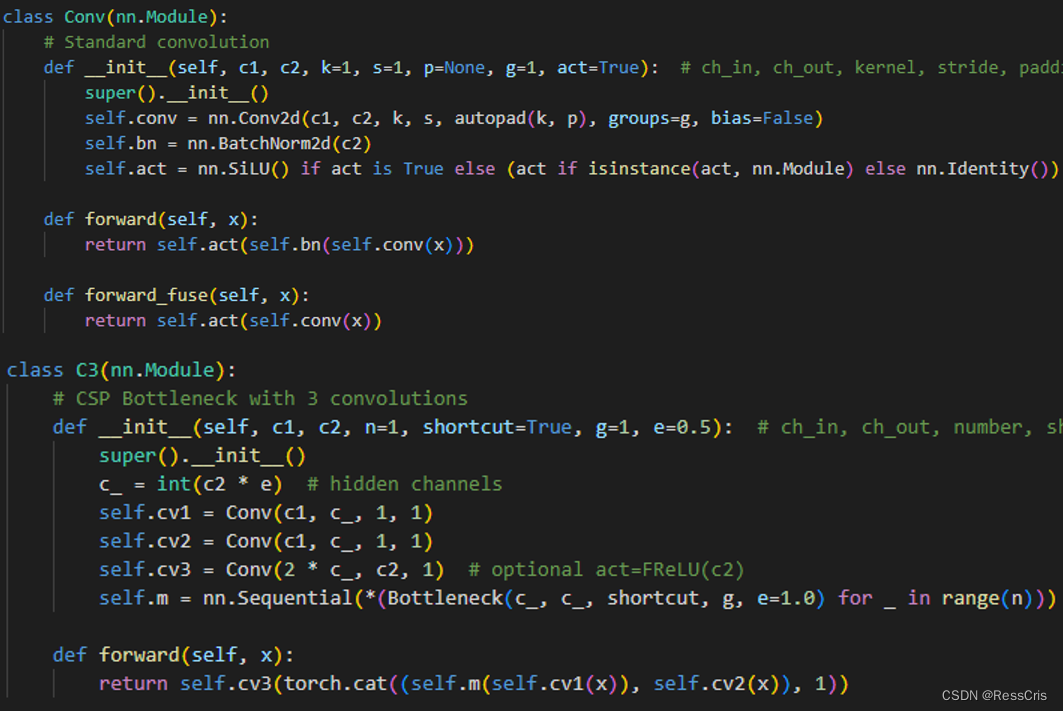
由于YOLOv5没有论文,这里便根据官方的源码绘制一下CSPBlock的结构图,其实对应的便是YOLOv5官方库的C3 Block:
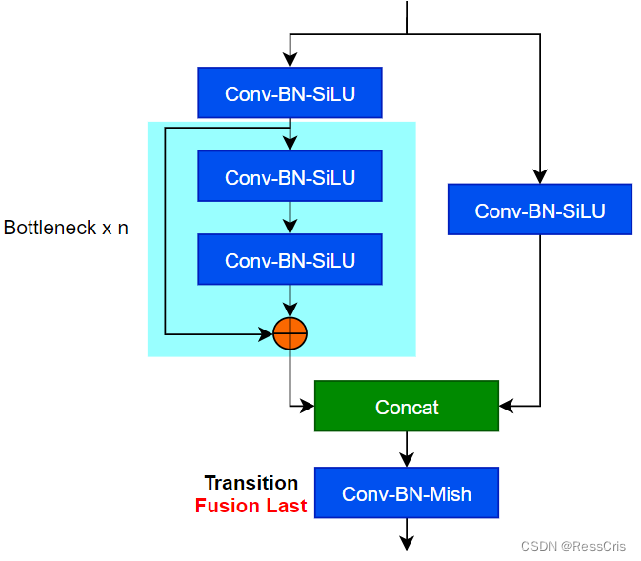

SSPF 模块
SSPF模块将经过CBS的x与一次池化后的y1、两次池化后的y2和3次池化后的y3进行拼接,然后再CBS进一步提取特征。
仔细观察不难发现,虽然SSPF对特征图进行了多次池化,但是特征图尺寸并未发生变化,通道数更不会变化,所以后续的4个输出能够在channel维度进行融合。
这一模块的主要作用是对高层特征进行提取并融合,在融合的过程中多次运用最大池化,尽可能多的去提取高层次的语义特征。

正负样本匹配

首先,将GT与当前特征图的 3 个 Anchors 作比较,如果GT的宽与Anchor 宽的比例、GT的高与 Anchor 高的比例都处于 1/4 到4区间内,那么当前GT就能与当前特征图匹配。
然后,将当前特征图的正样本分配给对应的 Grid;如图所示在 YOLOv5 中会将一个 Grid 点分为4个象限,针对第一步中匹配的GT,会计算该GT(图中蓝点)处于4个象限中的哪一个,并将邻近的两个特征点也作为正样本。
如图所示,左边所示的GT偏向于右下象限,会将GT所在 Grid 的右、下特征点也作为正样本。而图中右边所示的GT偏向于左上象限,会将GT所在 Grid 的左、上特征点作为正样本。
相比较 YOLOv3 和 YOLOv4 匹配正样本的方式,YOLOv5的这种匹配方式能够分配更多的正样本,有助于训练加速收敛,以及正负样本的平衡。而且由于每个特征图都会将所有的 GT与当前特征图的 Anchor 计算能否分配正样本,也就说明一个GT可能会在多个特征图中都分配到正样本。
损失函数






】线性结构和非线性结构)







)
)




