文章目录
- 为什么要有进程间通信
- pipe函数
- 共享管道原理
- 管道特点
- 管道的四种情况
- 管道的应用场景(进程池)
- ProcessPool.cc
- Task.hpp
为什么要有进程间通信
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
pipe函数
通过pipe函数实现两个进程间的通信
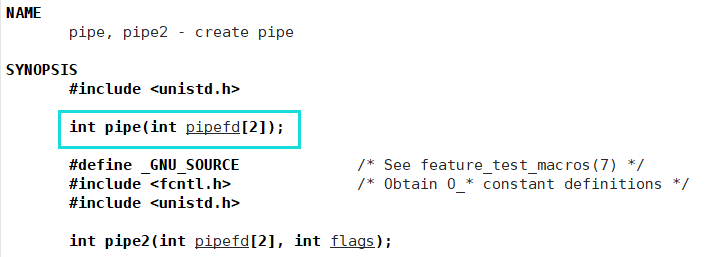
pipe()函数作用:生成两个文件描述符,分别为读端和写端
参数:
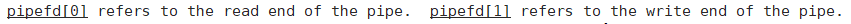
输出型参数pipefd[2],返回值pipefd[0]为读端,pipefd[1]为写端
返回值:
成功返回0,失败返回-1,并且设置错误码error
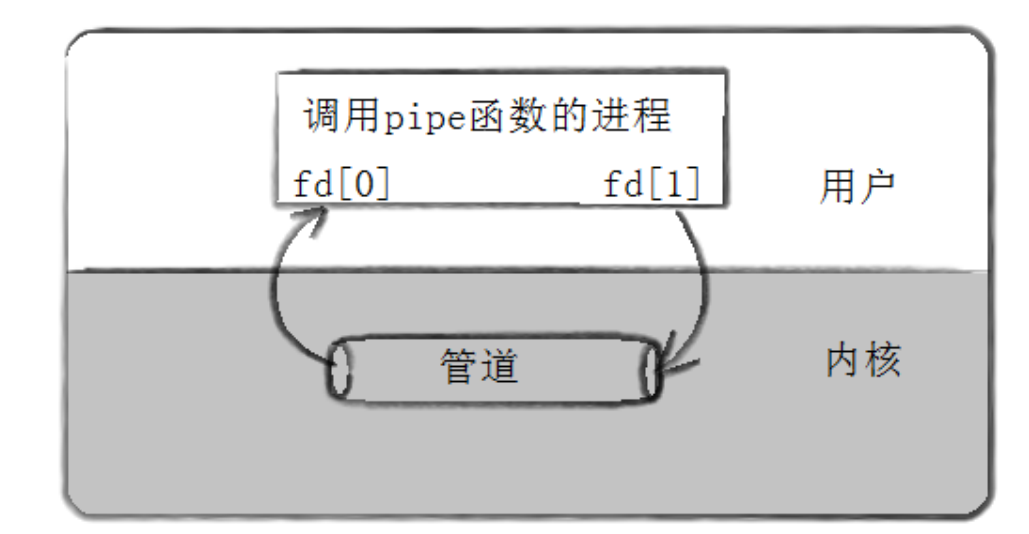
共享管道原理
通过fork函数实现父子之间的管道共享,同一进程fork出的多个进程之间都可以进行管道共享,因此只要是亲戚就可以。
管道共享更确切的说应该是缓冲区共享,我们先来理解一下fork函数,一个进程fork出了子进程,两个进程之间的代码是共享的,数据是独有的,当其中一个进程的数据发生改变时,就会发生写时拷贝。那么文件缓冲区呢?
父子之间的文件缓冲区也是共享的,因此父子之间就是借助这一点进行通信的。
我们以3号文件描述符为读端,4号文件描述符为写端为例,父进程向3号文件描述符写,子进程将数据写入到4号文件描述符。而4号文件描述符读到的就是父进程向3号文件描述符写的数据,这是怎么实现的呢?
1.父子进程是同步的
2.父子之间缓冲区是共享的。
因此当父亲向缓冲区写的时候,子进程就直接从缓冲区内读
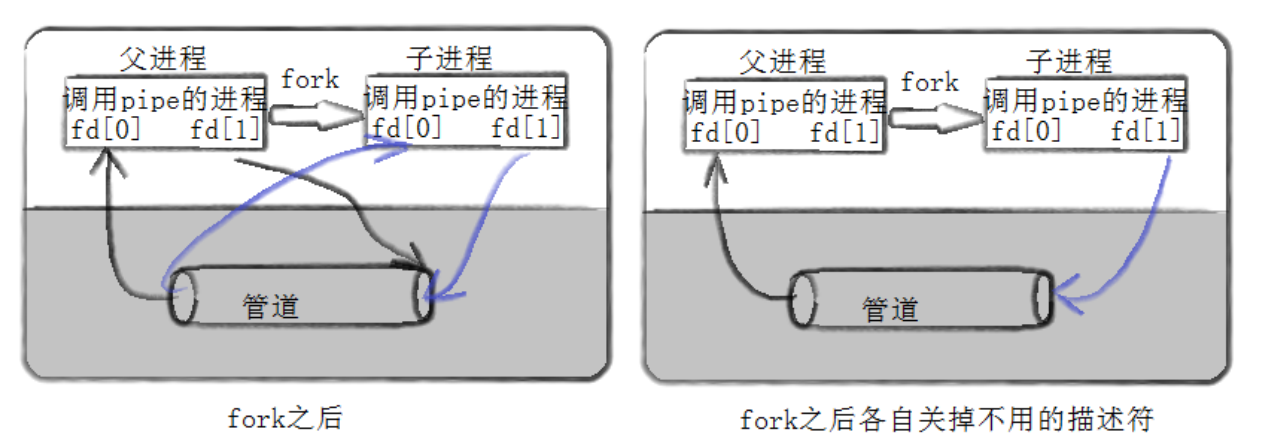
你可能会有疑问,操作系统为什么要搞出管道,要是上面那样的话,和父进程直接向一个文件写,子进程从这个文件里读有什么区别?
管道通信是加载在内存上的,管道本身是一块缓冲区,这种方式更快,因为对于文件而言,它是在磁盘上加载的,如果单纯的对一个文件进行读写操作,肯定是要慢一些的
为什么说这种管道通信只能应用于亲戚之间呢?
因为只有亲戚之间,也就是同一个进程fork出的进程之间才会进行缓冲区共享
#include <iostream>
#include <unistd.h>
#include <error.h>
#include <stdio.h>
#include <cstring>
#include <sys/wait.h>#define N 2
#define NUM 1024using namespace std;void Writer(int wfd)
{string s = "i am a child abcdefg";char buf[NUM];buf[0] = 0;snprintf(buf, sizeof(buf), "%s", s.c_str());//把s.c_str()以字符串形式写入到buf里write(wfd, buf, sizeof(buf));//write(wfd, buf, sizeof(s.c_str()));// cout << "sizeof(s.c_str()):" << sizeof(s.c_str()) << endl;//s.c_str()返回值为char类型的指针// cout << "strlen(buf):" << strlen(buf) << endl;// cout << "strlen(s.c_str()):" << strlen(s.c_str()) << endl;
}void Reader(int rfd)
{char buf[NUM];ssize_t n = read(rfd, buf, sizeof(buf));//sizeof != strlenbuf[n] = 0;//0 == '\0' cout << buf << endl;//cout << n << endl;//printf("%s\n", buf);
}int main()
{int pipefd[N] = {0};//pipefd[2]int n = pipe(pipefd);//给pipe()函数传递一个数组,返回的数组下标0位置是读的文件描述符,下标1位置为写的文件描述符//cout << pipefd[0] << " " << pipefd[1] << endl;pid_t id = fork();if(id < 0){perror("fork error");return 1;}if(id == 0)//child --- 我们让子进程写,父进程读{close(pipefd[0]);//关闭子进程的读文件描述符Writer(pipefd[1]);close(pipefd[1]);//可关可不关,因为进程结束,它会自动关闭exit(0);}if(id > 0)//father----我么让父进程读,子进程写{close(pipefd[1]);//关闭父进程的写文件描述符Reader(pipefd[0]); }pid_t rid = waitpid(id, nullptr, 0);//return id -------- ridclose(pipefd[0]);//可关可不关,因为进程结束,它会自动关闭return 0;
}
管道特点
1.只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
2.管道提供流式服务
3.一般而言,进程退出,管道释放,所以管道的生命周期随进程
4.一般而言,内核会对管道操作进行同步与互斥管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
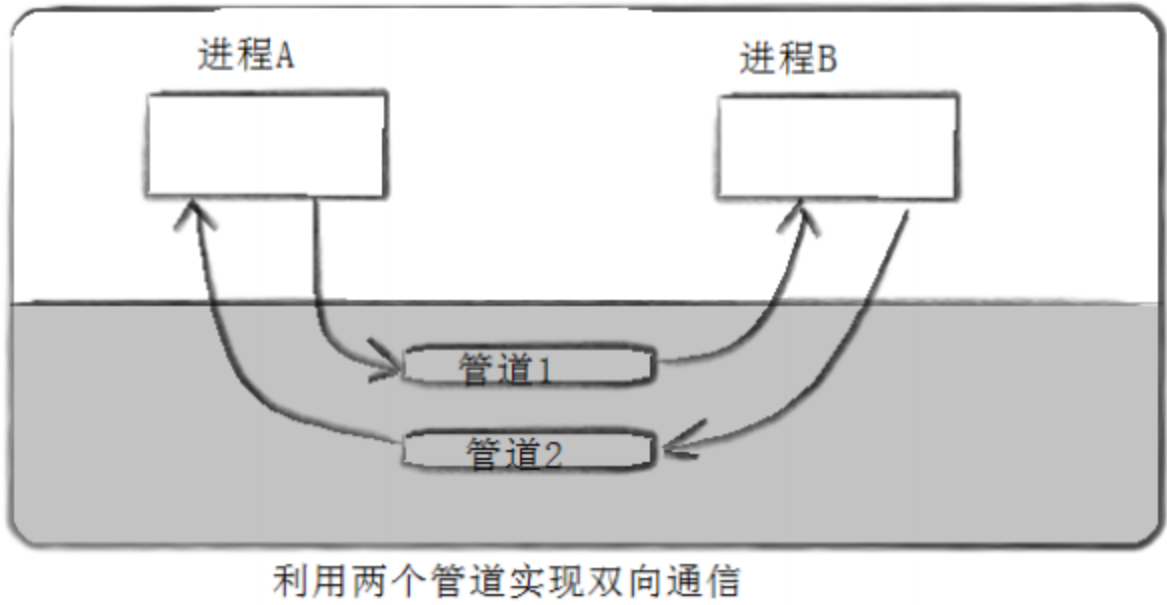
管道的四种情况
1.读写端正常,管道如果为空,读端就要阻塞
2.读写端正常,管道如果被写满,写端就要阻塞
3.读端正常读,写端关闭,读端就会读到0,表明读到了文件pipe的结尾,不会被阻塞
4.写端正常写,读端关闭了。操作系统就要杀掉正在写入的进程。如何杀掉?通过信号杀掉,因为操作系统是不会做这种抵消,浪费等类似的工作,如果做了就是操作系统的bug
管道的应用场景(进程池)
我们知道当一个进程要执行一个事情时,一般它会创建一个子进程,并把这件事交给该进程让它去完成,现在我们有若干个任务要去让这个进程去完成,因此该进程就要去创建多个子进程,让他们分别去完成这些事,但是像这种每一次都要创建子进程的过程是很浪费时间的,操作系统是不会允许这种影响效率的事情发生的,那么我们要怎么提高效率呢?
进程池,就是让为该进程提前创建好若干个子进程,当有多个任务来的时候,就让这个父进程给子进程去派发不同的任务。我们以父进程为老板,子进程为打工人的场景来模拟,具体实现如下:
ProcessPool.cc
#include <unistd.h>
#include <string>
#include <iostream>
#include <vector>
#include <sys/wait.h>
#include <ctime>
#include "Task.hpp"using namespace std;#define processnum 10
#define N 2
#define NUM 1024
vector<task_t> tasks;//声明Task.hpp中的变量//先描述
class channel//管道
{
public:channel(int cmdfd, pid_t slaverid, const string& processname):_cmdfd(cmdfd),_slaverid(slaverid),_processname(processname){}public:int _cmdfd;//发送任务的文件描述符pid_t _slaverid;//该子进程的pidstring _processname;//子进程的名字
};void slaver()
{// char buf[NUM];// read(0, buf, sizeof(buf));int cmdnum = 0;//几号任务read(0, &cmdnum, sizeof(int));//cout << "读到了:" << cmdnum << endl;if(cmdnum > 0 && cmdnum <= tasks.size()){//cout << "cmdnum:" << cmdnum << endl;tasks[cmdnum - 1]();//为什么要加括号?//cout << "读到了:" << cmdnum << endl;}}void Menu()
{cout << "*******************************" << endl;cout << "********1.开机 2.打怪兽******" << endl;cout << "********3.回血 4.关机********" << endl;cout << "*******************************" << endl;cout << "请输入要执行的任务" << endl;
}void InitChannels(vector<channel>* channels)
{for(int i = 0; i < processnum; i++){int pipefd[N] = {0};pipe(pipefd);//cout << "pipefd[0]:" << pipefd[0] << " " << "pipefd[1]:" << pipefd[1] << endl;pid_t pid = fork();if(pid == 0){close(pipefd[1]);dup2(pipefd[0], 0);slaver();//slaver(pipefd[0]);//close(pipefd[0]);//子进程读的文件描述符可以不用关exit(0);}//fatherclose(pipefd[0]);//write(pipefd[1], "abcd", sizeof("abcd"));//Writer();string name = "process:" + to_string(i);channels->push_back(channel(pipefd[1], getpid(), name));//close(pipefd[1]);//waitpid(getpid(), nullptr, 0);}
}void Print(vector<channel> channels)
{int i = 0;for(auto& e : channels){cout << e._cmdfd << " " << e._processname << " " << e._slaverid << endl;//cout << "xxxxxxxxxxxxxxxxxxx" << i << "xxxxxxxxxxxxxxxxxxxxx" << endl;i++;}
}void ctrlSlaver(vector<channel> channels)
{while(1){//1.选择任务Menu();int select = 0; cin >> select;//2.选择进程srand(time(nullptr));int processpos = rand() % channels.size();//进程vector中对应的下标位置//3.发送任务write(channels[processpos]._cmdfd, &select, sizeof(int));//cout << channels[processpos]._cmdfd << endl;sleep(1);}
}void QuitProcess(const std::vector<channel> &channels)
{for(const auto &c : channels) close(c._cmdfd);// sleep(5);for(const auto &c : channels) waitpid(c._slaverid, nullptr, 0);// sleep(5);
}int main()
{LoadTask(&tasks);vector<channel> channels;//1.初始化channelsInitChannels(&channels);//Print(channels);//2.控制子进程ctrlSlaver(channels);QuitProcess(channels);return 0;
}
Task.hpp
#pragma once#include <iostream>
#include <vector>using namespace std;typedef void (*task_t)();//task_t先和*结合,所以task_t是一个指向参数为空,返回值为void的函数指针void task1()
{cout << "开机" << endl;
}void task2()
{cout << "打怪兽" << endl;
}void task3()
{cout << "回血" << endl;
}void task4()
{cout << "关机" << endl;
}void LoadTask(vector<task_t> *tasks)
{tasks->push_back(task1);tasks->push_back(task2);tasks->push_back(task3);tasks->push_back(task4);
}








。find_in_set(`id`, ‘1,2,3‘) 函数,)










