文章目录
- 一、 实时调度类分析
- 1.1 实时调度实体sched_rt_entity数据结构
- 1.2 实时调度类rt_sched_class数据结构
- 1.3 实时调度类功能函数
- 二、SMP和NUMA
- 2.1 SMP(多对称处理器结构,UMA)
- 2.2 NUMA(非一致内存访问结构)
- 2.3 CPU域初始化

一、 实时调度类分析
1.1 实时调度实体sched_rt_entity数据结构
表示实时调度实体,包含整个实时调度数据信息。具体内核源码如下:
// 表示实时调度实体
struct sched_rt_entity {struct list_head run_list; // 用于加入优先级队列当中unsigned long timeout; // 设置时间超时unsigned long watchdog_stamp; // 记录jiffies值unsigned int time_slice; // 记录时间片unsigned short on_rq;unsigned short on_list;struct sched_rt_entity *back; // 临时用于从上往下连接RT调度实体
#ifdef CONFIG_RT_GROUP_SCHEDstruct sched_rt_entity *parent; // 指向父RT调度实体/* rq on which this entity is (to be) queued: */// rt_rq:实时类struct rt_rq *rt_rq; // RT调度实体所属实时运行队列,被调度/* rq "owned" by this entity/group: */struct rt_rq *my_q; // RT调度实体拥有的实时调度队列,用于管理子任务或子组任务
#endif
} __randomize_layout;
1.2 实时调度类rt_sched_class数据结构
数据结构内核源码如下:
const struct sched_class rt_sched_class = {.next = &fair_sched_class,.enqueue_task = enqueue_task_rt, // 将task存放到就绪队列或者尾部.dequeue_task = dequeue_task_rt, // 将task从就绪队列末尾删除.yield_task = yield_task_rt, // 主动放弃执行.check_preempt_curr = check_preempt_curr_rt,.pick_next_task = pick_next_task_rt, // 核心调度器,从就绪队列中选择一个执行.put_prev_task = put_prev_task_rt, // 当任务将要被调度出时执行 .set_next_task = set_next_task_rt,#ifdef CONFIG_SMP.balance = balance_rt,.select_task_rq = select_task_rq_rt,.set_cpus_allowed = set_cpus_allowed_common,.rq_online = rq_online_rt,.rq_offline = rq_offline_rt,.task_woken = task_woken_rt,.switched_from = switched_from_rt,
#endif.task_tick = task_tick_rt,.get_rr_interval = get_rr_interval_rt,.prio_changed = prio_changed_rt,.switched_to = switched_to_rt,.update_curr = update_curr_rt,#ifdef CONFIG_UCLAMP_TASK.uclamp_enabled = 1,
#endif
};
1.3 实时调度类功能函数
- 插入进程:enqueue_task_rt(…) -> ,源码如下:
/** Adding/removing a task to/from a priority array:* 更新调度信息,将调度实体插入到相应优先级队列末尾*/
static void
enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{struct sched_rt_entity *rt_se = &p->rt;if (flags & ENQUEUE_WAKEUP)rt_se->timeout = 0;enqueue_rt_entity(rt_se, flags);if (!task_current(rq, p) && p->nr_cpus_allowed > 1)enqueue_pushable_task(rq, p);
}
- 选择进程:pick_next_rt_entity(…),实时调度会选择最高优先级的实时进程来运行,源码如下:
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq,struct rt_rq *rt_rq)
{struct rt_prio_array *array = &rt_rq->active;struct sched_rt_entity *next = NULL;struct list_head *queue;int idx;// 首先找到一个可用实体idx = sched_find_first_bit(array->bitmap);BUG_ON(idx >= MAX_RT_PRIO);// 从链表组中找对对应链表queue = array->queue + idx;next = list_entry(queue->next, struct sched_rt_entity, run_list);return next; // 返回找到的运行实体
}
- 删除进程:dequeue_task_rt(…),从优先级队列中删除实时进程,并更新调度信息,然后把这个进程添加到队尾。源码如下:
// 删除进程
static void dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{struct sched_rt_entity *rt_se = &p->rt;update_curr_rt(rq); // 更新调度数据信息等等dequeue_rt_entity(rt_se, flags); // 将rt_se从运行队列中删除,然后添加到队列尾部dequeue_pushable_task(rq, p); // 从hash表中进行删除
}
二、SMP和NUMA
2.1 SMP(多对称处理器结构,UMA)
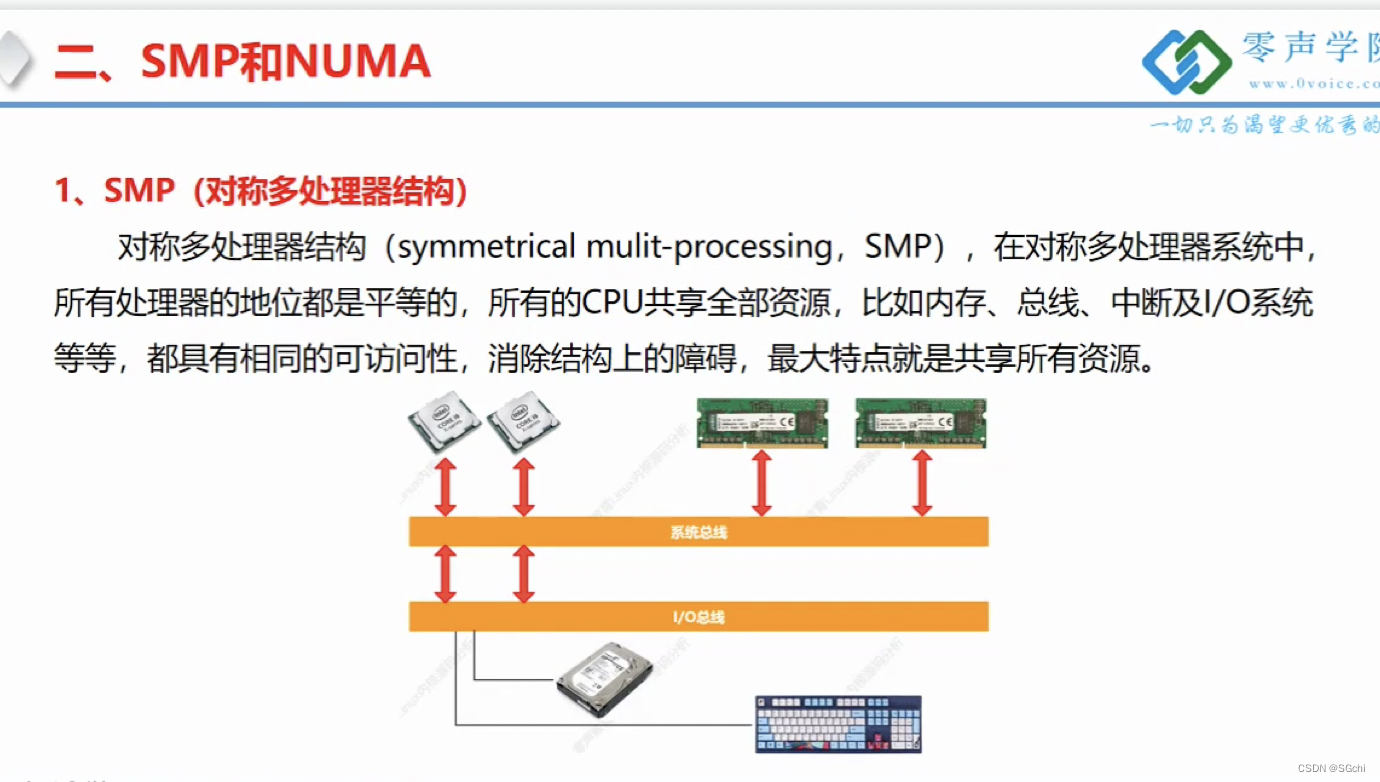
实践证明SMP服务器CPU利用率最高是2-4个CPU

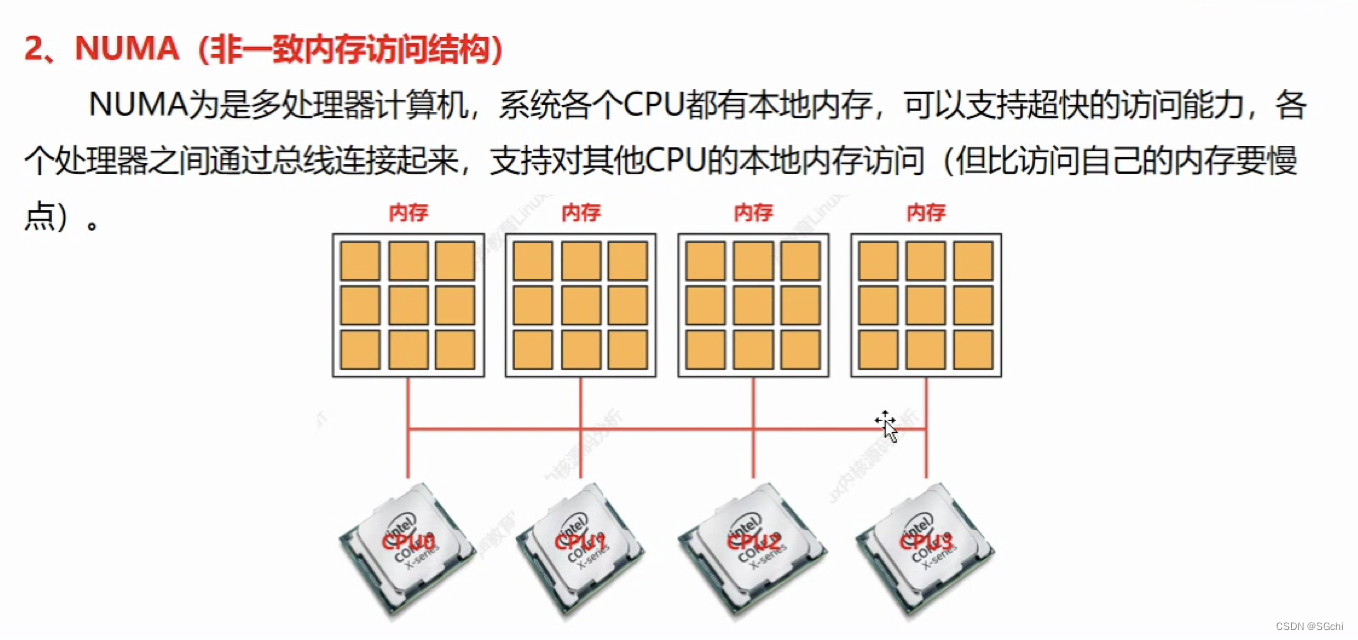
2.2 NUMA(非一致内存访问结构)
2.3 CPU域初始化

extern struct cpumask __cpu_possible_mask;
extern struct cpumask __cpu_online_mask;
extern struct cpumask __cpu_present_mask;
extern struct cpumask __cpu_active_mask;
// 表示有多少可以执行的CPU核心
#define cpu_possible_mask ((const struct cpumask *)&__cpu_possible_mask)
// 表示有多少正处于运行状态的CPU核心
#define cpu_online_mask ((const struct cpumask *)&__cpu_online_mask)
// 表示有多少个具备online条件的CPU核心(不一定都处于online状态,有的CPU核心可能被热插拔)
#define cpu_present_mask ((const struct cpumask *)&__cpu_present_mask)
// 表示系统中有多少个活跃的CPU核心
#define cpu_active_mask ((const struct cpumask *)&__cpu_active_mask)










)



, ‘%Y%v‘))




