=========================================================================
个人主页点击直达:小白不是程序媛
Linux专栏:Linux系统化学习
=========================================================================
目录
前言:
父子进程
父子进程的引入
查看父子进程
查询进程的动态目录
更改进程的工作目录
fork创建进程
fork的引入
fork的使用
fork的原理
fork如何实现的?
为什么fork之前的代码不执行?
为什么要有两个返回值?
前言:
上篇文章我们谈到了进程,运行在内存的程序、被执行的指令都可以是一个进程;并且对Linux的进程有一定的认识,知道如何使用指令查看进程和第一个系统调用。进程还有很多的奥秘需要我们探索,让我们开始今天的学习吧!
父子进程
父子进程的引入
还是上篇文章的代码和指令,每个进程都PID,在属性列表前面的PPID为父进程的ID。

我们对自己写的可执行程序进行多次的运行和终止,会发现每次的进程ID都会变,而父进程ID始终不变。
 经过查询我们可以知道这个父进程就是我们的命令行解释器(bash)。
经过查询我们可以知道这个父进程就是我们的命令行解释器(bash)。

总结:
- 启动进程本质就是创建进程,一般是通过父进程创建的(父子关系)
- 我们命令行启动的进程都是bash的子进程
查看父子进程
新的进程创建时操作系统会给每个进程创建一个task_struct(PCB),里面存放着关于这个进程的各种信息、属性等;其中就包括PID和PPID是操作系统内部的数据,操作系统那片文章我们提到用户是无法拿到操作系统内部的数据的要通过系统调用才可以,Linux也给我们提供了相应的函数接口供我们使用。
- 获取子进程ID:getpid()
- 获取父进程ID:getppid()
通过man指令可以查询到这两个函数的使用方法。

1 #include<stdio.h>2 #include<unistd.h>3 int main()4 5 {6 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid()); 7 return 0;8 }
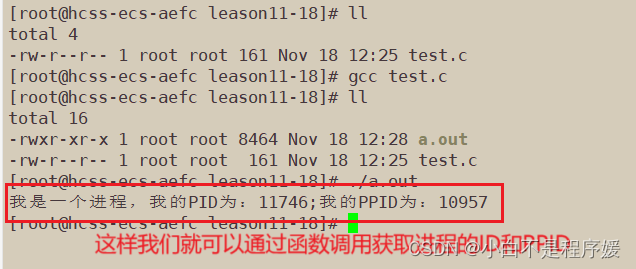
通过编写代码,函数调用获取我们的ID和PPID。
查询进程的动态目录
Linux操作系统下有一个有一个动态的目录结构,存放着所有进程;可以通过每个进程的PID查询到这个目录
- 指令: proc/PID
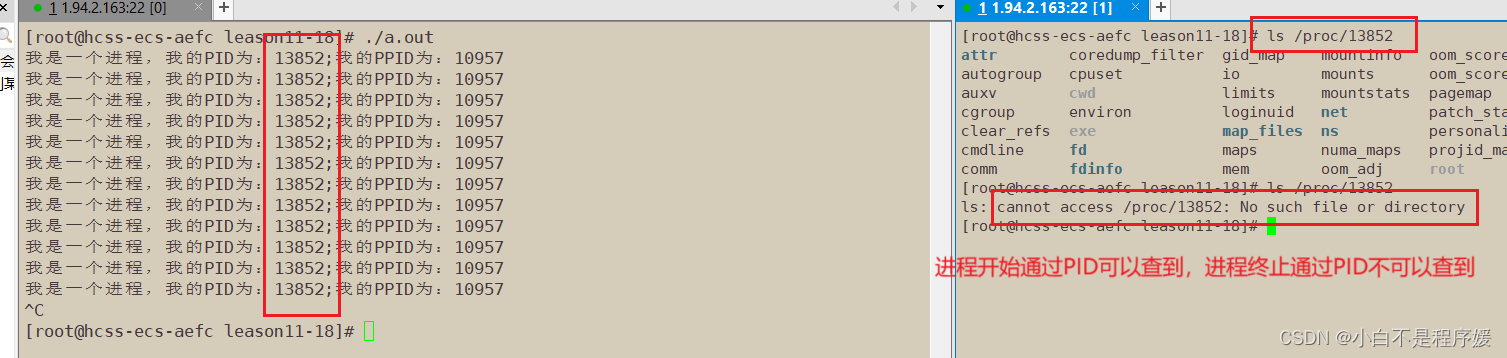
我们将整个进程的完整目录调出来
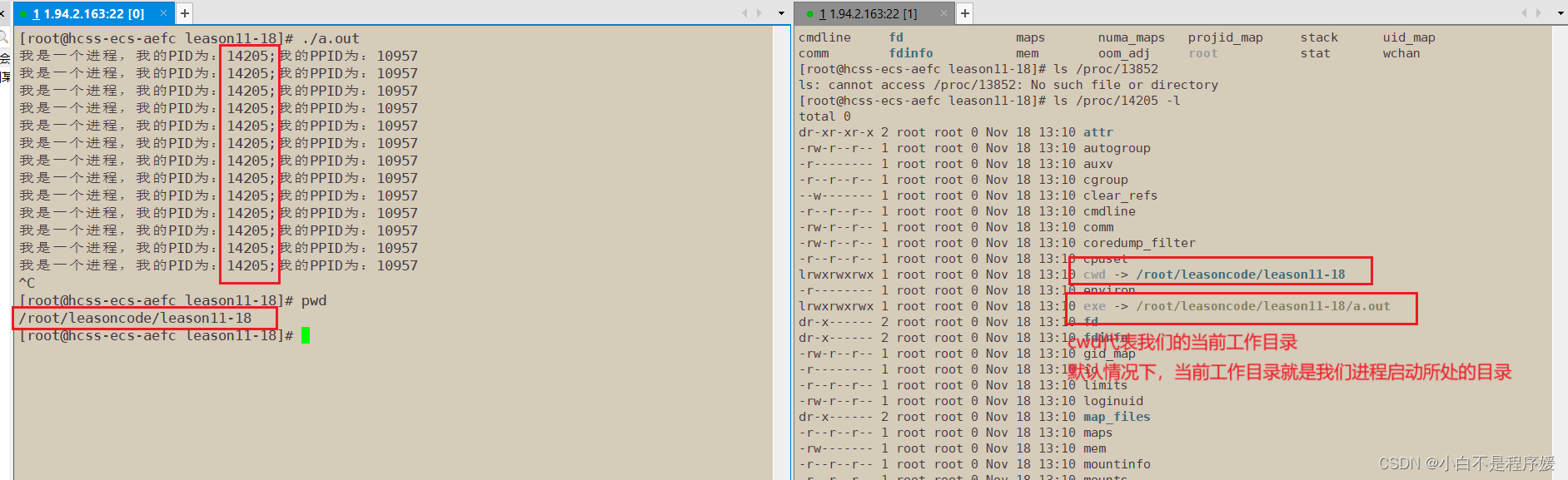
更改进程的工作目录
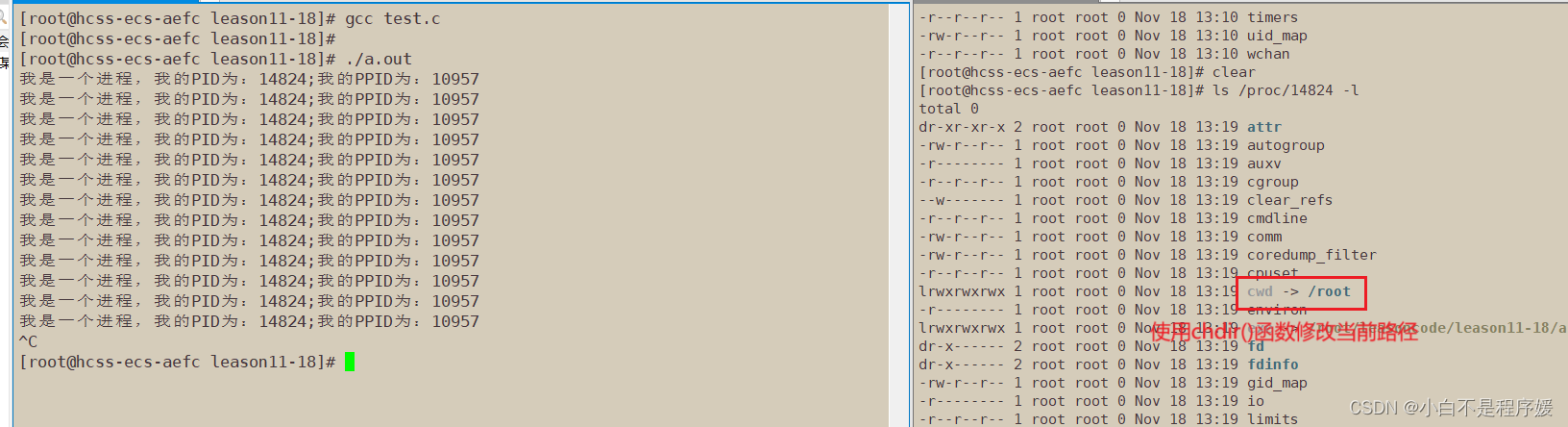
我们可以使用chdir()修改当前工作目录
1 #include<stdio.h>2 #include<unistd.h>3 int main()4 5 {6 chdir("/root"); 7 while(1)8 {9 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid());10 sleep(1);11 }12 return 0;13 }
fork创建进程
fork的引入
在Linux操作系统下有两种创建进程的方式
- 命令行中直接启动进程(手动启动)
- 通过代码来创建进程(fork)
我们一直在使用第一种方式创建进程,下面将通过演示fork来创建进程。
fork的使用
man fork 查看fork如何使用

1 #include<stdio.h>2 #include<unistd.h>3 int main()4 5 {6 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid());7 fork();8 9 printf("我是一个进程,我的PID为:%d;我的PPID为:%d\n",getpid(),getppid());10 sleep(1); 11 return 0;12 }

运行我们编译好的程序我们发现同一条输出语句运行了两次。这是因为在fork之前只有一个进程,fork创建了一个进程,所以才会执行两次。
fork的原理
fork如何实现的?
fork是一个函数,函数可以设置返回值;当fork子进程成功时给父进程返回子进程的PID,给子进程返回0;fork子进程失败时返回-1;子进程创建成功后会将fork下面的代码拷贝一份,相当有两个进程执行同一份代码,因此会输出两条语句。
1 #include<stdio.h>2 #include<unistd.h>3 int main()4 5 {6 pid_t id =fork();7 if(id<0)8 {9 return 0;10 }11 else if ( id == 0 )12 {13 while(1)14 {15 printf("我是子进程,我的Pid为:%d,我的PPid为:%d\n",getpid(),getppid());16 }17 sleep(1);18 }19 else 20 {21 22 while(1)23 {24 printf("我是父进程,我的Pid为:%d,我的PPid为:%d\n",getpid(),getppid());25 }26 sleep(1);27 }28 return 0;29 }

为什么fork之前的代码不执行?
在学习C语言的时候我们知道,代码执行的时候会有一个指针执行一条语句,指针就会随着变化;执行到fork时候,指针也变化到fork语句;因此只能将fork之后的语句拷贝给另一个进程。
为什么要有两个返回值?
这和我们用户使用计算机的场景有关,就像我现在在同一个浏览器里一边在CSDN写着博客,一边还在查找相关的资料。浏览器这一个进程含有两个进程,两个进程做着不同的事情,甚至更多。但是当前我们只能让做相同的事情,执行同一份代码。在以后的学习中我们会通过返回值让他们执行不同的代码片段。
今天对Linux下父子进程和fork进程的介绍分享到这就结束了,希望大家读完后有很大的收获,也可以在评论区点评文章中的内容和分享自己的看法。您三连的支持就是我前进的动力,感谢大家的支持!!!








)



, ‘%Y%v‘))






