chatGML
看到
【【官方教程】ChatGLM-6B 微调:P-Tuning,LoRA,Full parameter】 【精准空降到 15:27】 https://www.bilibili.com/video/BV1fd4y1Z7Y5/?share_source=copy_web&vd_source=aa8c13cff97f0454ee41e1f609a655f1&t=927
记得看pdf
https://pan.baidu.com/s/1CKS5yBz6-GN_J7UB_wxguw?pwd=g26m
github
https://github.com/THUDM/ChatGLM-6B
参考资料
https://blog.csdn.net/v_JULY_v/article/details/129880836
/2
部署
colab
https://colab.research.google.com/drive/1N2ynqFbFSqKMcfQrofshcrkJgIfXMruR#scrollTo=Ae7KXXUsRJOv
解决内存和显存不足
https://www.cnblogs.com/bruceleely/p/17348782.html
本地服务器
可以考虑安装容器
下载这个容器 要登陆才可以下载
image:nvidia-pytorch:22.08-py3
Change your pip source
pip config set global.extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple
# Writing to /opt/conda/pip.conf
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# Writing to /opt/conda/pip.conf
pip config set global.trusted-host https://pypi.tuna.tsinghua.edu.cn/simple
# Writing to /opt/conda/pip.conf下载权重
1直接 git clone huggingface上的链接下载。比较慢,并且会不显示正在下载最后一个,通过bwm-ng显示下载进程,卡的要死
2清华云盘下载
一个一个下载。
通过工具下载
git clone git@github.com:chenyifanthu/THU-Cloud-Downloader.git
cd THU-Cloud-Downloader
pip install argparse requests tqdmpython main.py \
--link https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/ \
--save ../chatglm-6b/
下载项目
下载环境
自己安装适合的torch版本,不要让txt下载
微调
https://www.bilibili.com/video/BV1fd4y1Z7Y5/?spm_id_from=333.999.0.0&vd_source=6d6126fdf98a0a7f2e284aa4d2066198
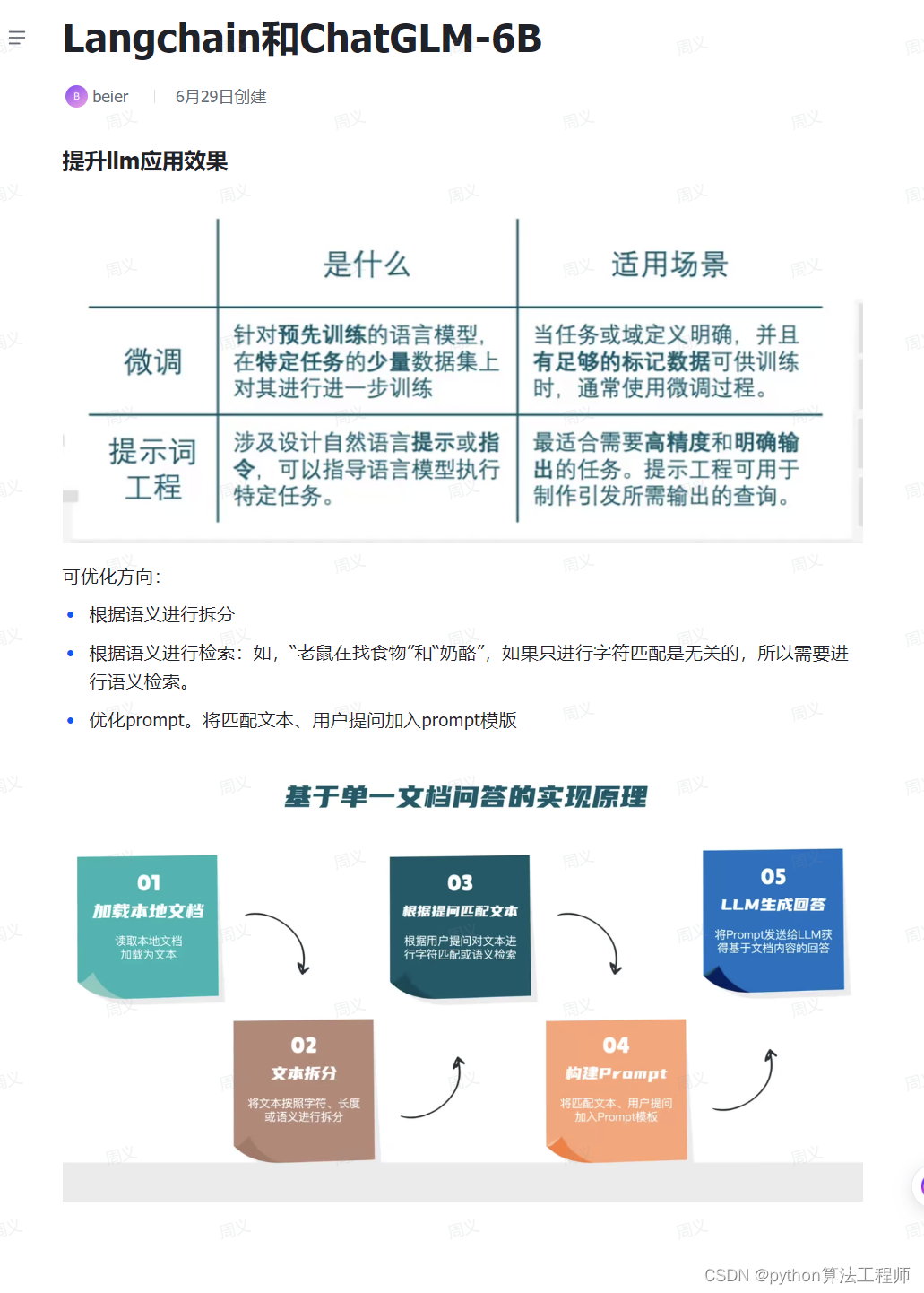
微调原理
硬件要求
P-tuning int4 -8G
用下面docker这image 要换源,因为他默认的会很慢
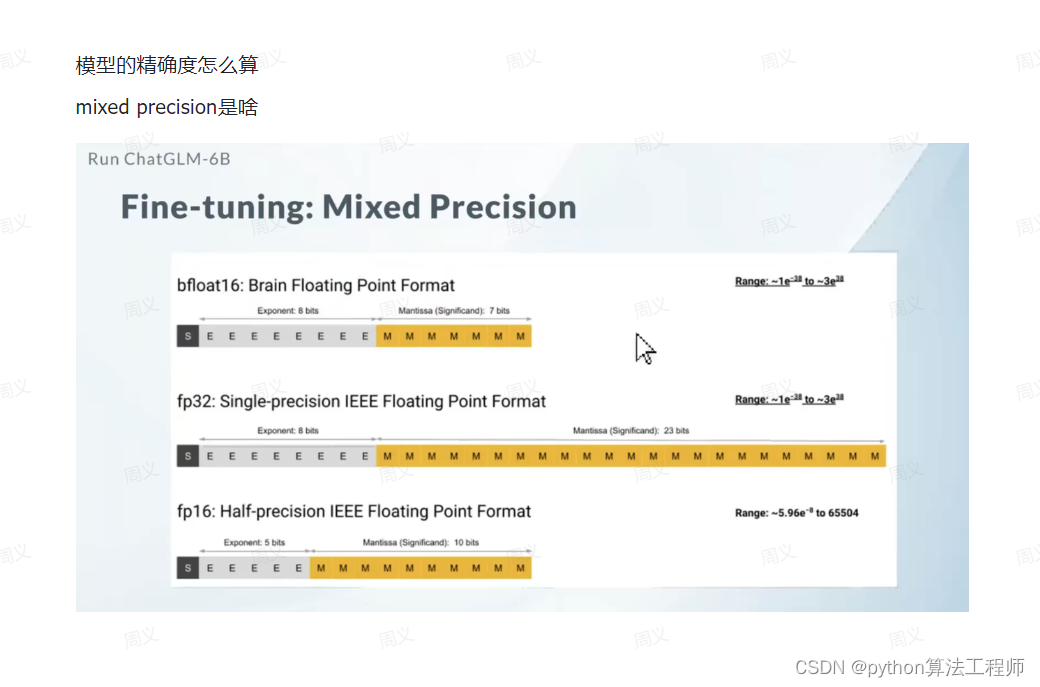
混合精度训练
float32 可以表示的数值范围是 10 的负 38 次方到正 38 次方。
float16 可以表示的数值范围是 10 的负 8 次方到正 4 次方。用他会快一倍
What
更新的梯度在10的负27次方,影响就会非常的小,但是在10-27到10的-8的精度。
- 模型初始化:将模型参数初始化为32位浮点数。
- 前向传播:使用16位浮点数进行前向传播计算,得到输出结果。
- 反向传播:把loss变大乘以一个因子 使用32位浮点数进行反向传播计算,计算梯度。
- 梯度缩放:将梯度乘以一个缩放因子,以抵消16位浮点数的精度损失。
- 参数更新:使用32位浮点数的梯度更新模型参数。
zeRO。
DP多卡训练,每一个卡单独反向传播,然后最后通信取平均值,在更新
MP
在adam优化器
权重,adam的一阶梯度,二阶梯度都用32表示。
Dynamic loss scaling 技术会把loss变大乘以一个常数因子,比如 -16,变成-15
coding
import numpy as np# 定义初始参数
x = 3.0# 定义学习率和动量参数
learning_rate = 0.1
beta1 = 0.9
beta2 = 0.999
epsilon = 1e-8# 定义一阶和二阶矩估计的初始值
m = 0
v = 0# 定义损失函数
def loss_fn(x):return x ** 2# 进行优化
for _ in range(10):# 计算梯度gradient = 2 * x# 更新一阶和二阶矩估计m = beta1 * m + (1 - beta1) * gradientv = beta2 * v + (1 - beta2) * (gradient ** 2)# 校正一阶和二阶矩估计的偏差m_hat = m / (1 - beta1)v_hat = v / (1 - beta2)# 更新参数x -= learning_rate * m_hat / (np.sqrt(v_hat) + epsilon)# 打印参数值print(x)
zeRO。
DP多卡训练,每一个卡单独反向传播,然后最后通信取平均值,在更新
MP
why
训练时都是用Float 32精度来训练的,但是它占的内存比较大,有时候还没用到这么精细,就很浪费。所以会考虑用用float16,会快一倍但是全都用,进度就会下降很多。梯度小于10*-27次方。对训练没影响,但是10*-27到10的-8次方又有影响。所以用混合精度
P-tuningv2
记得看readme,README.md
安装依赖
在chatGLM项目里面的ptuning文件里的,train.sh,里面修改配置,然后运行他
![[图片]](https://img-blog.csdnimg.cn/ceb34d6fdd39470b9e496fd27e72589c.png)
参数解析
全量微调
说明在里面在ChatGLM-6B/ptuning/README.md里面
在chatGLM项目里面的ptuning文件里的这个文件里面写了ds_train_finetune.sh。
运行他就可以
要用4张卡的58G显存
lora微调
https://cloud.tencent.com/developer/article/2276508
方法1
下载,里面有lora微调chatGLM代码
https://github.com/yuanzhoulvpi2017/zero_nlp,
在这里面
zero_nlp/simple_thu_chatglm6b/code02_训练模型全部流程.ipynb
然后改里面的代码,主要是数据加载方面的。
Lora微调
②Lora:技术原理简单,但真有奇效,需要注意rank大小的设置,是根据业务领域来的,领域垂直性越强,就要设置的越大,比较有意思的就是数据,看起来最没技术含量的事情,大家不愿意做,但其实是最难的,数据收集存在诸多问题,数据少且封闭,缺乏标注,垂直领域往往对结果要求很高。
NLP Metrics Made Simple: The BLEU Score
https://towardsdatascience.com/nlp-metrics-made-simple-the-bleu-score-b06b14fbdbc1
WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences
https://arxiv.org/pdf/2306.07906.pdf
中文介绍
https://github.com/THUDM/WebGLM/blob/main/README_zh.md
Langchain-chaGLM
问题
解释一下矢量,解释一下万有引力,解释一下摩擦力,解释一下直线运动,刚体运动的分类,解释一下机械波,热力学第一定律
github
https://github.com/imClumsyPanda/langchain-ChatGLM
参考
https://blog.csdn.net/v_JULY_v/article/details/129880836
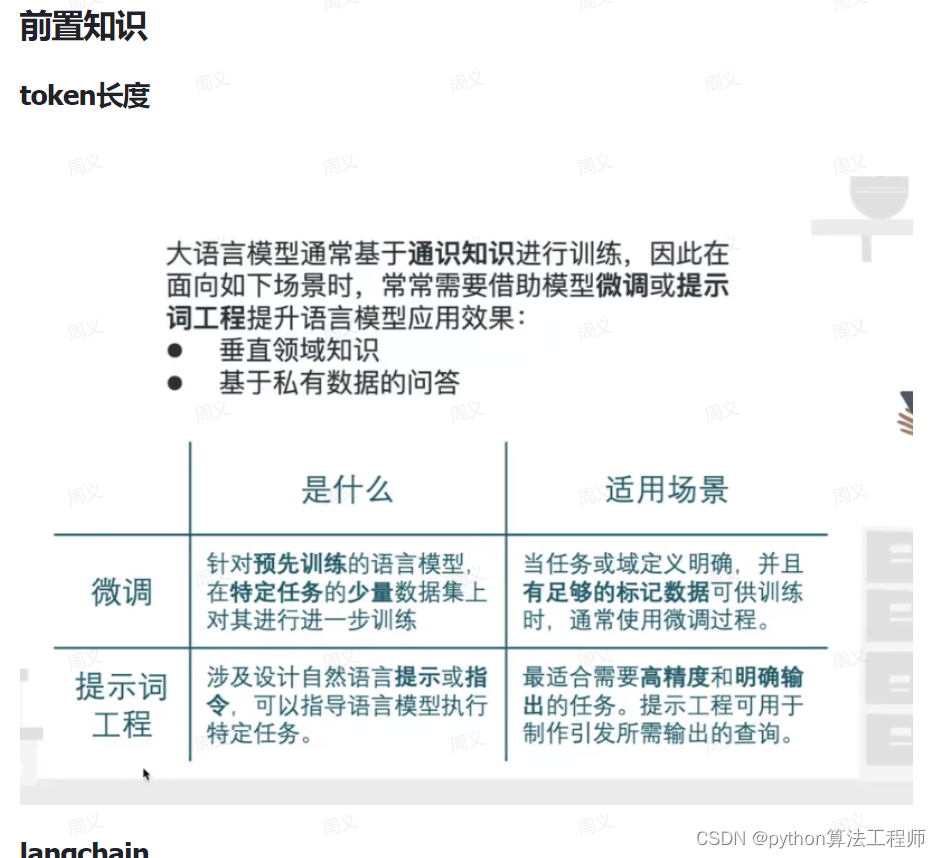
langchain
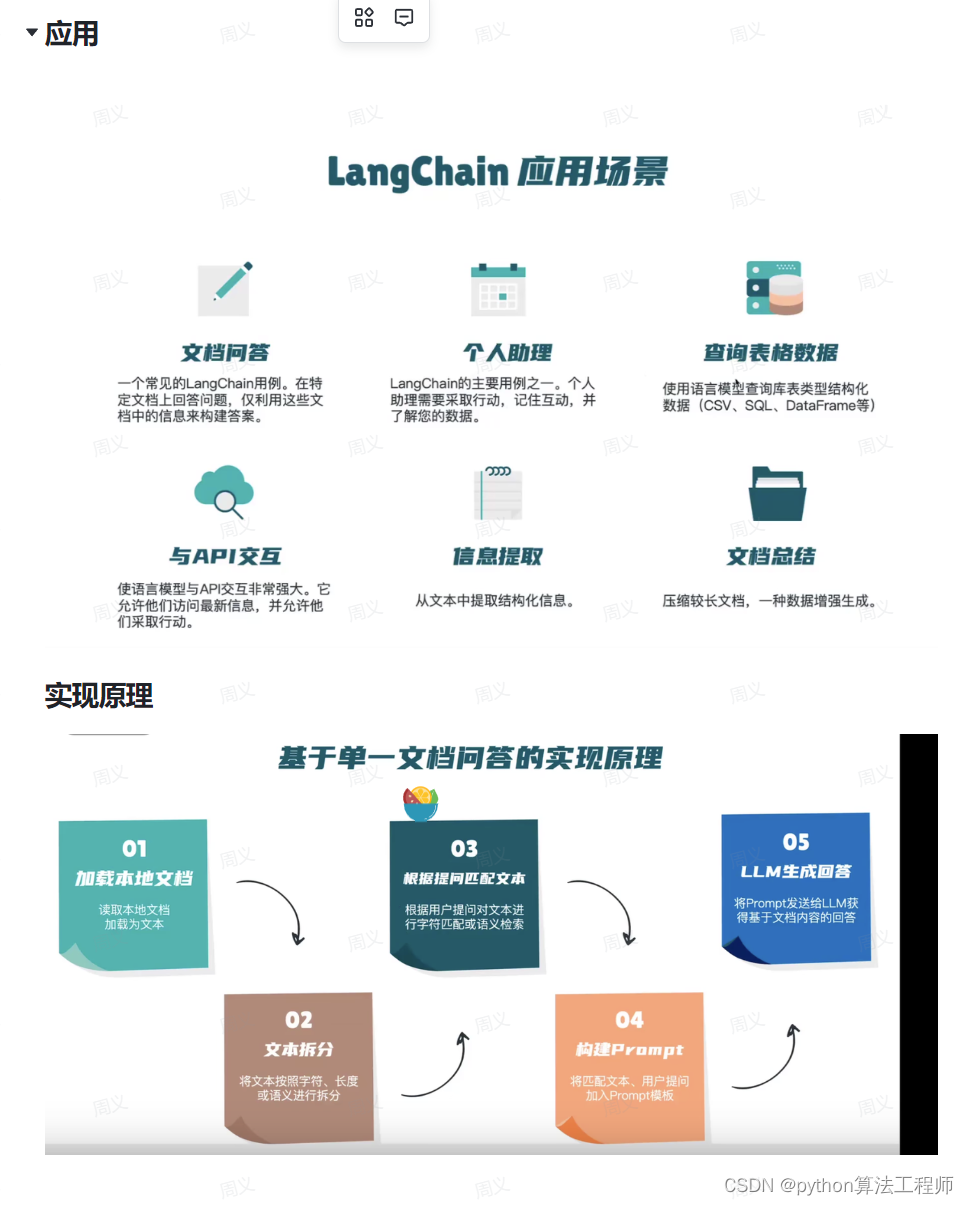
LangChain是一个用于开发由语言模型驱动的应用程序的框架。
主要功能:
调用语言模型
将不同数据源接入到语言 模型的交互中
允许语言模型与运行环境交互
LangChain中提供的模块
●Modules: 支持的模型类型和集成。
●Prompt: 提示词管理、优化和序列化,支持各种自定义模版。
●Memory: 内存是指在链/代理调用之间持续存在的状态。
Indexes:当语言模型与特定于应用程序的数据相结合时,会变得更加强大-此模块包含用于
加载、查询和更新外部数据的接口和集成。
●Chain: 链是结构化的调用序列(对LLM或其他实用程序)。
Agents:代理是一个链,其中LL M在给定高级指令和一-组工具的情况下,反复决定操作,执
行操作并观察结果,直到高级指令完成。
●Callbacks: 回调允许您记录和流式传输任何链的中间步骤,从而轻松观察、调试和评估应用
程序的内部。
what
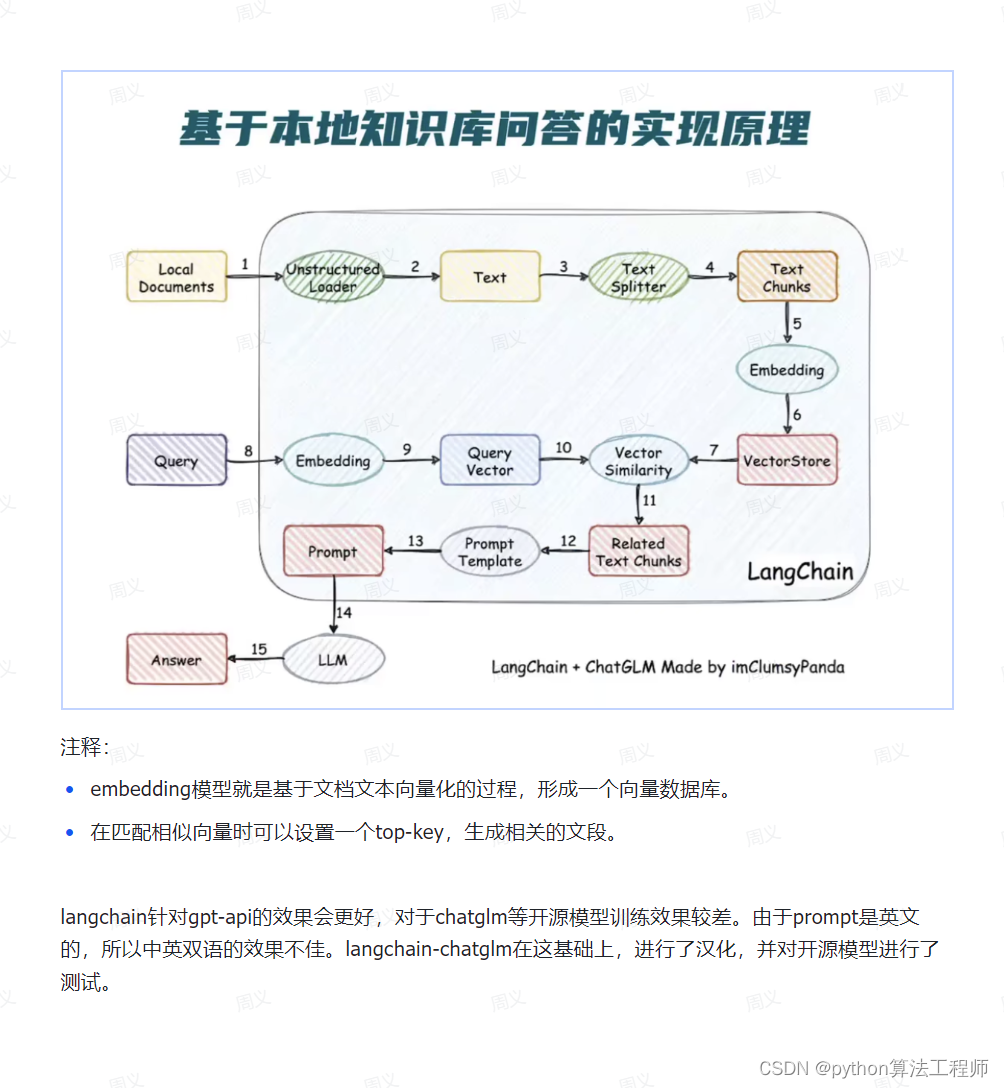
LangChain-ChatGLM项目简介
LangChain- -ChatGLM是一个基于ChatGLM等大语言模型的本地知识库问答实现。
项目特点
LangChain主要是适用用于openai等API,并且对英文比较友好,我们对其根据chatGLM优化
●依托 ChatGLM等开源模型实现,可离线部署
●基于 langchain实现,可快速实现接入 多种数据源
●在分句、 文档读取等方面,针对中文使用场景优化
支持pdf、txt、 md、docx等文件类型接入,具备命令行demo、webui 和vue前端。
项目结构.
models: Im的接口类与实现类,针对开源模型提供流式输出支持(原来是不支持的)。
loader: 文档加载器的实现类(优化了对中文的OCR)。
textsplitter:文本切分的实现类。
chains: 工作链路实现,如chains/local doc .qa 实现了基于本地文档的问答实现。
content: 用于存储上传的原始文件。
vector_ store: 用于存储向量库文件,即本地知识库本体(知识库的向量库)。
configs:配置文件存储。
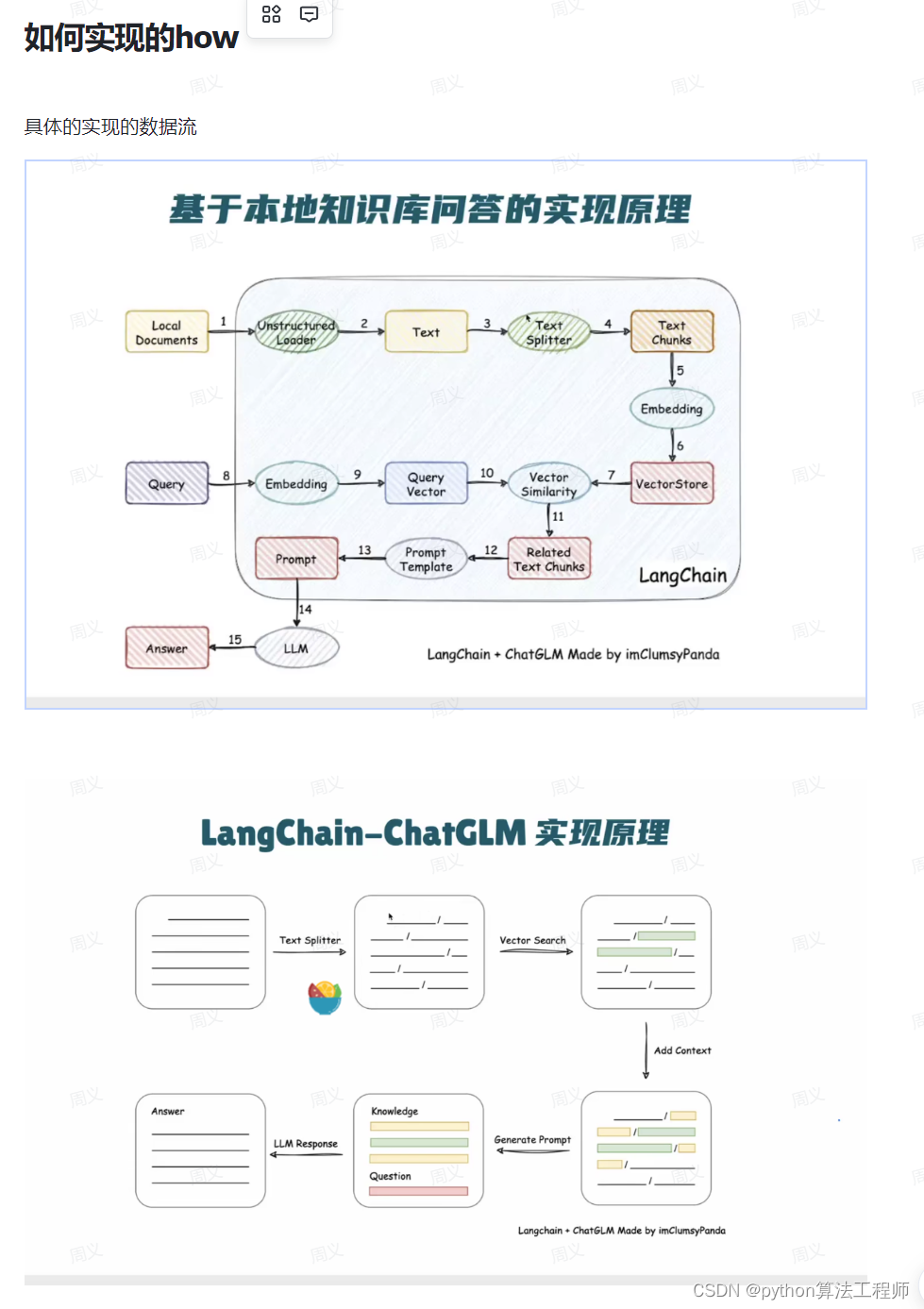
Vector searech如果是标题的话,会把他上下文一起选中
多个相关句子搜索,找到的比较的多话,会重新排列和去重
部署
在别人免费的服务器上部署
一步一步教你的视频
https://www.bilibili.com/video/BV11N411y7dT/?spm_id_from=333.337.search-card.all.click&vd_source=6d6126fdf98a0a7f2e284aa4d2066198
依据
https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui
本地服务器上部署
官方群里的教程
langchain-ChatGLM, 小白入门
简单的视频教程
https://www.bilibili.com/video/BV1Ah4y1d79a/?spm_id_from=333.337.search-card.all.click&vd_source=6d6126fdf98a0a7f2e284aa4d2066198
根据github上的来
下载权重
要下载两个权重,语言大模型和编码模型text2vec-base,chatglm-6b
根据github 里面说名明从huggingface里面下载

自己的服务器电脑上很难下载(系统如果没有翻墙的话),通过colab上下载下来吧
可以从国内直接下载,别人复制的
https://openi.pcl.ac.cn/Learning-Develop-Union/LangChain-ChatGLM-Webui/datasets?page=2
直接在服务器上面下载
Wget -O name 'https://s3.openi.org.cn/opendata/attachment/0/c/0cebbcbc-5e41-4826-9052-718b601790d9?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=1fa9e58b6899afd26dd3%2F20230630%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230630T145020Z&X-Amz-Expires=604800&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3D%22text2vec-base-chinese.zip%22&X-Amz-Signature=523c6e6b24a82b1fcd030286f1298bd04b9642e552999b60094d07e8afe8fa58'
在jumpserver.deepblueai.com服务器里面那就下载到/data里面
根据安装指南配置python环境
Bug
记得参考 https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/FAQ.md 或者issues
- 1module ‘PIL.Image’ has no attribute ‘Resampling’
pip install --upgrade pillow - python loader/image_loader.py 出现 No module named ‘configs’
以下两行移到main函数内可以解决这个问题:
from configs.model_config import NLTK_DATA_PATH
nltk.data.path = [NLTK_DATA_PATH] + nltk.data.path
配置文件修改
在langchain-ChatGLM/configs/model_config.py里面修改
修改模型对应的路径
text2vec-base,chatglm-6b 这两个是必要的,下载后,对应的路径要改成自己下载后的路径
启动 直接代码交互
#启动模型from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer. from_ pretrained("THUDM/chatglm-6b", trust_ remote_ code =True)
model = AutoModel. from_ pret rained( "THUDM/chatglm-6b", trust_ remote_ code=True) . half(). cuda()
chatglm = model.eval()from langchain. document_ loaders import Unst ructuredF ileLoader
from langchain. text_ splitter import CharacterTextSplitter
from langcha in. embeddings . openai import OpenAIEmbeddings
from langchain. vectorstores import FAISS
#定义文件路径
filepath = "test. txt"
#加载文件
loader = UnstructuredF ileLoader( filepath)
docs = loader. load()
#文本分割 一段字符chunk_size=500大小,200重复
text_ splitter = CharacterTextSplitter(chunk_ size=500, chunk_ overlap=200)
docs = text_ splitter.split_ text(docs)
#构建向量库 使用 OpenAI的模型,要他的key
embeddings = OpenAIEmbeddings()
vector_ store = FAISS. from_ documents(docs , embeddings)
#根据提问匹配上下文
query = "Langchain 能够接入哪些数据类型? "
docs = vector_ store.similarity_xsearch( query)
context = [doc, page_ content for doc in docs]
# 149ji1 Prompt
prompt = f"Bẞfta: n(contextnBf n(query)"
# llm生成回答
chatglm.chat(tokenizer, prompt, history=[])
webui界面启动
已经启动的
财务
https://74751b9051e05d9334.gradio.live
物理的
https://cfa4ae934de998f390.gradio.live
量化4模型启动
原本
CUDA_VISIBLE_DEVICES=0 python webui.py --model chatglm-6b-int4 --no-remote-model
我的
CUDA_VISIBLE_DEVICES=0 python webui-caiwu.py --model chatglm-6b-int4 --no-remote-model
CUDA_VISIBLE_DEVICES 指定第几张显卡
–model 模型名称,这里是量化int4模型
–no-remote-model 不从远程加载模型
https://github.com/gradio-app/gradio/issues/884
详细参数配置看
https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/StartOption.md
外网访问
webui.py 里面设置为 share=True,
bug
1 运行 python webui.py --model chatglm-6b-int4 --no-remote-model
WARNING 2023-06-28 11:03:40,657-1d: The dtype of attention mask (torch.int64) is not bool
ERROR 2023-06-28 11:03:40,661-1d: Library cublasLt is not initialized
解决
cuda版本太低了,更新一下,我是更新到11.4,并且这个操作还会影响到chatglm模型的使用。
2
raise EnvironmentError(
OSError: Can’t load the configuration of ’ model/chatglm-6b-int4’. If you were trying to load it from ‘https://huggingface.co/models’, make sure you don’t have a local directory with the same name. Otherwise, make sure ’ model/chatglm-6b-int4’ is the correct path to a directory containing a config.json file
解决
记得看人家说明用绝对路径
3 debug时指定使用某张显卡失效
解决
配置launch.json文件,在configurations中填入以下内容,最后按F5调试即可
"program": "${workspaceFolder}/<your-python-file.py>",
"env": {"CUDA_VISIBLE_DEVICES": "3"} # 指定编号为3的显卡
启动成功
INFO 2023-06-29 15:52:23,800-1d: Load pretrained SentenceTransformer: /data/wbe/langchain-ChatGLM-master/text2vec-base-chines
WARNING 2023-06-29 15:52:25,232-1d: The dtype of attention mask (torch.int64) is not bool
{‘answer’: ‘你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。’}
INFO 2023-06-29 15:52:31,644-1d: 模型已成功加载,可以开始对话,或从右侧选择模式后开始对话
Running on local URL: http://0.0.0.0:7860
Running on public URL: https://0c7198ac57dc8d288c.gradio.live
在服务器上的路径
项目在
/home/deepblue/wbe/langchain-ChatGLM-master
权重在
/data/wbe/langchain-ChatGLM-master
环境在
(WBE)
预期效果
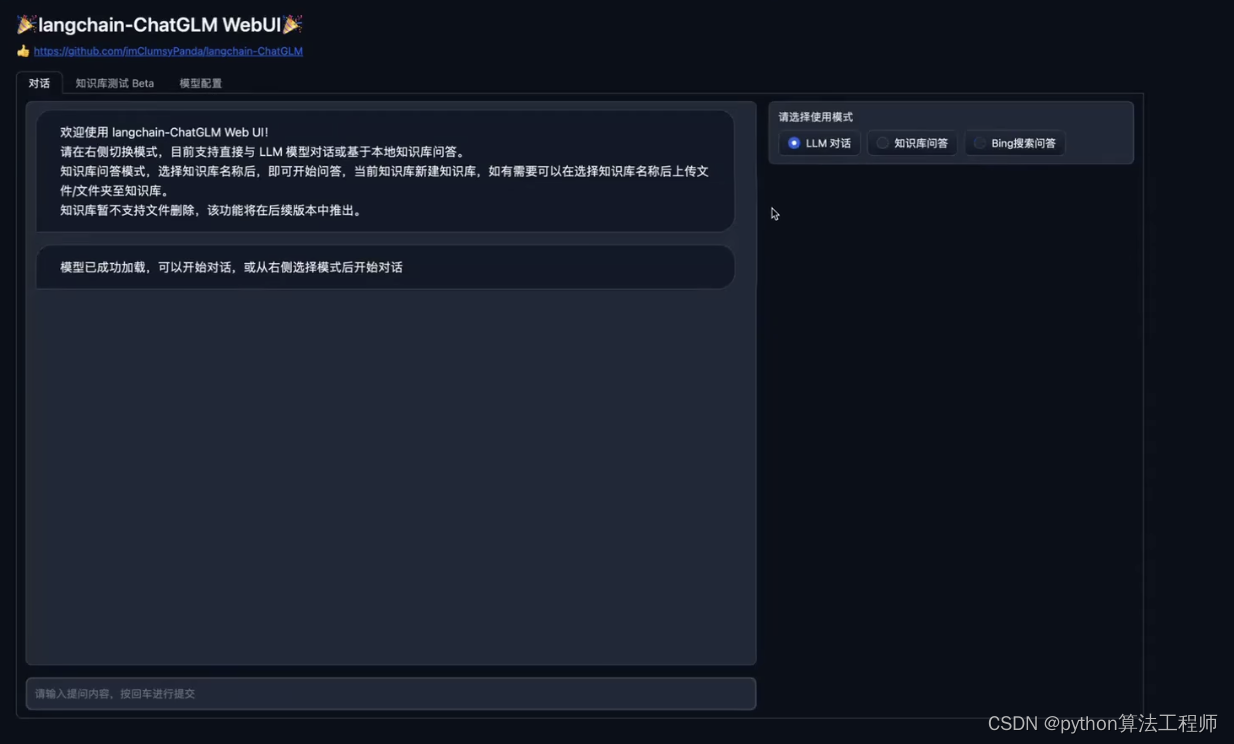
LM对话
知识库回答
选择要导入的文件名字不能中文,输入的文本的大小
bing搜索问答
要key
功能测试以及要要优化的点
知识库问答
上传知识库后,对知识库进行加载,在如下界面操作
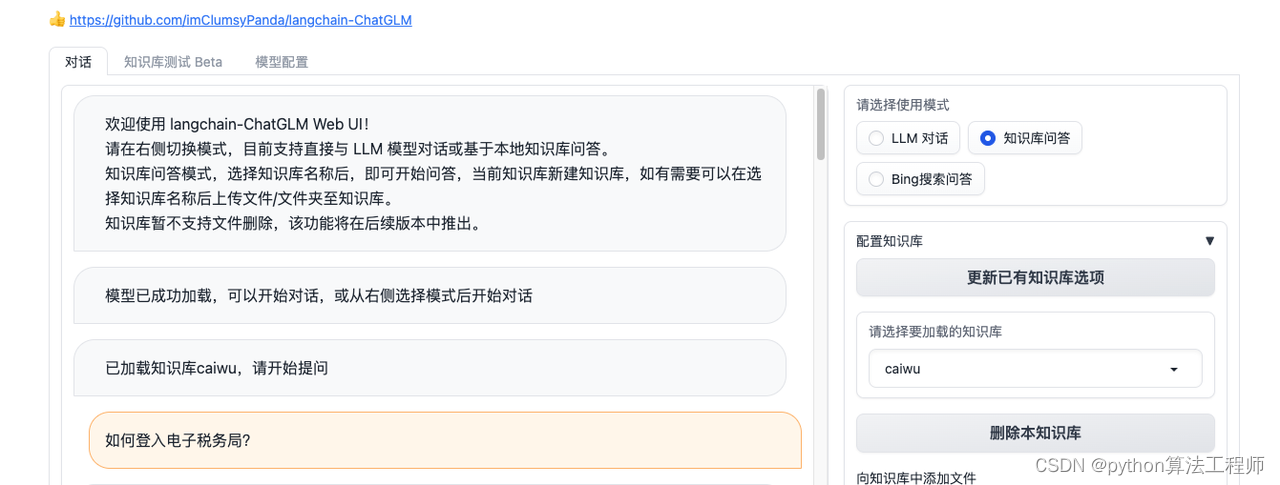
优化
1 文档加载:可以扩展支持类型,增加文档类别标签,便于细分
2 文档分段:看看nlp里面中文或者中英文分段比较好的方法,比较一下
3 文本向量化:比较不同embedding模型对中文或中英文文本生成效果
4 语义向量匹配:不同向量数据库的存储、查询效率比较
5 prompt模版:模版汉化与双语模版支持(主要是受限于llm的双语能力可能不足)
0添加链接描述1对chatglm模型微调
02文档加工
文本分段优化,避免对于标题,还选取他的上文
文本向量长度太长,通过模型文本分段总结,在对他编码成向量
03提示词优化
使用不同模型
ChatGLM-6B
int4
无量化
ChatGLM2-6B
https://github.com/THUDM/ChatGLM2-6B
https://huggingface.co/THUDM/chatglm2-6b
gradio界面优化
html显示图片
gr.Blocks()里面添加
gr.HTML( ),自己根据html调一调样式和布局
),自己根据html调一调样式和布局
不管路径是什么前面都要加一个file/
显示图标和修改背景图片
gr.Blocks()里面添加
title=“物理问答系统”
css=“.gradio-container {background: url(‘file=/home/deepblue/wbe/langchain-ChatGLM-phy/images/4401689141796_.pic.jpg’)}”
设置比较好的模型参数,token,和长度
langchain-ChatGPT API
参考资料
吴恩达老师和langchain作者发布的大模型开发新课程,指导开发者如何结合框架LangChain 使用 ChatGPT API 来搭建基于 LLM 的应用程序
https://github.com/datawhalechina/prompt-engineering-for-developers/tree/main/content/LangChain%20for%20LLM%20Application%20Development
datawhalechina 的上面课程的文档和代码


LoadBalancer负载均衡)










)



--支持向量机)
——机器学习实践案例总体流程)
(附源码))