文章目录
- 概述
- Hugging Face
- obs操作
- git-lfs
- 例子
- RedPajama-Data-1T
- SlimPajama-627B/
- git clone续传
- 数据格式
- 参考资料
概述
大模型训练中语料是非常重要的,目前公网上有各种各样的语料可以供下载,但是不可能每个用户、每次训练任务都通过公网去拉取语料,因此我们需要在语料平台上为用户提前下载并且注册一些需要的语料,通过语料平台维护一些公用的语料。
鉴于语料下载的多样性,目前下载公网上的语料一般会先把语料下载到国外的服务器,然后再上传到华为云的 obs,最后再在 IDC 环境的服务器上将 obs 的数据下载到 CephFS 的语料目录(要求这台机器需要有外网以及挂载CephFS的权限)。
外网动辄上 TB 的语料下载是很费时间的,也很考验网络的可靠程度,因此在下载的时候,不管用什么方法,一定要注意断点续传之类的方案。
Hugging Face
下面以下载 Hugging Face 的 cerebras/SlimPajama-627B 为例,下面的脚本前提是需要安装 datasets。
from datasets import load_dataset
ds = load_dataset("cerebras/SlimPajama-627B")
因为数据集是会有低数据量的版本的,因此建议用户可以先用这部分做一些简单的测试,再决定是否全量下载。
# cat test.py
from datasets import load_dataset
dataset = load_dataset("neulab/conala", cache_dir="./dataset")
dataset.save_to_disk('dataset/neulab/conala')
(chatgpt) [root@ecs-f430 ~]# tree
.
├── dataset
│ ├── downloads
│ │ ├── c2f5907d74f66a3a8e62dfbbd17301cd9ac82f7af932353dbd97faa7c5636cfa
│ │ ├── c2f5907d74f66a3a8e62dfbbd17301cd9ac82f7af932353dbd97faa7c5636cfa.json
│ │ ├── c2f5907d74f66a3a8e62dfbbd17301cd9ac82f7af932353dbd97faa7c5636cfa.lock
│ │ ├── c6099a128d3e027c23a9f2e574333bf42e65bd69a531bbbe4ca2a53e6ee93190
│ │ ├── c6099a128d3e027c23a9f2e574333bf42e65bd69a531bbbe4ca2a53e6ee93190.json
│ │ └── c6099a128d3e027c23a9f2e574333bf42e65bd69a531bbbe4ca2a53e6ee93190.lock
│ ├── neulab
│ │ └── conala
│ │ ├── dataset_dict.json
│ │ ├── test
│ │ │ ├── data-00000-of-00001.arrow
│ │ │ ├── dataset_info.json
│ │ │ └── state.json
│ │ └── train
│ │ ├── data-00000-of-00001.arrow
│ │ ├── dataset_info.json
│ │ └── state.json
│ └── neulab___conala
│ └── curated
│ └── 1.1.0
│ ├── 8557ab15640c382a1db16dca51ee1845bc77bf7c45015a2c095446a8e20ba5d3
│ │ ├── conala-test.arrow
│ │ ├── conala-train.arrow
│ │ └── dataset_info.json
│ ├── 8557ab15640c382a1db16dca51ee1845bc77bf7c45015a2c095446a8e20ba5d3_builder.lock
│ └── 8557ab15640c382a1db16dca51ee1845bc77bf7c45015a2c095446a8e20ba5d3.incomplete_info.lock
└── test.py10 directories, 19 files
obs操作
curl -LO https://obs-community.obs.cn-north-1.myhuaweicloud.com/obsutil/current/obsutil_linux_amd64.tar.gz
tar zxvf obsutil_linux_amd64.tar.gz
mv obsutil_linux_amd64_5.5.9/obsutil /usr/local/bin/
obsutil config -i=<秘钥> -k=<秘钥> -e=obs.cn-north-4.myhuaweicloud.com
obsutil config -i=MJBDGH3HLXYZERXD2NRE -k=DAIVJcgpeflGzgdXMmA27yatPp1oYfyu707vx3gr -e=obs.ap-southeast-3.myhuaweicloud.com# 测试
obsutil cp obs://a800-bj/tmp/llama-2-7b . -f -r
obsutil cp obs://dok/dok-release-without-app-image.gz . -f -r
obsutil cp obs://dok/dok-release-without-app-image.gz.md5sum . -f -r
下面就是实际操作的时候打印的日志,可以评估一下下载的速度。

git-lfs
Hugging Face 的语料也可以用 git-lfs 进行下载,但是 git 下载的时候会把 .git 文件下载下来,而这个文件在使用的时候是没什么必要的。
git lfs install
git clone https://huggingface.co/datasets/cerebras/SlimPajama-627B
可以看到,通过 git 下载的数据,是跟 Hugging Face 页面显示的语料格式一样的。

例子
RedPajama-Data-1T
比如说下载这个数据集 RedPajama-Data-1T,实际上依靠下面的脚本也可以完成下载,通过分析 urls.txt 可以发现,下载的这些数据文件完全不经过 HF 的服务器,类似这种情况,有时候能是比直接从 HF 的服务器下载语料是快很多的。
wget 'https://data.together.xyz/redpajama-data-1T/v1.0.0/urls.txt'
while read line; dodload_loc=${line#https://data.together.xyz/redpajama-data-1T/v1.0.0/}mkdir -p $(dirname $dload_loc)wget "$line" -O "$dload_loc"
done < urls.txt
SlimPajama-627B/
这个在华为云的新加坡区的机器下载非常慢。
python -c 'from datasets import load_dataset;dataset = load_dataset("cerebras/SlimPajama-627B")'
但是上述这个方法一样会遇到一些网络问题。
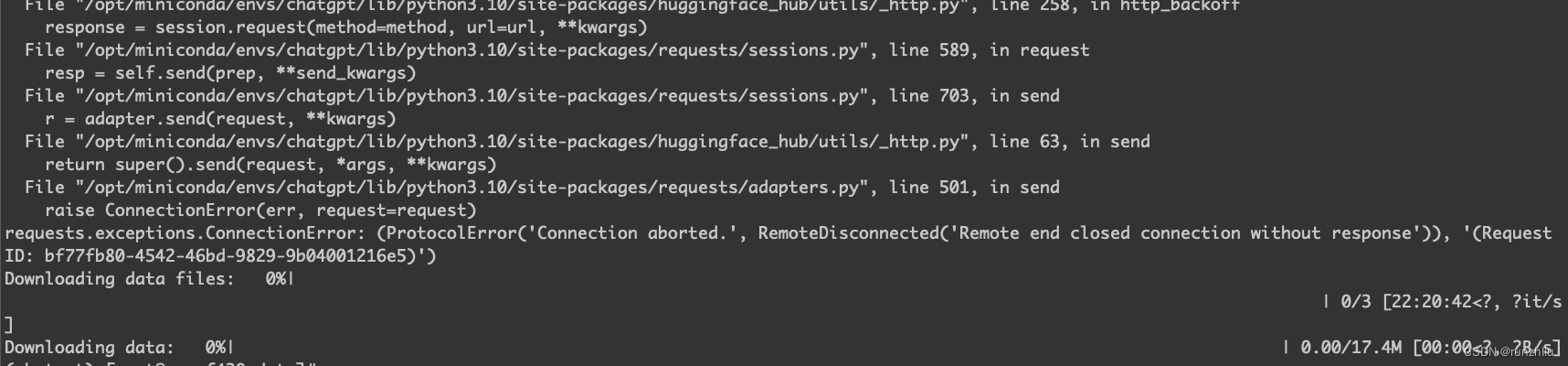
通过 git clone 是容易报错的。
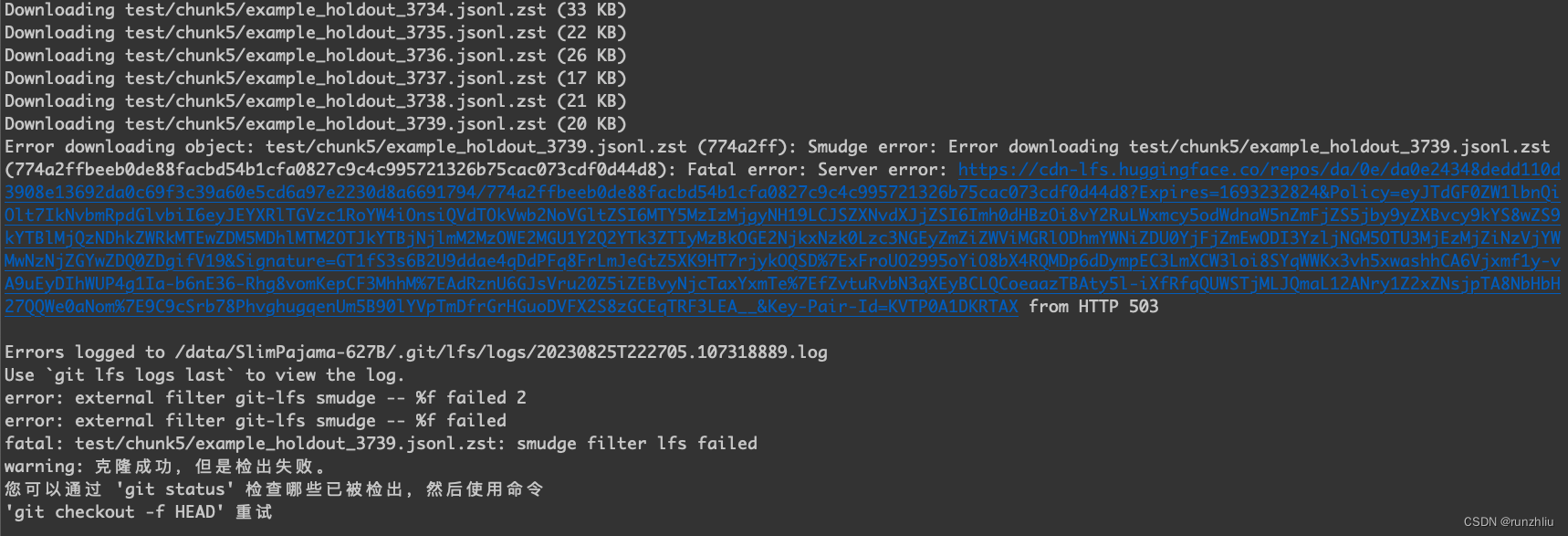
可以通过下面的方法实现断点续传。
from datasets import load_dataset
import datasets
import os# 需要设置一下环境变量
os.environ["HF_DATASETS_CACHE"] = "/data/hf_dataset/"
config = datasets.DownloadConfig(resume_download=True, max_retries=100)
dataset = datasets.load_dataset("cerebras/SlimPajama-627B", cache_dir="/data/hf_dataset/", download_config=config)
git clone续传
git clone --recursive --depth 1 <repository_url>
数据格式
- jsonl: json line格式
- jsonl.zst: 用zst压缩json line格式文件
测试一下。
(base) [root@ecs-f430 tmp]# unzstd example_holdout_212.jsonl.zst
example_holdout_212.jsonl.zst: 95993 bytes
(base) [root@ecs-f430 tmp]# ls
awesome-chatgpt-prompts example_holdout_212.jsonl example_holdout_212.jsonl.zst obsutil_linux_amd64_5.4.11 systemd-private-a37c64d204184d31a75497db9347d40f-chronyd.service-jMVrVi
(base) [root@ecs-f430 tmp]# vim ^C
(base) [root@ecs-f430 tmp]# ll example_holdout_212.jsonl*
-rw-r--r-- 1 root root 95993 9月 4 14:17 example_holdout_212.jsonl
-rw-r--r-- 1 root root 39089 9月 4 14:17 example_holdout_212.jsonl.zst
(base) [root@ecs-f430 tmp]# ll -h example_holdout_212.jsonl*
-rw-r--r-- 1 root root 94K 9月 4 14:17 example_holdout_212.jsonl
-rw-r--r-- 1 root root 39K 9月 4 14:17 example_holdout_212.jsonl.zst
(base) [root@ecs-f430 tmp]# vim example_holdout_212.jsonl
参考资料
- datasets-server
- Hugging Face教程 - 5. huggingface的datasets库使用
- Datasets 使用小贴士: 探索解决数据集无法下载的问题
- huggingface之datasets将数据集下载到本地
- datasets.Dataset.save_to_disk
- How can I get the original files using the HuggingFace datasets platform?
- jsonlines官方网站





)








自定义导航栏)




