🌈个人主页:Sarapines Programmer
🔥 系列专栏:《人工智能奇遇记》
🔖少年有梦不应止于心动,更要付诸行动。
目录结构
1. 机器学习之数据清洗概念
1.1 机器学习
1.2 数据清洗
2. 数据清洗
2.1 实验目的
2.2 实验准备
2.3 实验原理
2.4 实验内容
2.4.1 获取数据,整体去重;
2.4.2 整体查看数据类型以及缺失情况;
2.4.3 删除缺失率过高的变量;
2.4.4 删除不需要入模的变量;
2.4.5 删除文本型变量,有缺失值行;
2.4.6 修复变量类型;
2.4.7 变量数据处理方式划分;
2.4.8 变量数据处理方式划分;
2.4.9 拼接数据处理流水线.
2.5 实验心得
1. 机器学习之数据清洗概念
1.1 机器学习
传统编程要求开发者明晰规定计算机执行任务的逻辑和条条框框的规则。然而,在机器学习的魔法领域,我们向计算机系统灌输了海量数据,让它在数据的奔流中领悟模式与法则,自主演绎未来,不再需要手把手的指点迷津。
机器学习,犹如三千世界的奇幻之旅,分为监督学习、无监督学习和强化学习等多种类型,各具神奇魅力。监督学习如大师传道授业,算法接收标签的训练数据,探索输入与输出的神秘奥秘,以精准预测未知之境。无监督学习则是数据丛林的探险者,勇闯没有标签的领域,寻找隐藏在数据深处的秘密花园。强化学习则是一场与环境的心灵对话,智能体通过交互掌握决策之术,追求最大化的累积奖赏。
机器学习,如涓涓细流,渗透各行各业。在图像和语音识别、自然语言处理、医疗诊断、金融预测等领域,它在智慧的浪潮中焕发生机,将未来的可能性绘制得更加丰富多彩。
1.2 数据清洗
数据清洗,曲调优美的数据魔法,是数据分析与机器学习的不可或缺篇章。其目标在于在数据舞台登场前,发掘、矫正或祛除问题、不准确、不完整或无效的角色,以确保数据的绝对贵族品质,从而让分析和建模的舞台更加光彩夺目。
主要任务包括:
缺失值魔法:发现并施展缺失值的魔法,通过填充、删除或其他巧妙手法,为数据赋予完美的元素。
异常值舞台:挑战并征服异常值,这些幽灵可能源于数据输入的误差、设备的叛变等。
重复值消失术:感知并消除数据舞台上的重复记录,确保数据的独特华丽,让每个角色都是独一无二的明星。
数据格式魔咒:将数据转换为统一的魔法符号,使其更适合于分析和建模的神奇仪式。
一致性合唱:在数据的音乐殿堂中,确保不同部分之间的和谐奏鸣,让数据流畅一致。
数据变形技艺:对数据进行变形,使其适用于特定的分析或建模任务。
噪音降妖:发现并减弱数据中的噪音,提升数据的纯净度。
数据清洗,是数据分析的星光耀眼的序幕,因为原始数据集可能蕴含各种幽灵,而这些隐患将影响最终分析和建模的辉煌表演。通过巧妙的数据清洗,数据的可靠性得以提升,为分析和模型的绚丽演绎打下坚实基石。
机器学习程序源文件![]() https://download.csdn.net/download/m0_57532432/88521177?spm=1001.2014.3001.5503
https://download.csdn.net/download/m0_57532432/88521177?spm=1001.2014.3001.5503
2. 数据清洗
2.1 实验目的
(1)了解数据清洗的重要性;
(2)掌握数据清洗基本方法。
2.2 实验准备
(1)安装机器学习必要库,如NumPy、Pandas、Scikit-learn等;
(2)配置环境用来运行 Python、Jupyter Notebook和相关库等内容。
2.3 实验原理
在数据清洗中,针对不同情况需采取相应措施。发现重复记录或同义但不同名称情况时,进行去重或标准化,确保记录唯一一致。处理数据类型不匹配,如字符串误标为数值型,进行类型转换或纠正,确保每个特征正确类型。
同时,对连续型变量的缺失值进行处理。可选择删除含缺失值记录、用均值或中位数填充,或利用插值方法估算缺失值。保证数据集在缺失值方面完整,以确保后续分析和建模的有效进行。
2.4 实验内容
导入必要的库函数:

图1-1
代码:
# -*- coding: utf-8 -*-import osimport pandas as pdimport numpy as npnp.set_printoptions(suppress=True, precision=20, threshold=10, linewidth=40)# np禁止科学计数法显示pd.set_option('display.float_format',lambda x : '%.2f' % x)# pd禁止科学计数法显示2.4.1 获取数据,整体去重;
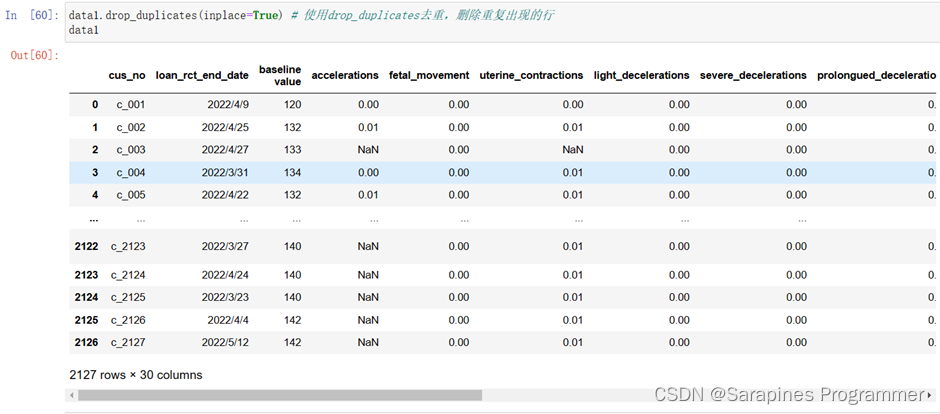
图1-2
代码:
data1 = pd.read_csv('./data/test_health.csv') #读取数据data1
图1-3
代码:
data1.drop_duplicates(inplace=True) # 使用drop_duplicates去重,删除重复出现的行data1
图1-4
代码:
data1.reset_index(drop=True, inplace=True) # 重置索引data12.4.2 整体查看数据类型以及缺失情况;

图1-5
代码:
data1.info() #整体查看数据类型,根据数量查看是否缺失2.4.3 删除缺失率过高的变量;
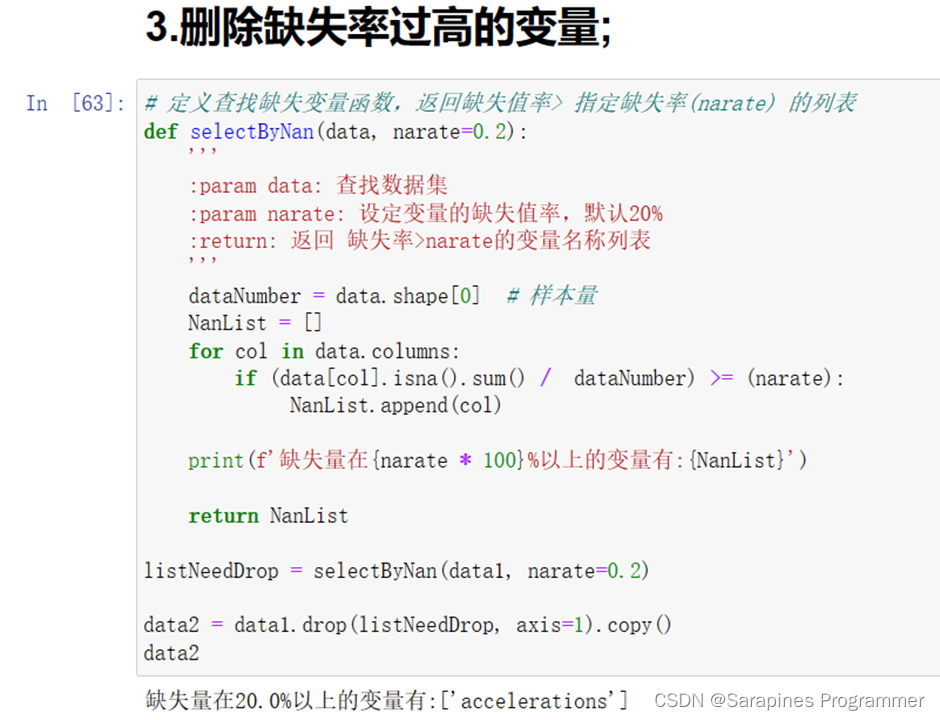
图1-6
运行结果
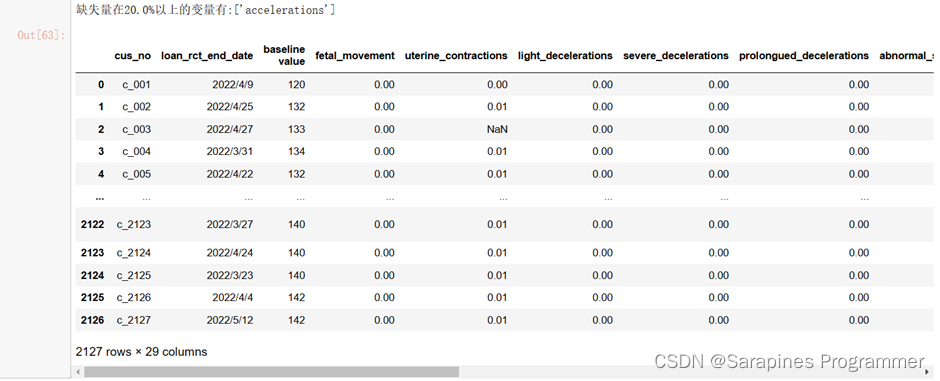
图1-7
代码:
# 定义查找缺失变量函数,返回缺失值率>指定缺失率(narate)的列表def selectByNan(data, narate=0.2):''':param data: 查找数据集:param narate: 设定变量的缺失值率,默认20%:return: 返回缺失率>narate的变量名称列表'''dataNumber = data.shape[0] # 获取数据集的样本量NanList = [] # 存储缺失率大于指定缺失率的变量名称列表# 遍历数据集的每一列for col in data.columns:# 计算每一列的缺失值率,并与指定缺失率进行比较if (data[col].isna().sum() / dataNumber) >= narate:NanList.append(col) # 如果缺失值率大于指定缺失率,则将变量名称添加到NanList中# 打印缺失值率大于指定缺失率的变量名称列表print(f'缺失量在{narate * 100}%以上的变量有:{NanList}')return NanList # 返回缺失值率大于指定缺失率的变量名称列表# 调用selectByNan函数,查找缺失值率大于指定缺失率的变量,并将其存储在listNeedDrop中listNeedDrop = selectByNan(data1, narate=0.2)# 在data1上调用drop方法删除listNeedDrop中的变量列,并创建data2作为副本data2 = data1.drop(listNeedDrop, axis=1).copy()data2# 返回删除指定列后的data1副本data22.4.4 删除不需要入模的变量;
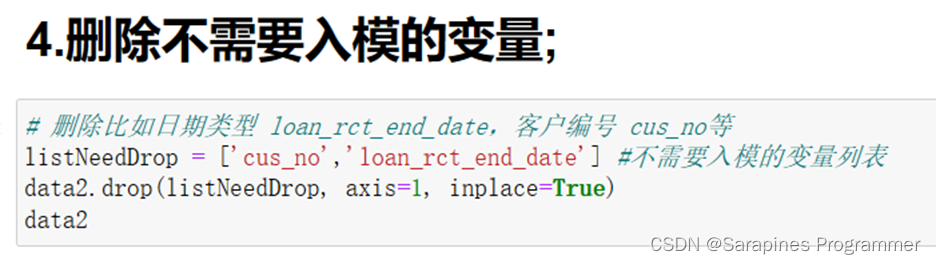
图1-8
运行结果

图1-9
代码:
# 删除比如日期类型 loan_rct_end_date,客户编号 cus_no等listNeedDrop = ['cus_no','loan_rct_end_date'] # 创建一个包含不需要入模的变量的列表data2.drop(listNeedDrop, axis=1, inplace=True) # 使用DataFrame的drop方法删除指定的列# 参数listNeedDrop是要删除的列名的列表# axis=1表示按列删除,axis=0表示按行删除# inplace=True表示在原始DataFrame上进行修改data2# 返回删除指定列后的DataFrame对象2.4.5 删除文本型变量,有缺失值行;

图1-10
结果如下:
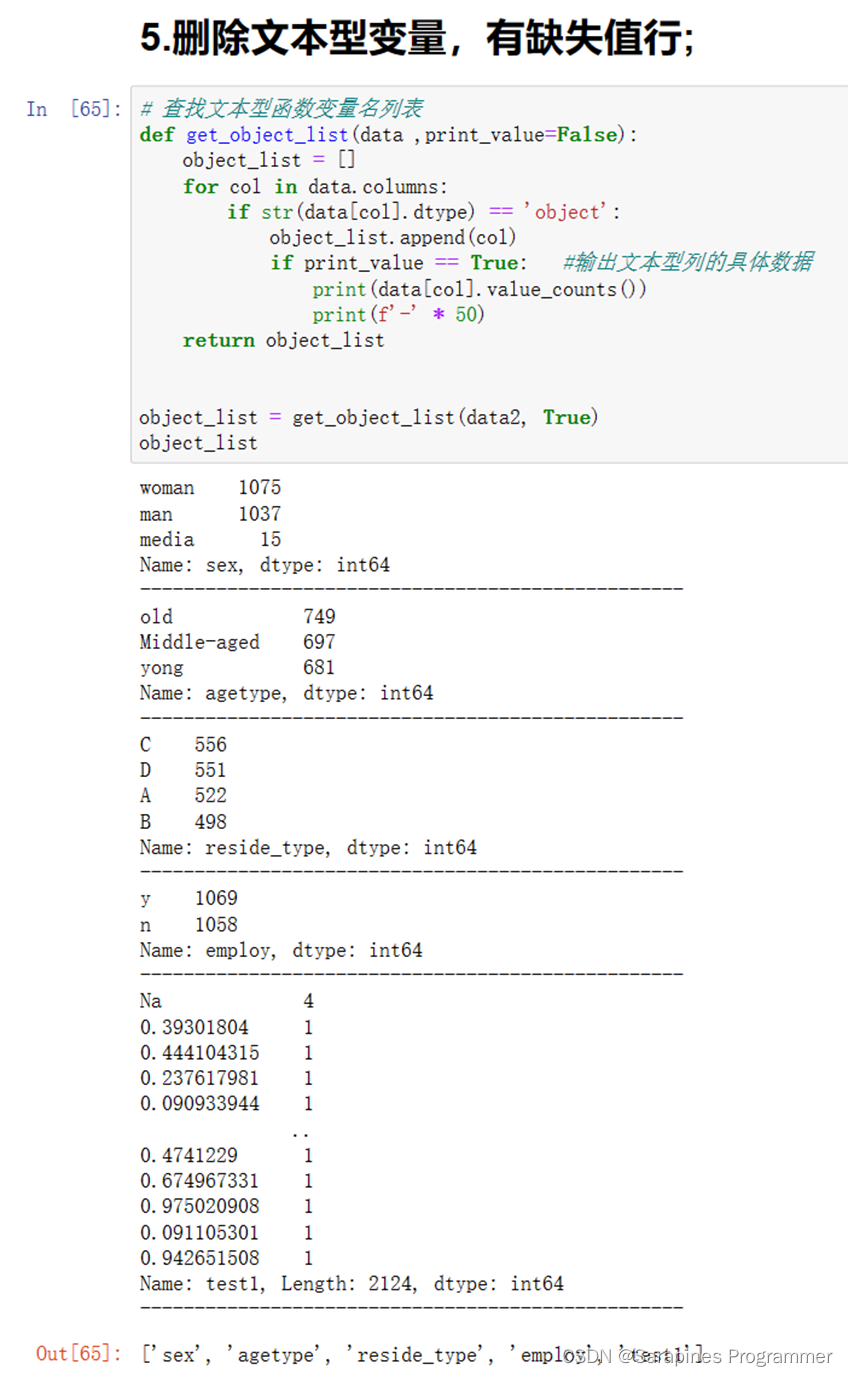
图1-11

图1-12
代码:
# 查找文本型函数变量名列表def get_object_list(data, print_value=False):''':param data: 要查找的数据集:param print_value: 是否打印文本型列的具体数据,默认为False:return: 返回文本型变量名列表'''object_list = [] # 存储文本型变量名的列表# 遍历数据集的每一列for col in data.columns:# 检查每一列的数据类型是否为object(文本型)if str(data[col].dtype) == 'object':object_list.append(col) # 如果是文本型变量,则将其名称添加到object_list中if print_value == True: # 如果设置了print_value为True,则打印文本型列的具体数据print(data[col].value_counts())print(f'-' * 50)return object_list # 返回文本型变量名列表# 调用get_object_list函数,查找data2中的文本型变量,并将print_value设置为Trueobject_list = get_object_list(data2, True)# 输出文本型变量名列表object_list# 情况3,删除文本型变量中有空值的行data2.dropna(subset=object_list, axis=0, inplace=True)# 使用dropna方法删除包含文本型变量中任何空值的行# 参数subset指定要考虑的列(文本型变量列)# axis=0表示按行删除# inplace=True表示在原始DataFrame上进行修改data2.reset_index(drop=True, inplace=True)# 使用reset_index方法重置行索引,并丢弃旧的索引# 参数drop=True表示丢弃旧的索引# inplace=True表示在原始DataFrame上进行修改data2# 返回删除了包含文本型变量中任何空值的行并重置索引后的data22.4.6 修复变量类型;
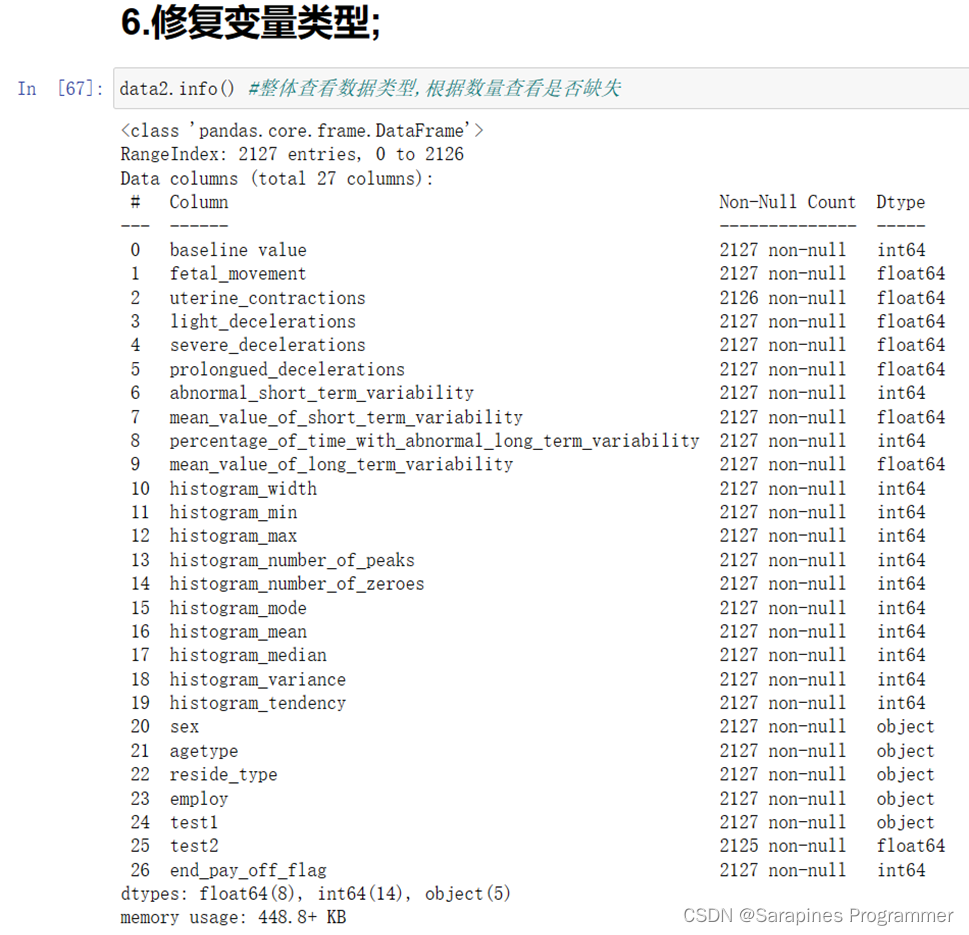
图1-13
代码如下:
data2.info() #整体查看数据类型,根据数量查看是否缺失
图1-14
代码如下:
# 查找float类型def isfloatnum(string):'''检查字符串是否为浮点数:param string: 要检查的字符串:return: 如果是浮点数返回True,否则返回False'''list_str = string.split('.') # 将字符串按照小数点进行分割if len(list_str) > 2: # 如果分割后的列表长度大于2,说明小数点不止一个,不是浮点数return Falseelse:for num in list_str:if not num.isdigit(): # 如果分割后的列表中有元素不是数字,不是浮点数return Falsereturn True # 否则是浮点数# 查找连续型变量是否有字符串情况存在def find_str_innum(data):'''通过检查传入数据集中object类型的变量,统计字符串str_sum数量 以及 浮点数/整数 int_num数量:param data: 传入需要检查的数据集:return: 包含object类型变量、数值型和字符串统计的DataFrame。列包括object_facname(变量名)、sample_num(样本量)、str_sum(文本数据量)、float/int_sum(浮点数/整数数据量)、str_detail(字符串详细内容)'''df_find_str_innum = pd.DataFrame(columns=['object_facname', 'sample_num', 'str_sum', 'float/int_sum', 'str_detail'])num_index = 0# 遍历数据集的每一列for col in data.columns:if str(data[col].dtype) == 'object': # 检查列的数据类型是否为object(文本型)n_samples = data[col].shape[0] # 样本量sum_str = 0 # 文本数据量sum_float = 0 # 浮点数/整数数据量list_detail = [] # 存储字符串详细内容的列表for value in data[col]:if isfloatnum(value) or value.isdigit(): # 如果值是浮点数或整数sum_float += 1else: # 否则是字符串sum_str += 1list_detail.append(value)if n_samples != sum_str: # 如果样本量不等于文本数据量,说明该列还包含其他类型的数据(浮点数/整数)list_detail = np.unique(list_detail) # 去重字符串详细内容str_detail = ','.join(list_detail) # 将字符串详细内容以逗号连接else:str_detail = ''df_find_str_innum.loc[num_index] = [col, n_samples, sum_str, sum_float] + [str_detail] # 添加到结果DataFramenum_index += 1return df_find_str_innum# 调用find_str_innum函数,传入数据集data2,获得包含统计信息的DataFramedf_find_str_innum = find_str_innum(data2)df_find_str_innum# 返回
图1-15
代码如下:
data2.drop(data2[(data2['test1'] == 'Na') |(data2['test1'] == 'unknown')].index, inplace=True)data2.reset_index(drop=True, inplace=True) # 恢复索引data2
图1-16
代码如下:
# 将test1转换为float类型data2['test1'] = data2['test1'].astype(float)data2.info()2.4.7 变量数据处理方式划分;

图1-17
代码如下:
# 需要对数据进行划分# ① 取数值、连续类型的数据list_train_num = ['baseline value','fetal_movement','uterine_contractions','light_decelerations','severe_decelerations','prolongued_decelerations','abnormal_short_term_variability','mean_value_of_short_term_variability','percentage_of_time_with_abnormal_long_term_variability','mean_value_of_long_term_variability','histogram_width','histogram_min','histogram_max','histogram_number_of_peaks','histogram_number_of_zeroes','histogram_mode','histogram_mean','histogram_median','histogram_variance','histogram_tendency','test1','test2']# ②取文本/离散、无需独热编码 类型的数据(类似 住宅类型、就业类型 等字段)list_train_str = ['sex','employ']# ③取文本/离散、需 独热编码 类型的数据(类似 教育水平分类 等变量)list_train_str_needtrf = ['reside_type','agetype']# 查看训练集空值情况(此时只剩数值型空值,其他类型的数据都被处理了)data2[data2.isnull().any(axis=1)].head()源码解释如下:
- list_train_num: 创建一个包含数值、连续类型数据的列表。该列表包含了一系列数值型变量的名称,例如'baseline value'、'fetal_movement'等。
- list_train_str: 创建一个包含文本/离散、无需独热编码的数据类型的列表。该列表包含了一系列文本型变量的名称,例如'sex'、'employ'等。
- list_train_str_needtrf: 创建一个包含文本/离散、需要独热编码的数据类型的列表。该列表包含了一系列需要进行独热编码的变量的名称,例如'reside_type'、'agetype'等。
- data2[data2.isnull().any(axis=1)].head(): 使用isnull().any(axis=1)方法检查data2中是否存在空值,并返回含有空值的行。.head()用于查看返回结果的前几行。这里的目的是查看训练集中数值型变量的空值情况。

图1-18
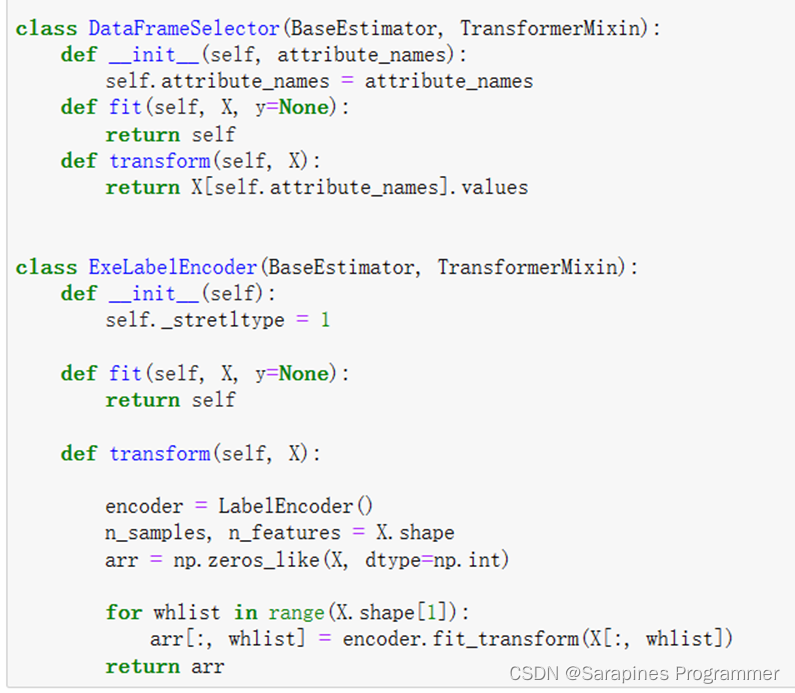
图1-19
代码如下:
# 数据清洗函数定义from sklearn.impute import SimpleImputerfrom sklearn.base import BaseEstimator, TransformerMixinfrom sklearn.preprocessing import LabelEncoderfrom sklearn.preprocessing import LabelBinarizerfrom sklearn.utils import check_arrayfrom scipy import sparseclass CategoricalEncoder(BaseEstimator, TransformerMixin):"""将分类特征编码为数字数组。此函数输入 分类的整数矩阵 或 字符串矩阵,将把分类(离散)特征所具有的值转化为数组"""def __init__(self, encoding='onehot', categories='auto', dtype=np.float64,handle_unknown='error'):self.encoding = encodingself.categories = categoriesself.dtype = dtypeself.handle_unknown = handle_unknowndef fit(self, X, y=None):"""Fit the CategoricalEncoder to X.Parameters----------X : array-like, shape [n_samples, n_feature]The data to determine the categories of each feature.Returns-------self"""# 报错预警if self.encoding not in ['onehot', 'onehot-dense', 'ordinal']:template = ("encoding should be either 'onehot', 'onehot-dense' ""or 'ordinal', got %s")raise ValueError(template % self.handle_unknown)if self.handle_unknown not in ['error', 'ignore']:template = ("handle_unknown should be either 'error' or ""'ignore', got %s")raise ValueError(template % self.handle_unknown)if self.encoding == 'ordinal' and self.handle_unknown == 'ignore':raise ValueError("handle_unknown='ignore' is not supported for"" encoding='ordinal'")X = check_array(X, dtype=np.object, accept_sparse='csc', copy=True)n_samples, n_features = X.shape # n_samples 样本数,n_features 特征数self._label_encoders_ = [LabelEncoder() for n_f in range(n_features)]for i in range(n_features):le = self._label_encoders_[i]Xi = X[:, i]if self.categories == 'auto':le.fit(Xi)else:valid_mask = np.in1d(Xi, self.categories[i])if not np.all(valid_mask):if self.handle_unknown == 'error':diff = np.unique(Xi[~valid_mask])msg = ("Found unknown categories {0} in column {1}"" during fit".format(diff, i))raise ValueError(msg)le.classes_ = np.array(np.sort(self.categories[i]))self.categories_ = [le.classes_ for le in self._label_encoders_]return selfdef transform(self, X):"""Transform X using one-hot encoding.Parameters----------X : array-like, shape [n_samples, n_features]The data to encode.Returns-------X_out : sparse matrix or a 2-d arrayTransformed input."""X = check_array(X, accept_sparse='csc', dtype=np.object, copy=True)n_samples, n_features = X.shapeX_int = np.zeros_like(X, dtype=np.int) # 构建一个和 X 维度相同的X_mask = np.ones_like(X, dtype=np.bool) # 构建一个和 X 维度相同的for i in range(n_features): # 对每个变量开始循环valid_mask = np.in1d(X[:, i], self.categories_[i])if not np.all(valid_mask):if self.handle_unknown == 'error':diff = np.unique(X[~valid_mask, i])msg = ("Found unknown categories {0} in column {1}"" during transform".format(diff, i))raise ValueError(msg)else:# Set the problematic rows to an acceptable value and# continue `The rows are marked `X_mask` and will be# removed later.X_mask[:, i] = valid_mask # unique矩阵赋予X_maskX[:, i][~valid_mask] = self.categories_[i][0]X_int[:, i] = self._label_encoders_[i].transform(X[:, i])if self.encoding == 'ordinal':return X_int.astype(self.dtype, copy=False)mask = X_mask.ravel() # .ravel()将矩阵向量化n_values = [cats.shape[0] for cats in self.categories_]n_values = np.array([0] + n_values)indices = np.cumsum(n_values)column_indices = (X_int + indices[:-1]).ravel()[mask]# 找到该变量某个离散值中的所有的列索引row_indices = np.repeat(np.arange(n_samples, dtype=np.int32),n_features)[mask]data = np.ones(n_samples * n_features)[mask]out = sparse.csc_matrix((data, (row_indices, column_indices)),shape=(n_samples, indices[-1]),dtype=self.dtype).tocsr()# out = out[:,1:]# 这里为one_hot,如果要转换成哑变量需要将状态进行k-1删除,防止虚拟陷阱!if self.encoding == 'onehot-dense':return out.toarray()else:return outclass DataFrameSelector(BaseEstimator, TransformerMixin):def __init__(self, attribute_names):self.attribute_names = attribute_namesdef fit(self, X, y=None):return selfdef transform(self, X):return X[self.attribute_names].valuesclass ExeLabelEncoder(BaseEstimator, TransformerMixin):def __init__(self):self._stretltype = 1def fit(self, X, y=None):return selfdef transform(self, X):encoder = LabelEncoder()n_samples, n_features = X.shapearr = np.zeros_like(X, dtype=np.int)for whlist in range(X.shape[1]):arr[:, whlist] = encoder.fit_transform(X[:, whlist])return arr2.4.8 变量数据处理方式划分;

图1-20
代码如下:
from sklearn.model_selection import train_test_split# 如果为监督学习则需要复制标签,如果无监督学习则不需要下方复制标签的代码data2_labels = data2["end_pay_off_flag"].copy() # 复制标签data2.drop(["end_pay_off_flag"], axis=1,inplace=True) # 删除逾期标签# 30%数据做测试集Xtrain, Xtest, Ytrain, Ytest = train_test_split(data2, data2_labels, test_size=0.3, random_state=42)Xtrain源码分析:
1.导入train_test_split函数,该函数用于划分数据集为训练集和测试集。
2.根据注释中的说明,如果是监督学习任务,则需要复制标签列,如果是无监督学习任务,则不需要复制标签列。在这里,假设是监督学习任务,因此需要复制标签列。
3.通过data2["end_pay_off_flag"].copy()将标签列("end_pay_off_flag")复制到data2_labels变量中。
4.使用data2.drop(["end_pay_off_flag"], axis=1, inplace=True)从data2数据集中删除标签列,即在原始数据集上进行修改。
调用train_test_split函数,并传入以下参数:
- data2:要划分的特征数据集。
- data2_labels:复制的标签数据集。
- test_size=0.3:测试集的比例为30%。
- random_state=42:设置随机种子,以确保每次划分的结果都相同。
函数返回四个数据集:
- Xtrain:训练集的特征数据。
- Xtest:测试集的特征数据。
- Ytrain:训练集的标签数据。
- Ytest:测试集的标签数据。
2.4.9 拼接数据处理流水线.

图1-21
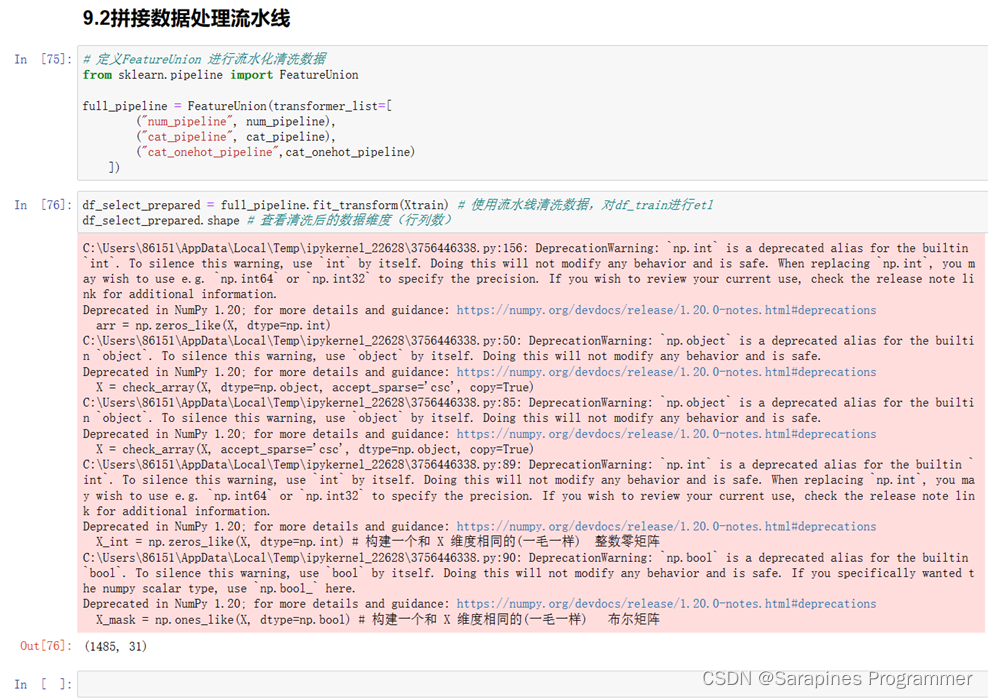
图1-22
代码如下:
from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import FeatureUnion# 定义连续型数据处理的Pipelinenum_pipeline = Pipeline([('selector', DataFrameSelector(list_train_num)), # 选择连续型特征('simple_imputer', SimpleImputer(strategy="mean")), # 填充缺失值('std_scaler', StandardScaler()), # 标准化数据])# 定义离散型数据处理的Pipelinecat_pipeline = Pipeline([('selector', DataFrameSelector(list_train_str)), # 选择离散型特征('label_encoder', ExeLabelEncoder()), # 使用ExeLabelEncoder将数据转换为数字])# 定义需要进行One-Hot编码的离散型数据处理的Pipelinecat_onehot_pipeline = Pipeline([('selector', DataFrameSelector(list_train_str_needtrf)), # 选择需要进行One-Hot编码的离散型特征('cat_encoder', CategoricalEncoder(encoding="onehot-dense")), # 使用CategoricalEncoder进行One-Hot编码])# 定义FeatureUnion,将连续型、离散型和One-Hot编码的数据处理Pipeline合并full_pipeline = FeatureUnion(transformer_list=[("num_pipeline", num_pipeline),("cat_pipeline", cat_pipeline),("cat_onehot_pipeline", cat_onehot_pipeline)])# 使用full_pipeline对训练集Xtrain进行数据清洗和处理,并返回处理后的数据集df_select_prepared = full_pipeline.fit_transform(Xtrain)df_select_prepared.shape # 查看清洗后的数据维度(行列数)源码分析:
定义了多个Pipeline,用于对不同类型的特征进行数据清洗和处理。
1.num_pipeline是用于连续型数据的Pipeline,包括以下处理步骤:
- selector:选择连续型特征,使用DataFrameSelector进行选择。
- simple_imputer:填充缺失值,使用SimpleImputer,采用平均值策略。
- std_scaler:标准化数据,使用StandardScaler进行标准化。
2.cat_pipeline是用于离散型数据的Pipeline,包括以下处理步骤:
- selector:选择离散型特征,使用DataFrameSelector进行选择。
- label_encoder:将离散型数据转换为数字,使用ExeLabelEncoder进行转换。
3.cat_onehot_pipeline是用于需要进行One-Hot编码的离散型数据的Pipeline
最后,使用FeatureUnion将上述三个Pipeline合并成一个整体的数据处理Pipeline,并命名为full_pipeline。打印df_select_prepared.shape,输出清洗后的数据维度(行列数)。
2.5 实验心得
通过这次实验,深度领略了使用机器学习库进行数据清洗的奥妙。成功搭建了机器学习的基石,包括NumPy、Pandas、Scikit-learn等,同时搭建了Python、Jupyter Notebook等运行环境。
在实验中,探索了数据清洗的精髓和关键步骤,明白了数据清洗的不可或缺。这一过程帮助我们从原始数据中剔除不准确、不完整或不适合模型的记录,确保数据准确、可靠、适合训练模型,并发现纠正数据中的错误、缺失和不一致,提升数据的质量和准确性。
在清洗过程中,遇到了不同情况下的数据问题,如唯一性、同义异名、数据类型不匹配以及连续型变量的缺失值等。针对这些问题,采取了相应的清洗步骤。
首先,剔除了缺失率过高的变量,提高后续分析和模型训练的效率。然后,清理了不需要入模的变量,以提高模型效率和准确性。接着,删除了文本型变量中存在缺失值的行,修复了变量的类型,确保每个变量都具有正确的数据类型。
在数据处理方式阶段,根据变量类型和处理方式将数据分为不同类别,为每个类别选择了相应的数据处理方法,例如标准化、归一化等。这样可根据不同变量特点更准确、合理地处理数据。
最后,将数据分为训练集和测试集,以进行模型训练和性能评估。为简化整个数据清洗流程,创建了一个数据处理流水线,整合了不同处理步骤,方便未来的数据分析任务中重复使用。通过实验,深刻领会了数据清洗的原理和步骤,认识到了在实际数据分析工作中的不可或缺性。
致读者
风自火出,家人;君子以言有物而行有恒